DoorMan——先仿真中“教师-学生两阶段训练”后Sim2Real,最后仅靠视觉打开会议室的门,给客户递杯水(可额外探索教师策略未演示的行为)
前言
如原论文所说,DoorMan提出了一种用于基于视觉的人形机器人行走-操作的教师-学生-自举学习框架,并以关节物体交互作为具有代表性的高难度基准任务
- 该方法引入了一种分阶段重置的探索策略,用于稳定长时域特权策略的训练,并提出了一种基于 GRPO 的微调过程,以缓解部分可观测性问题,并提升从仿真到现实强化学习中的闭环一致性
- 该策略完全在仿真数据上训练,在多种门类型上实现了鲁棒的零样本性能,并在使用相同的全身控制栈条件下,将任务完成时间最多缩短了 31.7%,优于人类远程操作员
总之,这是首个仅依赖 RGB 视觉、能够在多样化关节行走-操作任务上实现从仿真到现实迁移的人形机器人策略
PS,年前,我们大概率会搞下『让双足人形、或轮式人形打开会议室的门,然后给客户递杯水』这个难度相对较高的任务,虽这个doorman暂未开源,但不影响挑战的决心,另欢迎985/211的准研一来我司实习,共赴世界级前沿
第一部分
1.1 引言与相关工作
1.1.1 引言
如原论文所说,在机器人学领域的现实是,相比只利用 RGB 视觉就能打开门这一问题,人形机器人的“功夫”和后空翻等已经先被攻克了,而日常行走-操作一体化(loco-manipulation)仍然是类人机器人自主性最具挑战性的前沿之一
- 看似简单的家庭交互,例如拉抽屉、扭动旋钮或解开门闩,都需要精确的感知-动作耦合、接触丰富的控制,以及在不确定性条件下的全身协调
- 在这些任务中,开门是一个尤为苛刻的典型场景:机器人必须通过运动的自我视角摄像头识别抓取位置,旋转带弹簧的门把手,跟踪门板的顺应性圆周运动,并在合页施加的力作用下保持平衡
这些高度耦合的要求使开门成为对任何通用行走-操作一体化系统的强力压力测试
本文要介绍的DoorMan的目标是构建一条具有良好泛化能力的、基于视觉的人形机器人行走—操作一体化学习流程,并以开门这一具有挑战性的真实场景任务作为代表性案例

- 其paper地址为:Opening the Sim-to-Real Door for Humanoid Pixel-to-Action Policy Transfer
作者来自:1 NVIDIA、2 UC Berkeley 3 CMU、4 CUHK
具体包括
Haoru Xue1,2* , Tairan He1,3* , Zi Wang1* , Qingwei Ben1,4 , Wenli Xiao1,3 , Zhengyi Luo1 , Xingye Da1 , Fernando Castañeda1 , Guanya Shi3 , Shankar Sastry2 , Linxi “Jim” Fan1† , Yuke Zhu1† - 其项目地址为:doorman-humanoid.github.io
