不管VLA还是RL,基于Learning的机器人操作,搞懂“这俩”就够了。
▲图1|从“机器人操作”这件事出发,先把问题拆成上下两层:上层负责把任务想清楚并拆步骤(高层规划),下层负责把动作做稳、做准(低层控制)。为了让机器人更像“会做事”,上层常见会动用一整套工具箱:语言理解、视觉理解、可执行流程、运动目标、可操作区域,以及更结构化的三维场景信息。它提示研究者,在追逐新范式之前,或许应先回答:我所改进的,究竟是机器“思考”任务的能力,还是其“执行”动作的可靠性?机器人要

新词万变,内核不变:机器人操作的本质
——名词通胀何解?
目录
可操作区域学习:比“这是什么”更重要的是“哪里能动、怎么动”
视觉语言大模型、扩散策略等基础模型的兴起,为机器人操作带来了新的思路与新工具,相关研究呈现爆发之势。
然而,各种模型架构与学习范式层出不穷,术语纷繁交织(--VLA、--RL),看似技术爆炸,却也让人不禁追问:
这些模型究竟在解决同一个问题的哪一环?这种“名称各异,内核趋同”的现状,让技术演进的主线变得模糊。
跳出“按模型分类”的惯常视角,一篇由西安交通大学、香港科技大学(广州)等8个顶尖团队发表的最新综述,系统梳理了基于学习的机器人操作方法,提出了一个“穿透术语”的本质框架:
无论技术名词如何演变,其功能都可归结为 “高层任务规划” 与 “低层运动控制” 两层分工。
上层负责“想”——拆解指令、推理步骤;下层负责“做”——感知环境、精准执行。
“零散”的技术名称被纳入同一对话体系。后续方法的差异,往往只是上层如何组织任务逻辑,与下层如何将动作落实至物理世界的具体实现之别。
让机械臂把杯子放进柜子里——
这种任务的难点,往往不在“认出杯子”,而在于:
要先想清楚步骤(做什么、按什么顺序、遇到变化怎么改);
还要把每一步做稳(动作要连续、力度要合适、出偏差要能纠正)。
因此,很多研究者更愿意用一张简单好用的地图来看“机器人操作”:分成两层就够了:
上层:高层规划,负责“想清楚怎么做”;
下层:学习型控制,负责“把动作做稳”。
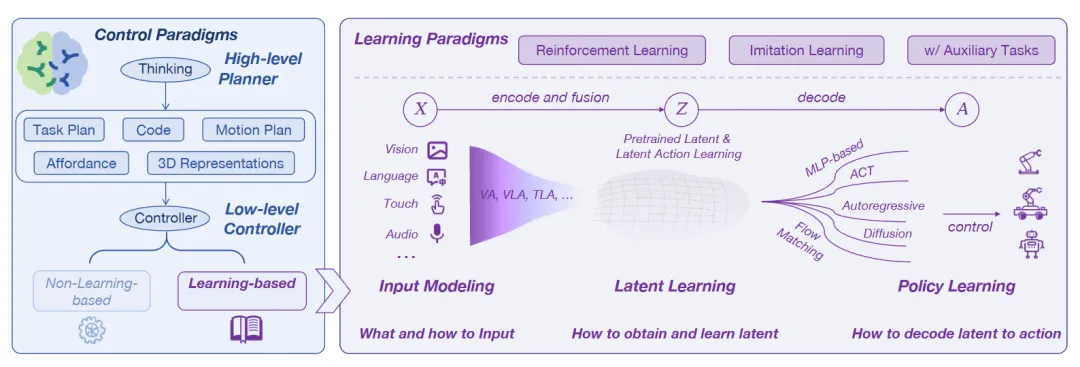
▲图1|从“机器人操作”这件事出发,先把问题拆成上下两层:上层负责把任务想清楚并拆步骤(高层规划),下层负责把动作做稳、做准(低层控制)。其中下层部分重点关注“用数据训练出来的控制策略”,也就是让机器人通过学习来掌握操作动作
下面,我们具体介绍基于学习的机器人操作方法“两层结构” 。
01 上层在做什么?
