YOLO26 重磅发布:性能翻倍!更快更强更轻量的目标检测新标杆
YOLO26发布:突破性边缘AI视觉模型 摘要:Ultralytics最新发布的YOLO26模型带来了四大创新:1)原生端到端设计彻底摒弃NMS后处理;2)移除DFL模块简化部署流程;3)首创MuSGD优化器实现稳定训练;4)增强损失函数提升小目标检测。该模型在CPU上实现43%的速度提升,支持目标检测、分割等六大视觉任务,特别优化了边缘设备部署,通过统一框架降低应用门槛。YOLO26的革新设计使
YOLO26 重磅发布:性能翻倍!更快更强更轻量的目标检测新标杆
北京时间2025年9月25日,在伦敦举行的YOLO Vision 2025大会上,Ultralytics创始人兼CEO Glenn Jocher正式发布了备受期待的YOLO26。作为YOLO系列的最新成员,YOLO26承诺成为更好、更快、更小的Vision AI模型,专门为边缘和低功耗设备设计。
官方介绍:https://docs.ultralytics.com/zh/models/yolo26/
论文:YOLO26: Key Architectural Enhancements and Performance Benchmarking for Real-Time Object Detection
代码:https://github.com/ultralytics/ultralytics/blob/main/docs/en/models/yolo26.md

YOLO26并非简单的版本升级,而是一次理念上的革新。它的架构遵循三个核心原则:简单性、部署效率和训练创新。
-
简洁性: YOLO26是一个原生的端到端模型,直接生成预测结果,无需非极大值抑制(NMS)。通过消除这一后处理步骤,推理变得更快、更轻量,并且更容易部署到实际系统中。这种突破性方法最初由清华大学的王傲在YOLOv10中开创,并在YOLO26中得到了进一步发展。
-
部署效率: 端到端设计消除了管道的整个阶段,从而大大简化了集成,减少了延迟,并使部署在各种环境中更加稳健。
-
训练创新: YOLO26 引入了MuSGD 优化器,它是 SGD 和 Muon 的混合体——灵感来源于 Moonshot AI 在 LLM 训练中 Kimi K2 的突破。该优化器带来了增强的稳定性和更快的收敛,将语言模型中的优化进展转移到计算机视觉领域。
-
任务特定优化: YOLO26 针对专业任务引入了有针对性的改进,包括用于 Segmentation 的语义分割损失和多尺度原型模块,用于高精度 姿势估计 的残差对数似然估计 (RLE),以及通过角度损失优化解码以解决 旋转框检测 中的边界问题。
与传统YOLO模型最大的区别在于,YOLO26是原生端到端模型,无需非极大值抑制(NMS)后处理即可直接生成预测结果。这一突破性方法最初由清华大学的王敖在YOLOv10中首创,并在YOLO26中得到了进一步发展。
这意味着推理过程更快、更轻便,也更容易部署到现实世界的系统中。
核心技术突破:四大创新设计
1. 彻底告别DFL模块
YOLO26完全移除了分布焦点损失(DFL)模块。虽然DFL有效,但它常常使导出复杂化并限制了硬件兼容性。这一简化大大扩展了对边缘和低功耗设备的支持。
2. 端到端无NMS推理
与依赖NMS作为单独后处理步骤的传统检测器不同,YOLO26直接生成最终预测结果。这消除了整个管道阶段,显著减少延迟,使部署更加稳健。
3. 全新的MuSGD优化器
YOLO26引入了MuSGD优化器,它是SGD和Muon的混合体,灵感来自Moonshot AI在LLM训练中取得的Kimi K2突破。这一创新将语言模型中的优化技术应用到了计算机视觉领域,带来更稳定的训练和更快的收敛速度。
4. 增强的损失函数
结合ProgLoss和STAL等改进的损失函数,YOLO26在检测精度上有所提高,尤其在小物体识别方面有显著改进。这对于物联网、机器人、航空图像和其他边缘应用至关重要。
移除分布焦点损失(DFL),简化预测流程 早期 YOLO 模型在训练过程中使用分布焦点损失(DFL)来提升边界框精度。尽管这一方法有效,但 DFL 增加了模型复杂度,且对回归范围设置了固定限制,给模型导出和部署带来挑战,尤其在边缘设备和低功耗硬件上表现更为明显。
YOLO26 完全移除了 DFL 模块。这一改动消除了早期模型中固定的边界框回归限制,提升了检测超大物体时的可靠性和准确性。通过简化边界框预测流程,YOLO26 更易于导出,且能在各类边缘设备和低功耗硬件上稳定运行。
端到端无 NMS 推理
传统目标检测流程依赖非极大值抑制(NMS)作为后处理步骤,用于过滤重叠预测结果。尽管 NMS 效果显著,但它会增加延迟和复杂度,且在多运行时环境和不同硬件目标上部署时容易出现不稳定问题。