但,截止到26年2月中旬,暂未开源,且不确定其未来是否会开源
具体而言
- 现有专门针对开门问题的系统通常难以满足这一更广泛的目标
许多方法依赖深度传感、以物体为中心的特征,或在轮式平台上预先硬编码的运动基元Calvert et al., 2025,即A behavior architecture for fast humanoid robot door traversals(一种用于人形机器人快速穿越门的行为架构)
Weng et al., 2025,即Hdmi
详见此文《HDMI——人形交互式全身控制:宏观上从人类RGB视频中学习全身交互控制,微观上暂依赖动捕数据,且暂一项技能一套策略(已开源)》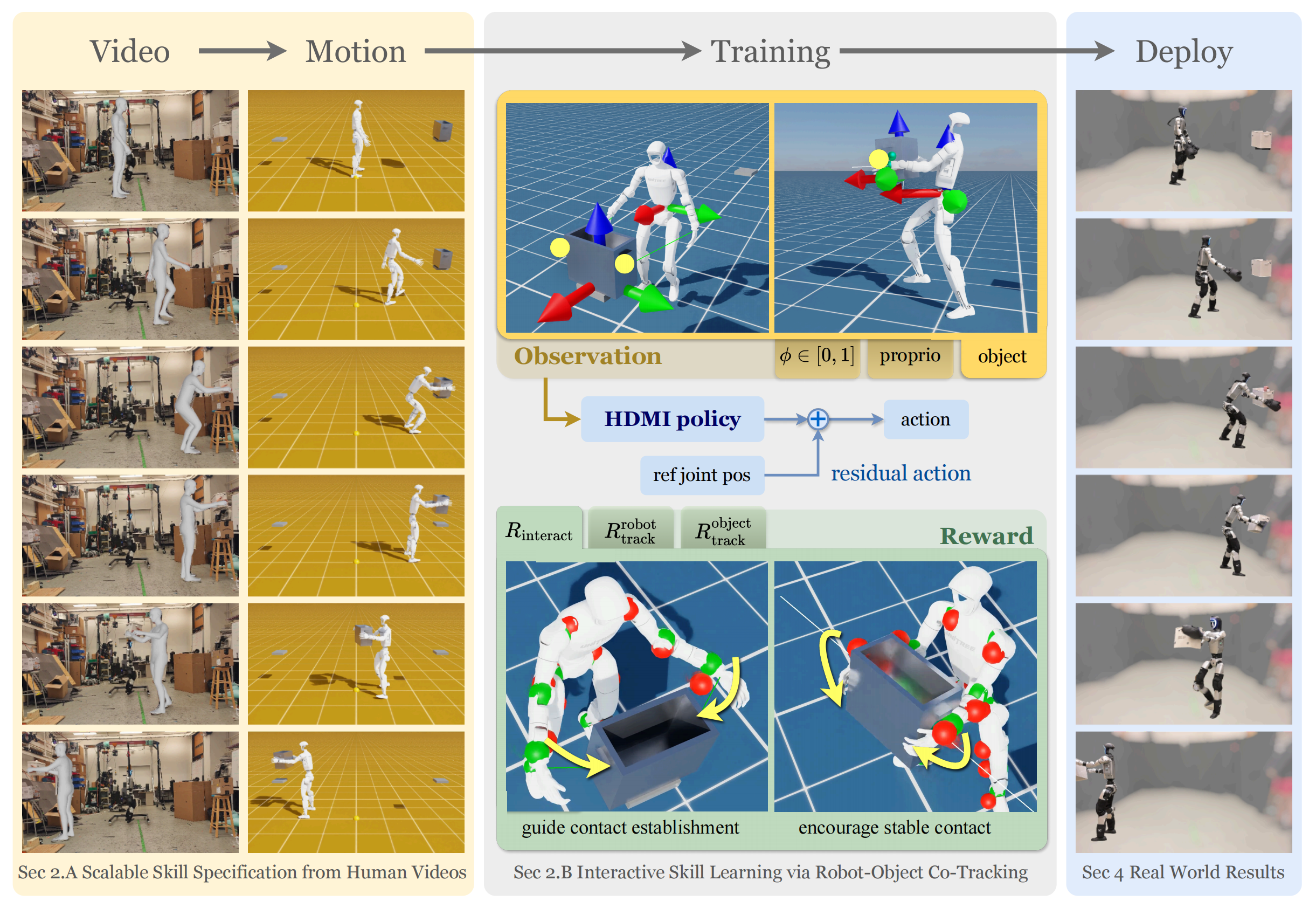
Xiong et al., 2024,即Adaptive mobile manipulation for articulated objects in the open world(开放世界中铰接对象的自适应移动操作)
————
详见此文《以Mobile ALOHA为代表的模仿学习的爆发:从Dobb·E、伯克利Gello到斯坦福ALOHA、OK-Robot、CMU自适应移动操作机器人》的「第七部分 CMU自适应移动操作机器人:模仿学习 + RL之后,一切自主操作」
还有一些方法简化了接触力学,或要求精确的物体定位
Zhang et al., 2025,即Learning to open and traverse doors with a legged manipulator(学习使用机器狗 + 机械臂开门并穿越)
DARPA RoboticsChallenge 时代的系统『Technical overview of team drc-hubo@ unlv's approach to the 2015 darpa robotics challenge finals(UNLV DRC-Hubo 团队参加 2015 年 DARPA 机器人挑战赛决赛的技术方案概览)
在很大程度上依赖脚本和人工操作员干预
而近期以遥操作为中心的流程『Lee et al., 2025,即Stageact: Stage-conditioned imitation for robust humanoid door opening(Stageact:基于阶段条件的模仿学习,用于鲁棒的人形机器人开门)』
依然较为脆弱
————
这些设计尚不能为日常环境中所需的多样化行走—操作技能提供一种可扩展的解决方案 - 近期在仿真、硬件和强化学习(RL)方面的进展,使得在
