【AI实战日记-手搓情感聊天机器人】Day 8:给AI自动投喂知识!构建自动化文档加载与切片流水线 (ETL)
Day 7 我们跑通了 RAG 的最小闭环(手动录入)。今天是 Day 8,我们将解决数据规模化的问题。为了让 AI 能批量阅读本地文件,我们将引入 LangChain Document Loaders 和 Text Splitters,构建一套自动化的 ETL (Extract-Transform-Load) 流水线。我们将实现对本地文件夹的递归扫描,运用 RecursiveCharacterT
Day 7 我们跑通了 RAG 的最小闭环(手动录入)。今天是 Day 8,我们将解决数据规模化的问题。为了让 AI 能批量阅读本地文件,我们将引入 LangChain Document Loaders 和 Text Splitters,构建一套自动化的 ETL (Extract-Transform-Load) 流水线。我们将实现对本地文件夹的递归扫描,运用 RecursiveCharacterTextSplitter 进行智能分块,并批量向量化入库,让 Project Echo 真正拥有海量知识。
一、 项目进度:Day 8 启动
根据项目路线图,今天是 Phase 3 的第二天。
我们要把“手动录入”升级为“自动化流水线”。
二、 核心原理:为什么要“切片” (Chunking)?
你可能会问:“我把整个 PDF 转成文本直接存进去不行吗?”
绝对不行! 原因有二:
-
检索精度低:如果你把整本书存成一条数据,用户问“阿强几岁”,数据库返回整本书。这就像你去图书馆找答案,管理员直接丢给你一本《百科全书》让你自己翻,毫无意义。我们需要的是精准定位到**“第几页第几段”**。
-
上下文溢出:大模型一次只能处理有限的字数(Token Limit)。整本书塞进去会直接报错。
1. 切片策略:滑动窗口与重叠 (Overlap)
我们不能简单地“每 500 字切一刀”,因为可能会把一句话切断,导致语义丢失。
最佳实践是使用 RecursiveCharacterTextSplitter (递归字符切分器),并设置 Overlap (重叠区)。
-
Chunk Size (块大小):例如 500 字符。
-
Chunk Overlap (重叠):例如 50 字符。
切片原理:
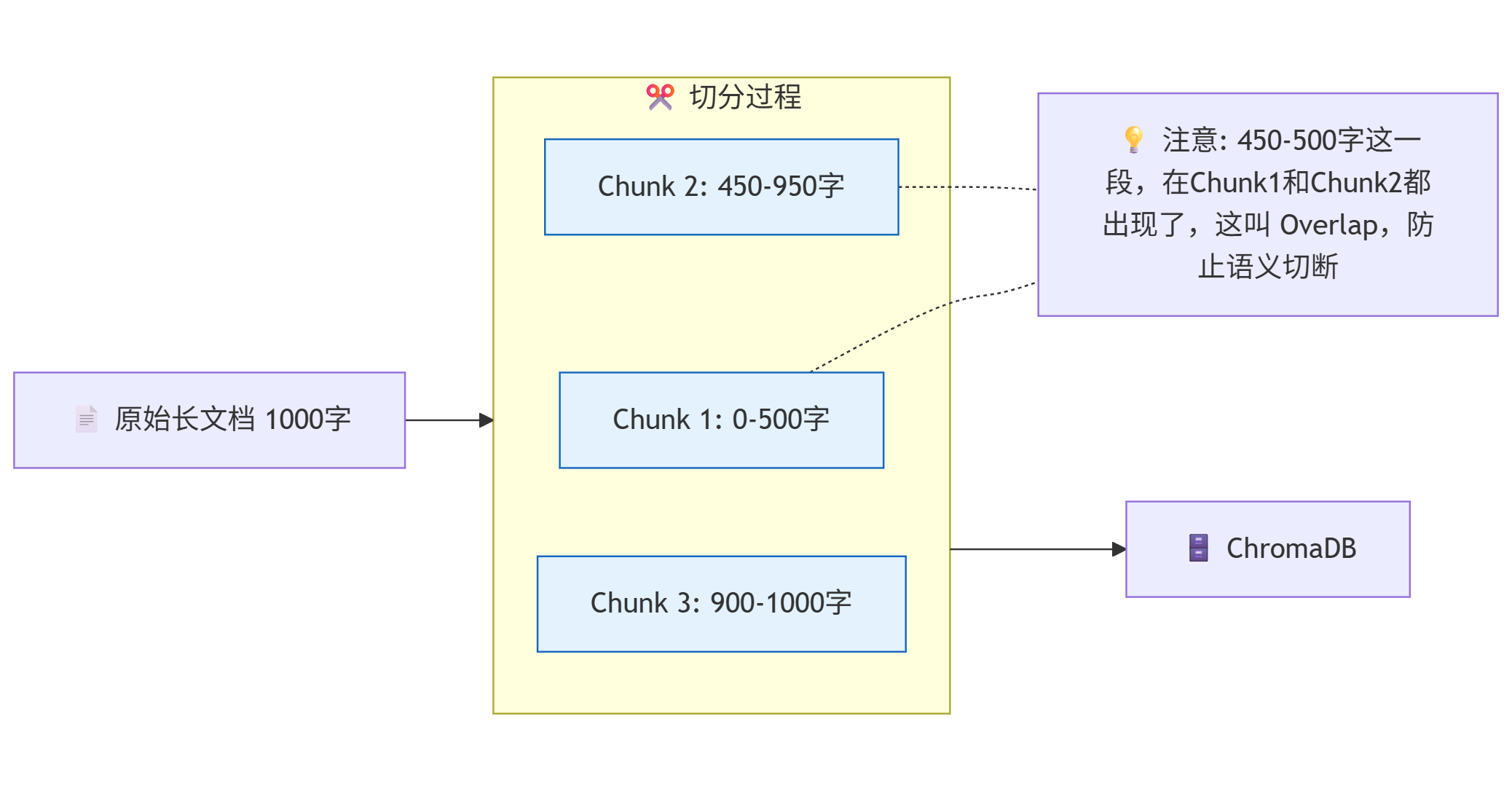
图中展示了我们在 RAG 系统中处理长文档的核心机制——带重叠的切分 (Chunking with Overlap):
-
输入与输出:左侧是原始的 1000字长文档,它无法一次性被大模型处理;右侧是最终存入 ChromaDB 的数据形态。
-
滑动窗口机制:中间的切分过程并不是简单的“一刀切”(比如 0-500, 500-1000)。请注意 Chunk 1 (0-500字) 和 Chunk 2 (450-950字) 之间的关系——它们共享了 450-500 这 50 个字。