YOLO26 引入原生端到端推理模式,模型可直接输出最终预测结果,无需将 NMS 作为独立的后处理步骤。重复预测的过滤的操作在网络内部完成。移除 NMS 不仅降低了延迟,简化了部署流程,还减少了集成错误的风险,使 YOLO26 特别适合实时部署和边缘部署场景。
渐进式损失平衡(ProgLoss)+ 小目标感知标签分配(STAL),提升识别能力
训练相关的关键特性是引入了渐进式损失平衡(ProgLoss)和小目标感知标签分配(STAL)。这些优化的损失函数有助于稳定训练过程,提升检测精度。
ProgLoss 让模型在训练过程中学习更稳定,减少了训练波动,使模型收敛更平稳。同时,STAL 则针对小目标进行了优化,改善模型在视觉信息有限情况下的学习效果。
ProgLoss 和 STAL 的结合实现了更可靠的检测效果,尤其在小目标识别方面有显著提升。这一点对于物联网(IoT)、机器人技术和航空影像等边缘应用至关重要,因为在这些场景中,物体往往体积小、距离远或部分可见。
MuSGD 优化器,实现更稳定的训练
YOLO26 采用了一种新的优化器 MuSGD,用于提升训练的稳定性和效率。MuSGD 将传统随机梯度下降(SGD)的优势,与源自大语言模型训练的 Muon 类优化思想相结合。
SGD 在计算机视觉领域长期被证明具有良好的泛化能力,而近年的大模型训练经验也表明,适当引入新的优化策略可以进一步提升稳定性和效率。MuSGD 将这些理念引入了计算机视觉领域。
受 Moonshot AI 的 Kimi K2 训练经验启发,MuSGD 融入了有助于模型更平稳收敛的优化策略。这使得 YOLO26 能够更快地达到出色性能,同时减少训练不稳定性,尤其在更大规模或更复杂的训练场景中效果显著。
MuSGD 让 YOLO26 在不同模型尺寸下的训练都更具可预测性,既提升了性能,又增强了训练稳定性。
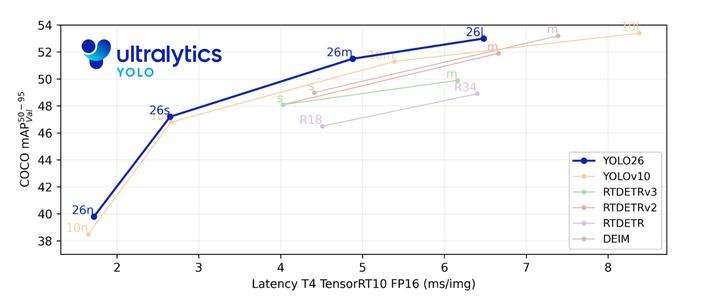
CPU 推理速度提升高达 43%
随着 Vision AI 不断向数据产生端靠近,边缘性能的重要性持续提升。YOLO26 针对边缘计算场景进行了深度优化,在无 GPU 的条件下,CPU 推理速度最高提升可达 43%。
这一能力使实时视觉系统能够直接运行在摄像头、机器人和嵌入式硬件上,满足低延迟、高可靠性和成本受限的实际需求。
性能提升:数字说明一切
根据官方公布的性能预览,YOLO26在标准CPU上的推理速度相比前代模型最高可提升43%。这一提升对于资源受限的环境来说是一个重大飞跃。
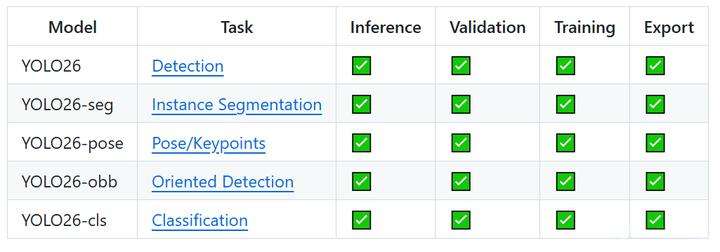
多任务支持:一站式的视觉AI解决方案,YOLO26延续了Ultralytics模型的多功能传统,支持广泛的计算机视觉任务:
-
目标检测:识别和定位图像或视频帧中的多个物体
-
实例分割:生成像素级完美的物体边界
-
图像分类:将整个图像归类到特定类别或标签
-
姿态估计:检测人体和其他物体的关键点及姿态
-
定向边界框(OBB):检测任意角度的物体,特别适用于航拍和卫星图像
-
目标跟踪:跨视频帧或实时流跟踪物体
这种统一框架使YOLO26成为真正多功能的视觉AI解决方案,适用于从实时检测到分割、分类、姿态估计和定向物体检测的各种任务。
相对比热门模型:
| 维度 | YOLOv11 | YOLOv26 | DEIMv2 |
|---|---|---|---|
| 核心目标 | 通用场景下精度与多任务平衡 | 边缘设备的高效推理与部署 | 高精度检测与特征表示 |
| 关键创新 | C3K2与C2PSA模块 | 无NMS端到端设计、MuSGD优化器 | DINOV3特征迁移、密集一对一匹配 |
| 精度表现 | 较YOLOv8提升2%-5%mAP | 小目标AP提升5.1% | DEIMv2-X达57.8AP |
| 推理速度 | 比yolov8快15-20% | cpu推理速度提升43% | 未强调速度优势 |
| 部署复杂度 | 中等 | 低(无需NMS后处理) | 中等 |
| 硬件适应性 | 边缘设备至GPU服务器 | 低功耗cpu至中端GPU | 服务器至移动端全场景覆盖 |
-
YOLOv11: 适用于需要平衡精度、速度与多任务支持的通用场景,如综合视觉分析系统。
-
DEIMv2: 适用于对检测精度有严苛要求的专业场景,如自动驾驶、医疗影像等。
-
YOLO26: Nano模型CPU 提升高达43%,是目前边缘计算和CPU部署领域中速度最快的高精度目标检测模型之一。所有计算机视觉任务均支持在统一框架内进行训练、验证、推理和导出,降低了部署学习门槛。
实际应用场景:从机器人到智能交通
YOLO26的轻量化和高精度特性,使其在多个行业展现巨大潜力:
-
