清华大学团队YOLOE的基础理论知识
该模型支持文本提示、视觉提示及全自动检测三种模式,在保留YOLO系列骨干网络、特征金字塔和分割/回归头的基础上,创新性地优化了视觉-文本语义对齐机制,通过轻量级辅助网络提升开放场景下目标识别的泛化能力,同时采用解耦式视觉提示编码降低计算复杂度,兼顾检测精度与实时性,成功打破传统模型对预定义类别的依赖,为自动驾驶、机器人视觉等动态开放环境提供灵活可靠的视觉理解解决方案。PAN的核心思想是在FPN的基
1.概述
YOLOE是清华大学团队于 2025 年基于YOLO系列的重要创新模型,针对像YOLO系列传统模型受限于预设类别和开放场景中的适应性的问题,提出了通过利用文本提示、视觉提示或无提示范式来克服这一问题。该技术将多种开放提示机制的检测与分割整合到单一高效模型中,实现实时观察任何内容。对于文本提示,该技术提出可重新参数化的区域-文本对齐(RepRTA)策略。它通过可重新参数化的轻量级辅助网络优化预训练文本嵌入,并以零推理和转移开销的方式增强视觉文本对齐。对于视觉提示,我们介绍语义激活视觉提示编码器(SAVPE)。它采用解耦语义和激活分支,以最小复杂度提升视觉嵌入和准确性。对于无提示的场景,我们引入了懒惰区域-提示对比(LRPC)策略。它利用内置的大词汇和专门的嵌入技术来识别所有对象,避免了昂贵的语言模型依赖。
评价:这一多模态能力使其既能听懂语言指令,又能看懂图像,甚至还能自主发现新事物,实现了真正的「实时看见一切」。其主要完成的工作包括
- 通过文本描述检测任意物体
- 使用参考图像引导检测过程
- 在完全未知的环境中自主识别目标
2、YOLOE架构
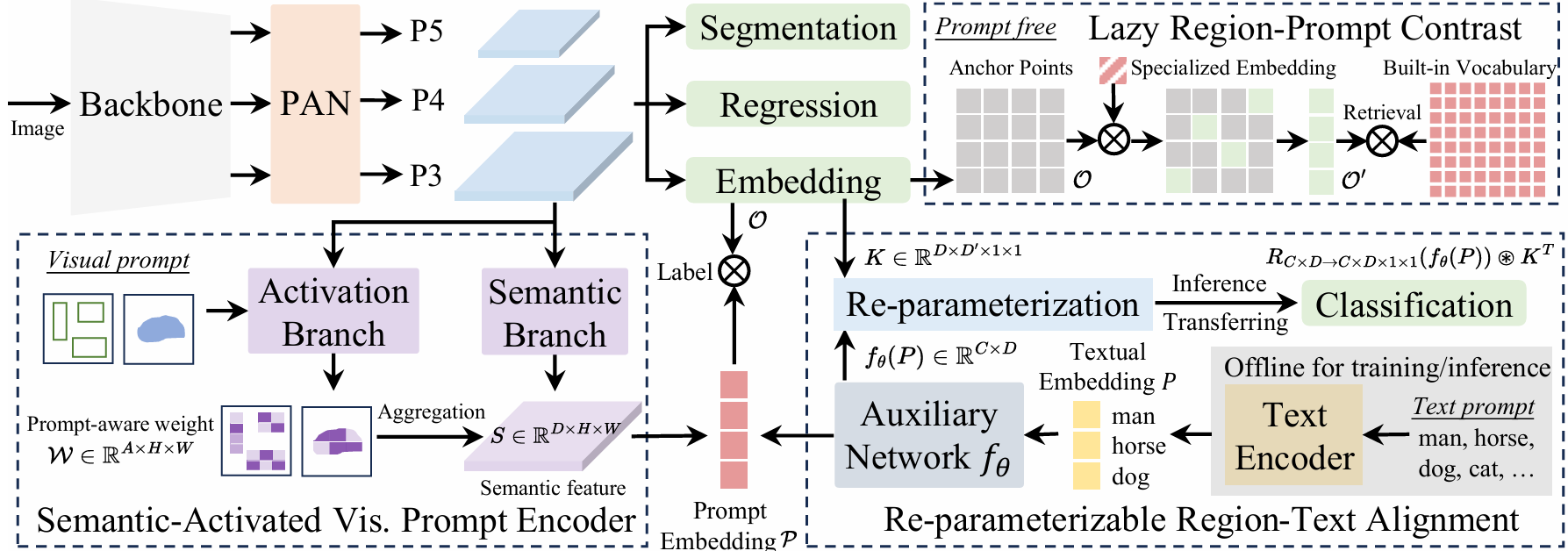
yoloE的架构各组成的含义如下:
Backbone:骨干网络,负责从原始数据中提取特征,它通常又多个卷积层、池化层等基本组件构成,具有不同的深度和复杂度。其主要作用是将输入数据进行特征提取和抽象,将原始数据转换为更具有表征性的特征表示。
PAN:(Path Aggregation Network)是一种用于目标检测任务的特征金字塔网络结构,它通过引入自底向上的路径增强来改进FPN(Feature Pyramid Network)。PAN的核心思想是在FPN的基础上增加一个从深层特征到浅层特征的传播路径,以增强低层特征的定位能力,同时保留高层特征的语义信息。
