清华和Qwen团队最新!深究VLM如何影响VLA性能?并通过少量新参数转化为VLA策略
VLA 作为具身智能的核心技术框架,本文通过系统实验构建了 “构建范式 - 影响因素 - 模块作用 - 优化路径” 的完整体系,首次明确了 VLM 在 VLA 中的核心作用与性能瓶颈。其核心价值在于:为工程实践提供了 VLM 选型、辅助任务设计、模块训练策略的明确指导,推动具身智能从 “专用模型” 向 “通用模型” 跨越。
在具身智能体(Embodied AI Agents)广泛应用于机器人操控、虚拟交互等场景的当下,核心研究已从单一模态任务处理转向多模态融合的动作规划。传统视觉 - 语言模型(VLM)聚焦图像与文本的理解匹配,难以满足具身智能体在物理世界中 “感知 - 决策 - 动作” 的闭环需求。而视觉 - 语言 - 动作模型(VLA)作为整合 VLM 能力与动作生成的核心框架,成为具身智能实现自主操控与环境适应的关键技术支撑。
本文基于 100 余次实验数据,系统拆解 VLA 的构建范式、核心影响因素、模块作用与性能瓶颈,为具身智能的工程化落地提供全面参考。
Project Page: https://cladernyjorn.github.io/VLM4VLA.github.io/
Paper: https://www.arxiv.org/abs/2601.03309
Code: https://github.com/CladernyJorn/VLM4VLA
核心背景:从视觉 - 语言理解到具身动作规划的范式转移
早期具身智能研究依赖专用机器人模型,通过传感器数据直接学习动作映射,但其泛化能力受限,难以适应复杂场景变化。随着 VLM 在跨模态理解领域的突破,研究人员开始将预训练 VLM 整合到 VLA 框架中,利用其海量视觉 - 语言知识提升动作规划的通用性——例如服务机器人通过 VLM 理解 “拿起红色勺子” 的指令并转化为机械臂动作,工业机器人借助 VLM 识别零件位置并完成装配任务。
这种需求催生了 VLM 与 VLA 的技术衔接:VLM 提供跨模态理解能力,VLA 则负责将理解结果转化为可执行的物理动作。二者紧密关联:VLM 是 VLA 的 “认知基础”(通过视觉 - 语言对齐实现指令与环境的理解),VLA 是 VLM 的 “动作延伸”(赋予认知结果实际操控意义)。
当前 VLA 研究面临三大核心问题:VLM 选型与 VLA 性能的关联不明确、辅助任务微调对 VLA 效果的影响未知、VLM 内部模块(视觉编码器 / 语言编码器)在 VLA 中的作用权重模糊。本文通过构建统一实验框架,系统解答这些关键问题,为 VLA 的高效构建提供技术参考。
理论基石:VLM 与 VLA 的差异与统一性
核心差异:从认知建模到动作生成的本质不同
VLM 与 VLA 在核心目标、输入输出、优化目标等维度存在本质区别。VLM 的核心目标是实现视觉与语言的跨模态对齐,输入为图像 - 文本对,输出为文本回答或图像描述,优化目标聚焦理解准确性;而 VLA 的核心目标是将视觉 - 语言输入转化为连续 / 离散动作,输入为 “图像 + 任务指令”,输出为机器人可执行的动作序列,优化目标聚焦动作执行成功率。