上层的角色更像“指挥”,核心工作是决定行动意图、时间顺序和注意力焦点,并把感知与控制组织起来,让下层执行有章可循。
因此上层做的就是:把“任务”变成“可执行的步骤与约束”。
为了让机器人更像“会做事”,上层常见会动用一整套工具箱:语言理解、视觉理解、可执行流程、运动目标、可操作区域,以及更结构化的三维场景信息。
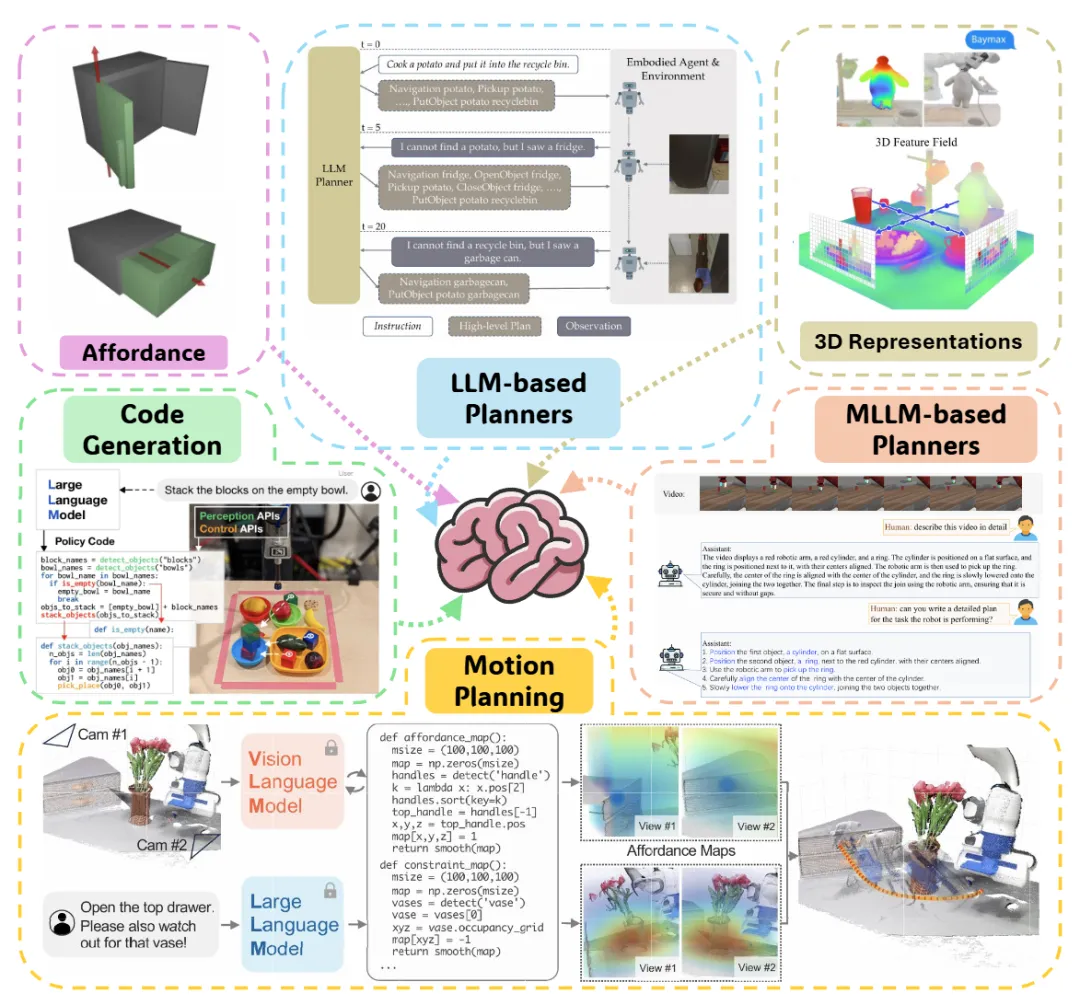
▲图2|上层规划的六块拼图。一张图把上层规划拆成六个核心模块:1)基于语言的任务拆解与步骤规划;2)结合视觉的任务规划(边看边想);3)生成结构化的可执行流程(把计划写得更“能跑”);4)运动规划(生成可行、平滑的动作路径);5)可操作性学习(物体哪里能动、怎么动);6)三维场景表示(用更结构化的空间信息辅助操作)
下面我们对这6个方向逐块介绍。
用语言做任务拆解:先把“大句子”拆成“小步骤”
当人说“把杯子放进柜子里”,机器人需要把它拆成一串可执行的小动作:
走近柜子、开门、抓杯子、抬起、移动、放下、关门。
语言模型常被用来做这件事,相当于把自然语言变成“步骤清单”,并在执行过程中根据情况调整顺序或补充步骤。
这条路线的关键不在“会不会说”,而在“能不能跟着做”:
如果执行中发现柜门卡住、杯子不在原位、抓取失败,上层必须能根据反馈改计划,而不是照着原步骤一路撞南墙。
典型研究如LLM-Planner,根据环境反馈不断更新。
