刷完了端到端和VLA新工作,这9个开源项目最值得复现......
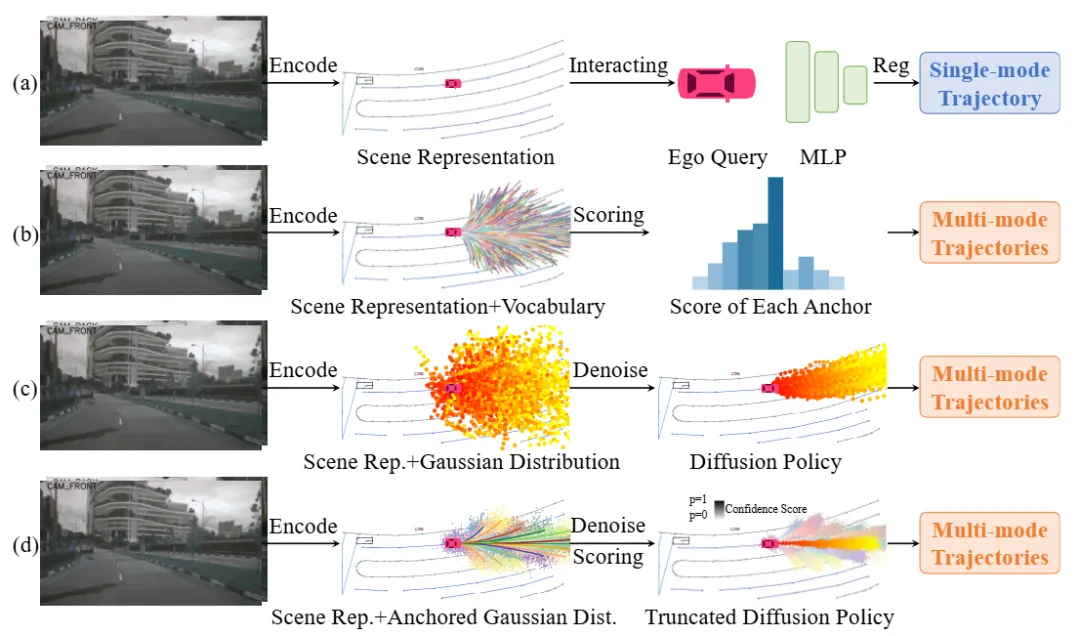
DiffusionDrive 针对扩散模型在端到端自动驾驶规划中“多样性生成”与“实时推理”的根本矛盾,提出了高效的解决方案:通过引入多模态驾驶锚点作为结构化先验,并结合截断扩散日程,将模型从传统的多步去噪简化为仅需 2-4 步 的快速生成,在保持动作分布多样性与合理性的同时,实现了45 FPS的实时性能(基于4090)。该模型仅依赖视觉输入,通过共享表征学习,使同一个网络既能完成闭环驾驶,又能进

「最前沿的工程化方向」
目录
开源是最诚实的答案。
本文精选了 2025 年高价值的开源项目,不以会议论英雄,只看复现热度与工程参考性。这些仓库提供了从数据清洗、训练配方到闭环评测的全套方案,是快速上手端到端自动驾驶的最佳捷径。
需要说明的是,2025 年开源的自动驾驶项目真的太多了,随着AI技术的发展,开源项目数量正在快速增长,优秀的工作远不止本文所覆盖的范围。本文主要以 GitHub 上已公开的项目为线索进行整理,筛选标准以代码可获取性和项目活跃度为主(具有一定Star数量),难免存在遗漏。未被提及的相关工作同样具有参考价值,读者可结合自身研究方向进一步查阅和补充。
DiffusionDrive
Github Star:1.2K
机构:华中科技大学;地平线
亮点:DiffusionDrive 针对扩散模型在端到端自动驾驶规划中“多样性生成”与“实时推理”的根本矛盾,提出了高效的解决方案:通过引入多模态驾驶锚点作为结构化先验,并结合截断扩散日程,将模型从传统的多步去噪简化为仅需 2-4 步 的快速生成,在保持动作分布多样性与合理性的同时,实现了45 FPS的实时性能(基于4090)。