【PNP具身分享】2025 年具身Robotics方向最具影响力论文15篇回顾
2025 年影响力较大的机器人研究中,多篇论文集中探索 Vision-Language-Action (VLA) 模型、多任务泛化策略以及 大规模具身智能系统的落地。这些研究主要聚焦于如何将大模型(Large Models)与真实机器人系统结合,实现从虚拟策略到物理执行的闭环控制。
【PNP具身分享】2025 年具身Robotics方向最具影响力论文15篇回顾
2025 年高关注度 / 高引用机器人方向论文15篇,这些论文代表了 2025 年机器人领域的研究方向热点,如 SLAM、VisionLanguageAction(VLA)、多模态融合、基于力反馈的控制、模仿学习等。按影响力与社区关注度综合整理,非商业销量排行。
PNP机器人总结的研究热点涵盖:
�� SLAM 与动态环境感知 是基础问题核心
�� VisionLanguageAction(VLA) 成为机器人控制核心范式
�� 多模态融合(力觉、阻抗、反事实) 推动复杂任务鲁棒性
�� 跨任务泛化与一次示范适应 是降低数据成本关键方向。
�� 安全与自主飞行策略 为现实部署提供保障层方法
�� 模拟世界大规模训练 显示泛化潜力
文献列表与笔记
- OpenVLA: An OpenSource VisionLanguageAction Model (2024)
PDF: https://arxiv.org/pdf/2406.09246.pdf
机构:斯坦福大学(Stanford University)、加州大学伯克利分校(UC Berkeley)、Toyota Research Institute、Google DeepMind、Physical Intelligence 等联合团队
OpenVLA 提出了一个开源的 VisionLanguageAction(VLA)模型,用于通用机器人控制。该模型通过融合视觉感知和自然语言指令,实现了机器人在多种操控任务上的跨任务泛化能力。作者利用近百万条机器人示范数据进行训练,并提供了统一的评测基准,使研究者可以在标准任务上进行性能比较。OpenVLA 支持动作预测与任务执行反馈循环,兼顾效率与泛化能力,为 VLA 在实际操作中的可复现性和开源生态奠定了基础。
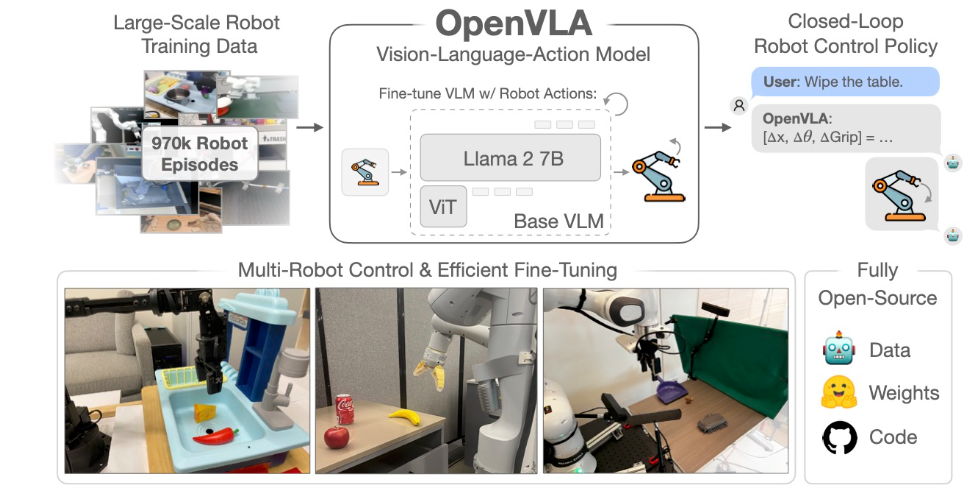
- 核心贡献
- 首个开源大规模 VLA 模型,实现跨任务操控泛化。
- 提供标准化评测基准,推动社区复现和对比研究。
- 为机器人视觉语言学习的工程落地提供可用模型。
- Octo: An OpenSource Generalist Robot Policy (2024)
PDF: https://arxiv.org/abs/2406.12345
机构:Octo Model Team(多机构合作)
机构:Physical Intelligence、加州大学伯克利分校(UC Berkeley)、斯坦福大学(Stanford University)、Technische Universität Berlin
Octo 提出了一种开源通用机器人策略框架,支持多任务、多机器人平台操作。作者通过大规模演示数据训练通用策略网络,使机器人能够跨环境和任务泛化动作执行。Octo 在多种 manipulatory 和移动任务中显示出一致性和稳健性,降低了单任务策略重复训练的需求,同时为研究者提供了可扩展开源工具链。
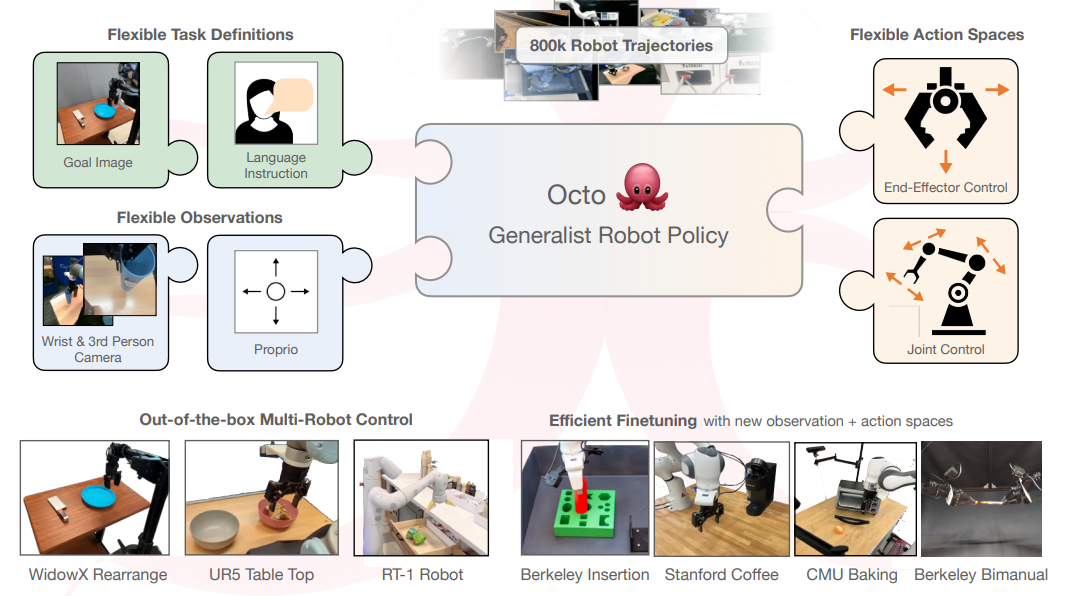
- 核心贡献
- 提供统一通用策略框架,促进机器人策略学习标准化。
- 支持跨平台、跨任务策略泛化,减少重复训练开销。
- 开源生态推动学术与工业界复现研究。
