【翻译】FAST-LIVO2:快速,直接的LiDAR惯性视觉里程计
FAST-LIVO2:快速,直接的LiDAR惯性视觉里程计
郑春然 1,徐伟 1,邹祖豪 1,华桐 1,袁崇建 1,何冬娇 1,周炳阳 1,刘政 1,林嘉荣 1,朱方程 1,任云帆 1,王蓉 2,孟凡 2,张富 1*
图1:实时生成的FAST-LIVO2映射结果。(a)-©展示的是航空测绘,(d)代表手持设备采集的一条零售街,(e)演示了一架携带激光雷达、相机和惯性传感器的无人机在机载计算机上进行实时状态估计(即FAST-LIVO2),轨迹规划,并跟踪控制。在(d)-(e),蓝色线表示计算出的轨迹。在(e1)-(e4),白色点表示当时激光雷达扫描的位置,彩色线描绘了计划的轨迹。(e1)和(e4)标记了激光雷达退化区域。(e2)和(e3)显示了障碍物规避。(e5)和(e6)描绘了从室内到室外的第一人称视角摄像机图像,突出了突然过曝到正常照明变化之间的巨大差异(请查看我们在YouTube上的附加视频:youtu.be/aSAwVqR22mo)。
摘要——本文提出FAST-LIVO2:一种快速、直接的LiDAR惯性视觉里程计框架,用于在同步定位与建图(SLAM)任务中实现准确且稳健的状态估计,并为实时、机载机器人应用提供了巨大的潜力。FAST-LIVO2通过误差状态迭代卡尔曼滤波器(ESIKF),高效地融合了IMU、LiDAR和图像测量。为了应对异构LiDAR和图像测量之间的维度不匹配问题,提出了基于ESIKF的多传感器融合方法。
†通讯作者(电子邮件:fuzhang@hku.hk)
机械与机器人系统实验室,香港大学机械工程系,中国香港特别行政区。中国电子科技集团信息科学研究院
公司
我们使用卡尔曼滤波器中的顺序更新策略。为了提高效率,我们在视觉和激光雷达融合中都使用直接方法,其中激光雷达模块注册原始点而无需提取边缘或平面特征,视觉模块最小化直接光度误差而无需提取ORB或FAST角点特征。基于单个统一的体素地图,将视觉和激光雷达测量进行融合,其中激光雷达模块为新扫描的激光雷达构建几何结构,视觉模块将图像块附着到激光雷达点(即视觉地图点),以实现新的图像对齐。为了提高图像对齐的准确性,我们从体素地图中的激光雷达点使用平面先验,并在对齐过程中动态更新参考块。
图像对齐。此外,为了增强图像对齐的鲁棒性,FAST-LIVO2采用按需射线投射操作,并实时估计图像曝光时间。我们分别在基准数据集和私有数据集上进行了广泛的实验,证明我们的系统在准确度、鲁棒性和计算效率方面显著优于其他最先进的里程计系统。此外,系统的各个关键模块的有效性也得到了验证。最后,我们详细介绍了FAST-LIVO2的三个应用:无人机机载导航展示了该系统的计算效率;空中测绘展示了系统的映射精度;基于网格和NeRF的三维模型渲染强调了重建稠密地图适合后续渲染任务。我们将代码、数据集和应用程序开源到GitHub1,以造福机器人社区。
关键词——同步定位与建图(SLAM)、传感器融合、三维重建、空中导航。
I. 前言
近年来,同步定位与地图构建(SLAM)技术取得了显著进展,特别是在未知环境下的实时三维重建和定位方面。由于其能够在实时估计姿态并重构地图的能力,SLAM已成为各种机器人导航任务中不可或缺的一部分。定位过程为机器人内部控制器提供了关键的状态反馈,而密集的三维地图则提供诸如空闲空间和障碍物等关键环境信息,这些信息对于有效的轨迹规划至关重要。彩色地图还承载着丰富的语义信息,能够生动地呈现真实世界,并且具有广泛的应用潜力,如虚拟现实、增强现实、3D建模以及人机交互。
目前,已经成功实现了单测量传感器的几种SLAM框架,主要是相机[1]-[4]或激光雷达[5]-[7]。尽管视觉和激光雷达SLAM在各自领域都显示出前景,但每种方法都有固有的局限性,限制了它们在各种场景中的性能。
基于低成本CMOS传感器和镜头的视觉SLAM能够建立准确的数据关联,从而实现一定的定位精度。丰富的色彩信息进一步丰富了语义感知。进一步利用增强的场景理解,采用深度学习方法进行稳健特征提取和动态对象过滤。然而,在视觉SLAM中缺乏直接深度测量导致需要通过三角化或深度滤波等操作对地图点进行同步优化,这引入了显著的计算开销,往往限制了地图的准确性与密度。视觉SLAM还面临其他诸多限制,例如不同尺度下的测量噪声变化、光照变化敏感性以及纹理环境对数据关联的影响。
利用激光雷达传感器的LiDAR SLAM,直接获得精确的深度测量值,在定位和地图绘制任务中具有更高的精度和效率。
视觉SLAM。尽管具有这些优势,激光雷达SLAM也存在几个显著的缺点。一方面,它重建的点云地图虽然详细,但缺乏颜色信息,从而降低了其信息量;另一方面,在诸如狭窄隧道、单一且延伸的墙壁等几何约束不足的环境中,激光雷达SLAM性能往往会下降。
随着对在现实世界中操作智能机器人需求的增长,尤其是在经常缺乏结构或纹理的环境中,现有系统依赖单个传感器无法提供所需的准确和稳健的姿态估计。为了解决这个问题,将常用的传感器如激光雷达、相机和惯性测量单元(IMU)进行融合正受到越来越多的关注。这种策略不仅结合了这些传感器的优势以提供增强的姿态估计,而且有助于构建精确、稠密且彩色的点云地图,在个别传感器性能退化的情况下也是如此。