其设计的级联条件解码器确保了场景信息与动作的高效融合,在NAVSIM基准上取得88.1的PDMS,验证了规划质量。此项工作不仅验证了极简扩散步数在动态场景中的可行性,更通过完整开源代码与模型,为行业提供了一个兼具高性能、高实时性与强可用性的端到端规划基线。
链接:https://github.com/hustvl/DiffusionDrive?tab=readme-ov-file
OpenEMMA
Github Star:0.9k
机构:德克萨斯农工大学;密歇根大学;多伦多大学
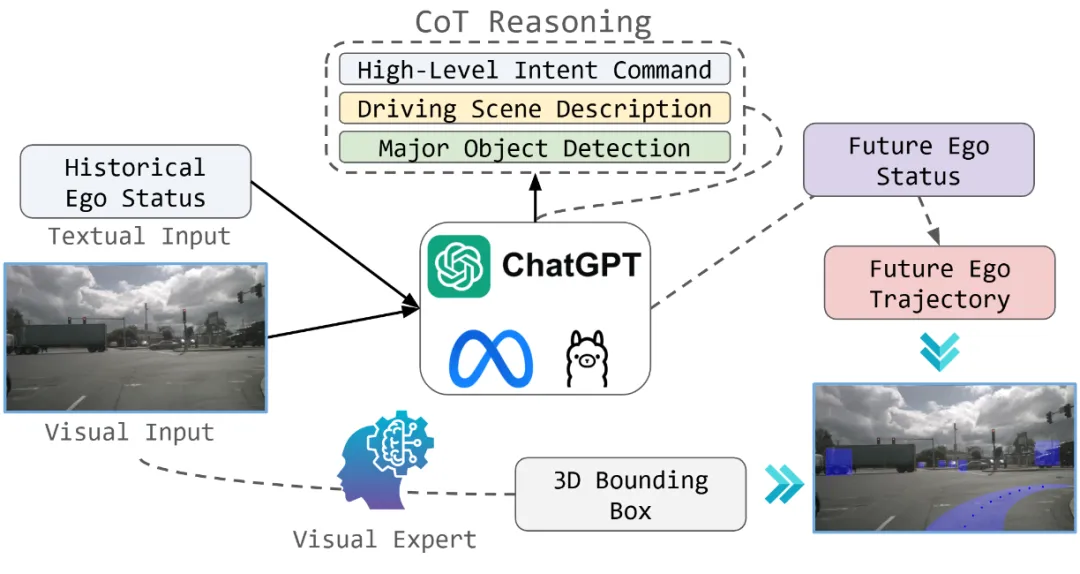
亮点:OpenEMMA 针对多模态大语言模型在端到端自动驾驶中训练成本高、部署难度大的现实瓶颈,提出了一种轻量化且可泛化的框架:通过引入 Chain-of-Thought 推理机制,引导模型在完成驾驶决策时显式生成逻辑推理链条,从而在多种现有 MLLM 上稳定提升其在复杂场景下的泛化与可靠性。该框架无需从头训练巨量参数,显著降低了算力与数据门槛,并以完整开源代码提供了一套可复用的工程模板,使研究者能够快速将不同的多模态大模型适配到端到端驾驶任务中,有效加速了 MLLM 在自动驾驶领域的落地探索。
链接:https://github.com/taco-group/OpenEMMA
Diffusion-Planner
Github Star:0.8k
机构:清华大学;中国科学院自动化研究所;香港中文大学;上海交通大学;毫末智行;上海人工智能实验室
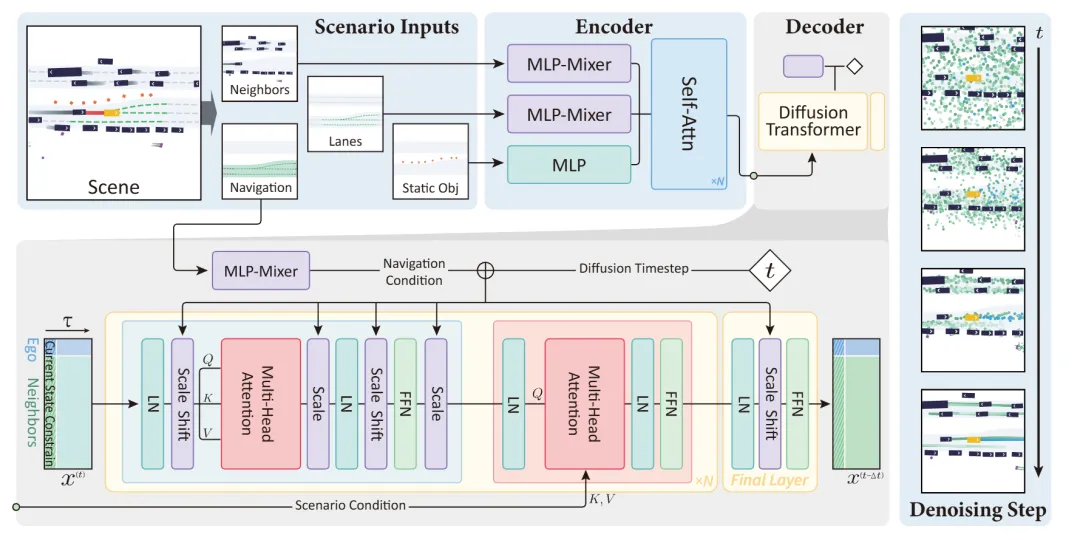
