【无标题】ASTRA:自回归去噪的通用交互式世界模型
Astra模型提出了一种通用交互式世界建模新范式,新性地将自回归长时程建模与扩散高保真合成相结合,通过噪声增强历史记忆机制和动作感知适配器,在自动驾驶、机器人操作等多样化场景中实现了高精度未来预测与动作交互。实验表明,Astra在保真度、远距离预测和动作对齐方面显著超越现有世界模型,为构建可交互、高一致性的通用视觉世界模型提供了新思路。

标题:《ASTRA : GENERAL INTERACTIVE WORLD MODEL WITH AUTOREGRESSIVE DENOISING》项目:https://eternalevan.github.io/Astra-project/来源:清华大学;快手科技
文章目录
摘要
扩散Transformer 的最新进展使视频生成模型能够从文本或图像中生成高质量视频片段。然而,具备根据过往观察和动作预测长期未来的能力的世界模型仍处于探索阶段,尤其在通用场景和多种动作形式方面。Astra是一个交互式通用世界模型,可为自动驾驶、机器人抓取等多样化场景生成真实世界的未来画面,并精确模拟动作交互(如摄像头运动、机器人动作)。自回归去噪架构,采用时序因果注意力机制,整合过往观察数据并支持流式输出。通过引入噪声增强历史记忆机制,在响应速度与时间连贯性之间取得平衡,避免过度依赖历史帧。为实现精准动作控制,我们设计了动作感知适配器,将动作信号直接注入去噪过程。进一步开发的动作专家混合模型能动态路由异构动作模态,显著提升探索、操作、摄像头控制等多样化现实任务的通用性。Astra实现了交互性、一致性与通用性的长期视频预测,并支持多种交互形式。多数据集实验表明,Astra在保真度、远距离预测和动作对齐方面较现有最先进世界模型均有显著提升。
相关工作
1. 视频生成模型
近年来,去噪扩散模型 已成为生成建模领域的主流范式,因其高保真度和可控性而备受推崇。继其在文本到图像(T2I)合成领域的成功后,早期视频生成方法将扩散模型拓展至时间域,通常通过在基于图像的UNet中添加额外的时间层来实现。近期,Sora及其后续研究开创了高质量、高分辨率的文本到视频(T2V)扩散模型。这些模型普遍采用扩散Transformer(DiT)架构来捕捉复杂的空间与时间一致性,进一步提升了长时序一致性。除纯扩散模型外,混合框架也被提出以协调长距离预测与高质量合成。通过结合时间建模的自回归与局部真实性的扩散机制,StreamingT2V 和 MAGI 等方法实现了视频的扩展生成。然而,这些方法仍面临长序列中误差累积的挑战,且对外部动作响应有限,导致视频生成与真实交互式世界模拟之间存在差距。
2. 视觉世界模型
视觉世界模型不仅限于视频生成,其核心目标在于捕捉环境的因果动态,使智能体能够模拟未来轨迹并与世界互动。与依赖静态输入生成短视频的文本转视频或图像转视频模型不同,视觉世界模型能显式整合历史信息与动作决策,这使其在规划、控制和具身智能等任务中至关重要。近期多项研究印证了这一趋势:
1.【iVideoGPT】 Interactive VideoGPTs are Scalable World Models 将自回归视频Transformer扩展至动作与奖励的整合,使智能体能预测交互环境中未来观测的演变;
2. 【WorldDreamer】 Towards General World Models for Video Generation via Predicting Masked Tokens 将世界建模转化为离散潜在空间中的mask token预测,支持多模态条件化与开放环境模拟;
3. 【Vid2World】 Crafting Video Diffusion Models to Interactive World Models 将预训练视频扩散模型适配为带有因果动作引导的自回归框架,实现可控视频预测;
4. 在导航领域,【Navigation World Models】采用条件扩散变换器生成可信的未来智能体观测,助力陌生场景规划;
5. 【WorldVLA】 Towards Autoregressive Action World Model 提出的视觉-语言-动作(VLA)联合框架,通过自回归方式同步建模世界状态与智能体行为。
6. 在更大规模应用中,【Genie】 Generative Interactive Environments 表明,通过扩展Transformer架构和增加上下文窗口,能显著提升模型在不同领域的部署保真度和泛化能力。
7. 【Yume】 An Interactive World Generation Model 提出的 masked 视频扩散Transformer(MVDT)技术,通过mask输入特征来优化视频质量。
尽管这些方法展现了交互式场景中视觉世界模型的潜力,但仍存在误差累积、长周期部署时的时序漂移以及对多样化动作响应有限等问题。
三、自回归去噪模型
自回归去噪框架,将自回归的长时程建模与扩散的高保真合成相结合。给定一个被离散化为 z 1 : N z^{1:N} z1:N块的视频序列,生成目标为:

每个步骤中,通过 流匹配训练的去噪过程预测下一数据块 z t + 1 z_{t+1} zt+1。具体而言,首先对目标数据块进行带噪插值采样:

并训练流模型 v θ v_θ vθ 以估计干净图像的方向:

其中 v ∗ v^∗ v∗为真实速度。推理过程中,自回归生成通过从噪声中去噪以获得 z i + 1 z^{i+1} zi+1,随后将其附加至历史序列以预测未来片段。这种迭代的AR-去噪循环实现了长距离、一致且高质量的视频预测。
四、算法总览
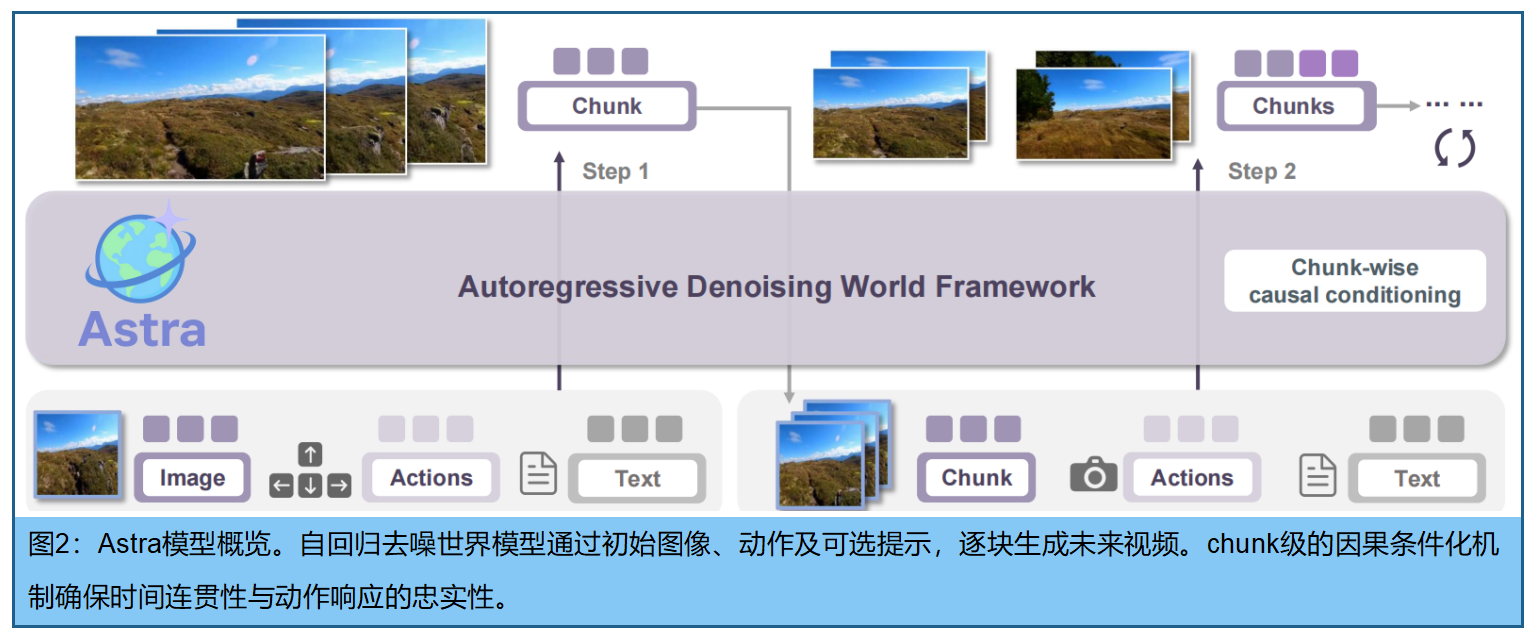
Astra——一个自回归去噪框架,采用“噪声即掩码”策略,通过选择性破坏历史视觉上下文,使模型能更精准地整合动作信号并响应用户指令,实现真实场景视频预测。
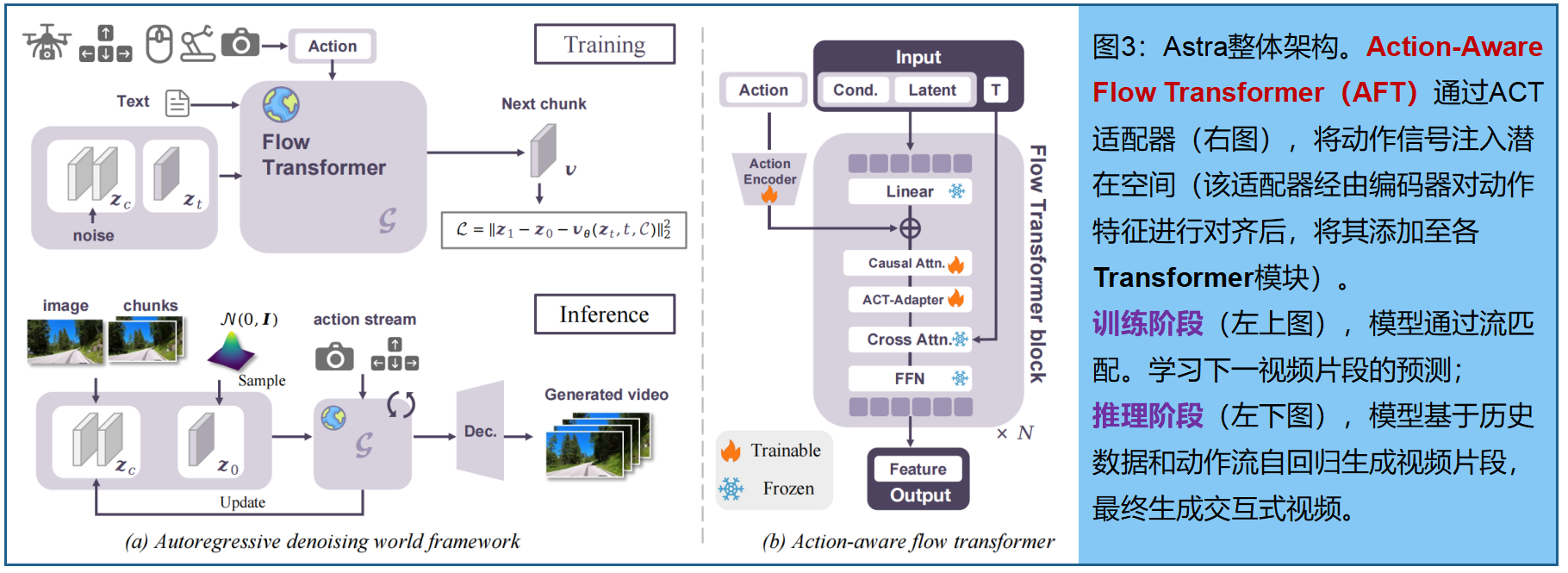