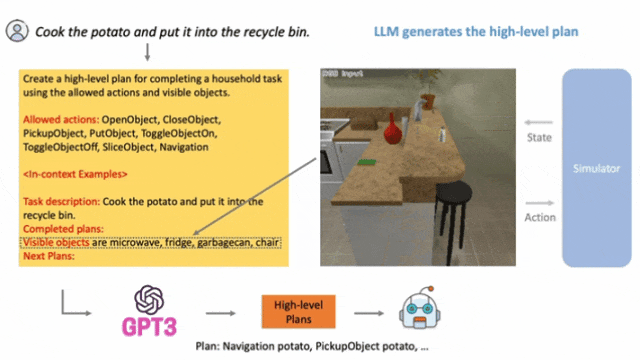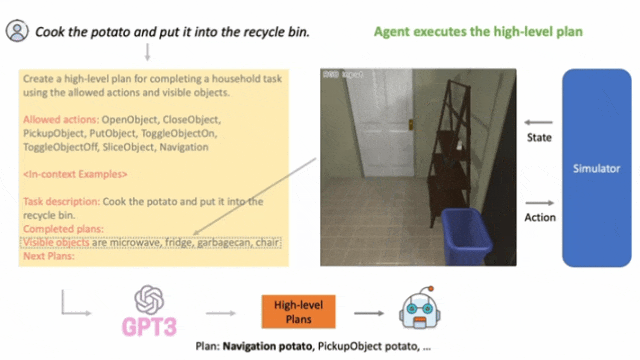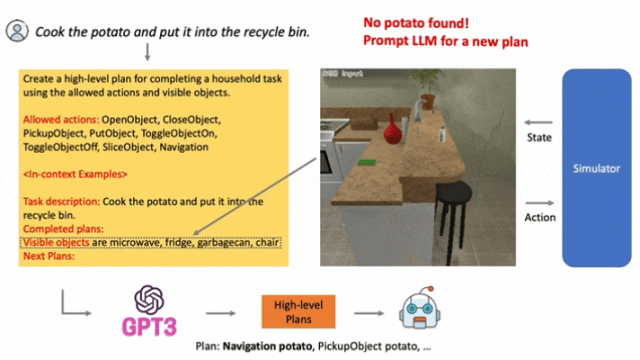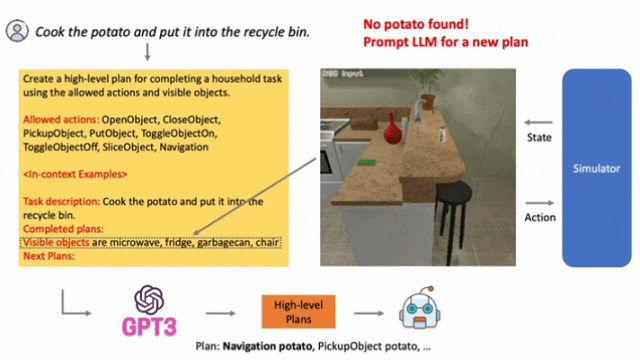
▲LLM-Planner: Few-Shot Grounded Planning for Embodied Agents with Large Language Models
视觉与语言联合规划:边看边想,少走一层“翻译”
如果上层“只能处理文字”,就需要先把视觉信息“翻译成文本”再推理,系统会更复杂,也更容易丢信息。
于是另一条路线是让模型同时接收画面与指令,在同一个推理过程中完成“看到什么”和“要做什么”的联合判断。
更通俗地说,就是不让机器人先写一段“我看见了什么”的作文,再决定怎么做;而是直接边看边想,减少中间环节的损耗。
典型研究如RoboBrain,实时语音中断调整,展现了在物体空间关系识别、多步骤推理、快速交互式推理和实时中断调整方面的能力。

▲RoboBrain 2.0: See Better. Think Harder. Do Smarter
代码式规划:把计划写成“能跑的流程”,而不是一段描述
光用自然语言写计划,有时会太松散,尤其遇到条件分支和重复逻辑:
如果门没开就先开门、如果抓取失败就换个姿态重试……
