StageACT——基于CVAE的多阶段ACT:把开门任务分为五个阶段,且做好分段标注以引导低层策略逐一执行
本文提出StageACT框架,通过阶段条件化模仿学习解决人形机器人开门任务中的长时程、部分可观测挑战。作者发现将任务分解为五个自然阶段(寻找把手、接近把手等)并显式标注阶段标签,能有效消除视觉歧义并实现失败恢复。该方法基于ACT架构,采用CVAE结构生成动作序列,并通过阶段条件向量为策略提供时间上下文。实验表明,该框架仅需135次人类示范即可实现完全自主的行走-开门操作,无需外部感知或门的先验信息
前言
因上一篇文章解读DoorMan时,注意到了StageACT,故本文解读StageACT
对于其中的全身遥操,和《TrajBooster——通过“轨迹中心学习”提升人形全身操作能力的VLA:把智元轮式数据迁移到宇树G1上,先二次预训练后微调(免去动捕)》中用的方法 类似
1.2.4 后训练(即微调):先遥操采集数据(上半身VR控制、下半身遥控器控制),后微调VLA
- 遥操作数据采集
对于下肢动作
作者采用与相同的训练方法来生成下肢动作
然而,与分层模型不同,
的控制指令来源于人类操作员通过遥控操纵杆进行操作
作者采用文献[34-Opentelevision] 中提出的基于Apple Vision Pro 的遥操作框架来实现运动学映射
且使用两个手腕RGB 相机(左侧和右侧)以及一个头部RGB 相机收集视觉数据- 在目标人形机器人上微调VLA
收集到的远程操作数据被用于对已预训练的VLA模型进行后续训练,通过最小化公式8中定义的流匹配损失来实现
第一部分
1.1 引言与相关工作
1.1.1 引言
如原论文所说,近期的研究进展已经在类人灵活性方面取得了令人瞩目的成果 [6]–[9],并在多样化任务上的泛化能力方面展现出优秀表现 [10]–[13]
然而,运动和操作领域的进展在很大程度上仍是各自为政,缺乏统一融合。尤其是在操作方面,现有工作往往集中于抓取与放置这类任务,而这仅覆盖了现实世界中所需的、包含丰富接触交互的任务的一小部分
- 开门这一动作带来了超出典型操作的挑战。机器人必须推理关节结构的可供性,因为门与把手的运动都被约束在预定义的轴上。这类富接触的交互需要对动力学进行既精确又鲁棒的控制,尤其是在高自由度的仿人系统中 [1]
- 此外,该任务本质上是非马尔可夫的且仅部分可观测。关键信息(例如把手的锁扣状态或门的铰接/开启方向)无法被直接观测到 [2], [14]
因此,在视觉上相似的观测可能对应不同的状态,从而在诸如解锁这类关键状态转移过程中导致错误