核心思路是利用 预训练 Text-to-Video扩散模型的视觉生成能力,并通过将先前生成的片段作为条件,采用分块自回归预测方式。我们将详细阐述Astra的设计方案,包括用于精确条件化的动作感知适配器、用于长期一致性的噪声增强历史记忆,以及用于统一多样化动作输入的动作专家混合模型(MoAE)。Astra的整体框架如图3:
五、自回归去噪的交互式世界建模
现代SVD模型得益于大规模预训练,能够隐式获取三维空间感知、时间依赖性,甚至运动和力等简单物理模式的部分知识。然而,尽管这些模型具有令人印象深刻的保真度,它们在构建可被保存、交互和探索的真实场景方面仍存在不足。这引发了一个关键问题:T2V模型是否真正属于世界模型?我们认为,世界模型的决定性特征在于交互性——即能够根据任意时刻的任意动作输入动态调整生成的能力。虽然基于扩散的模型可以基于全局提示或场景属性进行条件化,但此类条件机制无法实现细粒度的在线交互。自回归框架天然支持基于历史观测与当前动作的逐步预测机制。与需要单次生成视频的扩散模型不同,自回归模型能即时响应动作输入,从而实现可控且自适应的输出。
基于前一视频片段 z 1 : i − 1 z^{1:i−1} z1:i−1,目标是建立下一帧片段的条件分布模型 p ( z i ∣ z 1 : i − 1 ) p(z^i |z^{1:i−1}) p(zi∣z1:i−1)。为确保高视觉保真度,采用预训练的视频流匹配模型 v θ v_θ vθ 作为预测器,但整合到交互式世界框架中会面临两大挑战:
- (1) 如何表征动作并量化其对未来视觉动态的影响;
- (2) 如何在保持生成质量的同时,将动作信号有效融入预训练的扩散骨干网络。
由于我们的目标是实现对动作输入 a i a^i ai(例如“右转”指令)的即时响应,动作效果应当直接体现在预测视频片段的转换上。受光流公式启发,我们将这种转换视为视频特征的位移——在扩散模型中,这对应着去噪器内部的潜在表征。因此,我们将动作视为扩散模型的附加条件信号,直接作用于其潜在特征空间。这一需求对现有视频扩散架构构成挑战:这些架构通常由堆叠的Transformer模块(DiT)构成,并依赖交叉注意力层将视频潜在特征与文本嵌入对齐。此类机制天然不适用于建模精细的动作诱导位移。为解决此问题, 我们引入动作感知流式Transformer适配器(ACT-Adapter),将预训练视频DiT扩展为自回归去噪模型,能将动作信号作为潜在空间转换进行整合,在保持主干网络生成能力的同时,有效建模动作影响。
如图3,引入动作编码器将动作映射到与视频潜在变量对齐的特征空间。通过在每个模块中逐元素相加的方式,将生成的动作特征注入去噪模型,确保动作信号直接调控潜在表征。为最大化复用预训练知识,我们冻结了流Transformer除自注意力层外的所有参数。此外,在每个自注意力模块后插入轻量级适配器模块——即初始化为单位矩阵的单层线性层。这使得模型在保持预训练主干网络稳定性的同时,逐步学习动作感知变换。对于历史条件 z c = z 1 : i − 1 z_c= z^{1:i−1} zc=z1:i−1,采用帧维度条件化策略:在 流Transformer 处理前,将前序块与预测块沿时间维度拼接。结合动作 a i a^i ai和提示 c c c,去噪模型 v θ v_θ vθ 的完整条件集为 C = C= C={ z 1 : i − 1 , a 1 : i , c z^{1:i−1},a^{1:i},c z1:i−1,a1:i,c}。