亮点:针对模仿学习在自动驾驶规划中常产生的“平均解”困境,提出了一个基于Transformer的扩散规划模型。其核心是通过扩散过程从噪声中生成多模态轨迹,从根本上支持对同一场景的多种合理驾驶行为进行表达,且无需依赖后置手写规则来修正轨迹质量。该模型创新性地将轨迹预测与自车规划置于同一架构中进行联合建模,以促进车辆间更自然的交互配合。关键技术在于引入了通过学习型打分函数实现的梯度引导机制,能够安全、灵活地将生成过程导向目标方向,从而在开放环境中实现既多样又可靠的规划。该方法在nuPlan大规模闭环基准上取得领先性能,并在一套200小时的实车配送数据集上验证了其对不同驾驶风格的适应能力。
链接:https://github.com/ZhengYinan-AIR/Diffusion-Planner
UniScene

Github Star:0.5k
机构:上海交通大学;东方理工大学宁波数字孪生研究院;清华大学;旷视科技;Mach Drive;复旦大学;香港大学
亮点:UniScene 针对自动驾驶高质量数据获取成本高昂的瓶颈,提出了一个以占据(occupancy)为统一中间表达的多模态生成框架。该方法采用分层生成思路:首先从用户定义的道路布局生成具有几何与语义信息的BEV占据图,再基于该结构化表示分别生成多视角视频与LiDAR点云。这种“布局→占据→多模态数据”的渐进式生成机制,不仅降低了复杂场景合成的难度,也使占据图自带标注属性,可直接为下游任务提供监督信号。实验表明,该方法在占据、视频与点云生成质量上均优于此前方案,且所合成数据能有效提升感知、预测等任务的性能。从工程角度看,该框架的核心价值在于提供了一套可复用的多模态数据生成流水线,能够从同一场景布局同步产出视频、点云与占据标注,显著降低不同自动驾驶模块在数据制备上的重复投入。
链接:https://github.com/Arlo0o/UniScene-Unified-Occupancy-centric-Driving-Scene-Generation
