深度强化学习算法DDPG、TD3与SAC在MuJoCo机器人实验环境下的研究
本框架面向机器人连续控制研究场景,基于 MuJoCo 的 HalfCheetah-v2 环境,提供四种主流深度强化学习算法(A3C、DDPG、SAC、TD3)的完整训练-测试-可视化闭环。开发者可在零侵入的前提下,一键切换算法、批量跑实验、自动输出曲线与统计报表,满足论文复现、算法对比、工程落地三类需求。无论是做学术研究还是工程交付,开发者只需聚焦算法核心逻辑,其余训练、评测、对比、可视化均可一键
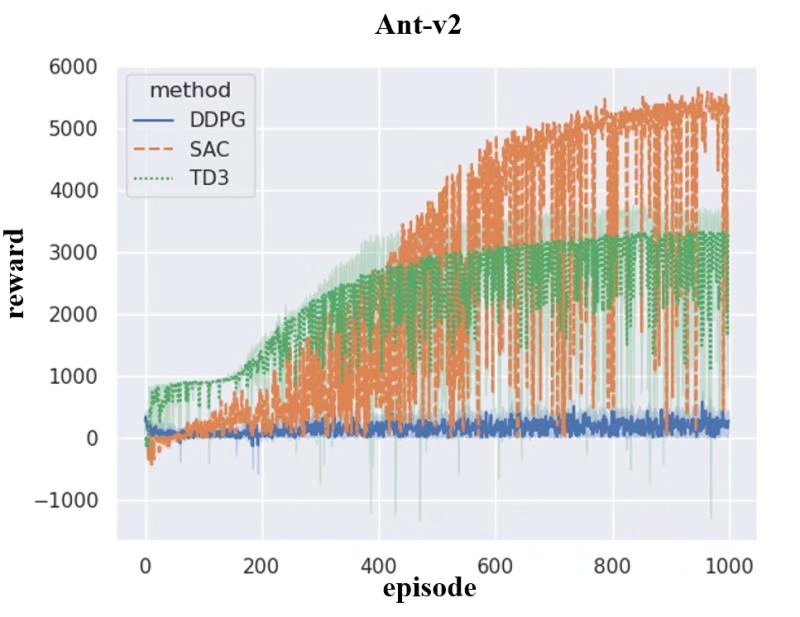
深度强化学习算法:DDPG TD3 SAC 实验环境:机器人MuJoCo
HalfCheetah-v2 深度强化学习实验框架功能说明书
——A3C / DDPG / SAC / TD3 一体化训练与评测平台
- 产品定位
本框架面向机器人连续控制研究场景,基于 MuJoCo 的 HalfCheetah-v2 环境,提供四种主流深度强化学习算法(A3C、DDPG、SAC、TD3)的完整训练-测试-可视化闭环。开发者可在零侵入的前提下,一键切换算法、批量跑实验、自动输出曲线与统计报表,满足论文复现、算法对比、工程落地三类需求。
- 总体架构
----------------------------------------------------------------
| 算法层 | 公共组件层 | 工具层 | 入口层 | 可视化层 |
----------------------------------------------------------------
- 算法层:a3c1~3、ddpg1~3、sac1~3、td31~33 共 12 个独立子工程,彼此无依赖,可并行开发。
- 公共组件层:ReplayBuffer、OrnsteinUhlenbeckActionNoise、SharedAdam、GaussianPolicy 等可复用模块。
- 工具层:seaborn、matplotlib、pandas、tensorboardX 自动绘图与表格生成。
- 入口层:runmain.py 提供“python runmain.py”一键启动;test.py 提供“python test.py”一键评测。
- 可视化层:plot.py 与 plot-without-a3c.py 自动读取所有 xlsx,输出对比曲线。
- 核心能力
3.1 零配置启动
每个算法目录内置默认超参,首次克隆即可运行:
$ cd sac1 && python runmain.py
3.2 多进程/多 GPU 透明加速
- A3C 基于 torch.multiprocessing,自动检测 CPU 核心数,共享全局网络。
- DDPG / SAC / TD3 默认走 cuda:0,支持通过 args.cuda 切换 CPU。
3.3 自动经验回放与噪声注入
- ReplayBuffer 统一采用循环队列实现;ddpg 系列内置 OrnsteinUhlenbeckActionNoise,sigma、theta 可配置。
- SAC 支持 Gaussian 与 Deterministic 双策略,自动缩放动作区间。
3.4 训练-测试解耦
训练阶段仅保存网络权重(.pkl / actor *critic),不依赖环境;测试阶段可脱离 MuJoCo 许可证,在纯 CPU 容器内复现曲线。
3.5 实时日志与断点续训
- 所有算法均按 Episode 粒度实时打印:Episode、TotalSteps、Reward、Loss。
- SAC 与 TD3 内置 tensorboardX,支持 lr、alpha、Q-loss 等 10 余项指标在线监控。
- 训练异常中断后,手动加载 /models/.pkl 即可续训。
3.6 批量实验与统计
- 同一算法 3 组随机种子独立运行,自动生成 sac.xlsx / ddpg.xlsx / td3.xlsx。
- plot.py 一次性读取 12 组数据,输出均值±标准差阴影曲线,直接用于论文插图。
- 目录与文件语义
