智元让机器人学会“边干边学”,一台犯错,全部秒级学会避免
作为一名 AI 行业的观察者,我见过太多精巧的算法来来去去。但一直以来,我最看好的,始终是带有进化本能的设计。SOP 最大的价值不是某个具体的技术 trick,而是范式的转变。机器人训练的主战场,从仿真环境 + 人类演示转移到了真实物理世界。在真实世界里,边做边学,像人类学习的方式。现实世界的经验,终于不再是机器人学习的瓶颈,而成为了可扩展的训练资源。如果说 GPT-4 的出现,是因为 OpenA
想象这样一个场景:
你家的机器人走在客厅撞到了一个新买的花瓶。它愣住了,不知道该怎么办。
这时候云端传来了更新—邻居家的同款机器人刚刚学会了如何绕过障碍。几分钟后,你的机器人就掌握了这个技能。
搁到以前这是不可能的,需要停机 → 收集数据 → 离线训练 → 重新部署,至少要几天时间修复。
智元具身研究中心最近发布了一项工作—SOP(Scalable Online Post-training)系统,开始让机器人拥有边干边学的能力。
机器人在真实环境里干活,做错了立刻纠正,这条经验会马上上传到云端,几十秒后所有机器人都学会了。
更关键的是,你家机器人犯的错,邻居家的机器人可以秒级学会避免。多台机器人共享一个不断进化的大脑。
听起来还挺简单?但是在机器人领域,这个事很难。
机器人后训练为什么这么难?
机器人大模型和语言大模型,走的其实是一条路。都是先预训练(学通用能力),再后训练(学特定任务)。
第一步已经有了—各种 VLA 大模型已经证明,大规模预训练可以让机器人获得通用能力。但一直缺第二步—一个好的、可扩展的在线后训练方案。
为什么 ChatGPT 能通过 RLHF 持续进化,因为它的训练数据是数字的,可以无限生产、开副本。
但是机器人不行。每次抓取失败,要重置场景,10 次失败可能就是一个小时没了。因为物理世界的试错,贵得要命。所以机器人领域的后训练,一直卡在这:离线、单机、周期长,根本扩展不起来。
智元具身研究中心的 SOP 系统可能就是那个 missing piece。
核心思路只有一句话:把物理世界变成可扩展的训练场,让机器人集群在真实世界中持续学习,实时进化。
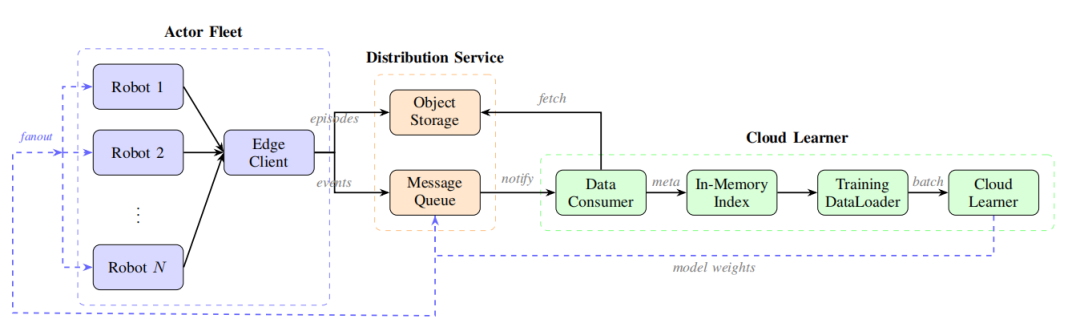
SOP 搭建了一个持续闭环的架构:
机器人执行 → 实时上传数据 → 云端学习 → 模型更新 → 立即下发。

看到这个框架时,我脑子里突然蹦出一部电影—《瞬息全宇宙》(Everything Everywhere All at Once)。

用它来理解 SOP,还挺贴切的:
-
Everything:叠衣服、组装纸盒、货架补货……所有任务同时进行
-
Everywhere:几十台机器人分布在不同物理环境,天然打破单机数据的时间相关性
-
All at Once:所有经验实时并行汇聚,智能瞬间同步
SOP 如何让机器人边干边学?