ORION
Github Star:0.5k
机构:华中科技大学;小米汽车
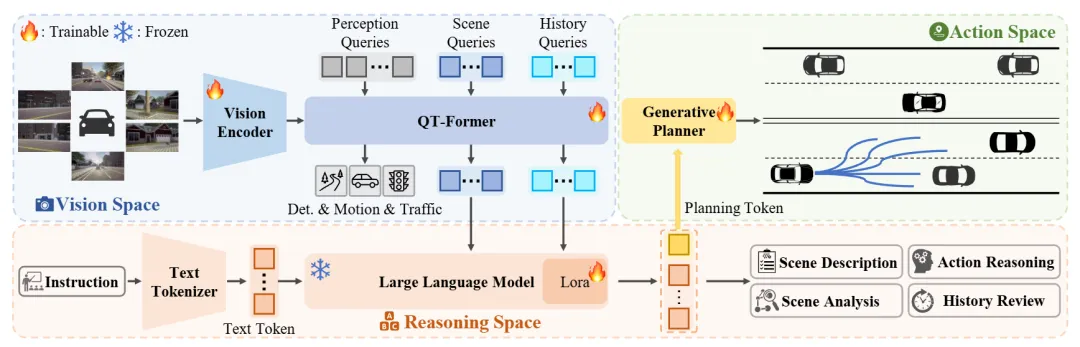
亮点:ORION 针对端到端自动驾驶中因果推理与轨迹生成脱节的核心问题,提出了一个统一对齐视觉、推理与动作空间的框架。它通过 QT-Former 聚合历史信息,并利用 LLM 进行场景理解后输出高层“规划 token”,再由生成式规划器将该 token 解码为具体、可执行的多模态轨迹。该方法的关键在于进行端到端的联合优化,使语义推理能够直接驱动稳定、合理的轨迹生成,从而在 Bench2Drive 闭环评测中显著提升了驾驶得分与成功率。
链接:https://github.com/xiaomi-mlab/Orion
FSDrive
Github Star:0.5k
机构:西安交通大学;高德地图;阿里巴巴达摩院
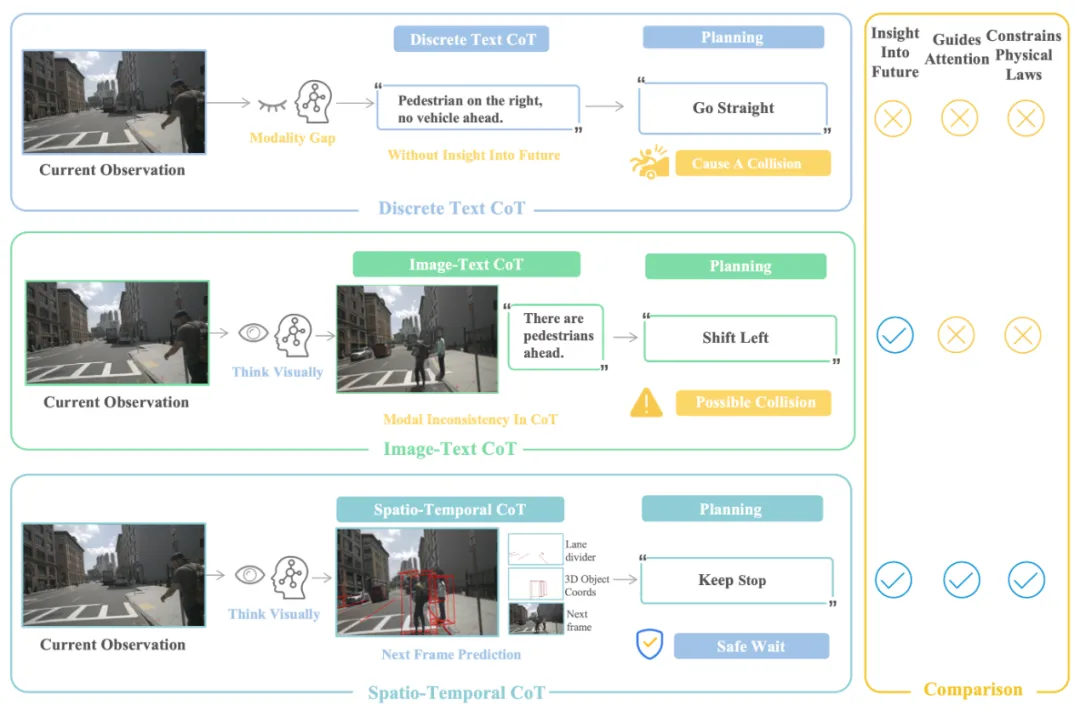
亮点:FSDrive 针对 VLA 在端到端驾驶规划中因依赖纯文字推理(CoT)而导致视觉细节丢失、形成模态断层的问题,提出了 “用画面思考”的视觉化推理范式。其核心是训练一个统一的 VLA 模型,使其既能作为世界模型预测包含车道线、3D 边界框等结构化先验的未来场景画面,又能基于当前观测与这幅“预演图”通过逆动力学生成精确轨迹,从而用更丰富的视觉中间表示弥合感知与规划间的鸿沟。该方法通过将视觉 token 纳入词表进行统一预训练,并采用从结构化先验到完整渲染的课程学习策略,有效提升了模型对物理规律的遵从与生成质量。实验表明,其在 nuScenes、NAVSIM 等基准上显著提升了轨迹精度与安全性,同时保持了优异的场景理解能力。该工作为“视觉化 CoT”提供了可复用的工程模板,推动了基于未来想象的规划范式在实际系统中的落地。