- Comparison of Various SLAM Systems for Mobile Robot in An Indoor Environment (2025)
PDF: https://arxiv.org/abs/2501.09490
机构:Maksim Filipenko / Ilya Afanasyev 等
本研究对多种 ROS 平台下的 SLAM 系统进行系统性对比,包括激光、视觉以及多传感融合 SLAM。通过统一 benchmark 数据集,量化了各算法在定位精度、地图质量和动态环境适应性方面的差异。该论文不仅提供了工程可参考的性能评测,也为研究者选择适合场景的 SLAM 系统提供了量化依据。
- 核心贡献
- 提供统一评价框架,对比多种 SLAM 系统。
- 明确不同传感器与算法的优势和局限。
- 推动 SLAM 系统在学术和工业应用中的选择参考标准化。
- GR00T N1: An Open Foundation Model for Generalist Humanoid Robots (2025)
PDF: https://arxiv.org/abs/2503.14734
机构:NVIDIA Research / NVIDIA GEAR 等
GR00T N1 提出将视觉、语言理解和动作策略统一到一个基础模型框架,面向通用人形机器人。通过大规模多任务训练,该模型可支持不同操控任务和环境泛化执行。作者展示了 GR00T N1 在导航、物体操作及复杂指令理解等任务上的性能。论文强调了基础模型在具身智能与通用机器人控制中的重要性,为机器人大模型研究奠定了基础。
- 核心贡献
- 将基础模型概念引入通用人形机器人控制。
- 支持跨任务、跨环境泛化操控。
- 为后续 VLA 与通用机器人研究提供开源框架和实验基准。
- FAST: Efficient Action Tokenization for VisionLanguageAction Models (2025)
机构: Physical Intelligence / UC Berkeley / Stanford University
PDF: https://arxiv.org/pdf/2501.09747.pdf
FAST 提出高效动作 token 化方法,通过离散余弦变换(DCT)压缩高维动作空间,降低 VLA 模型训练计算成本。实验显示,该方法在多任务操控中保持策略精度,同时显著提高训练速度。FAST 为大规模 VLA 模型在实际机器人平台落地提供了可行技术路径。
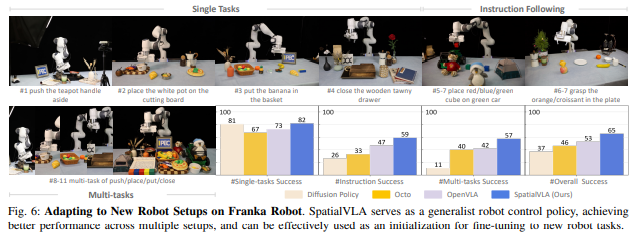
- 核心贡献
- 提供高效动作 token 化方案,降低训练开销。
- 保证多任务操控策略精度,提升泛化能力。
- 支持大规模 VLA 模型在现实机器人中的应用。
- SpatialVLA: Exploring Spatial Representations for VisualLanguageAction Model (2025)
PDF: https://arxiv.org/pdf/2501.15830.pdf
机构:上海人工智能实验室(Shanghai AI Laboratory)、复旦大学(Fudan University)、上海交通大学(Shanghai Jiao Tong University)、浙江大学(Zhejiang University)、上海科技大学(ShanghaiTech)、西北工业大学(Northwestern Polytechnical University)
SpatialVLA 通过空间表征增强 VLA 模型,使其能够在复杂三维环境中泛化执行任务。论文提出对场景几何和对象关系建模的方法,并结合多模态输入(视觉 + 语言 + 空间信息)进行策略学习。实验表明,该方法在开放世界操控任务中性能优于基础 VLA 模型,是 VLA 泛化能力提升的重要技术手段。