整套系统的运转逻辑,可以拆成两个角色:
-
前线:机器人(Actor)
机器人在真实世界里干活,同时也是数据采集员。
它们一边执行任务,一边把自己的"实战录像"实时回传云端——不光传成功的,失败的更要传。
为什么?
因为"失败-被人类纠正"这种数据,比一万条完美演示都有用。
-
后方:云端大脑(Learner)
云端 GPU 集群是真正的"总指挥部"。
它不等任何一台机器人,而是异步运转—有数据就学,学完就发新参数。
传统模式下(比如早期特斯拉 FSD),数据闭环周期是周甚至月。而 SOP 把这个速度压到了分钟级。
云端的数据池里混着两类经验:
-
(在线数据): 机器人刚传回来的新鲜热辣的实战经验。
-
(离线数据):以前存好的人类专家完美演示。
关键问题来了:这两类数据怎么混合?
SOP 的做法是设计一个动态学习权重采样器,看模型哪里菜,就给它补哪门课:
它会盯着模型的 Loss 损失值看:如果模型在某个任务上错误率飙升(Loss 高),系统会自动调高在线数据的比例,让它猛补实战经验;等适应了,再把离线数据的权重调回来,防止它忘了基本功。
有点像健身教练看你深蹲不行,就临时加深蹲课,而不是死板地按原计划练胸。最妙的一点的是物理世界的异构性。
论文里的实验用了 10 台双臂机器人,分布在不同场景里执行不同任务:4 台在超市理货,3 台在叠衣服,3 台在组装纸箱。
这看起来是个麻烦事——每台机器人遇到的情况都不一样,数据乱七八糟。
但这恰恰是 SOP 最强的武器—在传统机器学习眼里,这叫"噪声"。
在 SOP 眼里,这叫天然的数据增强。
当一台机器人在光滑桌面上打滑,另一台在粗糙地毯上卡住,第三台面对完全不同形状的衣服—这些同时发生的多样化失败,给了模型极其丰富的学习信号。
效果相当于告诉模型:
别去拟合某一台机器的特殊情况,去学真正通用的动作逻辑。
最后提一点 SOP 的架构设计哲学:
它把系统层(数据怎么传、怎么同步)和算法层(用什么学习方法)彻底分开了。