如果机器人对其自认为的状态产生错误感知,将会造成不利影响,而这种歧义尤其在长时域任务中会引发模式坍塌 [15]
————
基于人类示教的遥操作可能会使问题进一步恶化,因为人类操作者依赖于对任务进度的内部记忆,而这种记忆未必能通过传感器直接观测到
早期的解决方案(包括 DARPA 机器人挑战赛中的方法)依赖于对几何结构、接触点以及模块化控制器的显式建模 [1], [16]
近来,基于学习的方法表明,模仿学习或强化学习可以隐式地捕获这些复杂性,已经在四足机器人和轮式操作器上展示了开门操作 [3], [4], [14]
然而,这些系统往往假设事先已知门的参数,或依赖外部感知(例如 AR 标签),且很少被扩展到人形机器人。值得注意的是,现有的人形机器人开门演示大多仍然是遥操作的 [5]
尽管开门这一任务本身涉及诸多复杂性,但对人类来说它似乎不过是再普通不过的日常行为
- 作者的核心洞见源自人类自然而然采用的策略:将这一长时域任务分解为若干阶段,例如接近、抓取、解锁以及推门。这些阶段不仅构成了动作在时间上的顺序结构,还反映了底层接触动力学的转变
且作者通过显式地将低维的任务阶段信息作为条件,输入到低层模仿学习策略中来实现这一思想。尽管这只是对策略结构的一个简单增添,但作者观察到一个出人意料的效果:基于阶段的条件显著提高了成功率 - 具体而言,基于阶段条件的策略可以利用状态中的时间上下文,对原本在观测上相同、难以区分的情形进行消歧;同时,当在某一阶段发生失败时,在状态提示的驱动下,该策略能够重新进入较早的阶段,从而涌现出恢复行为
这使得该策略相比于通常只具有由少量状态构成的有限上下文窗口的标准模仿学习方法,更加有效地应对开门任务的长时域、部分可观测特性
总之,来自FieldAI的作者宣称

- StageACT首次展示了一种用于类人机器人开门的自主行走-操作策略,该策略完全基于人类示范进行训练,而无需依赖外部感知或关于门的特权信息
- 且提出了一个面向长时程任务的阶段条件化模仿学习框架,并表明阶段条件化策略显著优于标准行为克隆,尤其体现在解决观测歧义和实现失败恢复方面
- 其论文地址:StageACT: Stage-Conditioned Imitation for Robust Humanoid Door Opening
作者包括
Moonyoung Lee∗ , Dong-Ki Kim, Jai Krishna Bandi, Max Smith, Aileen Liao∗ , Ali-akbar Agha-mohammadi, Shayegan Omidshafiei- 其项目地址:icradooropen.github.io/icradooropen