数学定义上,VLM 可通过跨模态对齐损失(如对比学习损失、匹配损失)描述,核心优化视觉与语言表征的一致性;而 VLA 需扩展为 “认知 - 动作” 映射框架,通过模仿学习损失(如 MSE 损失、BCE 损失)优化动作预测的准确性,同时需考虑动作序列的连续性与物理可行性。这种差异本质是从 “理解世界” 到 “改造世界” 的范式转变。
统一性:最小适配框架下的技术融合
尽管二者存在显著差异,但可通过最小适配管道(VLM4VLA)实现技术统一。VLM4VLA 的核心是在不改变 VLM 主体结构的前提下,引入少量可学习参数(小于 1%),将通用 VLM 转化为 VLA 模型。其核心设计包括:
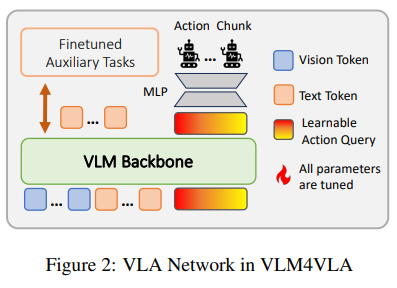
- 引入可学习的动作查询token(Action Query),从 VLM 的跨模态表征中提取动作相关信息;
- 采用简单 MLP 策略头,将跨模态表征解码为连续动作序列,避免扩散模型等复杂结构带来的随机性;
- 统一训练目标,通过 Huber 损失优化末端执行器的位置预测,通过二元交叉熵损失优化末端执行器的状态预测。
这种统一框架使得不同架构、不同规模的 VLM 能够在相同基准下进行公平对比,为 VLA 的技术选型提供了标准化参考。
构建 VLA 的必要性:泛化与实用双重视角
从泛化角度,传统机器人模型依赖大量专用数据训练,难以适应新场景、新任务;而 VLM 通过海量 web 数据预训练获得的通用视觉 - 语言知识,可作为 VLA 的先验,大幅提升模型的跨场景适应能力。从实用角度,VLA 无需从零训练,通过复用成熟 VLM 的能力,可显著降低具身智能的开发成本,加速技术落地。实验表明,基于 VLM 初始化的 VLA 模型性能远超从零训练的基线,验证了这一技术路径的必要性。
核心组件:VLA 的构建范式与关键影响因素
VLA 的性能表现受多重因素影响,核心可归结为三大维度:VLM 骨干模型选型、辅助任务微调、模块训练策略,三者共同决定了 VLA 的泛化能力与动作执行准确性。
VLM 骨干模型选型:通用能力与具身性能的非正相关
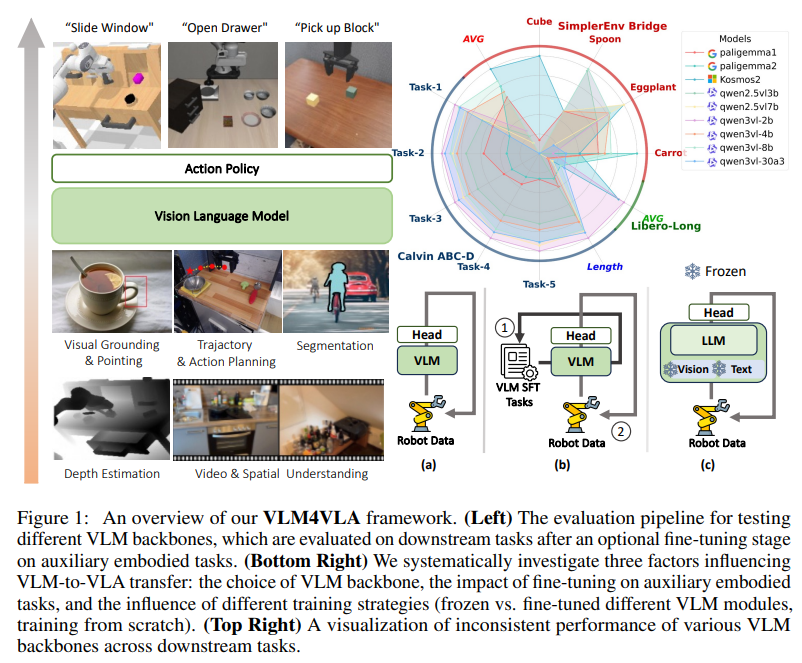
实验选取 9 种主流开源 VLM(参数规模 1B-30B),涵盖 QwenVL 系列、Paligemma 系列、Kosmos-2 等,在 Calvin、SimplerEnv、Libero 三大基准上的测试结果表明:
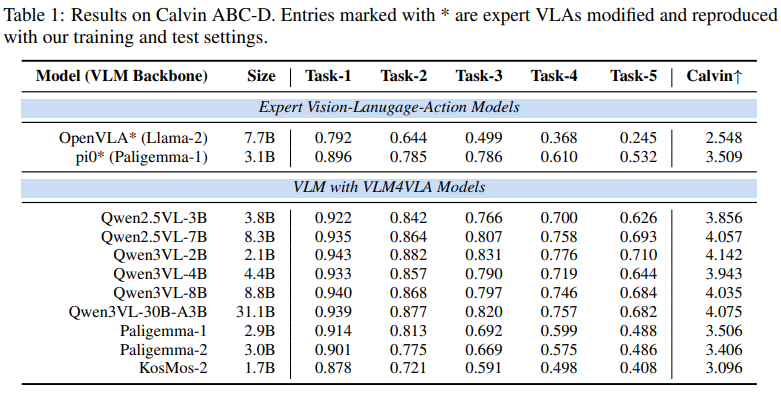
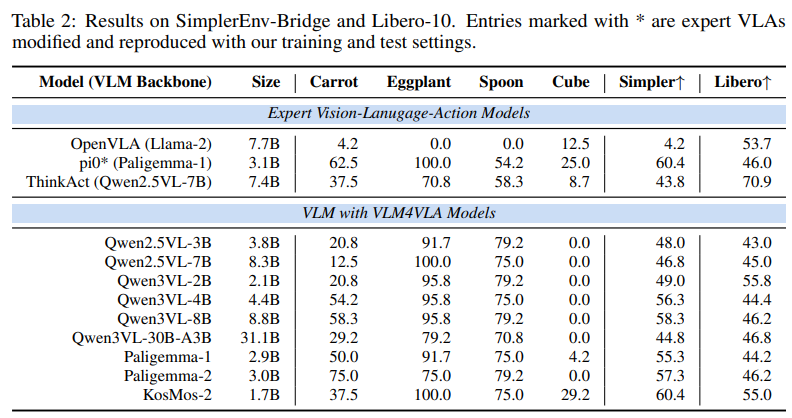
- VLM 预训练带来稳定增益:所有基于 VLM 初始化的 VLA 模型均显著优于从零训练的基线,验证了 VLM 先验知识的价值;