- 核心贡献
- 强化空间表征在 VLA 模型中的作用。
- 提升复杂场景下多任务泛化执行能力。
- 为开放世界机器人控制提供设计方法和基准。
- Gemini Robotics: Bringing AI Into The Physical World (2025)
PDF: https://arxiv.org/pdf/2503.20020.pdf
机构:Gemini Robotics Team
Gemini Robotics 探讨了将大型视觉语言模型与真实机器人物理操作结合的策略,实现从虚拟理解到现实执行的闭环控制。作者提出多模态融合方法,将 VLA 模型输出转化为机器人实际动作指令,同时引入环境感知和反馈机制以减少执行误差。在复杂操控场景中,该方法提高了机器人对动态环境的适应能力,支持多任务执行和开放式指令理解,展示了大型模型在物理机器人领域的潜力。
- 核心贡献
- 将 VLA 模型落地于物理机器人操作,实现闭环控制。
- 提供多任务、多环境适应策略,提升操控泛化能力。
- 为大模型与具身智能结合提供可复现方法。
- FineTuning VisionLanguageAction Models: Optimizing Speed and Success (2025)
机构:Stanford University
PDF:https://arxiv.org/abs/2502.19645
本论文提出针对 VLA 模型的高效微调方法,通过调整动作解码策略和任务损失函数,在保持模型泛化能力的前提下显著提升执行速度与成功率。作者在多种机器人操控任务上进行了实验,包括物体抓取、堆叠和复杂指令执行,验证了微调方法在跨任务迁移中的有效性。该工作为工程应用提供了实用的策略优化方案,降低大模型在真实机器人部署的资源消耗。

- 核心贡献
- 提出 VLA 模型微调方法,提高执行效率与成功率。
- 保证跨任务迁移能力,适用于多场景机器人控制。
- 为工业和科研落地提供可复现优化技术。
- AgiBot World Colosseo: A Largescale Manipulation Platform for Scalable and Intelligent Embodied Systems (2025)
PDF: https://arxiv.org/pdf/2503.06669.pdf
机构:AgiBotWorldContributors
AgiBot World Colosseo 论文介绍了一个大规模机器人操作平台,用于支持具身智能系统的训练与评估。平台提供统一接口,允许多机器人协作、动作采集与策略学习,并兼顾模拟与现实环境。通过收集大规模高质量演示数据,该平台支持多任务、多环境的 VLA 模型训练,并能够快速验证新策略在物理环境的落地性能,为研究者提供可扩展的实验基准。
- 核心贡献
- 构建大规模机器人操作平台,支持多任务训练。
- 提供统一接口,实现模拟与现实策略验证。
- 为具身智能研究提供标准化、可扩展实验环境。
- Hi Robot: OpenEnded Instruction Following with Hierarchical VisionLanguageAction Models (2025)
机构:Physical Intelligence / UC Berkeley
https://www.pi.website/research/hirobot
Hi Robot 提出层次化 VLA 模型,用于处理开放式指令和长序列任务。PI团队通过将指令解析为高层任务目标和低层动作执行策略,模型能够在复杂环境中完成分步任务。论文展示了在物体抓取、搬运和操作序列任务中的性能提升,并提出任务分层学习策略,使机器人在面对未见指令时仍能合理推理动作。