其GitHub地址:截止到26年1月中旬,暂未开源
1.1.2 相关工作
首先,对于富接触人形机器人行走-操作
近期在人形机器人全身控制方面的研究已经展示出令人印象深刻的敏捷性,例如跳跃 [6] 以及下蹲拾取物体 [17], [18]
当前主要有两类方法:
- 分解式框架,将下肢运动与上肢控制相分离 [17], [19]–[21]
- 以及单体式框架,在所有关节上训练单一的强化学习(RL)策略 [6]–[8], [11], [22]
单体方法可以产生鲁棒且多样的动作,而分解方法则能够提供对上肢的精确控制,这对于接触交互至关重要 [5]
为了获取上肢数据,现有工作使用了
- 来自 MoCap 的动作重定向 [11], [23]
- 基于外骨骼的遥操作 [17]
- 结合动作先验的基于视觉的跟踪 [8]
- 或基于 VR 的遥操作[18]–[20]
这些方法在动作模仿和全身协调方面是有效的,但大多侧重于跟踪参考轨迹,使得富接触的行走-操作任务仍然是一个尚未解决的挑战
- 总之,开门很好地体现了富接触任务的挑战 [1]。四足机器人和轮式底盘在通用行走-操作(loco-manipulation)方面已经取得了显著进展 [24]–[26],但直接处理与门交互的工作却寥寥无几
————
以往的方法依赖显式状态估计或对门参数的先验知识,例如使用 AR 标记进行状态跟踪,或对关节结构模型作出假设 [2]、[3]、[14]
在真实环境中开启多种类型门的研究在实现泛化方面展现出早期潜力 [4],但其平台仅限于机动性受限的轮式机器人 - 相比之下,人形机器人在施加接触力的同时还必须保持平衡,从而使问题显著更加困难
尽管开门是一个典型的基准任务 [1],但在人形机器人上的相关研究仍然十分稀缺,且最新工作 [5] 仅在遥操作设置下展示了开门,而非完全自主的操作
其次,对于长时序操作中的状态编码
模仿学习(Imitation Learning, IL)已经取得了显著成果,但将这些方法扩展到长时域、多阶段任务仍然十分困难
- 一种常见策略是将任务分解为针对各个阶段的策略 [27],或采用分层框架 [28],由高层控制器对基本技能进行串联,并在失败后重试
尽管这种分解在实践中有效,但其可扩展性较差,因为整体成功高度依赖于大量专门化组件 - 因此,近期工作更强调基于辅助输入进行条件化的单一通用策略,这类策略在可扩展性和泛化性方面表现更好 [29]