于是研究者会让模型生成更结构化的可执行流程(可以把它理解成“可执行的步骤脚本”)。
这类方法的好处是:流程结构清晰,条件逻辑明确,调试也更方便。对工程落地而言,它比“一段自由发挥的描述”更像真正能接入系统的计划。
典型研究如Demo2Code(NeurIPS 2023),将语言和演示总结为任务规范,然后递归地将该规范展开为可执行的任务代码。
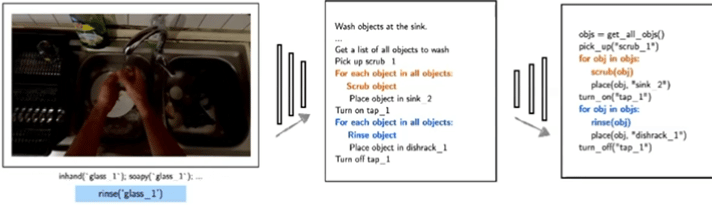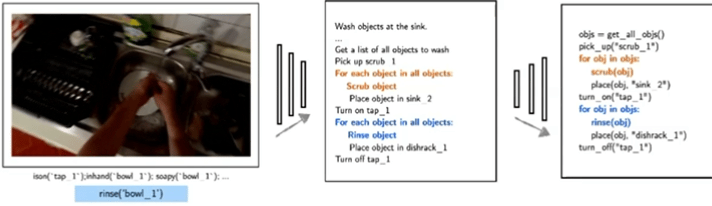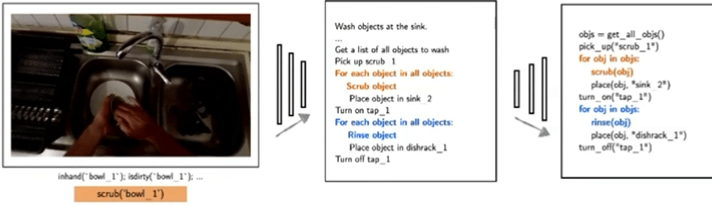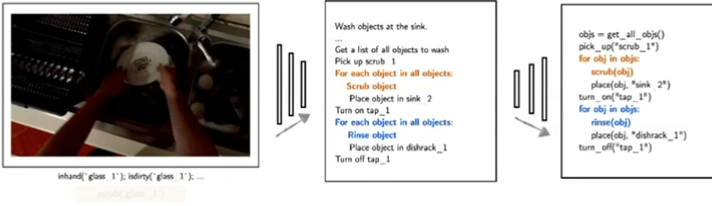
▲Demo2Code: From Summarizing Demonstrations to Synthesizing Code via Extended Chain-of-Thought
让模型指导运动规划:输出“连续目标”,再交给规划器落地
还有一条更贴近物理可行性的路线:上层不直接给“下一步动作”,而是给“运动目标与约束”:
把手移动到某个空间区域、避开某个障碍范围、沿着某个方向推拉……
然后由传统运动规划器在这些目标和约束下生成平滑、可执行的轨迹。
这种分工的价值很明确:学习模型更擅长给方向与意图,传统优化器更擅长保证轨迹可行、平滑、满足几何和动力学约束。
典型研究如ReKep,整个流程无需任何额外的训练或特定于任务的数据。

