MindDrive:一种基于在线强化学习的自动驾驶视觉-语言-动作模型
25年12月来自华中科技大学和小米电动汽车的“MindDrive: A Vision-Language-Action Model for Autonomous Driving via Online Reinforcement Learning”。目前自动驾驶领域的视觉-语言-动作(VLA)范式主要依赖于模仿学习(IL),但这会带来诸如分布偏移和因果混淆等固有挑战。在线强化学习提供一种有前景的途径,
25年12月来自华中科技大学和小米电动汽车的“MindDrive: A Vision-Language-Action Model for Autonomous Driving via Online Reinforcement Learning”。
目前自动驾驶领域的视觉-语言-动作(VLA)范式主要依赖于模仿学习(IL),但这会带来诸如分布偏移和因果混淆等固有挑战。在线强化学习提供一种有前景的途径,可以通过试错学习来解决这些问题。然而,将在线强化学习应用于自动驾驶中的 VLA 模型会受到连续动作空间中探索效率低下的限制。为了克服这一限制,提出 MindDrive,这是一个包含两个不同 LoRA 参数集的大语言模型(LLM) VLA 框架。其中一个 LLM 作为决策专家,负责场景推理和驾驶决策,而另一个则作为动作专家,将语言决策动态地映射到可行的轨迹。通过将轨迹级别的奖励反馈到推理空间,MindDrive 能够在有限的离散语言驾驶决策集合上进行试错学习,而不是直接在连续动作空间中操作。这种方法有效地平衡复杂场景下的最优决策、类人驾驶行为以及在线强化学习中的高效探索。使用 Qwen-0.5B LLM,MindDrive 在极具挑战性的 Bench2Drive 基准测试中取得 78.04 的驾驶分数(DS)和 55.09% 的成功率(SR)。
如图所示比较用于强化学习(RL)范式的不同视觉-语言-动作(VLA)模型。决策专家和行动专家共享一个基础视觉-语言模型,但使用不同的LoRA适配器。MindDrive利用行动专家将决策专家的语言推理映射到具体的轨迹,并通过利用行动奖励在线改进模型的推理能力。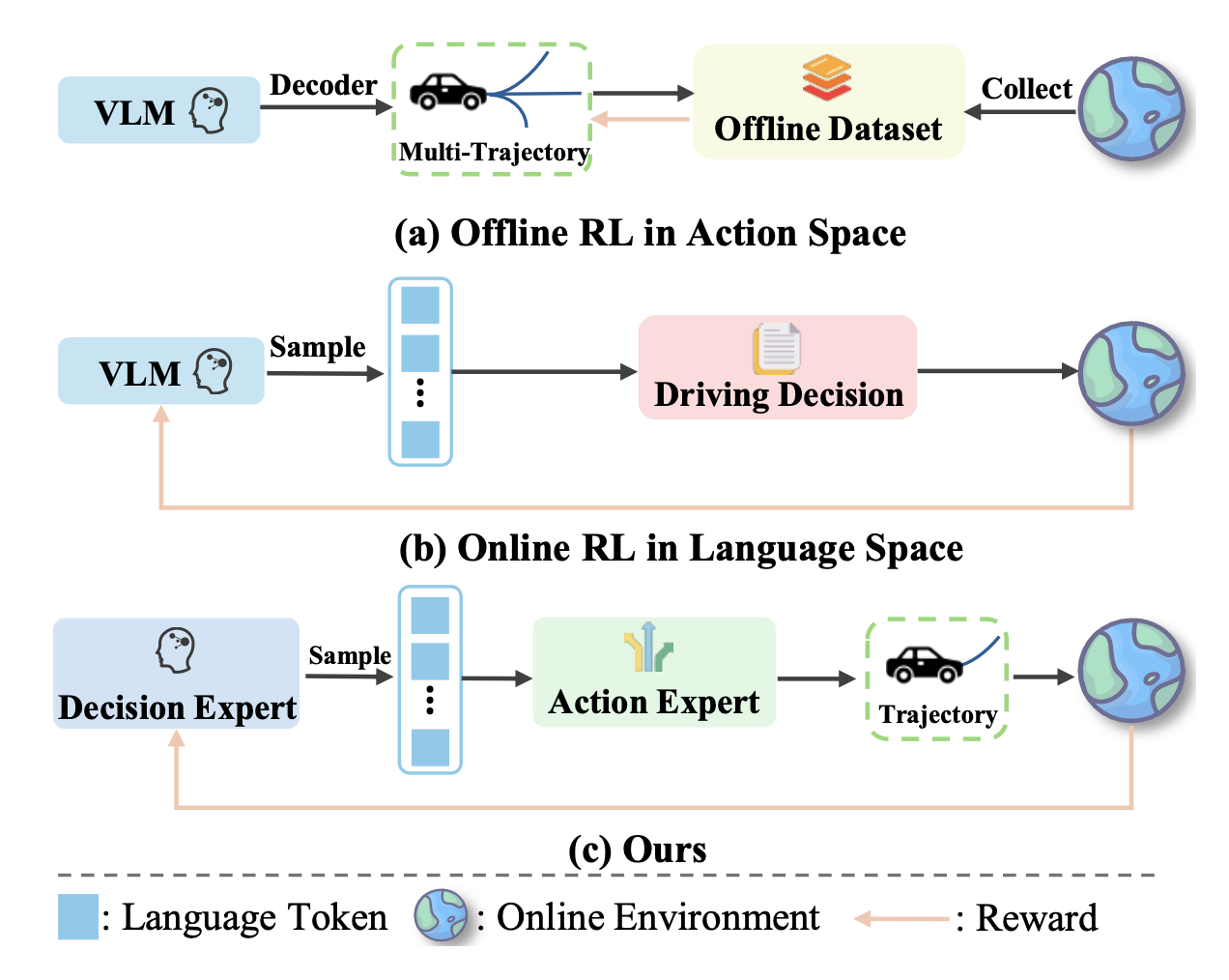