为增强动作效果, 提出一种无动作引导机制(AFG) ,其灵感源自无类别引导(CFG)。训练时随机剔除动作条件,迫使模型在无动作输入的情况下进行预测。推理时计算引导速度场:

其中 s s s为引导尺度, z t z_t zt为组合潜在变量, ∅ ∅ ∅表示零作用条件。该技术可增强作用效应,从而对用户输入产生更精确的响应。
六、具有噪声记忆的历史条件
如何平衡长期时间一致性与动作响应性。现有研究表明,生成连贯的长视频需要基于扩展历史进行条件化处理。但我们发现了一个矛盾现象:增加历史长度虽能提升时间一致性,却会削弱动作响应性。我们将这种现象称为“视觉惯性”——模型过度依赖过往视觉信息而忽视用户动作的倾向。这是因为现实数据集主要包含平滑运动轨迹,导致模型更倾向于优先考虑连续性而非突变的动作驱动变化。考虑到密集视觉输入与稀疏动作信号之间的不对称性,我们提出通过引入可控噪声污染来降低视觉条件反射的主导地位。与随机掩码视觉标记方法不同,我们采用 “噪声即掩码”策略:通过向条件视频注入随机噪声来降质模糊其信息内容(图3),具有双重优势:
- 1.无需对去噪模型进行架构修改或增加可学习参数;
- 2.通过污染视觉上下文,模型无法直接复制干净帧,从而被迫将动作线索融入生成过程。
由于污染噪声与扩散噪声相互独立,推理时可利用干净的历史帧。通过这种训练策略,模型学会了平衡动作依赖与历史记忆,从而克服视觉惯性。为进一步延长有效历史范围,采用压缩方法[ Packing input frame context in next-frame prediction models for video generation, 2025] 保留首帧画面,将中间历史压缩为紧凑视觉token,既保留长时程时间信息又不会淹没动作信号。
七、面向多样化场景的【MoAE:混合动作专家模型】
交互式世界建模通常需要 多模态输入:摄像头观测数据 a c a m a_{cam} acam、机器人位姿 a r o b a_{rob} arob和离散键盘/鼠标的动作指令 a c m d a_{cmd} acmd。这些异构信号在结构和尺度上存在差异,使得单一模型难以捕捉其特征。动作专家混合模型(MoAE)通过将不同模态数据分配(routes)至专家,为去噪模型生成统一的动作表征。

如图4,每个动作模态
- 1.首先通过模态专用投影器 R m R_m Rm映射到共享动作空间,即 a ~ i = R m ( a m i ) \tilde{a}^i = R_m(a^i_m) a~i=Rm(ami),其中 m ∈ m∈ m∈{ c a m , r o b , c m d cam,rob,cmd cam,rob,cmd}表示具体模态, i i i为序列索引。