运动locomotion
Ben et al., 2025,即Homie
Longet al., 2025,即Learning humanoid locomotion with perceptive internal model (利用感知内部模型学习人形机器人运动)
Ren et al., 2025,即Vb-com: Learning vision-blind composite humanoid locomotion against deficient perception (Vb-com:在感知缺陷下学习视觉盲区复合人形机器人运动)
Wang et al., 2025,即Beamdojo: Learning agile humanoid locomotion on sparse footholds
Xue et al., 2025,即Leverb: Humanoid whole-body control with latent vision-language instruction
Zhuang et al., 2024,即Humanoid parkour learning (人形机器人跑酷学习)
动作模仿motion imitation
He et al., 2025,即Asap
Liao et al., 2025,即Beyondmimic
Luo et al., 2025,即Sonic
灵巧操作dexterous manipulation
Akkaya et al., 2019,即Solving rubik's cube with a robot hand (用机器人手破解魔方)
Deng et al., 2025,即Graspvla: a grasping foundation model pre-trained on billion-scale synthetic action data (GraspVLA:在十亿级合成动作数据上预训练的抓取基础模型)
Handa et al., 2023,即Dextreme: Transfer of agile in-hand manipulation from simulation to reality (Dextreme:将敏捷的手内操作从仿真迁移到现实)
Liu et al., 2024,即Visual whole-body control for legged loco-manipulation (用于足式移动操作的视觉全身控制)
Singhet al., 2024,即Dextrah-rgb: Visuomotor policies to grasp anything with dexterous hands (Dextrah-RGB:利用灵巧手抓取任何物体的视觉运动策略)