条件信号的形式十分多样:在更一般的情况下,语言指令可以用来指定子目标或纠正信息 [10], [29], [30]
而在更显式的设定中,阶段或子目标标签可以在时间上为策略提供锚定 [15], [28]
总之,在接触密集的场景中,引入条件信息尤为重要,因为原始的视觉—运动输入往往难以捕捉接触模式之间那些微妙的过渡。为了解决这一问题,可以引入多模态信号,例如力、力矩或触觉反馈被纳入系统中,可以通过传感器融合隐式地实现[31], [32],也可以通过阶段预测器显式地实现 [15],以消除阶段之间转换的歧义
表示方式也各不相同:
- 有的方法为技能使用离散的 one-hot 标记 [33]
- 而另一些则采用连续的进度变量来表示任务完成度
在仿人机器人场景中,条件化通常通过显式状态机来实现,该状态机在用于箱体操作的强化学习(RL)训练技能之间切换 [22],或遵循预定义的接触序列 [7]
相比之下,作者的方法只使用一个仅基于阶段输入进行条件化的单一策略,避免了在运动和操作之间进行显式划分
1.2 前置工作数采:全身遥操作
1.2.1 全身遥操作
开门任务需要先旋转带弹簧的门把手以解除门闩,然后再向前推门,因此这是一个具有两自由度的交互过程。由于门把手和门本身都通过弹簧预张紧,如果没有将把手旋转超过某一阈值,或者在推门之前手发生滑脱,门闩就会重新锁上
由此,该任务不是准静态的,并且要求进行全身协调,以同时管理接触力、门的转动以及主体的行走运动
- 在执行过程中,人形机器人用左手拳头的下侧压住门把手以施加扭矩并解除门闩
- 一旦解锁,它就用右手推门并行走通过,从而完成任务
作者的远程操作系统使用配备 Dex-3 手的 Unitree G1 人形机器人,并搭配 Apple Vision Pro (AVP) 头显,通过捕捉操作员的姿态并利用逆运动学(IK)将其映射到机器人上
如下图图2所示,将上半身和下半身控制分离可提供更自然的人机接口,使两名操作员能够共同为移动-操作任务采集示教数据
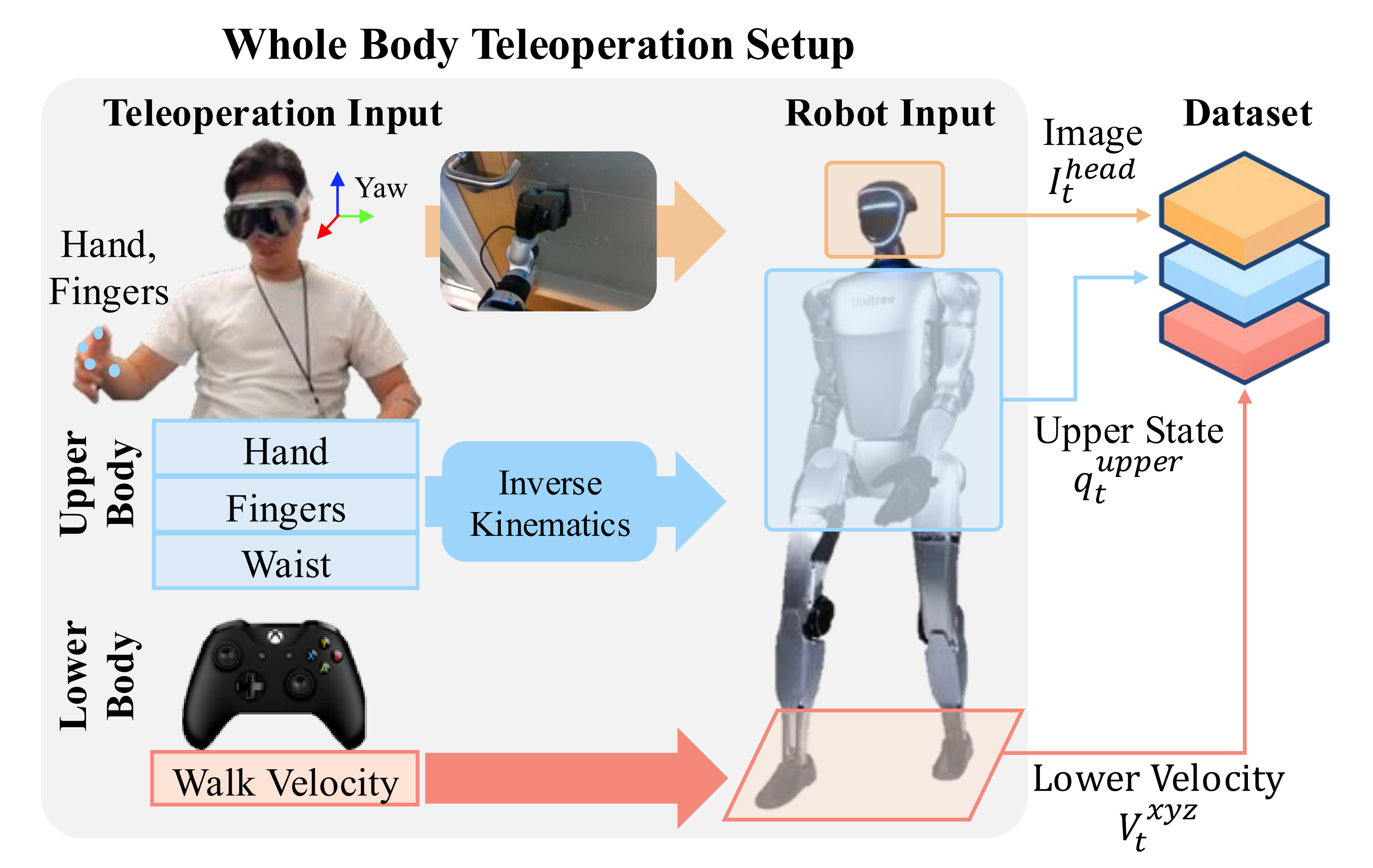
- 该系统构建在文献 [19-Open-television] 的基础之上,后者侧重于桌面场景的远程操作,而作者将其扩展以支持行走
——————