高效准确的激光雷达惯性视觉里程计(LIVo)和地图构建仍然是挑战:1)整个LIVo系统负责处理每秒数百到数千个点的激光雷达测量,以及高帧率、高分辨率图像。充分利用如此庞大的数据量,特别是有限的机载资源,需要非凡的计算效率;2)许多现有系统通常包含一个LiDAR惯性里程计(LIO)子系统和一个视觉惯性里程计(VIO)子系统,每个子系统都需要从视觉和激光雷达数据中提取特征以减少计算负担。在缺乏结构或纹理的环境中,这种提取过程往往导致有限的特征点。此外,为了优化特征提取,广泛的工程适应是必不可少的,以适应激光雷达扫描模式和点密度的变化;3)为了降低计算需求并实现相机和激光雷达测量之间的紧密集成,统一的地图对于同时管理稀疏点和观察到的高分辨率图像测量至关重要。然而,在考虑激光雷达和相机异构测量的情况下设计和维护此类地图特别具有挑战性;4)为了确保重建彩色点云的准确性,姿态估计需要达到像素级精度。满足这一标准面临巨大挑战:适当的硬件同步、严格外参参数预校准之间激光雷达和相机、精确恢复曝光时间,并且融合策略能够在实时达到像素级精度。
由这些问题所激发,我们提出了一种高效的LIVO系统FAST-LIVO2。该系统通过一个顺序更新的误差状态迭代卡尔曼滤波器(ESIKF)紧密地将LiDAR、图像和IMU测量集成在一起。在惯性导航单元传播的先验知识下,系统状态按顺序进行更新,首先利用LiDAR测量,然后利用图像测量,两者都使用基于单个统一体素地图的直接方法来更新几何结构。具体来说,在LiDAR更新中,系统将原始点注册到地图上以构建并更新其几何结构;而在视觉更新中,系统
重新使用LiDAR地图点作为视觉地图点,而无需从图像中提取、三角剖分或优化任何视觉特征。在地图上选择的视觉地图点附有先前观察到的参考图像块,并然后投影到当前图像以通过最小化直接光度误差(即稀疏图像对齐)来调整其姿态。为了提高图像对齐的准确性,FAST-LIVO2动态更新参考块并使用来自LiDAR点获得的平面先验知识。为了提高计算效率,FAST-LIVO2使用LiDAR点来识别可见于当前图像中的视觉地图点,并且在没有LiDAR点的情况下进行按需voxel射线投射。FAST-LIVO2还实时估计曝光时间以处理照明变化。
FAST-LIVO2是基于我们在之前的工作中提出的FAST-LIVO [8]开发的。与FAST-LIVO相比,新的贡献如下:
我们提出了一种高效的ESIKF框架,该框架采用顺序更新来解决LiDAR和视觉测量之间的维度不匹配问题,并提高了使用异步更新的FAST-LIVO的鲁棒性。
我们使用(甚至精炼)来自激光雷达点的平面先验,以提高精度。相反,FAST-LIVO假设一个区域中的所有像素具有相同的深度,这是一个非常不合理的假设,大大降低了图像对齐中仿射变形的准确性。
我们提出了一种参考贴图更新策略,以提高图像对齐的准确性。通过选择具有大视差和足够纹理细节的高质量、内点参考贴图来实现。FAST-LIVO根据当前视图选择参考贴图,经常导致低质量的参考贴图降低精度。
4)我们对处理环境照明变化进行了在线曝光时间估计。FAST-LIVO没有解决这个问题,导致在显著的光照变化下图像对齐效果不佳。
我们提出了一种按需的体素射线投射,以增强FAST-LIVO在激光雷达近距离盲区引起的激光雷达点测量缺失的情况下系统的鲁棒性。FAST-LIVO没有考虑这个问题。
以上每个贡献都通过综合消融研究进行了评估,以验证其有效性。我们实现了所提出的系统作为实用的开放软件,并精心优化了Intel和ARM处理器上的实时操作。该系统具有多功能性,支持多行旋转激光雷达、新兴的固态激光雷达以及各种鱼眼相机。
此外,我们对公共数据集(即Hilti和NTU-VIRAL数据集)的25个序列以及各种代表性的私有数据集进行了广泛的实验,并与R3LIVE、LVI-SAM、FAST-LIO2等其他最先进的SLAM系统进行比较。定性和定量结果表明,在计算成本降低的情况下,我们的系统在准确性和鲁棒性方面明显优于其他同类产品。
为了进一步强调我们系统的实际应用性和多功能性,我们部署了三个独特的应用程序。首先,完全自主的无人机导航演示了该系统在实时能力方面的表现,并且是首次将激光雷达惯性视觉系统用于实际的自主无人机飞行。其次,在无结构环境中进行空中测绘展示了该系统在实际使用中的像素级精度。最后,高质量的网格、纹理和NeRF模型生成突出了该系统适用于渲染任务的适用性。我们将我们的代码和数据集发布到GitHub上。
II 相关工作
A. 直接方法
直接方法在视觉和激光雷达SLAM中快速姿态估计方面脱颖而出。与基于特征的方法(例如,[5、6、9、10])不同,这些方法需要提取突出的特征点(例如,在图像中的角点和边缘像素;在激光雷达扫描中的平面和边缘点),并生成匹配描述符,直接方法直接利用原始测量值优化传感器姿态[11],通过最小化基于光度误差或点到平面残差的误差函数来实现,例如 [3、12]-[14] 。通过消除耗时的特征提取和匹配,直接方法提供快速的姿态估计。然而,由于没有特征匹配,准确的状态先验估计是避免局部极小值所必需的。
