基于LangChain、Streamlit框架,结合云平台的大模型构建聊天机器人(含本地部署、云服务器部署教程)
本文介绍了如何在云服务器上部署基于阿里云百炼大模型qwen-max的聊天机器人。文章首先展示了简洁的前端界面效果,随后详细说明了所需工具的安装步骤,包括WSL环境配置、pip工具更新以及LangChain、Streamlit等关键包的安装。核心代码部分重点讲解了get_session_history和get_res两个关键函数的实现逻辑,以及如何通过Streamlit构建交互式Web应用界面。最后
文章目录
尝鲜
先看效果:
前端界面很简洁,可将历史问答记录依次罗列,调用的是阿里云百炼的大模型:
qwen-max
正好我拥有一台云服务器,于是就在上面部署了这个聊天机器人,大家可以去体验一番:聊天机器人抢先用
注:本文不会介绍太多在云平台部署的操作,但也会提供部署所需工具以及相应代码和解释。
1、工具安装
我使用的是WSL工具,运行ubuntu环境,版本是Ubuntu 22.04.5LTS。
打开终端,使用apt安装pip工具,并用pip来安装所需的包:
- 更新apt并下载pip:
sudo apt update && sudo apt install python3-pip - 更新pip工具:
pip install --upgrade pip - 下载streamlit、LangChain包:
pip install streamlit langchain langchain-community- 这里的云平台选择阿里云的百炼,所以还要下载一个包:
pip install dashscope
简单介绍一下这些包的作用:
- langchain:大模型应用开发核心框架,提供链、记忆、检索等功能
- langchain_community:LangChain社区贡献组件,含第三方工具、模型集成
- dashscope:阿里云官方的大模型开发Python库,用于调用通义千问(Qwen)等阿里系大模型的API
2、代码及解释
源代码如下:
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_community.llms import Tongyi
from langchain_core.chat_history import InMemoryChatMessageHistory
from langchain_core.prompts import ChatPromptTemplate
import streamlit as st
api_key="#" # 这里要替换自己阿里云模型应用的API_KEY哦
# 定义模型
model = Tongyi(model="qwen-max", api_key=api_key)
# 保存历史
store = {}
def get_session_history(session_id: str) ->InMemoryChatMessageHistory:
if session_id not in store:
store[session_id] = InMemoryChatMessageHistory() # 初始化空历史
return store[session_id]
def get_res(prompt):
# 定义prompt
pro = ChatPromptTemplate.from_messages([
("system", "你是一个Python助手,能够思考后回答用户的问题,精准迅速。"),
("human",f"{prompt}")
])
# 构建基础链
base_chain = pro | model
chain = RunnableWithMessageHistory(
runnable=base_chain,
get_session_history=get_session_history,
input_messages_key="input",
history_messages_key="chat_history"
)
# 发送请求
res = chain.invoke(
{"input": prompt},
config={"configurable": {"session_id": "user_001"}}
)
return res
if "message" not in st.session_state:
st.session_state["message"] = []
st.title('Qwen-max对话机器人')
st.divider()
# 消息输入框
prompt=st.chat_input("请输入你的问题:")
# 保存历史对话
if prompt:
st.session_state["message"].append({
"role": "user",
"content": prompt
})
for msg in st.session_state["message"]:
st.chat_message(msg["role"]).markdown(msg["content"])
with st.spinner("AI思考中..."):
ai_res = get_res(prompt)
st.chat_message("assistant").markdown(ai_res)
history = get_session_history("user_001").messages # 获取当前会话的所有消息
for msg in history: # 遍历消息并编号
role= "user" if msg.type == "human" else "assistant"
if role == "assistant":
st.session_state["message"].append({
"role":role,
"content":msg.content
})
这里调用的包不同于25年底的旧版本,而是使用RunnableWithMessageHistory,调用千问模型并根据用户session将对话分别存储起来。
源代码部分的两个函数需要特别解释一下:
- get_session_history
- get_res
2.1 get_session_history
此函数是Langchain中的chain必须传的函数参数,用于存储和获取用户与模型的互动记录。
存储的过程框架会帮我们实现,我们只需要自定义该函数即可:
- 注意参数列表的类型指定以及返回值的指定不可省略
- 逻辑很简单:如果存储空间中没有用户的信息,初始化空历史后返回即可;若有,那就直接返回。
2.2 get_res
这个函数是调用云平台大模型的核心函数。
定义模型的代码:model = Tongyi(model="qwen-max", api_key=api_key)
此处的api_key需要前往阿里云百炼平台的密钥管理导航获取,当然应用的模型要选择qwen-max系列。
调用步骤为:
- 定义提示词prompt,一定要使用
ChatPromptTemplate的相关方法,不然构建基础链会报错。 - 构建基础链:
base_chain = pro | model - 构建
chain,注意必传参数:- 函数:
get_session_history - 基础链:
runnable
- 函数:
- 发送请求,注意在config中给出
session_id的键值。
到此为止,LangChain部分结束,说了这么多就是为了调用云平台的大模型来返回应答结果罢了。
2.3 Streamlit 代码
Streamlit框架能够将数据分析和模型展示转化为交互式的Web应用。
这里解释一下代码中用到的相关代码:
st.title():设置标题st.divider():分隔符st.chat_input():聊天输入框st.session_state:用于保存对话记录的列表st.spinner():等待提示框(AI思考中…)st.chat_message().markdown():问答输出,.markdown(内容)是为了格式化- 第一个参数列表如果传入"user",前端页面会显示用户图标
- 第一个参数列表如果传入"assistant",前端页面会显示机器人图标
将这些方法有机结合,就可以做出自己的专属聊天机器人!