在机器人技术领域,YOLO26能帮助机器人实时解读周围环境,使导航更加顺畅,物体处理更加精确。在制造业中,它可以实现自动化缺陷检测,比人工检测更快、更准确地识别生产线上的缺陷。
-
对智能交通系统而言,YOLO26能在低功耗硬件上实现实时监控与预警。而在无人机与遥感领域,通过OBB功能,它可以检测复杂角度的地面物体。
简单的YOLO26训练和推理示例
PyTorch pretrained *.pt 模型以及配置 *.yaml 文件可以传递给 YOLO() 类在 Python 中创建模型实例:
from ultralytics import YOLO
# Load a COCO-pretrained YOLO26n model
model = YOLO("yolo26n.pt")
# Train the model on the COCO8 example dataset for 100 epochs
results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
# Run inference with the YOLO26n model on the 'bus.jpg' image
results = model("path/to/bus.jpg")
部署灵活性:一次训练,随处部署
YOLO26支持多种导出格式,包括TensorRT、ONNX、CoreML、TFLite和OpenVINO等。这种灵活的部署选项使YOLO26可以轻松集成到现有工作流程,并兼容几乎所有平台。
得益于简化的架构,YOLO26还完美支持INT8量化与FP16半精度推理,在保证精度的前提下进一步减小模型体积、提升速度。这意味着YOLO26不仅能在服务器集群中高速运行,也能在手持设备、智能相机等边缘环境中稳定工作。
YOLOE-26:开放词汇实例分割
YOLOE-26将高性能YOLO26架构与YOLOE系列的开放词汇能力相结合。它通过使用文本提示、视觉提示或无提示模式进行零样本推理,实现对任何目标类别的实时检测和分割,有效消除了固定类别训练的限制。
通过利用YOLO26的免NMS、端到端设计,YOLOE-26提供了快速的开放世界推理。这使其成为动态环境中边缘应用的强大解决方案,其中感兴趣的目标代表着广泛且不断演进的词汇。 YOLOE-26 支持基于文本和基于视觉的提示。使用提示非常简单——只需通过 predict 方法,如下所示:
文本提示允许您通过文本描述指定要 detect 的类别。以下代码展示了如何使用 YOLOE-26 来 detect 图像中的人物和公交车:
from ultralytics import YOLO
# Initialize model
model = YOLO("yoloe-26l-seg.pt") # or select yoloe-26s/m-seg.pt for different sizes
# Set text prompt to detect person and bus. You only need to do this once after you load the model.
names = ["person", "bus"]
model.set_classes(names, model.get_text_pe(names))
# Run detection on the given image
results = model.predict("path/to/image.jpg")
# Show results
results[0].show()
何时可以体验YOLO26?
现已将代码公布,可至文章开头连接转至官网,得对应代码工程使用
结语:视觉AI的未来之路
YOLO26的发布标志着实时目标检测领域的又一个重要里程碑。通过端到端简化、架构优化和训练创新,YOLO26为计算机视觉带来了全新的速度与灵活性。
正如Glenn Jocher在YOLO Vision 2025大会上所言:“最大的挑战之一,就是在保持卓越性能的同时,让用户最大化利用YOLO26的简单性与高效性。”
随着边缘AI的快速发展,YOLO26的出现正当其时。它有望成为连接边缘AI与企业级系统的桥梁,推动计算机视觉技术走向更广泛的实际应用。
喜欢的小伙伴感谢给点个赞和关注,更多精彩内容持续更新~~ 关于本篇文章大家有任何建议或意见,欢迎在评论区留言交流!
end
福利!!!本公众号为粉丝精心整理了超级全面的python学习、算法、人工智能等重磅干货资源,关注公众号即可免费领取!

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 10
10 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)