视觉SLAM中的直接方法可以大致分为稠密直接、半稠密直接和稀疏直接方法。稠密直接方法,主要应用于RGB-D相机的全深度测量,如[15]-[17]所示,采用图像到模型对齐进行姿态估计。相比之下,半稠密直接方法[3, 18]通过利用具有显著灰度级梯度的像素来实现直接图像对齐。稀疏直接方法[2, 12]专注于通过少量精心选择的原始块提供准确的状态估计,从而进一步减轻与稠密和半稠密直接方法相比的计算负担。
不同于直接视觉SLAM方法,直接激光雷达SLAM系统([13, 14, 19, 20])不区分稠密和稀疏的方法,并且通常使用每个扫描中的空间下采样或时间下采样的原始点来构造姿态优化的约束。
在我们的工作中,我们利用直接方法的原理来为LiDAR和视觉模块。我们的系统中的LiDAR模块是从VoxelMap [14]中改编而来的,并且基于稀疏直接方法的一个变体[12]。虽然从[12]中汲取灵感,但是我们的视觉模块与之不同的是重新利用了LiDAR点作为视觉地图点,从而减轻了后端计算(即特征对齐、滑动窗口优化或深度过滤)。
B.激光雷达视觉(惯性)SLAM
将多个传感器集成到LiDAR视觉惯性SLAM中,使系统能够处理各种具有挑战性的环境,特别是
当一个传感器出现故障或部分退化时。受此启发,研究社区看到了各种LiDAR视觉惯性SLAM系统的兴起。现有的方法可以大致分为两类:松散耦合和紧密耦合。分类可以从两个角度进行确定:状态估计级别和原始测量级别。在状态估计级别上,关键在于是否从一个传感器的估计作为另一个传感器模型的优化目标。在原始测量级别上,涉及不同传感器的原始数据是否结合在一起。
Zhang等人提出了一种松散耦合的LiDAR-视觉惯性SLAM系统[21],该系统在状态估计级别上是松散耦合的。在这个系统中,VIO子系统仅提供扫描注册在LIO子系统中的初始姿态,而不是与扫描注册一起优化。VIL-SLAM[22]采用类似松散耦合的方法,不利用LiDAR、相机和IMU测量的联合优化。
一些系统(例如,DEM0 [23]、LIMO [24]、CamVox [25] 和 [26])使用三维激光雷达点来为视觉模块提供深度测量。虽然这些系统在测量级上表现出紧密耦合,但在状态估计中仍保持松散耦合,主要原因是状态估计中直接从激光雷达测量中得出的约束缺失。另一个问题在于三维激光雷达点与二维图像特征点和/或线之间没有一一对应关系,这主要是由于分辨率不匹配造成的。这种不匹配需要在深度关联中进行插值,引入潜在误差。为了应对这一问题,DVL-SLAM [28] 使用一种直接的方法来进行视觉跟踪,其中将激光雷达点直接投影到图像中以确定相应像素位置的深度。
上述提到的工作在状态估计层面上并未实现紧耦合。为了追求更高的精度和鲁棒性,最近出现了许多联合优化传感器数据的紧耦合方法。例如,基于MSCKF框架,LIC-Fusion [29] 紧密融合了IMU测量、稀疏视觉特征以及LiDAR平面和边缘特征;随后的LIC-Fusion 2.0 [31] 在滑动窗口内实现了对LiDAR姿态估计的增强,通过跟踪LiDAR平面特征来实现。VILENS [32] 通过统一因素图,以固定滞后平滑为基础,联合优化视觉、LiDAR 和惯性数据。R2LIVE [33] 则在迭代卡尔曼滤波器上紧密融合了LiDAR、相机和IMU测量值。对于R2LIVE中的VIO子系统,使用滑动窗口优化来三角化地图上的视觉特征位置。
几个系统在测量和状态估计级别上实现了完全的紧密耦合。LVI-SAM [35] 在一个紧耦合平滑和映射框架中融合了激光雷达、视觉和惯性传感器,该框架建立在一个因素图之上。VIO 子系统进行视觉特征跟踪,并使用激光雷达扫描提取特征深度。R3LIVE [36] 通过 LIO 构建全局地图的几何结构,并由 VIO 渲染地图纹理。这两个子系统通过将各自的激光雷达或视觉数据与 IMU 数据融合来联合估计系统状态。高级版本,R3LIVE ++ [37] 实时估计曝光时间。
时间,并且在之前进行光度校准,这使得系统能够恢复地图点的辐射。不同于大多数以前提到的依赖于特征的方法来实现LiDAR-Inertial-Vision系统的子系统,R3LIVE系列[36、37]采用直接方法,无需特征提取,能够在纹理或结构缺失的情况下捕捉到细微的环境特征。
我们的系统还联合估计状态,使用LiDAR、图像和IMU数据,并在测量级别上维护紧密耦合的体素地图。此外,我们的系统采用直接方法,利用原始LiDAR点进行LiDAR扫描注册,并使用原始图像块进行视觉跟踪。与R3LIVE(或R3LIVE++)相比,我们系统的关键区别在于R3LIVE(以及R3LIVE++)在VIO中以单个像素为单位操作,而我们的系统则在图像块级别上操作。这种差异赋予了我们的系统显着的优势。首先,在鲁棒性方面,我们的方法使用简化的一步帧到图稀疏图像对齐来估计姿态,从而减轻了R3LIVE中必须通过帧到帧光流获得准确初始状态的依赖性。因此,我们的系统简化并改进了R3LIVE中的两阶段帧到帧和帧到图操作。其次,从计算角度来看,R3LIVE中的VIO主要采用密集的直接方法,这需要大量的残留构建和渲染点,计算成本高昂。相比之下,我们的稀疏直接方法提供了增强的计算效率。最后,我们的系统利用原始图像块的分辨率信息,而R3LIVE仅限于其点图的分辨率。