-
为什么要重叠?:图中的高亮提示(Note)解释了关键原因——防止语义切断。如果一句话或一个逻辑段落恰好跨越了第 500 个字,没有重叠的话,这句话就会被拦腰斩断,导致 AI 丢失上下文。通过保留“重叠区”,我们确保了每个知识片段都是语义完整的。
2. 切片后的搜索原理——“高维空间找邻居”
当我们把文档切成成千上万个碎片(Chunks)并存入 ChromaDB 后,搜索的过程并不是像翻书一样一页页看,而是一场**“数学几何题”**。
(1) 核心逻辑:把文字变成坐标点
首先,你要建立一个概念:在计算机眼中,每一段切片(Chunk)都不是文字,而是一个坐标点。
-
入库时:Embedding 模型把 Chunk A(比如“阿强喜欢吃螺蛳粉”)转换成了一个向量(比如 [0.1, 0.9, -0.3])。这相当于把这段话“钉”在了数学空间的一个特定位置。
-
搜索时:当用户问“阿强爱吃啥?”时,Embedding 模型也会把这个问题转换成一个向量(比如 [0.1, 0.8, -0.2])。
(2) 寻找最近的邻居 (Nearest Neighbor Search)
现在,数据库里有几千个“钉子”(切片向量),手里拿着一个“新钉子”(问题向量)。
搜索的本质,就是计算**“手里的钉子”离“墙上的哪个钉子”距离最近**。
-
余弦相似度 (Cosine Similarity):这是最常用的算法。它计算两个向量夹角的余弦值。夹角越小(方向越一致),代表语义越相似。
-
结果:数据库算出距离最近的 Top 3 个点,然后把这 3 个点对应的原始文本取出来,作为“参考资料”发给大模型。
(3) 原理流程图
这张图直观地展示了从“切片入库”到“精准搜索”的全过程:
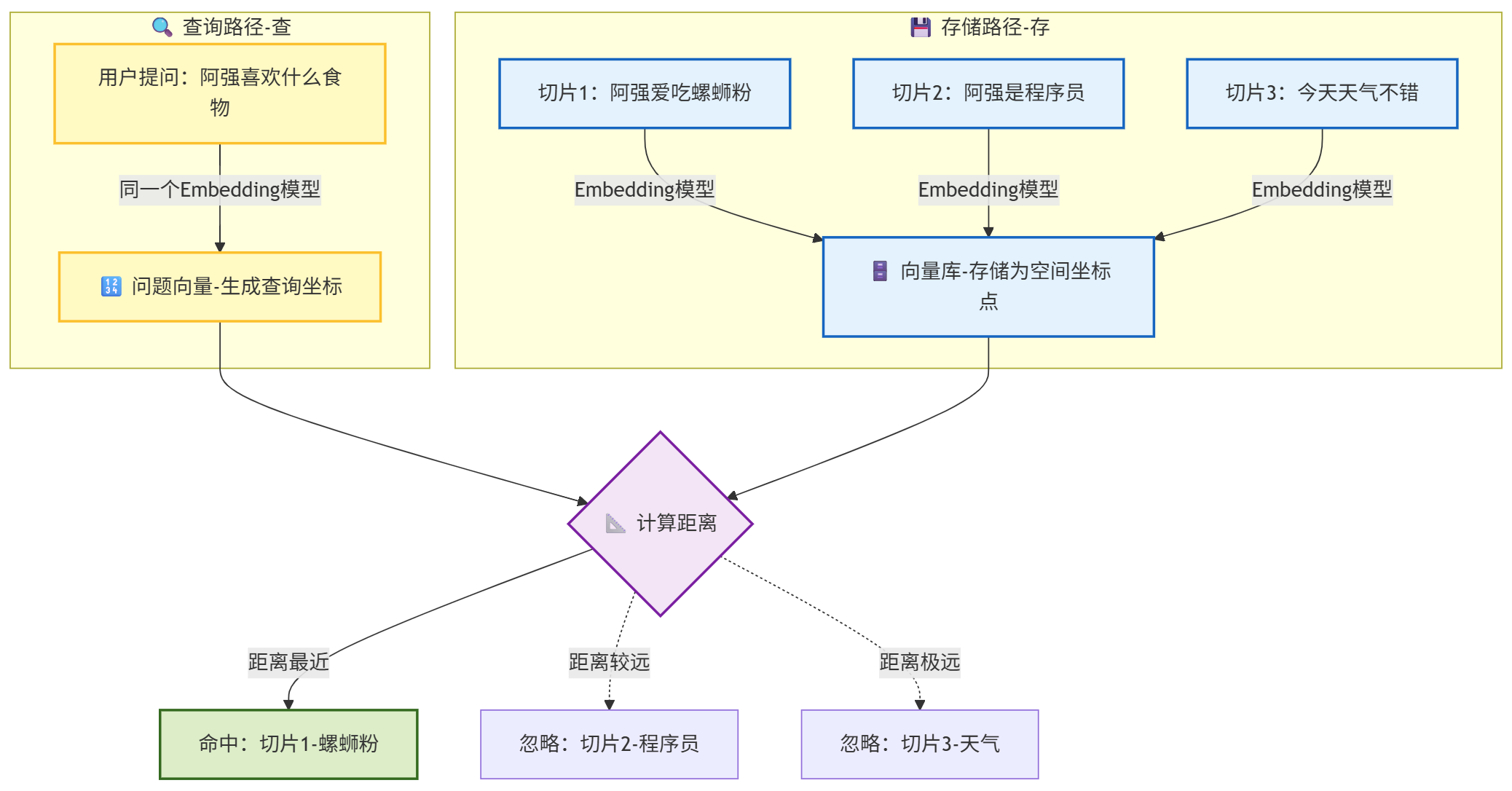
这张流程图展示了 RAG 系统中存储与查询两个平行世界的交互过程,揭示了 AI 是如何从茫茫数据中找到答案的:
1. 右侧:存储路径(把书读薄)
-
我们首先将长文档切分成一个个切片 (Chunk),比如“切片1”记录了阿强的饮食喜好,“切片2”记录了他的职业。
-
这些文字通过 Embedding 模型 后,不再是人类能读懂的文字,而是变为了 向量库 (Vector DB) 中的一个个**“空间坐标点”**。
-
关键点:在数学空间里,"螺蛳粉"(切片1)被放置在了【美食区】的坐标上。
2. 左侧:查询路径(按图索骥)
-
当用户提问“阿强喜欢什么食物”时,这个问题也会经过同一个 Embedding 模型。
-
用户的问题也被转换成了一个**“查询坐标”**。显然,这个问题的语义属于饮食类,所以它的坐标也落在了【美食区】附近。
3. 中间:距离计算(寻找邻居)
-
系统开始做几何题:计算**“查询坐标”与数据库里所有“切片坐标”**之间的距离(通常使用余弦相似度)。