等任务上取得了强有力的仿真到真实(sim-to-real)成果
然而,将这些技术应用到“行走-操作一体”(loco-manipulation)场景中——在该场景下,感知、平衡、接触与导航相互耦合——仍然研究不足
在这一设定中,作者识别出通用化学习面临的两个根本性挑战:
i)算法本身必须足够简单、可扩展,并对部分可观测性具有鲁棒性,能够在多样化任务中产生自主策略,协调视觉与全身控制(WBC);这一系列要求在既有工作中尚未得到满足
ii)视觉仿真到真实的鸿沟涵盖了外观和物理属性变化的巨大空间,这就需要广泛、异质的数据,而非少数经过精心策划的场景
为了解决第一个挑战,作者提出了一种新颖且可扩展的教师-学生-自举学习流程
- 首先,利用具有特权状态(例如,门的位姿和关节状态)的教师,在阶段条件奖励的设置下,通过强化学习(RL)进行训练
为了提高训练效率,引入了一种探索方案,从后期阶段的快照重置环境,利用模拟器的可恢复性 - 接下来,使用DAgger(Ross 等人,2011)将教师蒸馏到一个基于RGB 的学生中,在强烈视觉随机化的条件下,将视觉编码器与本体感知信息进行融合
- 最后,为了缓解纯视觉控制中固有的部分可观测性问题,应用GRPO 微调,以稳定长时间跨度的行为,并鼓励将任务相关区域保持在视野内
为了解决第二个挑战,作者在 Isaac Lab(NVIDIA et al., 2025)中构建了一条大规模的域随机化流水线,在物理属性和外观属性两个层面实现大范围的变化
- 在物理层面,作者随机化门的类型、尺寸、铰链阻尼、门闩动力学、把手位置以及阻力转矩
- 在视觉层面,作者随机化材质、光照以及相机的内参/外参
且作者并不试图重建特定场景,而是有意让策略暴露在一个覆盖范围极广的变化包络之内,这是实现从仿真到真实世界可迁移的仿人机器人行走-操作(loco-manipulation)的必要前提
1.1.2 相关工作
// 待更
1.2 基于师生蒸馏的 RGB 行走-操作
在本节中,作者介绍 DoorMan 的三阶段训练过程,其建立在经典的教师–学生蒸馏框架之上
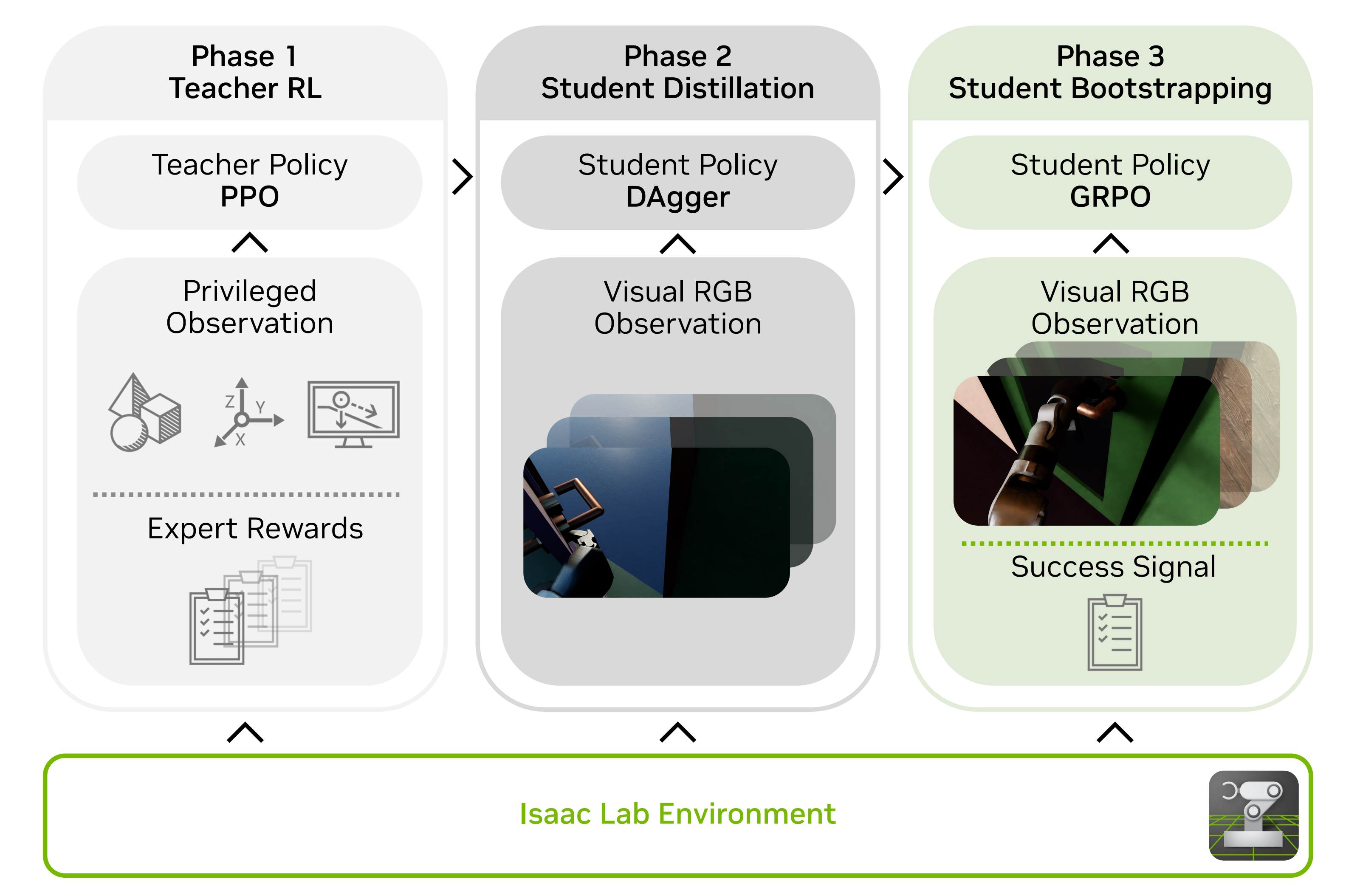
- 首先给出一个用于全身行走-操作的视觉仿真到现实(sim-to-real)管线,重点强调两个设计要素:
一是针对长时程任务定制的多阶段探索方案
二是用于缓解学生策略部分可观性问题的自举式精化策略 - 随后,作者将描述一个大规模合成数据生成管线,其在Isaac Lab(NVIDIA 等,2025)能够生成物理真实且视觉多样的门环境,用于训练和评估,并将开门视为一种具有代表性的行走-操作(loco-manipulation)任务
1.2.1 视觉强化学习与教师-学生蒸馏