我们的系统视觉模块与DV-LOAM [39]、SDV-LOAM [40]和LVIO-Fusion [41]最相似,它将附有贴图的激光雷达点投影到新图像中,并通过最小化直接光度误差来跟踪该图像。然而,它们有几个关键差异,例如使用单独的地图进行视觉和激光雷达,依赖于在视觉模块中的贴图变形假设不变深度,状态估计层松散耦合以及图像对齐的两个阶段:帧到帧和帧到关键帧。相比之下,我们的系统紧密地集成帧到地图图像对齐、激光雷达扫描注册和IMU测量在一个迭代卡尔曼滤波器中。此外,由于我们为激光雷达和视觉模块共享单个统一地图,我们的系统可以直接利用激光雷达点提供的平面先验加速图像对齐。
III。系统概述
我们的系统概述如图2所示,包含四个部分:ESIKF(第IV节)、局部映射(第V节)、激光雷达测量模型(第VI节)和视觉测量模型(第VII节)。
首先,通过扫描重组将异步采样的LiDAR点重新组合成相机的采样时间。然后,我们紧密耦合LiDAR、图像和惯性测量值,使用顺序ESIKF。
状态更新,其中系统状态按顺序进行更新,首先利用激光雷达测量结果,然后利用图像测量结果,两者均基于单个统一的体素地图(第IV节)采用直接方法。为了在ESIKF更新中构建激光雷达测量模型(第VI节),我们计算帧到地图点到平面残差。为了建立视觉测量模型(第VII节),我们从地图中提取当前视场内的视觉地图点,使用可见体素查询和需求射线投射;提取后,我们识别并丢弃异常视觉地图点(例如被遮挡或深度不连续的点);然后计算帧到地图图像光度误差以用于视觉更新。
本地地图更新的视觉和激光雷达地图都是一个体素图结构(第V节):激光雷达点构造并更新地图的几何结构,而视觉图像则附加到选定的地图点上(即视觉地图点),并动态更新参考贴图。更新后的参考贴图在单独的线程中进一步细化其法向量。
IV. 顺序状态更新的迭代卡尔曼滤波器
本节概述了基于顺序更新的错误状态迭代卡尔曼滤波器(ESIKF)框架的系统架构。
A. 符号和状态转换模型
在我们的系统中,我们假设三个传感器(激光雷达、惯性测量单元和相机)之间的时延已知,并且可以提前校准或同步。我们将IMU帧(表示为I)作为身体坐标系,并将第一个身体坐标系
全球框架(表示为G)。此外,我们假设三个传感器是刚性连接的,并且表I中定义的外参在测量前已经校准。然后,在i个IMU测量时离散状态转移模型如下:
其中∆t是IMU采样周期,状态x、输入u、过程噪声w和函数f定义如下:
M is SO (3) x R16, dim (M) = 19.
(2)
其中,GRI、GPI和GV1分别表示IMU在全局坐标系中的姿态、位置和速度,GG是全局坐标系中的重力矢量,τ是相对于第一帧的逆相机曝光时间,nτ是将τ建模为随机漫步的高斯噪声,ωm和am分别是原始IMU测量值,ng和na分别是ωm和am的测量噪声,ba和bg分别是IMU偏差,它们被建模为由高斯噪声驱动的随机漫步。
算法1:顺序状态更新
1扫描重组以在相机速率下同步LiDAR和图像数据;
向前传播以获得状态预测x和其协方差P;
3 后向传播用于激光雷达点运动补偿;
4/点到平面激光雷达更新
5 κ=-1,xκ=0=x;
重复6次。
7 κ= κ+ 1;
计算残差zκl和雅可比矩阵Hκl;
计算状态更新xk+1;
直到;xκ+1;xκ|< E;
将以下英文文本翻译成中文。 11x=xκ+1,P=(I - KH)P;
12//稀疏直接视觉更新
13级=-1;
重复14次。
15 κ=-1,xκ=0=x;
16 等级 = 等级 + 1;
重复17次。
18 κ= κ+ 1;
19 计算残差zκc和雅可比矩阵Hκc;
计算状态更新xκ+1;
until 1xκ+1 day x κ | < E;
22 x=xκ+1;
直到级别>=2;
24 x¯=xκ+1; P¯=(I − KH)P。
B. 扫描重组
我们使用扫描重组来将高频率、顺序采样的LiDAR原始点分割成在相机采样时刻的独立LiDAR扫描,如图3所示。这确保了相机和LiDAR数据以相同频率(例如,每秒10次)同步,允许同时更新状态。
C. 传播
在ESIKF框架中,状态和协方差从tk-1时刻开始传播,该时刻是上一次激光雷达扫描和图像帧接收完毕的时刻,到tk时刻,即当前激光雷达扫描和图像帧接收完毕的时刻。这种向前传播通过设置过程噪声wi在(1)式为零来预测tk-1和tk时刻的每个IMU输入ui的状态。表示传播后的状态为x,并且表示协方差为P,这将作为IV-D节后续更新的先验分布。此外,为了补偿运动畸变,我们进行如[42]中的反向传播,确保激光雷达扫描中的点“测量”于扫描结束时间tk。请注意,在符号简化的情况下,我们在所有状态矢量中省略了下标k。
D. 顺序更新
IMU传播的statex和covarianceP对x,时间tk系统状态施加一个先验分布如下:
我们把上述先验分布表示为p(x),把激光雷达和相机的测量模型表示为:
其中,vlN(0,Σvl)和vcN(0,Σvc)分别表示激光雷达和相机的测量噪声。
标准ESIKF [ 43 ]会使用所有当前测量值更新状态x,包括激光雷达测量yl和图像测量yc。然而,激光雷达和图像测量是两种不同的感测模态,其数据维度不匹配。此外,图像测量的融合可以在图像金字塔的不同级别进行。为了应对维度不匹配并为每个模块提供更多的灵活性,我们提出了一种顺序更新策略。该策略理论上等价于使用所有测量值的标准更新,假设给定状态向量x时激光雷达测量yl和图像测量yc之间统计独立(即由统计独立噪声污染的测量)。
为了介绍顺序更新,我们重新写出了当前状态x的总条件分布:
方程(5)表明,总条件分布p (x | y l , y c )可以通过两个连续的贝叶斯更新获得。第一步仅将LiDAR测量值y l 与IMU传播先验分布p ( x )融合以获得分布p ( x | y l ):
然后,第二步将相机测量值yc与p(x|yl)融合以获得最终的x后验分布:
有趣的是,(6)和(7)中的两个融合遵循相同的格式:
为了进行融合(8)中的激光雷达或图像测量,我们详细说明了先验分布q (x )和测量模型q (y | x )如下。对于先验分布q (x ),表示为x = x , δx ,其中δx ~ N (0, P ) 。在激光雷达更新的情况下(即第一步),(x ,P )是来自传播步骤的状态和协方差。在视觉更新的情况下(即第二步),(x ,P )是来自激光雷达更新的收敛状态和协方差。
为了获得测量模型分布q (y | x),将第κ次迭代的估计状态表示为xκ,其中x0 = x。通过在xκ处对测量模型(4)(无论是激光雷达还是相机测量)进行一阶泰勒展开逼近,得到:
其中,δxκ = xsxκ,zκ是残差,Lκ v ~ N(0,R)是集总测量噪声,Hκ和Lκ分别是h(xκ f δxκ,v)关于δxκ和v的雅可比矩阵,在零点处评估。
然后,将先验分布q (x )和测量分布q (y | x )代入(10)中的后验分布(8),并进行最大似然估计(MLE),我们可以在ESIKF框架的标准更新步骤中获得δx κ的最大后验估计(MAP)(因此x κ)。
合并状态和协方差矩阵然后使后验分布的均值和协方差q(x|y)。
文献中已经研究了序列更新的卡尔曼滤波器,例如在[44, 45]。本文采用这种方法对LiDAR和相机系统进行ESIKF。序列更新的ESIKF实现细节见算法1。第一步(第6行至第10行)迭代地从LiDAR测量值(VI-A节)更新误差状态,直到收敛。收敛的状态和协方差估计,再次表示为x和P,用于更新地图几何形状(V-B节),然后在第二步视觉更新(第13行至第23行)中,在图像金字塔的每个级别上进行优化,直至收敛。最优的状态和协方差,再次表示为x¯和P¯,用于传播进入IMU测量值(IV-C节)并更新地图的视觉结构(V-D和V-E节)。
V.本地映射
A. 地图结构
我们的地图使用了[14]中介绍的自适应体素结构,每个哈希条目由一个散列表和八叉树组织(图2)。散列表管理根体素,每个根体素具有固定的尺寸为0.5×0.5×0.5米。每个根体素封装了一个八叉树结构来进一步组织大小不同的叶体素。叶体素代表局部平面,并存储在该平面上的一组激光雷达原始点上的平面特征(即平面中心、法向量和不确定性)。其中一些点附带三个级别的图像块(8×8块大小),我们称之为视觉地图点。已收敛的视觉地图点仅附带参考块,而非收敛的则附带参考块和其他可见块(见第五节E部分)。叶体素的不同大小允许它表示不同规模的局部平面,因此可以适应具有不同结构的环境[14]。
为了防止地图的大小不受限制,我们仅在LiDAR当前位置周围长度为L的大局部区域中保留一个局部地图,如图4中的二维示例所示。最初,地图是一个以LiDAR起始位置p0为中心的立方体。LiDAR的检测区域可视化为以当前位置为中心的球体,其半径由LiDAR的检测范围定义。当LiDAR移动到新位置p1时,检测区域
触及地图边界,我们通过距离d将地图移离边界。随着地图的移动,包含被移动区域的内存会被重置以存储新进入本地地图的区域。这种环形缓冲区方法确保我们的本地地图保持在固定大小的内存中。环形缓冲区哈希表的实现细节见[46]。地图移动检查是在每个ESIKF更新步骤后进行的。
B.几何构造和更新
地图几何结构由激光雷达点测量构建和更新。具体来说,在IV节中,我们使用EISIKF对激光雷达进行更新后,将所有激光雷达扫描点注册到全局坐标系中。对于每个注册的激光雷达点,我们确定其在哈希映射中的位于根体素的位置。如果该体素不存在,则我们将新点初始化为该体素,并将其索引到哈希映射中。如果已确定的体素已经在地图上存在,则我们将该点附加到现有的体素中。在所有扫描点分配完成后,我们按照以下步骤进行几何构造和更新。