链接:https://github.com/MIV-XJTU/FSDrive
AutoVLA
Github Star:0.5k
机构:加利福尼亚大学洛杉矶分校
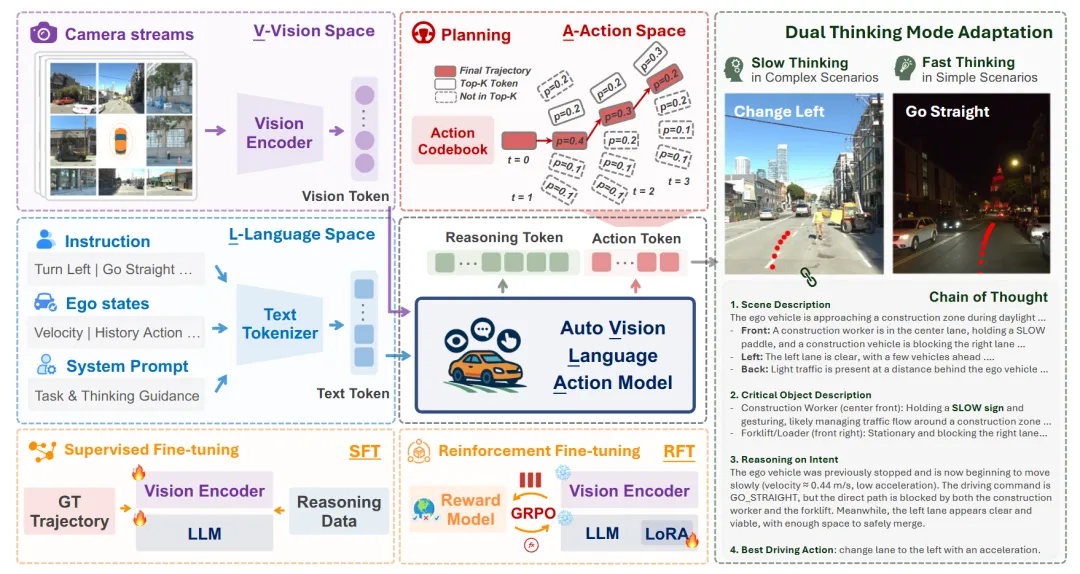
亮点:AutoVLA 针对现有 VLA 驾驶模型输出动作物理可行性差、系统冗余且推理效率低下的问题,提出了一个统一的自回归生成式框架。其核心创新在于将连续轨迹离散化为物理可行的动作 token,使语言模型能够像生成文本一样直接输出可执行规划,从而在架构层面确保了动作的合理性。该模型通过监督微调学习了自适应推理机制,可根据场景复杂度在“快思考”(直接规划)与“慢思考”)间切换;后续的强化学习微调进一步优化了规划质量并抑制了不必要的冗长推理。在 nuPlan、Waymo 等多个开环与闭环基准上的实验验证了其竞争力。该工作的核心开源价值在于提供了一套完整的工程配方,包括动作 Token 化设计、快慢思考训练与强化微调策略,为构建高效、可靠的 VLA 规划基线提供了可直接复用的模板。
链接:https://github.com/ucla-mobility/AutoVLA
OpenDriveVLA
Github Star:0.5k
机构:慕尼黑工业大学,慕尼黑大学
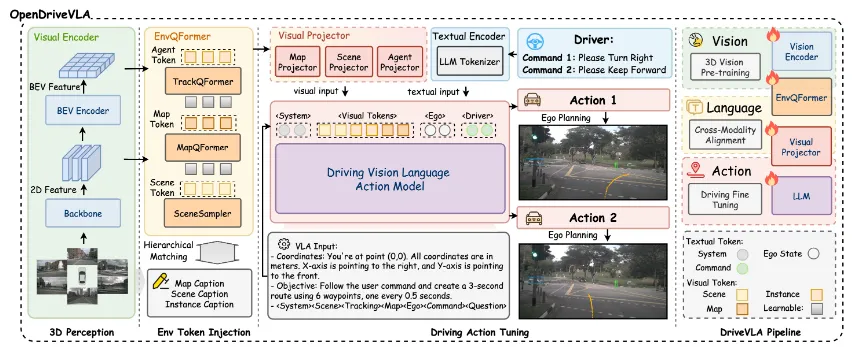
亮点:OpenDriveVLA 是一个开源的端到端驾驶 VLA 模型,其核心在于构建一个统一的生成框架,以直接根据多模态输入(包括2D/3D实例级视觉表示、车辆状态及语言指令)输出驾驶动作。为解决视觉与语言模态的语义鸿沟,模型采用分层视觉-语言对齐方法,将结构化视觉 token 映射到统一语义空间,实现有效融合。