头戴式 RealSense 相机将第一人称视角图像流式传输到 AVP,而人手姿态到机器人手臂的重定向则通过闭环 IK『Pinocchio [34-The Pinocchio C++ library – a fastand flexible implementation of rigid body dynamics algorithms andtheir analytical derivative]』来解决,人类手指到 Dex3 的重定向则是通过一优化工具 [35-AnyTeleop]
最后
将从 AVP 的 IMU 获取的偏航角映射到机器人的腰关节 - 对于下肢控制,作者将 Xbox 控制器的输入映射到Unitree 的行走(locomotion)API,并将指令速度限制在 with in[−1,1]m/s 的范围内
————
这种解耦控制方式使操作员在行走时只需发出简单的速度指令,而精确的手臂和手部运动则依赖基于逆运动学(IK)的重定向来完成
总之,根据作者的经验,将遥操作的职责分离开来『通过摇杆进行行走控制,通过 AVP 进行操作控制』在显著减轻操作员负担的同时,仍能保持有效的全身协调
且由于门与门把手之间的缝隙很窄,将不具顺应性的笨重 Dex-3 手指插入其中并不可靠
相反,就像人类往往选择按压而不是抓握一样,作者发现用拳头底部向下按压,是一种更稳定且足够有效的门把手转动策略
1.2.2 数据集
数据集由在两天内、两个办公室环境中采集的135 次成功开门演示组成,这两个环境具有不同的光照条件、背景外观以及门的动力学特性(例如,门把手的刚度和铰链阻尼)
- 遥操作时间总计超过八小时。每次试验持续约20-30 秒,其中包含失败尝试或发生碰撞的轨迹被移除,以确保一致性
- 每条演示轨迹
表示为一个由观测-动作对
组成的序列,其中
表示时刻
的观测,
表示对应的动作
————
观测由来自头戴式RealSense 相机的RGB 图像
以及上半身关节状态组成,包括14 个手臂、14 个手部和1 个腰部关节位置
动作被定义为目标关节位置与移动速度指令的组合,从而得到
。遵循ACT [12],数据集通过将轨迹划分为具有时间跨度
的固定长度动作块,为监督学习进行结构化,使得每个训练样本将当前观测
映射到其未来动作序列
形式上,这得到数据集。这种分块过程将135 条演示扩展为成千上万的训练样本,从而提高数据效率,并使模型能够学习时间上连贯的动作预测
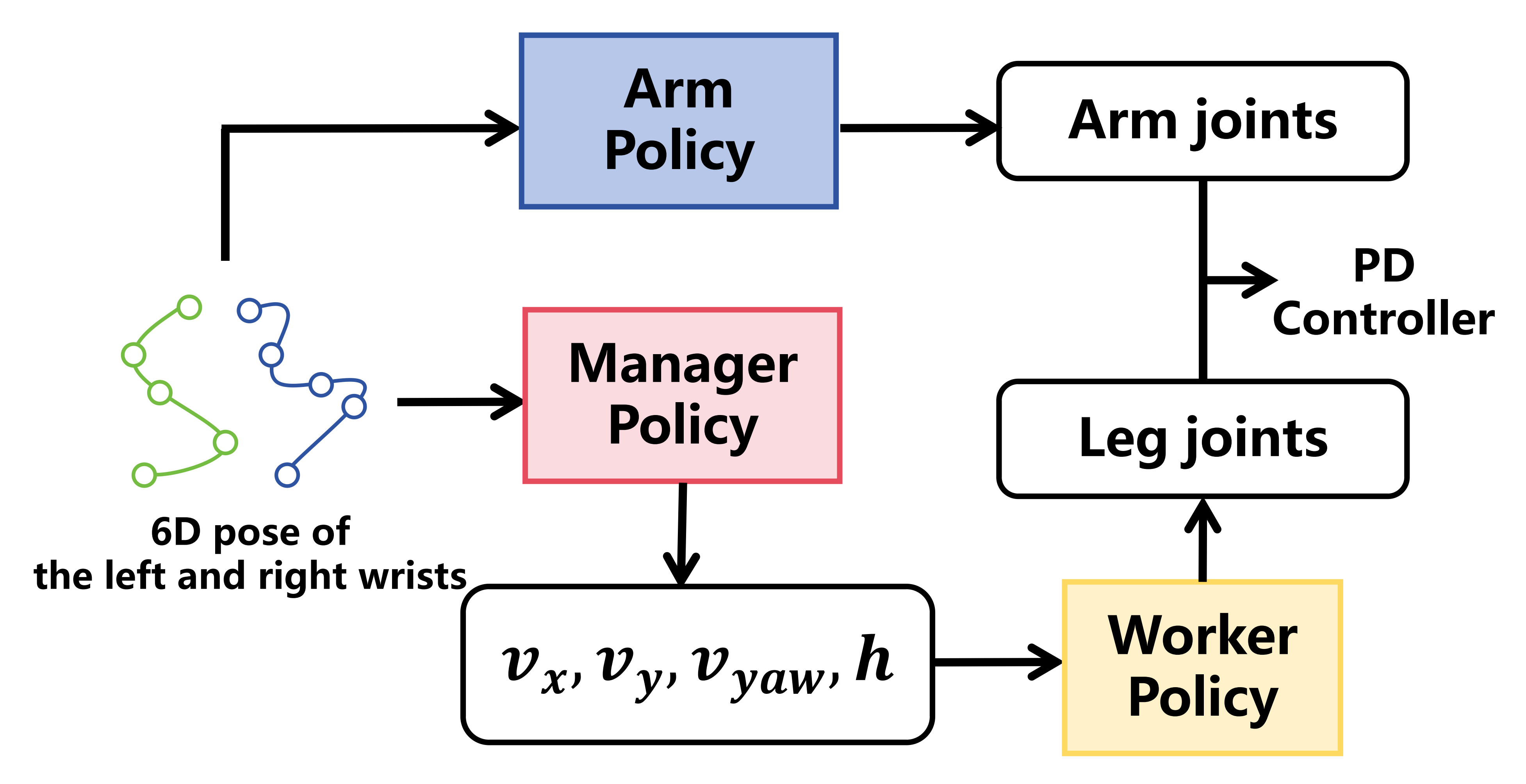
1.3 行走-操作学习框架
1.3.1 模仿学习框架
作者的方法 StageACT 构建在 Action Chunk-ingTransformer(ACT)[12] 之上,并通过引入阶段条件化(stage-conditioning),来解决长时域行走-操作任务在部分可观测性方面所面临的挑战