你可以把 SOP 理解成一台 Switch 主机—底层的网络通信、分布式调度都帮你搞定了,你只需要插入不同的算法卡带(模仿学习、强化学习、或者未来任何新的算法),系统就能跑起来。
所以论文里反复强调一点:SOP is agnostic to the choice of post-training algorithm(SOP 对后训练算法的选择是无关的)。
目前 SOP 已经适配了最主流的两种算法:
-
HG-DAgger(交互式模仿学习):原本是一对一示教,人类手把手教一台机器。SOP 把它升级成集群共享纠错:一次示范,全体受益。
-
RECAP(离线强化学习):原本只能离线复盘历史数据,容易"纸上谈兵"。SOP 让它变成在线实战:边打边学,实时修正。
实验分析
实验一:3 小时在线 vs 80 小时离线
研究者准备了三个版本的基础模型:分别用完整预训练数据的 1/8、1/2 和全部(约 160 小时)进行训练,架构完全相同,只是"喂"的数据量不同。然后让它们各自经历 SOP 在线优化,看最终能达到什么水平。
结果很清晰,从下图可以看到:SOP 都能持续提升性能,但天花板取决于预训练的底子,预训练数据越多,不仅起点更高,最终收敛的性能上限也更高。
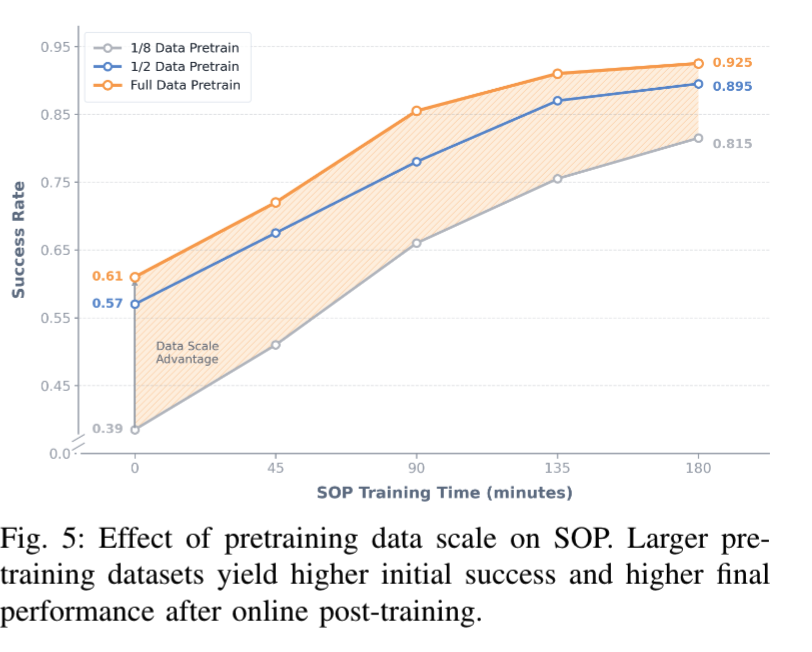
对于用 1/2 数据预训练的模型,如果再追加 80 小时人类演示数据,成功率只从 0.576 小幅提升到 0.612;而 SOP 仅用 3 小时在线交互,就把成功率从 0.571 拉到了 0.800。
差距为什么这么大?
因为离线数据是"冻结的",而 SOP 直接从机器人自己的失败中学习,把学习精准分配到最需要改进的地方。
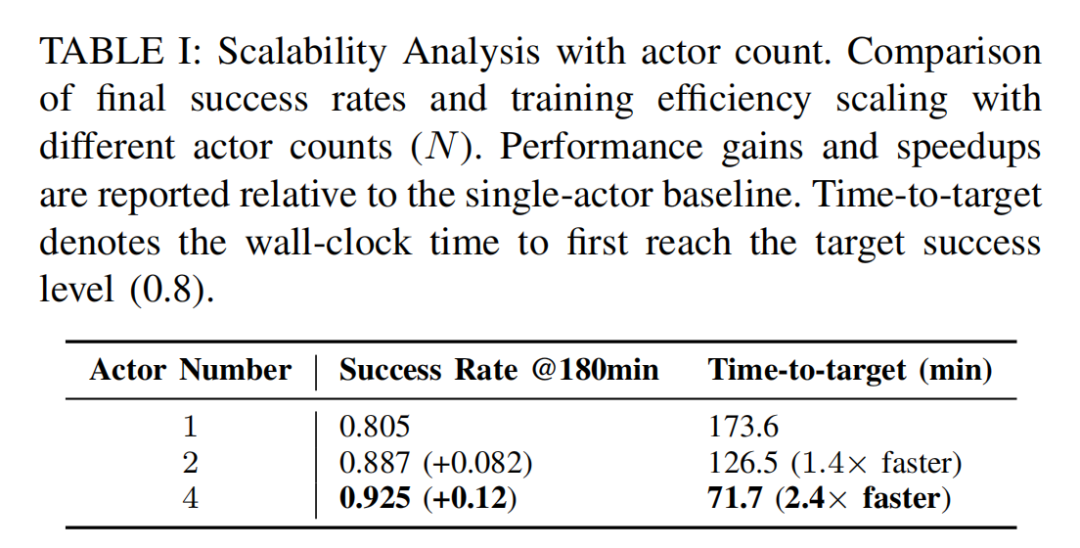
实验二:4 台机器人,训练速度提升近 60%
分别用 1 台、2 台、4 台机器人,在相同总训练时间内学习同一个任务。结果相当亮眼:
-
从 1 台扩展到 4 台,同样训练 180 分钟后,最终成功率从 0.805 提升至 0.925
-