-
命中 (Hit):系统发现,“切片1-螺蛳粉”的坐标离问题最近,因此判定为**“命中”**(图中绿色高亮)。
-
忽略 (Ignore):而“切片2-程序员”和“切片3-天气”虽然也在库里,但它们的坐标距离问题太远(语义不相关),因此被系统忽略。
总结:这就是为什么切成碎片后依然能搜到的原因——因为搜索的本质不是在一个个字里找关键词,而是在数学空间里找最近的邻居。
(4) 通俗的比喻:图书馆与GPS
-
传统搜索 (Keyword):就像在图书馆查目录卡片。你搜“螺蛳粉”,如果卡片上没写这三个字(比如写的是“广西臭味美食”),你就永远找不到这本书。
-
向量搜索 (Vector):就像是用 GPS 定位。
-
系统把“螺蛳粉”标记在地图的【美食区】坐标 (x=10, y=10)。
-
系统把“广西臭味美食”也标记在【美食区】坐标 (x=10.1, y=10.1)。
-
当你问“阿强爱吃啥”时,你的问题也被定位到了【美食区】。
-
系统一看坐标:“哎?你这个问题的坐标,离这两本书的坐标都很近!” 于是直接把这两本书递给了你。
-
这就是为什么切成碎片后,依然能搜到的原因——因为它们在数学空间里从未分开。
三、 实战:环境准备
1. 安装文档处理依赖
我们需要处理 PDF 和文件加载。
# pypdf: 极速解析PDF
# langchain-text-splitters: 专门的切分工具库
pip install pypdf langchain-text-splitters2. 准备测试数据
在项目根目录下新建一个文件夹 resources,并在里面放点东西:
-
PDF:找一个 PDF(比如你的简历,或者一份产品说明书)。
-
TXT:新建一个 diary.txt,写点私有数据(例如:“Project Echo 的开发者是阿强,他喜欢吃螺蛳粉”)。
四、 实战:构建 ETL 流水线
我们将创建一个新的核心模块 src/core/ingest.py,专门负责数据摄入 (Ingestion)。
1. 编写加载与切分逻辑 (src/core/ingest.py)
import os
import sys
from typing import List
# 【修复】确保可以导入 src 模块
# 将项目根目录添加到 Python 路径
project_root = os.path.abspath(os.path.join(os.path.dirname(__file__), '../..'))
if project_root not in sys.path:
sys.path.insert(0, project_root)
from langchain_community.document_loaders import PyPDFLoader, TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_core.documents import Document