具体来说,MindDrive 由两个同质的大语言模型(LLM)组成,它们唯一的区别在于各自的 LoRA 适配器 [13]。其中一个 LLM 充当决策专家,负责根据当前场景做出合理的决策;另一个则充当行动专家,负责将推理结果动态映射到连续的轨迹。MindDrive 首先利用模仿学习(IL)在决策专家推断出的元动作和行动专家输出的多模态轨迹之间建立一对一的对应关系。行动专家输出的高质量驾驶轨迹为在线强化学习提供合理且符合人类驾驶习惯的候选方案。随后,用在线强化学习来优化决策专家,使其能够通过采样不同的轨迹并从在线交互环境中接收相应的奖励信号来学习如何做出正确的决策。
如图所示,MindDrive 架构由两个主要组件组成:决策专家和行动专家。它们共享同一个视觉编码器和文本token化器,但仅在各自的 LoRA 参数上有所不同 [13]。决策专家根据导航指令和多视角视觉输入进行高级推理,生成以元动作形式表示的抽象驾驶决策。行动专家根据场景信息和指令,将这些元动作转换为具体的动作轨迹。这种设计实现了灵活且可解释的动作生成,将高级推理与低级控制联系起来。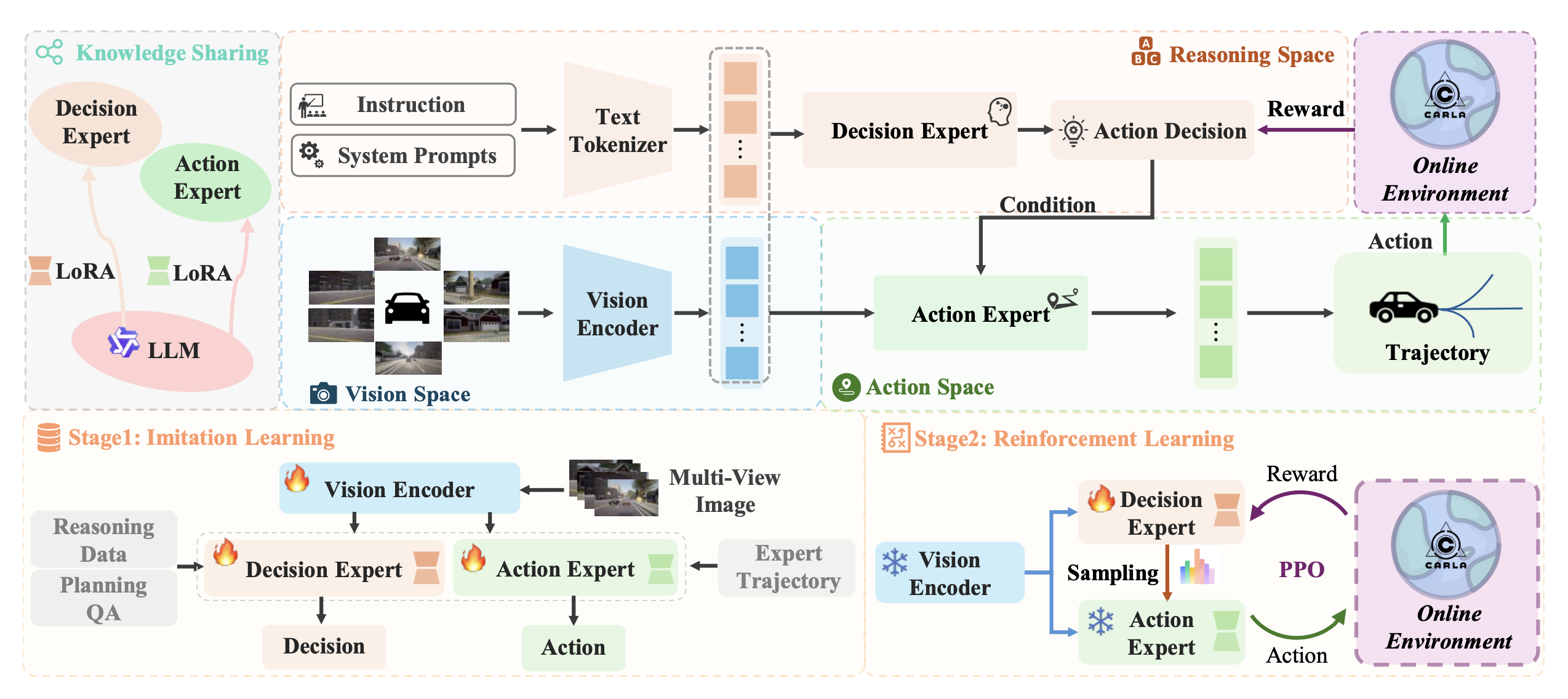
训练过程包括两个阶段:1)模仿学习 (IL) 建立语言和动作空间之间的映射,为在线强化学习 (RL) 提供高质量的候选轨迹,并有效减少其探索空间。2)在线强化学习通过在线环境中的动作奖励进一步增强模型的理解能力。
问题描述
在端到端自动驾驶任务中,目标是生成一组多样化的轨迹集合 A,并根据周围的视觉信息 V 和语言指令 L 确定最优轨迹 a*,其中 a_i 表示多模态轨迹集合 A 中的轨迹,π_g(a | V, L) 是轨迹生成策略函数。目前的方法通常基于评分选择策略 π_c 来选择最优轨迹。
为了充分发挥 VLA 模型的潜力,将选择任务建模为动作决策过程,并引入 π_d(a | V, L) 作为选择策略函数。
最优轨迹的生成取决于两个核心策略函数:π_d 和 π_g。以往的方法未能在线强化学习中建立这两个策略空间之间的联系。为了解决这一挑战,本文建立一种从语言元动作到轨迹的映射关系,然后利用轨迹反馈,通过在线强化学习来优化 π_d 的推理过程。