▲ReKep: Spatio-Temporal Reasoning of Relational Keypoint Constraints for Robotic Manipulation
可操作区域学习:比“这是什么”更重要的是“哪里能动、怎么动”
机器人要做操作任务,光知道“这是门”“这是抽屉”不够,它更需要知道“该抓哪里”“往哪个方向用力”。
因此,上层常会学习可操作性:预测物体哪些部位更适合抓、拉、按、推,动作方向是什么,力度应该怎么配。
这类方法一般会利用几类信息:
- 物体的几何结构(形状、关节限制)
- 视觉线索(在图像上预测“可操作热区”)
- 语义部件(把手、按钮、盖子等)
- 多模态融合(把视觉、语言、空间关系合在一起)
用一句话说:机器人不止要知道“这是门”,还要知道“门把手在哪、应该怎么拉”。
典型研究如MOKA(RSS 2024),采用预训练的视觉语言模型(GPT-4V)来预测基于点的可供性表征。
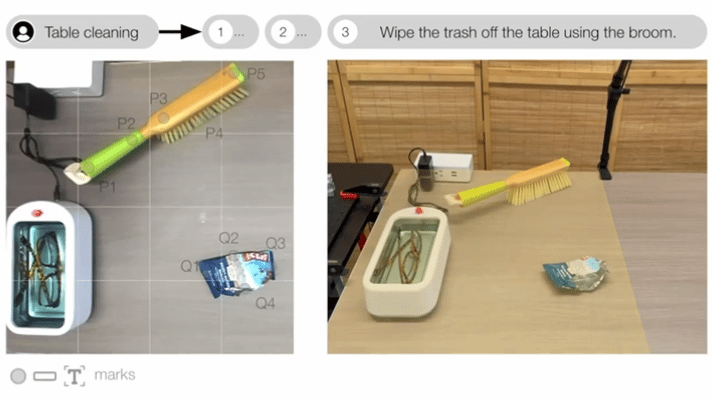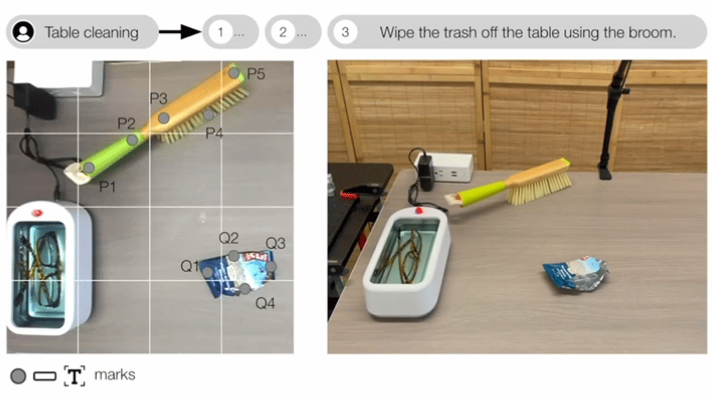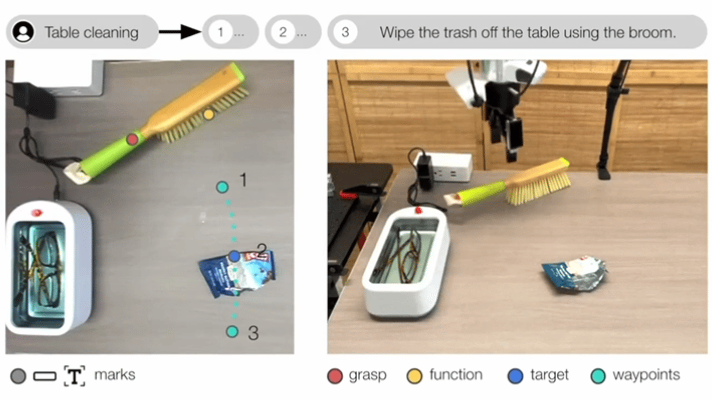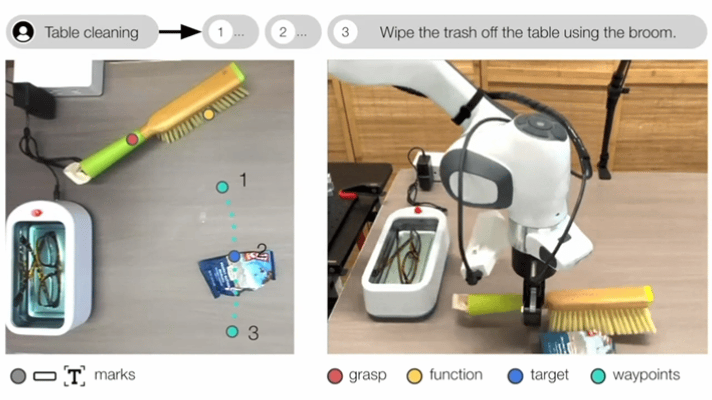
▲MOKA: Open-World Robotic Manipulation through Mark-Based Visual Prompting