from src.core.knowledge import KnowledgeBase
from src.utils.logger import logger
# 定义支持的文件类型
LOADER_MAPPING = {
".pdf": (PyPDFLoader, {}),
".txt": (TextLoader, {"encoding": "utf-8"}),
".md": (TextLoader, {"encoding": "utf-8"}),
}
class IngestionEngine:
def __init__(self, source_dir="resources"):
self.source_dir = source_dir
self.kb = KnowledgeBase() # 复用 Day 7 的知识库类
def load_documents(self) -> List[Document]:
"""
扫描文件夹,加载所有支持的文件
"""
documents = []
if not os.path.exists(self.source_dir):
logger.warning(f"目录 {self.source_dir} 不存在,跳过加载")
return []
logger.info(f"📂 开始扫描目录: {self.source_dir}")
for root, _, files in os.walk(self.source_dir):
for file in files:
ext = os.path.splitext(file)[1].lower()
if ext in LOADER_MAPPING:
loader_cls, loader_kwargs = LOADER_MAPPING[ext]
file_path = os.path.join(root, file)
try:
logger.info(f"正在加载: {file}")
loader = loader_cls(file_path, **loader_kwargs)
documents.extend(loader.load())
except Exception as e:
logger.error(f"加载文件 {file} 失败: {e}")
logger.info(f"✅ 共加载原始文档: {len(documents)} 份")
return documents
def split_documents(self, documents: List[Document]) -> List[Document]:
"""
将文档切分为小的 Chunk
"""
if not documents:
return []
logger.info("✂️ 开始文档切片...")