time-to-target 从 1 台的 173.6 分钟,降至 4 台的 71.7 分钟(原来一台的速度的 2.4 倍)
多机器人并行数据收集提供了更多样化的在线策略经验,而且,多台机器人带来的数据多样性,本身就是一种天然的正则化,减少了单机器人场景中对特定站点噪声和特性的过拟合。多台机器人带来的数据多样性,本身就是一种天然的正则化——这打破了我们熟悉的"边际效应递减"规律。
实验三:任务性能提升,效率翻倍
在叠衣服这种高难度柔性任务中,传统离线方法一旦抓歪就直接失败,吞吐量大概是 21 次/小时。接入 SOP 后,机器人学会了一个关键能力——恢复行为。抓歪了?没关系,微调姿态再来一次。
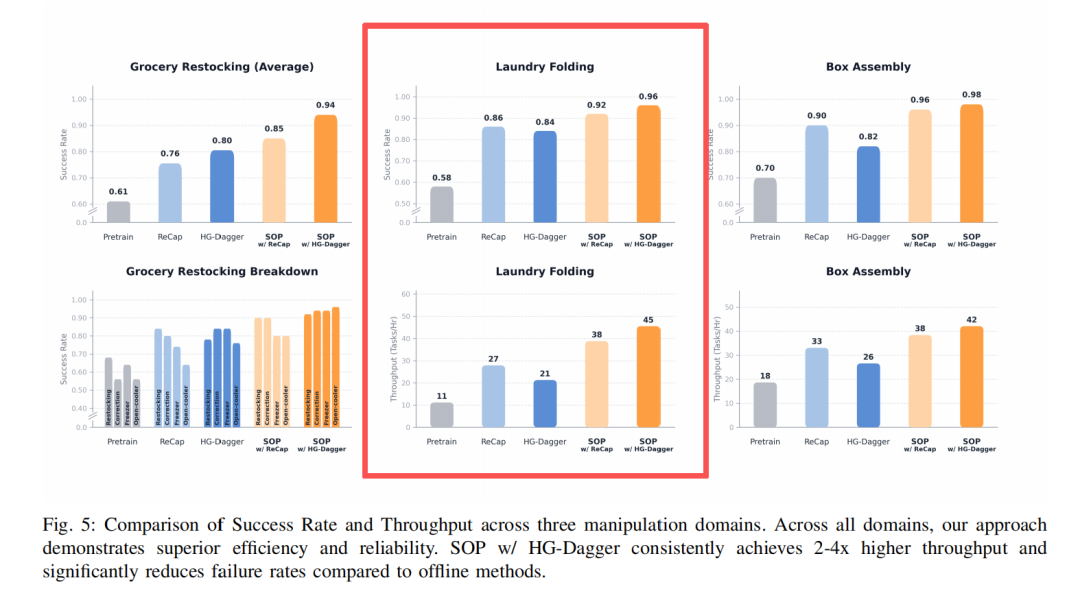
结果,叠衣服的吞吐量飙升至 42 次/小时,效率直接翻倍。
在叠纸盒的任务测试中,SOP完成了36 小时以上的稳定连续运行且无性能衰减。
而且,在人类干预下,还会“自发”地采用补救行为。
机器人在叠衣服期间执行任务的实录,可以看到在被人类干扰后,机器人能够立刻调整补救,可以直观感受 SOP 带来的稳定性和效率的提升~
结语
作为一名 AI 行业的观察者,我见过太多精巧的算法来来去去。但一直以来,我最看好的,始终是带有进化本能的设计。
SOP 最大的价值不是某个具体的技术 trick,而是范式的转变。机器人训练的主战场,从仿真环境 + 人类演示转移到了真实物理世界。
在真实世界里,边做边学,像人类学习的方式。现实世界的经验,终于不再是机器人学习的瓶颈,而成为了可扩展的训练资源。
如果说 GPT-4 的出现,是因为 OpenAI 把预训练和后训练都做到了极致,那么机器人的 GPT-4 时刻,可能就在 SOP 这样的系统框架成熟之后。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 13
13 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)