- 2.路由网络计算门控分数 g i = R o u t e r ( a ~ i ) g^i = Router(\tilde{a}^i) gi=Router(a~i),筛选出前K个相关专家。每个选定的专家 E k E_k Ek(独立的多层感知机MLP)将对齐特征转换为任务相关表征。
- 3.专家输出随后根据门控分数进行聚合,生成最终动作嵌入 e i = ∑ k = 1 K g k i E k ( a ~ i ) e_i = \sum_{k=1}^{K} g_{k}^i E_k(\tilde{a}^i) ei=∑k=1KgkiEk(a~i)。嵌入序列 e 1 : i e^{1:i} e1:i随后输入 Flow Transformer。为同时考虑历史和当前动作,我们通过添加二元指示符扩充 a ~ i \tilde{a}^i a~i的动作空间(用于标识输入对应的是过去动作还是当前动作)。
将MoAE与历史条件潜在输入相结合,使模型能够生成时间上连贯且跨模态响应的视频片段。该设计提升了模态特化能力、对新信号的可扩展性、通过仅激活相关专家实现的效率,以及整体通用性,从而在复杂交互场景中实现高保真预测。
实验
1.实验设置
数据集。训练整合了自动驾驶、主动探索、多摄像头渲染及机器人控制等领域的多样化数据集(如表1)。车辆姿态预测采用nuScenes;大规模野外视频(含丰富摄像头标注)使用Sekai和SpatialVID;合成多视角序列采用Multi-Cam Video;机器人动作轨迹则通过Open X-Embodiment获取的RT-1数据集。所有视频均经过480p分辨率调整与裁剪,动作标注通过时间插值法每4帧对齐,与视频 VAE 的时间压缩特性保持一致。这些数据集共同提供了互补的动作信号(车辆、摄像头及机器人姿态),为统一的动作感知世界建模提供支持。评估阶段,我们构建了Astra-Bench基准测试集,包含各数据集的20个保留样本,旨在覆盖真实场景的多样化需求。

训练细节。我们基于预训练的视频扩散模型(Wan: Open and advanced large-scale video generative models.)初始化模型,并在8个GPU(每个80GB) 上进行训练,每个GPU的批量大小为1。使用AdamW优化器进行优化,学习率设为1e−5,训练30个epoch,收敛约需24小时。训练在三维 VAE 的潜在空间中进行。在像素空间中,条件帧数量从[1,128]范围内随机采样,而目标帧数量固定为33帧。
评估指标。Astra-Bench通过六个细粒度指标,对世界模型的两大核心维度——视觉质量与指令跟随(摄像机运动追踪)进行评估。在指令跟随方面,我们重点考察生成视频是否准确呈现预期的行走方向和摄像机运动轨迹。虽然MegaSaM等姿态估计工具可实现自动化处理,但摄像机运动预测的误差和量化误差限制了其可靠性。为此采用人工评估确保精准度。其余维度(包括主体一致性、背景一致性、运动平滑度、美学品质及图像保真度)则采用VBench(Huang 等人,2024)的评估指标。所有测试视频均以480×832分辨率、20帧/秒、96帧/秒的参数生成,每个模型需经过50次推理步骤。