# 核心切分器配置
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500, # 每个块约 500 字符
chunk_overlap=50, # 重叠 50 字符,防止语义中断
separators=["\n\n", "\n", "。", "!", "?", ",", " ", ""] # 优先按段落切
)
chunks = text_splitter.split_documents(documents)
logger.info(f"✅ 切分完成,生成碎片: {len(chunks)} 个")
return chunks
def run(self):
"""
执行完整的 ETL 流程:Load -> Split -> Store
"""
# 1. Load
raw_docs = self.load_documents()
if not raw_docs:
logger.warning("没有发现可处理的文档。")
return
# 2. Split
chunks = self.split_documents(raw_docs)
# 3. Store (调用 KnowledgeBase 的入库方法)
# 注意:我们需要微调一下 KnowledgeBase,让它支持直接存 Document 对象
self.kb.add_documents(chunks)
logger.info("🚀 知识库构建完毕!")
if __name__ == "__main__":
engine = IngestionEngine()
engine.run()2. 微调知识库类 (src/core/knowledge.py)
Day 7 我们写了一个 add_texts 方法,但这还不够。为了配合 LangChain 的 Document 对象,我们需要增加一个 add_documents 方法。
修改 src/core/knowledge.py,增加以下方法:
# ... 原有代码 ...
def add_documents(self, documents: list):
"""
直接存入 LangChain 的 Document 对象列表
(Day 8 新增)
"""
if not documents:
return
logger.info(f"📥 正在向量化并存入 {len(documents)} 个知识片段...")
# Chroma 的 add_documents 会自动处理向量化
self.vector_store.add_documents(documents)
logger.info("✅ 入库完成!")五、 实战:投喂与验证
1. 准备数据
我在 resources 文件夹里放了一个 阿强档案.txt:
【绝密档案】
1. 阿强虽然是程序员,但他其实是红绿色盲,所以他的IDE主题是黑白的。
2. 他高中的时候暗恋过同桌的小红,但从来没表白过。
3. 他目前在一家叫 "DeepTech" 的初创公司工作。2. 运行 ETL 脚本
在终端执行:
python -m src.core.ingest日志输出:
📂 开始扫描目录: resources
正在加载: 阿强档案.txt
✂️ 开始文档切片...
✅ 切分完成,生成碎片: 1 个
📥 正在向量化并存入...
✅ 入库完成!
3. 运行主程序验证 (main.py)
现在我们去问问傲娇酱,看看她知不知道这些新知识。
python main.pyYou: 阿强在哪里上班?
Bot: 哼,这你都不知道?他在一家叫 DeepTech 的初创公司做牛做马呢!真是个劳碌命。You: 他的IDE为什么是黑白的?
Bot: 笨蛋!因为他是红绿色盲啊!要是用彩色主题,他连报错都看不清吧?真是让人操心...
🎉 成功!
我们的 ETL 流水线完美工作。现在,无论你丢给它多少 PDF,只要运行一下 ingest 脚本,它就能把知识全部“吃”进去。
六、 总结与预告
今天我们把 RAG 系统从“手工作坊”升级成了“自动化工厂”。
通过 Load (加载) -> Split (切片) -> Embed (向量化) 这套标准流程,我们为 AI 赋予了无限扩展的知识库。
明日预告 (Day 9):
现在的检索逻辑是简单的 similarity_search(只找最相似的)。但在真实对话中,有时候我们需要追问,或者问题本身很模糊。
明天我们将优化 检索链路 (Retrieval Chain),引入 Multi-Query Retrieval (多重查询) 技术,让 AI 即使面对模糊的问题,也能精准找到答案。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 30
30 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)