对于新创建的体素,我们根据奇异值分解确定其包含的所有点是否位于一个平面上。如果是,则计算中心点q=p¯、平面法向量n和平面参数(q,n)的协方差矩阵Σn,q。Σn,q用于表征平面不确定性,该不确定性来自姿态估计不确定性和点测量噪声。平面准则及其参数和不确定性的详细计算可以参考我们的先前工作[14]。如果包含的点不位于一个平面上,则将体素连续细分到八个较小的八分之一中,直到子体素中的点被确定为形成平面或达到最大层(例如,3)。在后一种情况下,叶体素中的点将被丢弃。因此,地图仅包含已识别为平面的根体素或子体素。
对于具有新点附加的现有体素,我们评估这些新点是否仍然与根体素或子体素中的现有点形成平面。如果不是,则进行上述体素细分。如果是,则更新平面参数(q,n)和协方差Σn,q也如上所述。一旦平面参数收敛(见[14]),该平面将
被认为是成熟的和新的点将被丢弃。此外,成熟的平面的估计平面参数(q,n)和协方差Σn,q将固定。
在后续部分,LiDAR点将用于生成视觉地图点。对于成熟平面,最近的50个LiDAR点是候选视觉地图点;而对于未成熟的平面,则所有LiDAR点都是候选视觉地图点。视觉地图点生成过程会识别一些这些候选点作为视觉地图点,并附上图像块以进行图像对齐。
C. 视觉地图点生成和更新
为了生成和更新视觉地图点,我们选择当前帧可见的(详细描述在第VII-A节)且灰度级梯度显著的地图候选点。然后,在视觉更新之后(IV-D节),我们将这些候选点投影到当前图像中,并保留每个体素中的最小深度作为局部平面的候选点。接着,我们将当前图像划分为均匀网格单元,每个单元有30×30个像素。如果一个网格单元不包含任何在此处投影的视觉地图点,则使用具有最高灰度级梯度的候选点来生成新的视觉地图点并将其与当前图像块、估计当前状态(即帧姿态和曝光时间)以及从激光雷达点计算出的平面法线关联起来。附着于视觉地图点的贴图层有相同大小的三层(例如,11× 11像素),每层是前一层的一半采样形成金字塔形的贴图堆栈。如果一个网格单元包含在此处投影的视觉地图点,则如果(1)自上次添加贴图以来已超过20帧或(2)其当前帧的位置相对于上一次添加位置偏离了超过40个像素,则将新贴图(金字塔的所有三个层)添加到现有的视觉地图点。结果,地图点可能会拥有均匀分布视场角的有效贴图。除了贴图金字塔外,我们还将估计的当前状态(即姿态和曝光时间)附加到地图点。
D. 参考补丁更新
由于添加了新的补丁,视觉地图点可能有多个补丁。我们需要选择一个参考补丁来对齐图像。具体来说,我们根据光度相似性和视图角度为每个补丁f打分如下:
其中,NCC(f,g)表示用于测量补丁f和g之间的相似性的归一化交叉相关性
在两个补丁的0级金字塔级别(分辨率最高的级别)上,对两个补丁应用均值减法后,c表示评估补丁f的正常向量n和视图方向p/lpl之间的余弦相似性。当补丁直接面对地图点所在的平面时,c的值为1。总体得分S通过加权NCC和c之和计算得出,其中前者代表评估补丁f与所有其他补丁gi和tr的平均相似度,后者表示正常向量协方差矩阵的迹。
在所有附着于视觉地图点的补丁中,得分最高的补丁被更新为参考补丁。上述评分机制倾向于选择那些(1)与其余大部分补丁具有相似外观(以NCC衡量),MVS [47]使用的技术避免动态对象上的补丁;(2)视图方向垂直于平面,从而保持纹理细节在高分辨率下。相比之下,在我们的先前工作FAST-LIVO [8]和先驱技术[4]中,参考补丁更新策略直接从当前帧中选择视图方向差异最小的补丁,导致所选参考补丁非常接近当前帧,因此对当前姿态更新施加了弱约束。
图5:(a)参考贴片和目标贴片之间的仿射变形。(b)任何正常Ir n∈S2在标准化球面上,首先投影到平面Ir pT M=1上的点M∈R3上,并且然后投影到x-y平面上的点m∈R2。这种转换将球面的扰动δn转化为x-y平面上的扰动δm。
E. 正常精炼
每个视觉地图点假设位于一个小的局部平面。现有工作 [2,4,8] 假设一个区域中的所有像素具有相同的深度,这是一个不适用于一般情况的荒谬假设。我们使用从激光雷达点计算出的平面参数来实现更高的精度,这些参数详细描述在第五节 B 部分中。这个平面法向量对于图像对齐过程中的仿射变形至关重要。为了进一步提高仿射变形的准确性,可以从附着到视觉地图点的区域中进一步细化平面法向量。具体来说,通过最小化与其它附着到视觉地图点的区域相关的光度误差,我们在参考区域中细化平面法向量。
1)仿射变形:仿射变形用于将参考帧(即源贴图)中的像素坐标转换为其他帧(即目标贴图)中的像素坐标,如图5 (a)所示。让ujr是源贴图的第j个像素坐标和uji是第j个像素坐标在 <
第i个目标补丁。假设补丁中的所有像素都位于以Ir n为法线的局部平面和视觉映射点位置Ir p(对应于源补丁和目标补丁的中心像素),并且两者都在源补丁框架中表示,我们有:
uji= Airujr
其中,Air表示将源(或参考)块的像素坐标转换到第i个目标块的仿射变形矩阵,IiRIrand IitIr分别表示相对于目标框架Ii的参考框架Ir的相对姿态。为了直接使用鱼眼图像而无需将其校正为针孔图像,我们基于不同的相机模型(例如P是用于针孔相机模型的相机固有矩阵)实现投影矩阵P和后投影矩阵P-1。
2)正常优化:为了细化平面法线Ir n,我们最小化参考贴图与其他图像贴图之间的光度误差(即最高分辨率水平的第零级金字塔)。