在轨迹生成阶段,模型通过自回归解码显式建模车辆与环境的交互关系,使规划结果具备空间与行为感知能力。该模型在 nuScenes 数据集上验证了其在开放环路规划与驾驶问答任务上的有效性,其开源实现为研究社区提供了一个可参考的、整合感知、推理与规划的 VLA 驾驶系统基线。
链接:https://github.com/DriveVLA/OpenDriveVLA
SimLingo
Github Star:0.3k
机构:Wayve;图宾根大学;
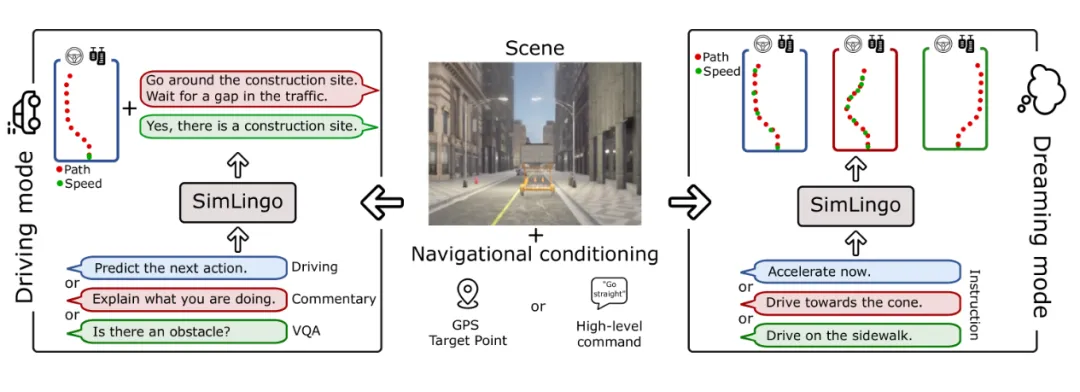
亮点:SimLingo 针对自动驾驶中语言模型常见“言行不一”的割裂问题,提出了一个多任务联合训练框架,旨在实现驾驶行为、视觉语言理解与语言-动作一致性三者的统一对齐。该模型仅依赖视觉输入,通过共享表征学习,使同一个网络既能完成闭环驾驶,又能进行场景问答,并确保其语言描述与驾驶决策在逻辑上保持一致,从而提升了模型的可解释性与行为可靠性。作为 CARLA Challenge 2024 的获胜方案之一,它在 Bench2Drive 等闭环评测中达到领先水平,同时保持了较强的视觉语言理解能力,验证了纯视觉架构下实现高效、可解释且行为一致的端到端驾驶系统的可行性。
链接:https://github.com/RenzKa/simlingo
总结
对于开发者而言,这些仓库不仅是代码,更是工程积木。建议直接 Clone 下来,跑通 Demo,学习其中的模块拆分、指标设计与训练 trick,这比精读十篇论文更能构建你的自动驾驶技术直觉。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 34
34 0
0- 0



 已为社区贡献88条内容
已为社区贡献88条内容

所有评论(0)