在线强化学习,使模型能够通过与环境的动态交互持续学习和优化其策略,这对于增强模型对因果关系的理解至关重要。将轨迹决策过程建模为马尔可夫决策过程 (MDP) [55, 59],用于在线强化学习。MDP 的结构为一个元组 ⟨S, A, P, R, γ⟩。状态 s_t ∈ S 表示智体在步骤 t 进行决策所需的所有信息。模型根据策略 (π_d, π_g) 从动作空间 A 中选择一个动作。执行动作后,系统根据闭环仿真环境隐式定义的动力学转换到新状态 s_t+1。奖励 r_t ∈ R(s_t) 是一个标量反馈信号,用于评估在状态 s_t 下执行动作的质量。目标是学习一个决策策略 π_d,该策略在折扣因子 γ 的指导下,最大化收集的数据 τ 中预期累积折扣奖励。
语言-动作映射
为了增强决策策略 π_d 和轨迹生成策略 π_θ 之间的协同作用,将单个大语言模型 (LLM) 分解为两个具有不同 LoRA 参数的专用专家模型。一个 LLM 作为决策专家,负责执行策略 π_d,而另一个则作为动作专家,负责执行策略 π_g。这种架构确保它们在共享世界知识的基础上运行,同时执行各自不同的功能。首先利用模仿学习 (IL) 在决策专家和动作专家之间建立映射,从而建立语言和动作之间的联系,并提高后续强化学习过程中的探索效率。
受 [40, 52] 的启发,将控制分解为纵向控制和横向控制,以提高规划灵活性,并在规划问答 (QA) 中设计相应的元动作。用 LLM 生成规划问答对,并通过人工筛选进行优化,以确保语言和动作之间的一一对应关系。然后,用推理数据和规划问答数据对模型进行训练,以学习从语言-到-动作的映射。
然后,在动作专家模块中将元动作映射到用于纵向控制的时间速度轨迹和用于横向控制的几何路径轨迹。具体来说,用动作专家的自回归特性将视觉和语言信息编码到隐状态 x 中,并引入两个特殊tokens <speed_waypoints> 和 <path_waypoints>,以从动作专家的输出中提取对数概率值。
最后,利用基于GRU解码器的变分自编码器(VAE)[28]来对齐语言空间和动作空间,将视觉-语言表示直接转化为最终的动作轨迹。
用常用的检测损失 L_det 进行辅助监督 [10]。变分自编码器 (VAE) 在专家轨迹的监督下,通过 Kullback-Leibler 散度损失进行训练。用 L1 损失作为行为克隆损失,用于速度和路径航点的回归。
用于动作推理的在线强化学习