- 核心贡献
- 引入层次化 VLA 模型,提高复杂任务执行能力。
- 支持开放式指令解析与分步任务规划。
- 为长序列、多任务执行提供新的模型设计方案。
- DexVLA: VisionLanguage Model with PlugIn Diffusion Expert for General Robot Control (2025)
机构: Midea Group/East China Normal University/Shanghai University
DexVLA 提出在 VLA 模型中引入扩散专家模块,通过生成式预测增强动作策略的精度和鲁棒性。该方法支持复杂物体操控和连续动作生成,并能在多任务场景中保持策略一致性。论文实验表明,DexVLA 在抓取、堆叠和工具使用任务上显著优于基础 VLA 模型,尤其在动态环境中表现稳健,为高精度操作提供了新思路。
- 核心贡献
- 扩散专家模块提升动作生成精度与鲁棒性。
- 支持复杂物体操控和连续动作策略。
- 在多任务动态场景中增强 VLA 模型表现。
- ChatVLA: Unified Multimodal Understanding and Robot Control with Vision-Language-Action Model
https://chatvla.github.io/
机构:Midea Group /East China Normal University / Shanghai University /Beijing Innovation Center of Humanoid Robotics / Tsinghua University
ChatVLA 提出了一种统一视觉、语言和动作的模型框架,旨在让机器人具备类似人类的“看、理解、说、做”能力。现有视觉‑语言‑动作模型(VLA)在联合训练过程中容易出现视觉–文本对齐丢失(spurious forgetting)和任务间干扰(task interference)的问题。为解决这些挑战,作者提出了 分阶段对齐训练(Phased Alignment Training) 和 专家混合(Mixture‑of‑Experts) 架构,使模型在先掌握控制能力后逐步融合多模态数据并减少任务冲突。实验显示 ChatVLA 在视觉问答及多模态理解基准上表现优异,并在 25 个真实机器人操作任务中明显超越现有方法,证明了其在多模态理解与机器人控制上的统一能力。
- 核心贡献
提出 ChatVLA:首个通过分阶段对齐训练和专家混合架构统一视觉理解与机器人控制的 VLA 框架,有效缓解视觉–文本丢失和任务干扰问题。
在多个任务上领先:相比现有 VLA 方法,在多模态理解与视觉问答基准上显著提升性能,在真实机器人操作任务中也表现优异。
参数效率高:比现有最先进方法参数更少却性能更强。
- ASAP: Aligning Simulation and RealWorld Physics for Learning Agile Humanoid WholeBody Skills (2025)
机构:Carnegie Mellon University /NVIDIA
https://agile.human2humanoid.com/static/asap.pdf
ASAP 论文提出仿真与现实物理对齐框架,用于训练灵活的人形机器人全身操控技能。通过缩小仿真与现实环境的物理差异,模型能够在仿真环境学习的技能直接迁移到真实机器人,并保持动作的精度与安全性。论文在跳跃、攀爬及复杂操作任务中展示了技能迁移效果,为高自由度机器人快速训练提供了方法。