三维场景表示:把感知变成“行动提案”
三维信息的价值,经常被误解成“把环境重建得更漂亮”。
但在操作任务里,三维表示更多是为了把感知变成“可行动的结构”:
空间关系、抓取候选、碰撞风险、物体相对位置等。
它未必直接输出控制,但可以为上层提供更可靠的行动提案,让计划不至于建立在脆弱的二维假设上。
典型研究如RoboSplat(RSS 2025),利用 3D 高斯散射 (3DGS) 生成新颖演示的框架。
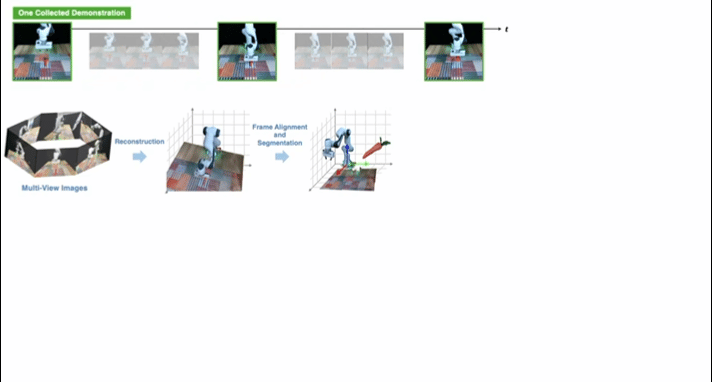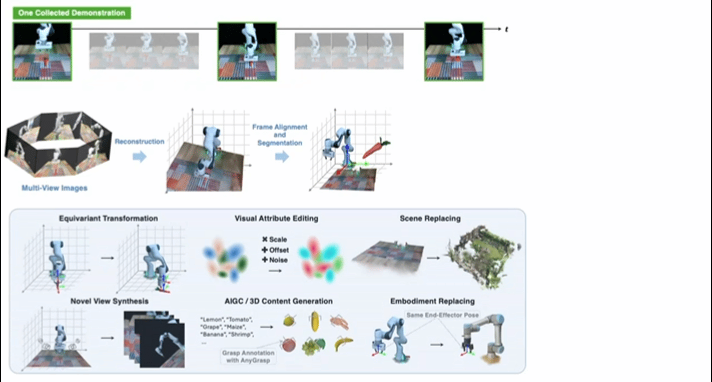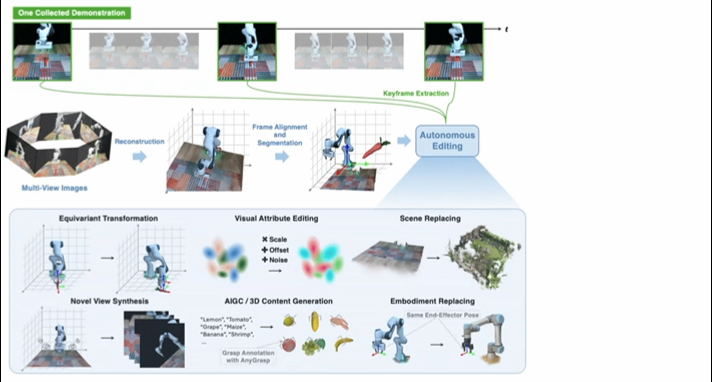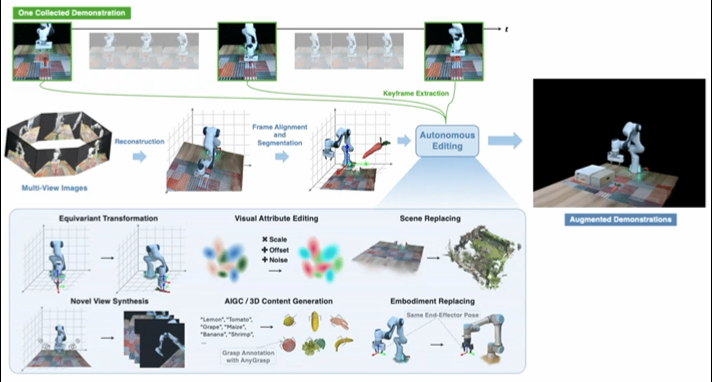
▲Novel Demonstration Generation with Gaussian Splatting Enables Robust One-Shot Manipulation
小结
上述6种研究路线可以理解成两组:
- 主干方向:用语言模型/多模态模型做任务规划、把计划写成可执行流程(类似脚本)、以及面向物理可行性的运动规划;
- 支撑能力:学习“哪里能抓、哪里能推”(可操作区域/可操作性),以及用三维场景结构帮助规划与决策。

▲图3|上层规划方法的分类图。
02 下层在做什么?