遵循 ACT 框架,StageACT 将模仿学习表述为一个生成建模问题。其核心思想是:不再把人类示范表示为单一的确定性轨迹,而是表示为可行动作序列上的分布
- ACT 通过将策略结构化为条件变分自编码器(CVAE)[36] 来实现这一点,并训练其在给定当前观测的条件下生成动作序列
- CVAE编码器将机器人当前的关节状态与示范的目标动作序列一起映射到一个潜在变量
中
该潜在变量捕获了人类示范的多样性,从而为策略提供了富有表现力的且超出直接行为克隆的建模能力
在测试时,舍弃编码器,并将潜在变量固定为零均值高斯分布 - CVAE解码器被实现为一种transformer,其通过自注意力聚合多种输入模态,如图3 所示
具体而言,它接收当前相机图像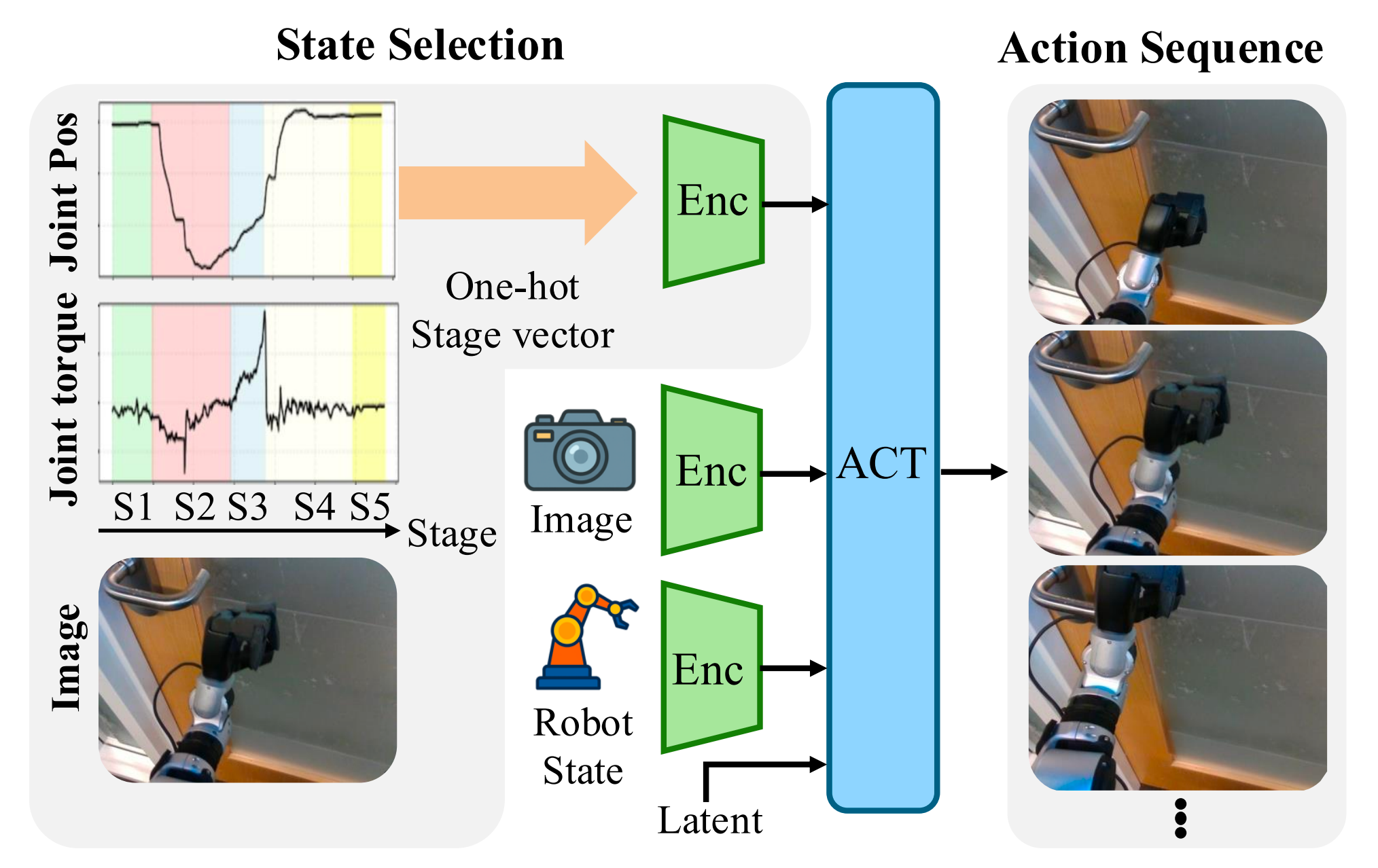
、机器人关节状态
以及潜在变量
解码器输出机器人动作
训练优化两个目标:
一个是重构损失,用于模仿示范轨迹;
另一个是KL 散度正则项,用于将编码器约束为高斯分布
且作者采用ACT 中提出的分块与时间集成策略,其中策略预测由100 步(约3 秒)组成的短时预测片段,并通过时间平滑将其聚合
这一设计提高了长时间任务执行过程中的稳定性,并防止机器人低层控制器出现抖动。超参数和训练流程均遵循原始ACT 工作中的设置,仅做出必要修改以适应下文所述的阶段条件化。在RTX 5090GPU 上训练约耗时4 小时,推理运行频率为30 Hz
更多可以参见此文《一文通透ACT——斯坦福ALOHA团队推出的动作分块算法:基于CVAE一次生成K个动作且做时间集成》的相关内容
“ 但策略需要重点关注高精度至关重要的区域,故ALOHA团队不得不通过训练他们的动作分块策略当做一个生成模型来解决这个问题(We tackle this problem by training our action chunking policy as a generative model)
- 最终他们将策略训练当做条件变分自编码器的生成问题「即we train the policy as a conditional variational autoencoder (CVAE),而CVAE 编码器采用类似BERT的transformer 编码器[13] 实现」
即以生成以当前观察为条件的动作序列- CVAE有两个组件:一个CVAE编码器和一个CVAE解码器,其中的CVAE编码器只用于训练CVAE解码器(策略),在测试时被丢弃