3、业务逻辑
至此,后端数据以及前端页面都有了,接下来就是二者结合的业务逻辑了:
- 初始化 message列表。
- 用户输入问题后,立即将"user"、用户问题存入列表中。
- AI响应之前,将message列表中的数据遍历,根据
role显示不同图标,输出问题或者AI应答。 - AI响应(调用方法get_res),将结果以机器人的图标输出到页面上。
- 获取历史会话记录,单独将AI应答结果存入message列表中
经过这样一个流程,我们就可以让网页保持对话记录,并不断地支持“用户提问,AI应答”的模式。
4、本地部署
本地部署非常容易,流程如下:
- 打开终端,进入到源代码文件(假如文件名为
chain_lit.py)的目录 - 执行命令:
streamlit run chain_lit.py - 第二步后,终端会给出两个地址供我们选择:
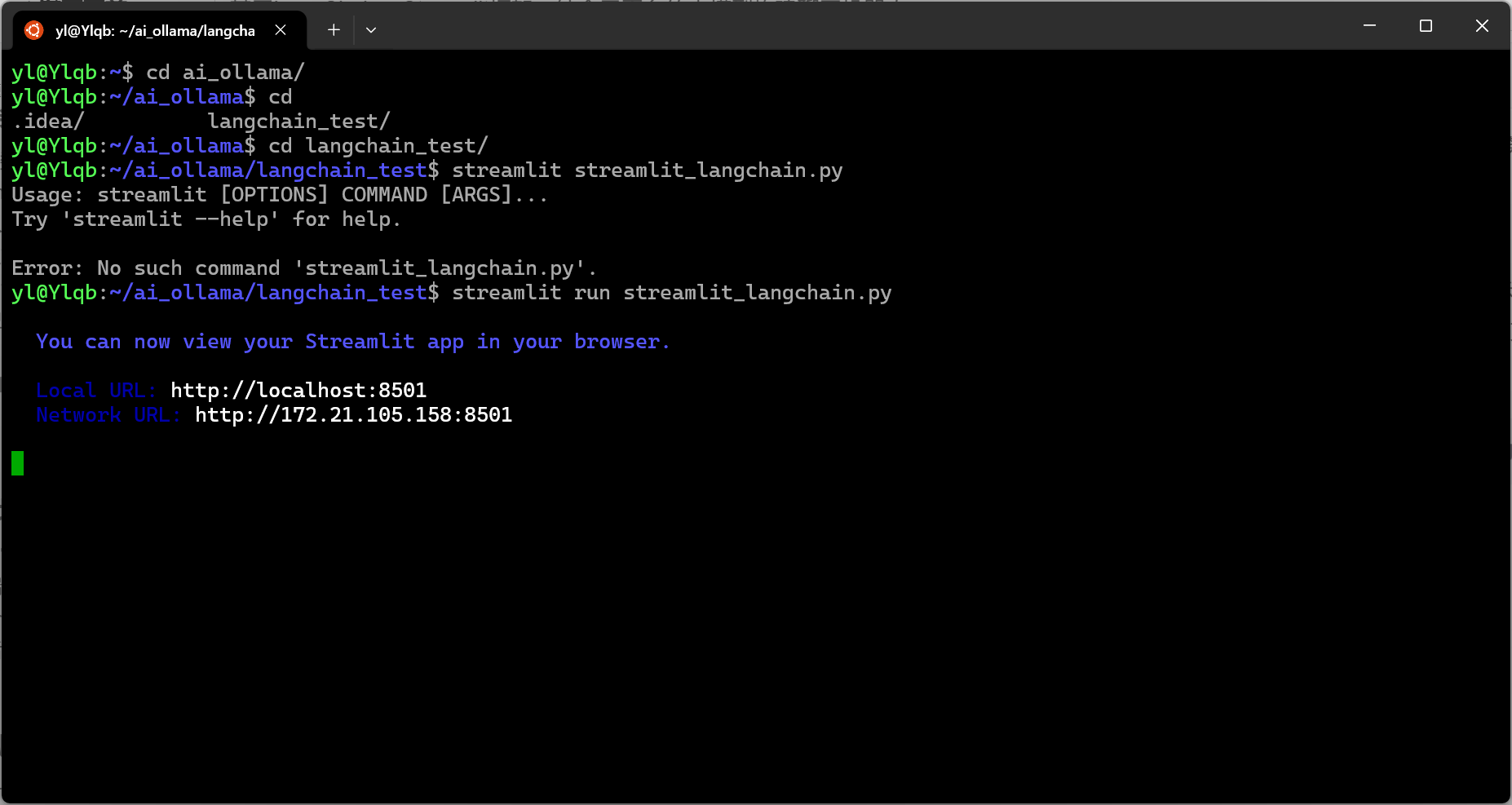
- 复制localhost所在的地址粘贴到浏览器上即可访问聊天机器人;若是选择下面的地址,就需要在ubuntu中添加防火墙端口,命令如下:
sudo ufw allow 8501/tcp # 仅允许TCP流量(推荐)- 此时,第二个地址也可以成功访问聊天机器人。
5、云服务器部署流程
- 在云服务器上准备好Langchain、Streamlit的包
- 源代码文件传云服务器(可使用scp命令发送,如:
scp 代码.py ubuntu@公网IP:/home/ubuntu)- 我的云服务器是
ubuntu版本
- 我的云服务器是
- 启动Streamlit服务,加入文件名为streamlit_app.py:
nohup streamlit run streamlit_app.py --server.port 8501 --server.address 0.0.0.0 &- 记得在云服务器的防火墙规则里增加8501端口放行
做完这些之后,无论是电脑浏览器输入公网IP:8501(比如:http://111.111.111.111:8501),
还是手机浏览器输入就都可以进入到这个聊天机器人的问答界面。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)