如果上层解决的是“做什么、按什么顺序做”,下层解决的就是“每一步怎么做得稳”。
因此下层做的就是:把“看见与理解”变成“稳定可执行的动作”。
为了把下层讲清楚,可以把它拆成三件事:
- 输入怎么组织?
- 中间表示怎么学?
- 动作策略怎么输出?
这三件事共同决定了机器人能不能在真实世界里稳定执行。
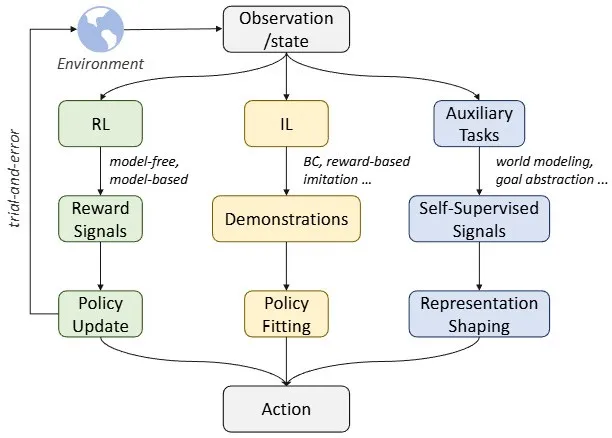
▲图4|下层操作控制的三种学习路线对比:强化学习、模仿学习和辅助任务学习。
输入怎么给:机器人到底“用什么感官”做决策
真实环境里,机器人很少只靠摄像头。
触觉、本体感受(关节角度、力矩)、甚至声音,都可能决定操作是否成功。
尤其在接触任务中,视觉只能告诉你“看起来碰到了”,触觉才能告诉你“到底压没压到、滑没滑、卡没卡”。
因此,下层的第一步往往不是追求更大模型,而是把输入组织得合理:
哪些传感是关键,怎么融合不同频率和噪声的信号,什么时候该相信触觉而不是视觉,这些会直接影响动作的稳定性。

▲图5|基于触觉的动作模型结构概览。当机器人需要抓、拧、插、按这类强接触操作时,光看图像往往不够用,触觉能告诉它“有没有滑”“压得够不够”“是否卡住”。这张图总结了利用触觉信号来生成动作的一类典型模型结构与处理流程
中间表示怎么学:让机器人有“内功”,别每次都从像素现算
第二步是学习一种稳定、可复用的内部表示,让策略不必每次从原始画面“现想现做”。
这种内部表示越扎实,越不容易被光照变化、遮挡、物体外观差异带跑偏,也更容易把经验迁移到新物体、新环境。
通俗点说,就是让机器人形成一种“看得更本质”的状态理解,而不是被表面纹理牵着走。
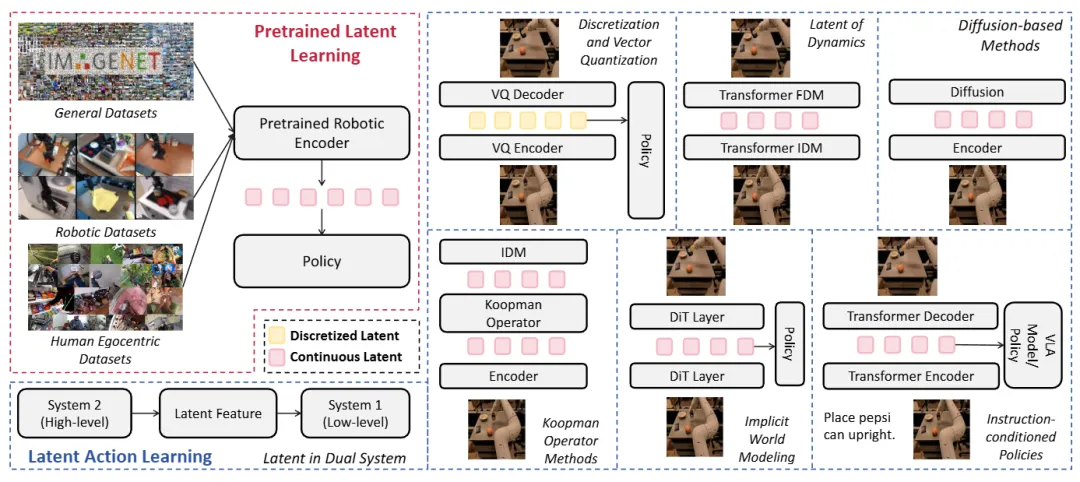
▲图6|“潜在表示学习”的整体思路示意。
核心想法是:先把高维的感知输入(图像、传感信号等)压缩成更稳定、更可复用的“内部状态”,再基于这个内部状态生成动作。
图中也展示了两种常见做法:
- 离散的内部状态:把动作或状态变成一组“可选的符号/类别”;
- 连续的内部状态:用连续向量表达更细腻的动作与状态变化。
这样做的目的,是让动作生成更稳定、对环境变化更不敏感。
动作怎么生成:从“下一步怎么动”走向“整段动作怎么走”
第三步是输出动作。
一个明显趋势是:策略不再只预测“下一步怎么动一点”,而更倾向于生成“整段动作轨迹”,把时间依赖、连续性和不确定性一起建模进去。