其中,N是路径大小,τr和τi分别是参考帧和第i个目标帧的逆曝光时间。Ir(ujr)表示参考帧中的第j个补丁像素,Ii(Airujr)表示第i个目标帧中的第j个路径像素,S是所有目标帧的集合。
3) Optimization Variable Transformation: In order to improve the computational efficiency, we re-parameterize the least squares problem in (14). Note that only the optimization variable Ir n1appeared in M 全Ir n ∈ R3 in (13), and the optimization of Ir n over Ir n can be carried out over M. Furthermore, the vector M is subject to constraint Ir p · M= 1, which means that M can be parameterized as follows:
由于没有选择视觉地图点的参考贴图,因此Ir pzr = 0。图5(b)显示了Ir n、M和m之间的关系。
最后,对式(14)中的向量m∈R2进行优化,而没有任何约束。该优化可以在单独的线程中执行以避免阻塞主要里程计线程。然后可以使用优化后的参数m来恢复最优法向量Ir n:
一旦飞机正常收敛,此视觉地图点的参考贴图和法线向量将固定而不再进一步细化,并且删除所有其他贴图。
VI.激光雷达测量模型
本节详细介绍了IV-D节中ESIKF的LiDAR更新所使用的LiDAR测量模型yl=hl(x,vl)。
A. 点到平面激光雷达测量模型
在扫描过程中获得未畸变点{Lpj}后,我们使用估计的statexκ在LiDAR更新的第κ次迭代中将其投影到全局坐标系:
然后,我们确定Gpκj在哈希映射中的根或子体素。如果没有找到体素或者该体素不包含平面,则丢弃该点。否则,我们使用体素内的平面来建立LiDAR点的测量方程。具体来说,假设给定准确的LiDAR姿态GTI和真实LiDAR点Lpgtj应该位于体素中以正常向量ngtj为中心点qgtj的平面上。即 <|end|>
由于地面真值点Lpgtj被测得为Lpj,且存在距离和方位噪声δLpj,我们有Lpgtj=Lpj−δLpj。同样地,平面参数(ngtj,qgtj)通过方差为Σn,q的协方差估计得到(nj,qj),因此我们有:ngtj=njBδnj,qgtj=qj−δqj。因此,
其中,测量噪声vl=(δLpj, δnj, δqj),分别由激光雷达点、法向量和平面中心的噪声组成。
B. 激光雷达测量噪声与光束发散
在[14]中,将LiDAR点δLpj的不确定性分解为两个部分:激光飞行时间(TOF)引起的距离不确定性和编码器引起的方位角不确定度δω。此外,我们还考虑了由激光束发散角θ引起的不确定性,如图6所示。随着方位角和法向矢量之间的角度增加,LiDAR点的距离不确定性显著增加,而方位角不确定性保持不变。由于激光束发散角引起的δd可以建模为:
考虑到TOF和激光束发散对δd的影响,当我们的系统从地面或墙壁上选择更多的点(见图6(c、d)),它比不考虑这种影响时的姿势估计更精确。
图6:(a)和(b)分别显示了考虑激光束发散角θ的LiDAR点不确定性模型的三维视图和侧剖面视图。红色轮廓线表示激光束扩散的区域。©和(d)根据点位置不确定度对扫描中的点进行着色。与©相比,(d)还考虑到由于激光束发散角引起的测距误差δd。这导致地面点的不确定性较高,因为激光束的扩散面积较大。
采样点
第七章 视觉测量模型
本节详细介绍了IV-D节中用于视觉更新的ESIKF中的视觉测量模型yc=hc(x,vc)。
A. 视觉地图点选择
为了在视觉更新中执行稀疏图像对齐,我们首先选择适当的视觉地图点。我们首先使用体素和射线投射查询提取当前相机视场可见的地图点(称为视觉子图),然后从该子图中选择视觉地图点并拒绝异常值。这个过程产生了一个准备用于构建视觉测量模型的视觉地图点集。
1) 可见体素查询。由于地图中体素数量庞大,识别当前帧视场内的地图体素具有挑战性。为解决此问题,我们通过查询当前激光雷达扫描中击中的体素来缩小范围:利用测量点位置快速检索体素哈希表即可实现。若相机视场与激光雷达视场高度重合,相机视场内的地图点很可能也位于这些体素中。同时,我们还会查询上一帧图像中通过相同体素查询与光线投射确认可见的地图点所关联的体素——此处假设连续图像帧之间存在较大视场重叠。最终,通过筛选这两类体素中包含的地图点并执行视场验证,即可获得当前视觉子图。