- 通用能力与具身性能无强关联:在标准 VQA 基准上表现优秀的 VLM,在 VLA 任务中未必表现突出。例如 Qwen2.5VL-7B 在通用 VQA 中性能领先,但在 SimplerEnv 基准上,参数更小的 Kosmos-2(1.7B)反而取得更高成功率;
- 架构适配性至关重要:专为接地任务优化的 Kosmos-2 在部分具身场景中表现优异,而侧重通用理解的 QwenVL 系列在长序列任务(如 Calvin ABC-D)中更具优势,表明 VLM 的架构设计需与具身任务特性匹配。
辅助任务微调:具身技能提升不等于动作性能优化
为探究辅助任务微调对 VLA 的影响,实验选取 7 种典型具身辅助任务(包括空间理解、指向预测、动作导向 VQA 等),对 Qwen2.5VL 系列模型进行微调后构建 VLA,结果发现:
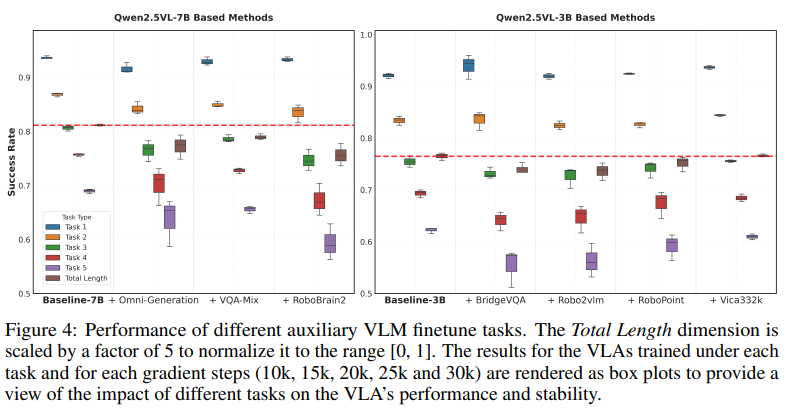
- 多数辅助任务微调效果不佳:除 Vica-332k(空间理解数据集)微调后略有提升外,其余辅助任务(如 Robopoint 指向预测、Robo2vlm 动作 VQA)均导致 VLA 性能下降或波动增大;
- 通用数据与具身数据的平衡关键:混合通用 VQA 数据与具身数据微调的 VQA-Mix 模型,性能最接近基线,表明 VLA 需要的是广谱的跨模态能力,而非单一具身技能;
- 生成式任务微调无效:深度图生成、语义分割等生成式辅助任务,并未提升 VLA 的动作规划能力,说明低级别视觉生成与动作控制的需求存在差异。
模块训练策略:视觉编码器是核心瓶颈
通过对 VLM 的视觉编码器、语言编码器、词嵌入层进行冻结 / 微调对比实验,发现各模块对 VLA 性能的影响差异显著:
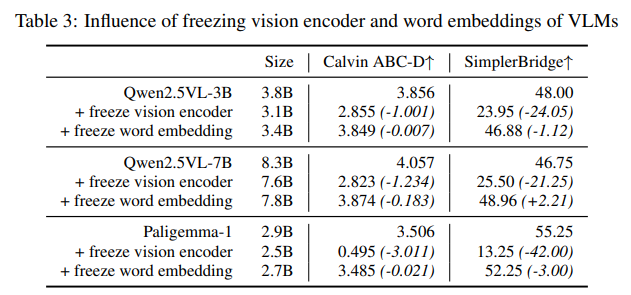
- 视觉编码器是关键:冻结视觉编码器会导致 VLA 性能大幅下降,例如 Paligemma-1 冻结视觉编码器后,Calvin 基准得分从 3.506 降至 0.495,降幅达 86%;即使是参数规模更大的 Qwen2.5VL-7B,冻结视觉编码器后性能仍低于小参数的 Qwen2.5VL-3B 全量微调模型;
- 语言模块影响有限:冻结词嵌入层或语言编码器,对 VLA 性能的影响极小(降幅通常小于 5%),表明 VLA 对语言理解的要求可由 VLM 的预训练能力满足,无需额外微调;
- 视觉域适配需求迫切:视觉编码器的性能瓶颈源于 VLM 预训练数据(web 图像)与具身场景数据(模拟 / 真实操控图像)的域差异,以及视觉 - 语言理解与低级别动作控制对视觉特征的不同需求。
推理机制:VLA 的动作生成范式与优化路径
VLA 的动作生成核心是 “跨模态理解 - 动作映射” 的推理过程,当前形成两大主流范式,各有优劣且呈现融合趋势。
直接映射范式:轻量化适配与高效推理
该范式以 VLM4VLA 为代表,通过简单的 “VLM 跨模态表征 + MLP 动作解码” 实现端到端动作生成,核心优势在于:
- 轻量化设计:仅引入少量可学习参数,训练成本低、推理速度快,适合实时操控场景;