具体而言,如下图所示(值得特别注意的是,下图左侧是CVAE编码器——包含一个transformer encoder,右侧是CVAE解码器——包含一个transformer encoder和一个transformer decoder)
... ”

1.3.2 阶段条件化
尽管 ACT 提供了一个强有力的模仿学习基线,但将模仿学习直接应用于非马尔可夫的长时间跨度任务仍然十分困难 [28]
- 近期工作试图通过将策略条件化在更高层次的信号上(例如子阶段 [28]、技能集[33],乃至语言指令 [10], [29])来缓解这一挑战
- 由于作者专注于利用单一策略来解决“开门”这一特定任务,而不是在多种任务之间进行泛化,因此作者选择一种更为轻量的、基于阶段条件设定的方法来引导人形机器人的行走-操作行为
即开门任务可以自然地分解为五个阶段,如图 4 所示

- (S1) 寻找把手
- (S2) 用左臂接近把手
- (S3) 旋转把手
- (S4) 用右臂推门
- (S5) 停止行走并将手臂放低至休息位置
每个阶段的起始和结束条件由人工标注者对示教轨迹进行后处理和分段来定义。在机器人的自我中心视角下,关闭的门在不同阶段可能呈现出完全相同的外观(图 5)

- 例如,只能部分看到门、且手臂处于初始姿态的画面,既可能对应阶段 (S1) 中正在接近门把手,也可能对应阶段 (S4) 中门把手已被解锁后开始推门
相比之下,关节力矩则为检测接触力何时开始或结束提供了有用的信息。作者通过将视觉检查与来自关节位置和力矩的本体感受线索相结合,对示教过程进行标注
绝对力矩水平在整个任务过程中难以统一解读,但其出现的尖峰往往对应于阶段转换,例如抓住门把手或开始推门 - 通过将策略条件化在一个显式的阶段标签上,作者为其引入时间上下文,从而消除这些视觉歧义,并有助于防止模式崩塌
在训练和评估过程中,这些阶段标签被编码为 one-hot 向量,并与策略的输入进行拼接。阶段向量会以固定间隔输入到低层策略(low-level policy)中,其中基于阶段的条件(stage-conditioning)起到高层引导作用
这样的设计不仅提高了鲁棒性和任务完成率,还在测试阶段提供了可控性:显式的阶段提示可以触发恢复行为,甚至支持超出演示数据顺序的执行,如原论文将在下一节中展示的那样
// 待更

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 19
19 0
0- 0



 已为社区贡献77条内容
已为社区贡献77条内容

所有评论(0)