IL 能够生成类似人类的轨迹,但常常面临因果混淆的问题。为了克服这一难题,在 CARLA 模拟器 [8] 中采用在线强化学习。如图所示,这种在线方法使智体能够通过试错法探索环境,从直接交互及其后果中学习,从而提升模型在复杂场景下的驾驶性能。为了利用 IL 的先验知识,价值网络与 LLM 共享相同的权重,唯一的区别在于其最后一层被替换为多层感知器 (MLP),用于预测状态值。
为了实现高效的部署流程,部署 N 个并行的 CARLA 收集器,重点关注模型在 IL 之后未能完成的不同场景下的路线。在每个步骤中,用视觉编码器处理场景中的视觉信息,并将其转换为状态嵌入。以问题的形式向决策专家提出查询,并从其输出的logits中抽取元动作token样本。抽取的元动作样本随后由动作专家映射到动作空间中的精确轨迹。同时,价值网络用于估计每个决策步骤中当前状态的价值。
鉴于MindDrive已通过IL预训练掌握基本的驾驶技能,采用稀疏奖励函数来指导其高级推理空间的优化。具体而言,当车辆成功到达目的地时,奖励+1;当触发预定义的惩罚事件时,奖励-1。对于所有其他正常的驾驶场景,奖励为0。
其采用官方 CARLA [8] 排行榜指标作为惩罚事件。惩罚事件包括重大违规行为,例如与其他车辆发生碰撞和闯红灯。一旦触发任何惩罚事件,轨迹生成过程就会终止。
收集完一条完整的路线后,用时序差分法计算 δ 值。然后,计算广义优势估计 (GAE)。
其没有直接使用多幅图像进行强化学习训练,而是使用视觉编码器提取的状态嵌入来表示当前状态。这种方法可以同时整合时间和视觉信息,并通过避免重复计算来提高计算效率。将每一步的价值、决策动作和奖励存储到数据缓冲区中。
将所有路线收集到轨迹缓冲区后,用近端策略优化 (PPO) 算法 [42] 优化策略 π_d。
同时,为了缓解强化学习微调阶段的灾难性遗忘问题,引入 Kullback-Leibler 散度损失作为正则化项。该损失函数旨在约束决策专家元动作的输出分布。
在训练过程中,只有价值网络中多层感知机(MLP)部分的参数会被更新。优化过程是通过最小化均方误差(MSE)损失函数来实现的。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 20
20 0
0- 0



 已为社区贡献211条内容
已为社区贡献211条内容

所有评论(0)