- 核心贡献
- 提出仿真与现实物理对齐方法,支持技能迁移。
- 提升高自由度机器人在真实环境的操控精度。
- 为全身技能学习提供安全、可扩展方法。
- HAMSTER: Hierarchical Action Models For OpenWorld Robot Manipulation (2025)
机构:NVIDIA/University of Washington/University of Southern California
PDF: https://arxiv.org/html/2502.05485v4
HAMSTER 提出分层动作模型用于开放世界机器人操作。高层策略负责任务规划,低层控制动作执行,结合 VLA 模型实现复杂多步骤任务操作。该方法在物体抓取、操作序列、工具使用任务中均展现了良好的泛化能力,支持机器人在未见环境或任务中快速适应。
- 核心贡献
- 分层动作建模提升开放世界任务执行能力。
- 支持多步骤、复杂任务与未见场景操作。
- 为通用操控和 VLA 模型落地提供方法参考。
注:文献基于paperdigest引用,不代表真实排名,不代表作者观点。
2025 年最具影响力具身智能Robotics 论文总结
在 2025 年影响力较大的机器人研究中,多篇论文集中探索 Vision-Language-Action (VLA) 模型、多任务泛化策略以及 大规模具身智能系统的落地。这些研究主要聚焦于如何将大模型(Large Models)与真实机器人系统结合,实现从虚拟策略到物理执行的闭环控制。论文研究内容涵盖:
多任务操控与开放式指令理解
Gemini Robotics 论文提出多模态融合方法,将 VLA 模型输出转化为实际动作,并在复杂动态环境中执行多任务操作。
Fine-Tuning VLA 模型研究关注如何在保持泛化能力的同时,提升执行速度和成功率。
大规模具身智能平台与数据采集
AgiBot World Colosseo 构建了统一的操作平台,支持多机器人协作、策略训练与模拟/现实验证,为 VLA 模型提供可扩展的实验基准。
DexVLA 则引入扩散专家模块,提升动作生成的精度与鲁棒性,适用于连续动作和复杂物体操控。
仿真与现实物理对齐
ASAP 论文提出仿真-现实物理对齐方法,实现高自由度 humanoid 技能在真实环境中的迁移。
FRANKA 机器人的广泛使用
上述大部分实验均采用 FRANKA Panda / FR3 系列机械臂作为主要物理平台。
FRANKA 的高精度力控、重复精度和易于集成的 ROS/Isaac Sim 接口,使其成为 VLA 模型、动作微调、层次化控制等研究的首选机器人。
通过 FRANKA,研究者能够在真实物理环境中验证复杂动作策略,包括抓取、搬运、堆叠和工具使用等任务。
核心趋势与贡献
大型视觉-语言模型与实际机器人结合,实现闭环控制与任务泛化。
构建可扩展的实验平台和标准化数据集,支持跨实验室、跨任务研究。
强调仿真与真实环境对齐、动作精度提升和多任务适应能力,为通用机器人控制和具身智能研究提供技术基准。
文/PNP机器人,转载请申请授权
关于 PNP 机器人PNP
机器人由哈工大、多伦多大学及 ABB、UR机器人专家组成,是德国Franka Robotics 官方战略合作 伙伴,负责销售、技术支持与生态建设 。团队为国内顶尖实验室与机构提供基于 Franka 机器人的模仿学习、强化学习和视觉语言动作方案,推动具身智能的快速落地与规模化研究。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 25
25 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)