这样做的好处是:动作会更平滑、更连贯,也更容易在真实执行时保持稳定。
背后的直觉很简单:现实里的操作不是一个点动作,而是一段连续过程。能生成“整段合理动作”,通常比只会“走一步看一步”更可靠。
难点何在?门槛在于四个“硬”问题:
- 更通用的体系架构(长期任务也能稳定执行);
- 更可持续的数据获取与迁移(数据稀缺与仿真差距);
- 更强的多模态物理交互能力(触觉与复杂材料不可缺席);
- 以及把安全与协作当作第一约束(关键时刻知道如何回退、如何不伤人不伤物);
这些问题不解决,模型再大也很难长期可靠地“干活”。
03 总结
这篇综述用“两层结构”去看基于学习的机器人操作,明确现代基础模型在机器人操作设计空间中的定位——
- 上层关注任务组织与结构化决策:怎么拆解、怎么规划、怎么对齐空间与动作;
- 下层关注把动作落到物理世界:感知输入、内部表示、动作生成。
这一框架将注意力从“模型是什么”重新导向“问题是什么”,聚焦机器人操作的本质功能而非表面的模型命名。
它提示研究者,在追逐新范式之前,或许应先回答:我所改进的,究竟是机器“思考”任务的能力,还是其“执行”动作的可靠性?
最后一句:真正的技术进步,必然始于对根本性问题的清晰洞察,而非对技术“热点”的被动追随。
Ref:
论文题目:Embodied Robot Manipulation in the Era of Foundation Models:Planning and Learning Perspectives
论文作者:Shuanghao Bai, Wenxuan Song, Jiayi Chen, Yuheng Ji, Zhide Zhong, Jin Yang, Han Zhao, Wanqi Zhou, Zhe Li, Pengxiang Ding, Cheng Chi, Chang Xu, Xiaolong Zheng, Donglin Wang, Haoang Li, Shanghang Zhang, Badong Chen
论文地址:https://arxiv.org/pdf/2512.22983
项目地址:https://github.com/BaiShuanghao/Awesome-Robotics-Manipulation

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 6
6 0
0- 0



 已为社区贡献88条内容
已为社区贡献88条内容

所有评论(0)