HalfCheetah-v2_merged.txt
├── a3c1~3 # 异步优势演员-评论家,共享 Adam 优化器
├── ddpg1~3 # 深度确定性策略梯度,双网络延迟更新
深度强化学习算法:DDPG TD3 SAC 实验环境:机器人MuJoCo
├── sac1~3 # 柔性演员-评论家,可自动调节温度系数 α
├── td31~33 # 双延迟 DDPG,双 Q 网络缓解过估计
├── plot.py # 全算法对比图(含 A3C)
└── plot-without-a3c.py # 仅对比 DDPG、SAC、TD3,曲线更清爽
- 关键超参速查
| 算法 | learning rate | batch | replay size | policy noise | temperature α |
|---|---|---|---|---|---|
| A3C | 1e-5 (SharedAdam) | — | — | — | — |
| DDPG | Actor 1e-4 / Critic 1e-3 | 64 | 1e6 | OU σ=0.2 | — |
| SAC | 3e-4 | 256 | 1e6 | — | 0.2 (可自调) |
| TD3 | 3e-4 | 256 | 1e6 | 0.2 * max_action | — |
- 典型工作流
Step1 训练
$ cd sac1
$ nohup python runmain.py > train.log &
Step2 监控
$ tensorboard --logdir runs/
Step3 测试
$ python test.py # 生成 TestSAC.png + 100 条 Episode 得分
Step4 批量对比
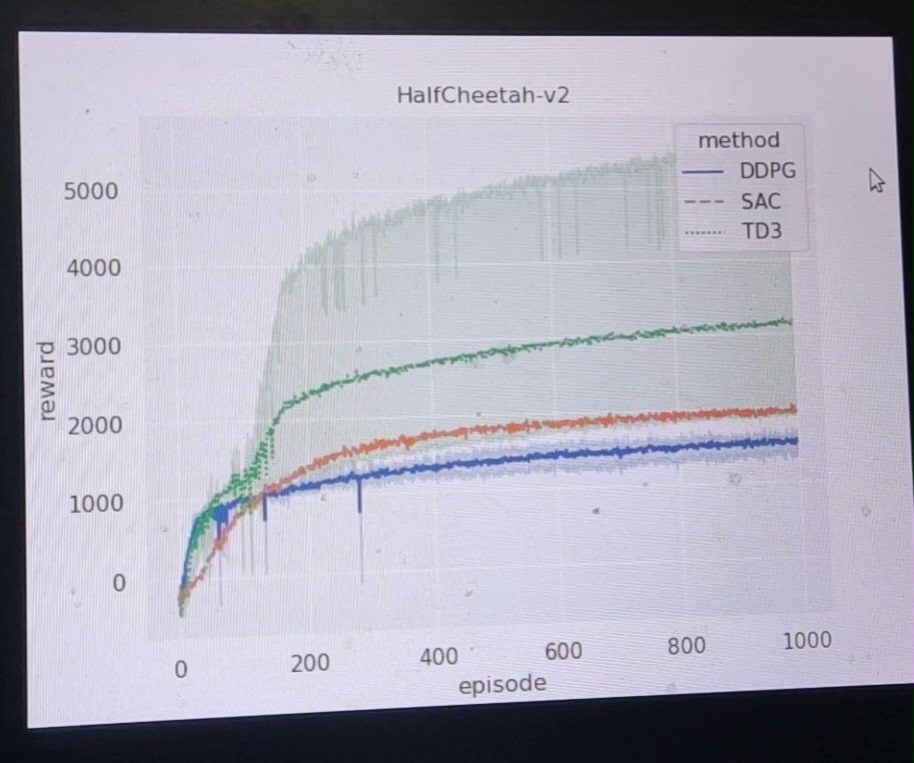
$ python ../../plot.py # 输出 HalfCheetah-v2.png
- 扩展指南
7.1 新增算法
- 新建目录 algoX1,实现 train()/test() 接口;
- 在 plot.py 的 get_data() 中追加读取 algoX1.xlsx;
- 无需改动其他算法代码,即可自动并图。
7.2 更换环境
- 将 runmain.py 中 env_name 由 HalfCheetah-v2 改为 Ant-v2 等;
- 检查 state/action 维度是否匹配,必要时调整网络输入输出尺寸;
- 若动作区间变化,需同步更新 GaussianPolicy 的 action_scale。
7.3 分布式训练
- A3C 已原生支持多进程,可扩展至数十核;
- SAC/DDPG/TD3 若需多卡,可在 replay_buffer.sample() 后使用 DistributedDataParallel 包装。
- 常见坑与排查
| 现象 | 根因 | 快速修复 |
|---|---|---|
| MuJoCo 报错 “Missing key” | 许可证未安装 | 按官方文档放置 mjkey.txt |
| A3C 收敛极慢 | 学习率过小 | 调大 SharedAdam lr 至 1e-4 |
| DDPG 曲线抖动大 | OU 噪声 σ 过高 | 降至 0.15 或改用 TD3 |
| SAC 动作饱和 | α 初始值太大 | 开启 automaticentropytuning |
- 版本与依赖
- Python ≥ 3.8
- PyTorch ≥ 1.11
- gym 0.21 + mujoco-py 2.1.2.14
- seaborn ≥ 0.11
- pandas ≥ 1.3
- 结语
本框架以“算法独立、数据互通、图表自动化”为设计宗旨,将散落的脚本沉淀为可维护、可扩展、可复现的实验平台。无论是做学术研究还是工程交付,开发者只需聚焦算法核心逻辑,其余训练、评测、对比、可视化均可一键完成,真正做到“写完即毕业,跑完即上线”。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)