Lazy Region-Prompt Contrast:指定区域提示对比,LRPC指加入视觉-语言模型能力,通过 prompt contrast 学习新类别。利用内置大词汇表和专用嵌入识别所有对象,避免依赖昂贵的语言模型。只需将识别出的物品的点与词汇表进行匹配,避免了对所有物品的点进行计算,提高了效率。将无提示场景重新定义为搜索问题,而非生成问题。
Semantic-Activated Vis. Prompt Encoder ,SAVPE通过分离的语义分支和激活分支,以最小的复杂度提升视觉嵌入和准确性。它具有两个解耦的轻量级分支:(1) 语义分支在 D 通道中输出与提示无关的语义特征,而无需融合视觉提示的开销;(2) 激活分支通过在低成本下在更少的通道中将视觉提示与图像特征交互来产生分组的提示感知权重。然后,它们的聚合会在最小复杂度下产生信息丰富的提示嵌入。
Re-parmerizable Region-Text Alignment,RepPTA,通过轻量级辅助网络优化预训练的文本嵌入,增强视觉-文本对齐,且在推理和迁移时无额外开销。 这个模块使用 CLIP 文本编码器获取预训练的文本嵌入。在训练期间,使用一个轻量级的辅助网络(一个SwiGLU FFN块)来增强文本嵌入,提高视觉-对比度。训练后,辅助网络可以重参数化到物体嵌入Head中,形成与原始YOLO相同的分类头,实现零头部署和迁移。
总结:YOLOE 它撕掉了传统模型“封闭检测”的标签,让机器真正学会“见万物、懂万物”。清华大学团队提出的YOLOE是基于YOLO架构的突破性开放场景目标检测与分割模型,通过引入可重参数化的区域-文本对齐模块(RepRTA)、语义激活视觉提示编码器(SAVPE)及惰性区域-提示对比(LRPC)三大核心技术,实现了多模态交互与高效推理的融合。该模型支持文本提示、视觉提示及全自动检测三种模式,在保留YOLO系列骨干网络、特征金字塔和分割/回归头的基础上,创新性地优化了视觉-文本语义对齐机制,通过轻量级辅助网络提升开放场景下目标识别的泛化能力,同时采用解耦式视觉提示编码降低计算复杂度,兼顾检测精度与实时性,成功打破传统模型对预定义类别的依赖,为自动驾驶、机器人视觉等动态开放环境提供灵活可靠的视觉理解解决方案。
3、部署及应用

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)