- 稳定性强:采用确定性损失函数(如 MSE、BCE),避免扩散模型等带来的性能波动;
- 通用性好:可适配任意 VLM 骨干模型,便于进行公平对比与选型。
典型案例包括基于 Qwen3VL-2B 的 VLA 模型,在 Calvin 基准上平均完成任务数达 4.142,接近 SOTA 专用 VLA 模型,且参数规模更小、训练效率更高。
增强推理范式:模块优化与知识注入
该范式通过强化 VLM 的具身相关能力或优化动作生成模块,提升 VLA 的复杂场景适应能力,典型方法包括:
- 视觉编码器增强:向 VLM 视觉编码器注入控制相关信息(如动作token),即使冻结编码器也能提升性能,Qwen3VL-4B 经此优化后,SimplerBridge 基准成功率提升 18.1%;
- 多模态融合优化:结合 proprioceptive 状态(如机器人关节信息),ThinkAct 模型在 Libero 基准上成功率达 70.9%,显著优于未使用该信息的模型;
- 架构升级:采用分层设计,VLM 负责高层任务理解与规划,专用动作专家负责低层动作生成,但需注意避免动作专家受限于 VLM 骨干的固有能力。
融合趋势:轻量化基础与增强型优化
单一范式难以满足复杂具身场景需求,融合趋势逐渐显现:以直接映射范式为基础,保证高效推理与稳定性;针对特定场景,引入视觉增强、多模态信息融合等优化手段,提升性能上限。例如,在通用场景采用 VLM4VLA 的基础架构,在高精度操控场景注入控制相关视觉监督,实现 “效率与性能” 的平衡。
评估体系:VLA 基准的演化与核心指标
VLA 评估基准的演化遵循 “简单场景→复杂场景、单一模态→多模态” 的逻辑,逐步贴近真实具身需求,当前主流基准各有侧重。
主流基准特性与评估维度
| 基准名称 | 核心场景 | 模态类型 | 评估指标 | 核心挑战 |
|---|---|---|---|---|
| Calvin ABC-D | 桌面长序列操控 | 视觉 + 文本 | 平均完成任务数 | 跨场景泛化(颜色 / 物体布局变化) |
| SimplerEnv Bridge | 真实 - 模拟迁移操控 | 视觉 + 文本 | 任务成功率 | 域适配(真实数据训练→模拟环境测试) |
| Libero-Long | 多类型物体操控 | 视觉 + 文本 | 任务成功率 | 长时程动作规划与多物体交互 |
这些基准的共同趋势是:从静态场景转向动态交互、从单一任务转向复合任务、从模拟数据转向真实 - 模拟混合数据,更能反映 VLA 的实际应用能力。
评估核心指标与注意事项
VLA 的核心评估指标包括任务成功率、平均完成任务数、动作序列平滑度等,评估过程中需注意:
- 控制随机性:避免扩散模型等带来的性能波动,采用足够多的测试轮次(如 SimplerEnv 基准 24 次随机初始化)确保结果可靠;
- 统一实验设置:保持输入模态(如仅用单视图图像)、训练超参数(学习率、批大小)一致,避免无关变量干扰;