- 对于预备知识
考虑一个部分可观测马尔可夫决策过程,其中
是状态空间,
是动作空间,
是观测空间,
是转移核,
是奖励,
是观测,
是折扣因子,以及
是初始状态分布
在人形全身控制相关文献中,策略负责输出目标关节位置,在Unitree G1 机器人的情形下,这包括29 个身体关节和14 个手部关节,从而导致动作空间维度极高,为33
这些关节角随后由低层电机通过PD 控制律进行跟踪。与准静态操作相关文献不同,该策略需要对力矩层级的动力学进行极其细致的推理以保持机器人的平衡,尤其是在推开带弹簧的门时
————
该策略还需要在50 Hz 的频率下持续进行推理,这就需要高效的神经网络结构
且在一个预训练的全身控制器(Ben et al., 2025)之上构建DoorMan,以减轻从零开始处理足式运动带来的额外负担 - 对于教师策略
在时间的教师策略
可以访问特权信息
,这些信息通常在仿真之外无法直接获得
这些包括真实的机器人基座到门的变换,左手和右手到门把手的变换
,
,以及基座线速度
————
先前的工作使用硬编码估计器(Calvertet al., 2025; Xiong et al., 2024; Zhang et al., 2025)来估计其中的一些量,而作者的目标是在部署时消除此类先验,并通过纯RGB 输入的学生策略最大化泛化能力
且作者使用标准的近端策略优化(PPO)(Schwarkeet al., 2025)来训练教师策略,具体的奖励塑形方案见附录A - 对于学生蒸馏
虽然学生策略可以访问非特权的本体感觉信息,例如关节角度、关节速度
以及根部角速度
,但它对任务的感知主要依赖于输入的RGB 观测及其时间上下文
图像由视觉编码器(He et al.,2015) 处理,得到的潜在表示与本体感觉特征串联后,输入到一个两层的LSTM(每层 512 个单元)
随后,一个三层的 MLP(512、256、128)将循环特征映射到目标关节角度。视觉编码器与策略一起联合微调
学生策略通过 DAgger(Ross 等, 2011)进行交互式蒸馏,这相比仅覆盖教师分布的行为克隆,使得可以在学生自身的输入分布上进行直接监督
1.2.2 多阶段全身行走-操作
如原论文所述,作者提出了一种用于全身行走-操作任务的鲁棒教师训练流程设计
- 类似于Zhanget al.(2024),作者设计了一个基于阶段的奖励系统,将任务分解为若干原子阶段,每个阶段都有其各自的奖励形式
且注入了一定的人类归纳偏置,例如利用门把手和合页的状态来区分一次成功开门操作中的接近、开启和通过阶段 - 作者发现,那些接触密集且需要高精度操作的任务(例如使用带关节的门),在鼓励策略稳定地进行探索并推进到更后期阶段时,存在独特的挑战
而这些挑战在以往关于强化学习全身控制的成功工作中并未被预见