2.实验结果
在Astra-Bench数据集上评估了本方法,并与近期最先进的视频生成和世界建模方法进行对比,包括Wan-2.1(Wan 等人,2025)、Matrix-Game(He 等人,2025)和 YUME(Mao 等人,2025)。如表2所示,我们的方法在所有指标上均持续优于基线方法,展现出在视觉质量和动作响应条件下的显著优势。Astra在保真度和可控性方面持续超越现有视频生成和世界建模方法。
- 我们的模型生成的视频细节更锐利、运动更流畅、时间连贯性更强(图5),在主体与背景一致性、运动平滑度及整体美学吸引力等视觉质量指标上得分更高。
- 指令遵循方面,人工评估证实,Astra在扩展时间范围内保持稳定(图6),生成的轨迹比先前方法更忠实地跟随预期的摄像机运动和动作方向。值得注意的是,虽然竞争方法在长时间运行时常出现误差累积和漂移问题,但,这使其特别适用于需要高保真度和可靠动作遵循的现实世界交互场景。
3.扩展应用
我们的交互式世界模型不仅突破了传统视频预测基准的局限,更能自然适配各类现实场景应用。得益于动作感知条件化、噪声增强记忆和模块化动作编码的均衡设计,该模型可灵活应对相机控制、操作视频预测、长距离探索及自动驾驶等多样化任务(如图7所示)。这种多功能性源于时间一致性与响应式动作整合的统一架构,使其成为模拟、交互与编辑动态环境的通用框架。

自动驾驶。利用nuScenes数据集将Astra扩展至自动驾驶领域,该数据集提供多视角视频和多样化交通场景。通过自我车辆观测和离散控制动作(如左转、前进),Astra生成逼真的未来驾驶视频,完整呈现车辆运动、道路几何特征及智能体交互。其长期连贯性与精准动作响应的结合,实现了交互式驾驶模拟
操控视频预测。在机器人环境中,Astra能够基于当前观察和操作动作预测未来的视频片段,以高保真度和时间一致性模拟抓取或工具使用等精细交互。这些预测性输出支持机器人学习中的规划、策略学习和安全探索。
像机控制。Astra支持通过动作信号实现交互式摄像机控制,这些信号可指定摄像机轨迹(如平移和视角切换)。基于这些位姿,系统生成的视频能遵循指令动作,同时保持空间与时间一致性。这使得在创意和实际应用中均可实现可控的电影级摄像机运动。
多智能体交互。图8展示了通过第一人称驾驶场景处理多智能体交互的能力,其中主驾驶车辆超车两辆其他车辆。模型根据动作指令序列生成连贯的执行轨迹,既遵循指定路线,又能合理模拟周边车辆的运动。这表明自回归去噪过程、噪声增强记忆机制与基于多智能体增强学习的动作条件反射相结合,能够实现稳定可靠的多智能体交互,并确保动作执行的精准性。


DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)