- 关注泛化能力:重点评估模型在 unseen 场景(如 Calvin 的 D 场景)的表现,而非仅在训练场景中过拟合。
核心挑战与未来方向
四大核心技术挑战
- 视觉域差异与特征错位:VLM 预训练图像与具身场景图像的域差异显著,且视觉 - 语言理解与动作控制对视觉特征的需求不同,导致视觉编码器成为性能瓶颈;
- 通用能力与具身性能的适配难题:VLM 的通用 VQA 性能与 VLA 的动作执行性能无强关联,难以通过现有 VLM 评估指标预测 VLA 表现;
- 辅助任务微调的有效性边界:多数具身辅助任务微调无法提升 VLA 性能,如何设计针对性微调任务尚不明确;
- 真实场景落地的公平性与可复现性:物理机器人硬件差异大,实验难以复现,导致当前研究多依赖模拟环境,与真实应用存在差距。
未来研究方向
- 视觉模块优化:聚焦 VLM 视觉编码器的域适配技术,开发控制导向的视觉表征学习方法,缩小视觉 - 语言任务与动作控制任务的特征差距;
- 范式融合与自适应架构:构建 “轻量化基础 + 增强型插件” 的自适应 VLA 架构,简单场景采用直接映射范式保证效率,复杂场景引入增强模块提升性能;
- 专用评估体系构建:设计兼顾真实场景、多模态动态交互、社交反馈循环的 VLA 评估基准,建立统一的性能验证标准;
- 数据与训练策略创新:探索通用数据与具身数据的最优混合比例,开发高效微调方法,在不损害 VLM 通用能力的前提下提升具身适配性。
总结:VLA 的范式价值与行业影响
VLA 作为具身智能的核心技术框架,本文通过系统实验构建了 “构建范式 - 影响因素 - 模块作用 - 优化路径” 的完整体系,首次明确了 VLM 在 VLA 中的核心作用与性能瓶颈。其核心价值在于:为工程实践提供了 VLM 选型、辅助任务设计、模块训练策略的明确指导,推动具身智能从 “专用模型” 向 “通用模型” 跨越。
随着视觉域适配技术的突破、融合架构的完善、专用评估基准的建立,VLA 将加速具身智能在家庭服务、工业生产、医疗康复等领域的落地,实现从 “感知理解” 到 “自主行动” 的关键跨越,让智能体真正融入物理世界并提供可靠服务。
具身求职内推来啦
国内最大的具身智能全栈学习社区来啦!
推荐阅读
从零部署π0,π0.5!好用,高性价比!面向具身科研领域打造的轻量级机械臂
工业级真机教程+VLA算法实战(pi0/pi0.5/GR00T/世界模型等)
具身智能算法与落地平台来啦!国内首个面向科研及工业的全栈具身智能机械臂
VLA/VLA+触觉/VLA+RL/具身世界模型等!具身大脑+小脑算法与实战全栈路线来啦~
MuJoCo具身智能实战:从零基础到强化学习与Sim2Real
Diffusion Policy在具身智能领域是怎么应用的?为什么如此重要?
1v1 科研论文辅导来啦!

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 14
14 0
0- 0



 已为社区贡献106条内容
已为社区贡献106条内容

所有评论(0)