————
直观来讲,在不了解如何以正确方向小心旋转门把手、或如何与精确的全身运动相配合的情况下去抓握门把手,会因为电机扭矩使用过大、接触力峰值过高,甚至存在摔倒风险而招致额外惩罚,从而导致策略“遗忘”抓握行为,并避免向下一阶段推进
为提高训练效率,作者受 Ecoffet 等人(2021)的启发,设计了一种简单的探索激励方案,利用物理模拟器的完全可恢复性
- 当环境进入下一阶段时,一个滑动缓冲区会在该步保存机器人和环境(门)的最近 100 个快照,其中包含场景中所有关节体和刚体对象的广义坐标
随后在重置时刻,机器人会以非零概率被随机重置到初始阶段或某个中间阶段。该流程如图 3 所示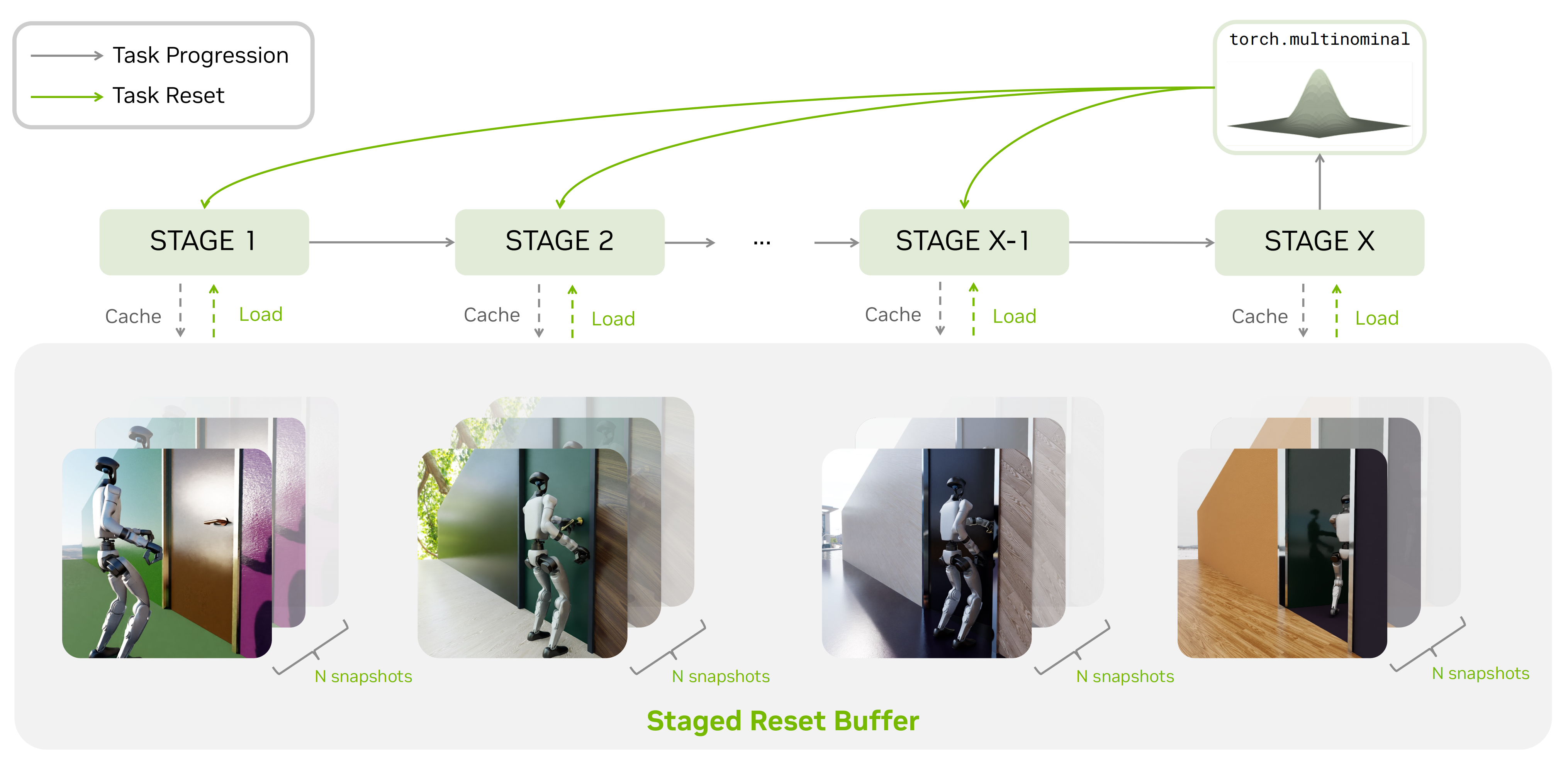
- 为了以更形式化的方式表述这一点,并更加清楚地看到它在 on-policy 强化学习(RL)中的效果,考虑一个长时域的多阶段任务,例如,接近门(阶段 1)并将其打开(阶段 2)
这些阶段对应于不相交子集由狭窄的过渡区域或桥
连接,必须穿过这些区域才能到达下一阶段
由于跨越此类桥的探索具有极低的概率,从
为此,作者提出了一种分阶段重置法则(staged reset law)
其指定了从每个阶段的重置分布 初始化的轨迹所占的比例。因此,由此得到的初始分布变为
并采用了更新后的折扣占用度量
其中 表示边缘概率。这表明,分阶段重置方案会将占用度量(occupancy measure)的权重偏向于后期阶段的区域,从而增加这些状态的出现频率以及对应梯度更新的有效幅度
1.2.3 针对部分可观测性的RL微调(RL Finetuning for Partial Observability)
在教师-学生策略蒸馏中,学生策略只接收部分观测
,而教师策略
则可以访问特权观测。仅使用标准行为克隆损失在学生观测空间由于遮挡而遗漏关键特征时,可能无法获得最优性能
实际上,学生策略往往需要在其自身的rollout 基础上进行自举,以发现额外的策略来弥补其——只能“部分可观测性”的局限,例如调整机器人的位置,使操作区域始终保持在摄像头的视野范围内
- 为了实现这种自我提升,作者使用Group Relative Policy Optimization (GRPO) (Shao et al., 2024) 算法对学生策略进行微调,该算法是PPO 的一种仅含actor 的变体,省略了价值函数,而是从分组的轨迹得分中估计基线
令一批由当前策略采样得到的G 个rollouts
,每个具有回报
,然后定义归一化的组相对优势
并使用裁剪的PPO 替代目标函数更新πS:
其中 - 从概念上讲,这一 GRPO 微调阶段使得学生策略能够超越对教师的简单模仿,在其自身仅具部分观测的条件下直接优化自己的行为
实证上,作者观察到,这种自举式的过程会使基于视觉的学生学到教师从未演示过的补偿性行为,例如始终让被操作的物体保持在视野中央,或调整末端执行器的姿态以维持可见性。————
因此,GRPO 充当了一个轻量且稳定的强化式精炼阶段,用以补充行为克隆,在从基于特权示范的模仿到实现鲁棒的自主执行之间架起桥梁
值得一提的是,在微调过程中,作者主要使用二元的任务成功信号,并辅以一些简单的塑形奖励项,例如关节速度、关节加速度以及动作频率惩罚,用于对人形机器人行为进行正则化
因此,这种方法可以作为一种即插即用的解决方案,用来提升任何具有非零成功率基础策略的行走-操作任务的表现
1.2.4 大规模仿真随机化
为将全身行走-操作任务在视觉与动力学多样性方面扩展到前所未有的规模,作者在 Isaac Lab中设计了一条程序化生成流水线,用于生成在物理和视觉上都多样且真实的关节体资产
与Infinigen-Sim(Joshi 等,2025)等先前工作相比,作者基于 Isaac Lab 的原生实现显著提升了物理真实感,并支持同时具备高精度与高效率的接触仿真,从而适用于并行强化学习工作流
- 作者强调,他们并没有在仿真中重建真实世界的场景;相反,作者用于评估的所有真实场景在训练期间都是未曾见过的
过程生成流水线不会对任何真实地点的特定尺寸、物理响应、纹理、颜色或光照条件产生偏向 - 这一点有别于小规模行为克隆相关文献(Lee 等,2025),后者的评估被局限在与数据最初采集时完全相同的场景、背景、光照和时间条件下
具体而言
- 物理变体
作者在生成管线中包含 5 种不同的门类型,覆盖 3 个大类中常见的门:带旋转门把手的推门;带旋转门把手的拉门;带推杆的推门
————
类似于 Zhang 等人(2025),门的所有可设想物理属性都被随机化,例如门的尺寸、把手位置、门铰链阻尼以及门把手的阻力矩
尤为重要的是,作者使用逼真的门闩机构来刻画开门瞬间整体动力学的突变 - 视觉变化
随机纹理从 IsaacLab 的物理真实感渲染(PBR)材质库中抽取,并应用于所有表面。此外,作者使用 5233 种穹顶光照纹理来模拟不同的地点和一天中不同的时间。为在并行训练强化学习(RL)策略的同时兼顾渲染质量和性能,且在性能模式下使用RTX 实时渲染器,并启用运动模糊和自动白平衡等后期处理效果
————
相机的外参和内参被对齐并进行轻微随机扰动。这些设置对于在苛刻的真实世界条件下重现相机安装在足式机器人上、且持续发生接触切换时的对应关系至关重要
// 待更

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 28
28 0
0- 0



 已为社区贡献77条内容
已为社区贡献77条内容

所有评论(0)