2)按需射线投射:在大多数情况下,可以通过上述的体素查询获取视觉子地图。然而,当激光雷达传感器太接近物体时(称为近距离盲区),它可能会返回没有点。此外,相机视场可能不会完全被激光雷达视场覆盖。为了在这些情况下召回更多的视觉地图点,我们采用图7所示的射线投射策略。我们将图像划分为均匀网格单元,每个单元有30×30个像素,并将从体素查询中获得的视觉地图点投影到网格单元上。对于每个未被这些视觉地图点占据的图像网格单元,沿中央像素向后投射一条射线,在深度方向上以dmin至dmax的距离均匀分布采样点。为了减少计算负载,我们在相机坐标系下预先计算了每条射线上采样点的位置。对于每个采样点,我们评估相应的体素的状态:如果该体素包含在投影后位于此网格单元内的地图点,则我们将这些地图点纳入视觉子地图并停止对该射线进行处理;否则,我们继续沿着射线上的下一个采样点直到达到最大深度dmax。通过所有未被占用的图像网格单元的射线投射处理后,我们获得了分布在整个图像中的视觉地图点集。
3)异常值拒绝:在体素查询和射线投射之后,我们获得了当前帧视场中的所有视觉地图点。然而,这些视觉地图点可能被当前帧遮挡、具有不连续的深度、参考贴图是在大视角下获取的或在当前帧中具有大的视角,这都会严重降低图像对齐精度。为了解决第一个问题,我们将所有
使用更新后的激光雷达姿态将子地图中的视觉地图点投影到当前帧,并在每个30×30像素网格单元中保留最低深度的点。为了解决第二个问题,我们投影当前激光雷达扫描中的激光雷达点到当前帧以生成深度图。通过比较视觉地图点与其深度图中9×9邻域的深度,确定其遮挡和深度变化。被遮挡或深度不连续的地图点被拒绝(见图8)。为了解决第三个和第四个问题,我们删除参考贴片或当前贴片视场角(即正常向量与从视觉地图点到贴片光学中心的方向之间的角度)太大的点(例如超过80°)。剩余的视觉地图点将用于对齐当前图像。
B.稀疏-直接视觉测量模型
提取的视觉地图点{Gpi}用于构建视觉测量模型。其原理是,当将地图点Gpi转换为当前图像Ik()时,参考区域和当前区域之间的光度误差应为零:
其中,π()是常见的相机投影模型(即Pinhole、MEI、ATAN、Scaramuzza和等距),CrTG是全局参考框架G相对于参考框架Cr的姿态,该姿态在接收并融合参考框架时估计得到;Ari是将第i个当前块中的像素变换到参考块的仿射变形矩阵;∆u是在当前块中ui中心点相对位置的相对像素位置;Igtk,Igtr分别表示参考帧和当前帧的真实像素值。它们被测量为实际图像像素值Ik,Ir,并且由于各种来源(例如,快门噪声和CMOS摄像机的Analog-to-Digital转换器(ADC)噪声)而产生测量噪声vc = (δIk,δIr)。因此,
(22)
为了提高计算效率,我们采用逆成分表示法[4、48],其中ui中的参数化GTI = GTκI Exp (δT)的姿势增量δT∈R6从ui移动到u:i如下所示:
由于在参考系中,ugi 在每次迭代过程中保持不变,因此我们只需要计算一次关于δT的雅可比矩阵,而不是为每个迭代重新计算它们。
为了从测量方程(22)中估计逆曝光时间τk,我们固定初始逆曝光
时间τ0 = 1,以消除方程(22)中所有倒置曝光时间均为零时的退化。因此,后续帧的估计倒置曝光时间是相对于第一帧的曝光时间。
方程(22)在三个层次的视觉更新步骤中使用(见算法1);视觉更新从最粗的层次开始,当一个层次收敛时,它会继续到下一个更细的层次。估计的状态然后用于生成视觉地图点(第五节C部分)和更新参考贴图(第五节D部分)。
八、评估数据集
在本节中,我们介绍了用于性能评估的数据集,包括公共数据集NTU-VIRAL [49]、Hilti’ 22 [50]、Hilti’ 23 [51] 和MARS-LVIG [52] ,以及我们的自收集的FAST-LIVO2私有数据集。具体来说,NTU-VIRAL和Hilti数据集被用来对我们的系统与最先进的SLAM系统进行定量基准比较(第IX-B节)。FAST-LIVO2私有数据集主要用以在各种极端挑战场景下评估我们的系统(第IX-C节),展示其高精度地图绘制能力(第IX-D节)并验证系统内各个模块的功能性(补充材料中的I-A至I-D节)。MARS-LVIG数据集用于应用演示(第十章)和消融研究(补充材料中的I-E节)。
A. NTU-VIRAL,Hilti和MARS-LVIG数据集
NTU-VIRAL数据集是在南洋理工大学校园内使用空中平台收集的,它展示了各种各样的场景,这些场景体现了独特的空中操作挑战。具体来说,“sbs”序列只能提供来自远处物体的嘈杂视觉特征。“nya”序列由于半透明表面和复杂的飞行动力学以及低照明条件而对LiDAR SLAM和视觉SLAM提出了挑战。该数据集配备了16通道OS1 gen13激光雷达,以每秒10赫兹的速度采样,并内置了100赫兹的IMU,还配有两台同步的针孔相机,触发频率为每秒10赫兹。左相机用于评估。
Hilti’22和Hilti’23数据集由手持设备和机器人设备收集,涵盖了建筑工地、办公室、实验室和停车场等环境中的室内和室外序列。这些序列引入了诸如长走廊、地下室和楼梯等具有纹理特征、不同照明条件以及不足的Li-DAR平面约束的挑战。手持序列使用一个Hesai PandarXT-324 LiDAR以10赫兹采样率,五个广角相机以40赫兹采样率,将它们降采样到10赫兹,并配备了一个外部Bosch BMI085惯性测量单元(IMU),其采样率为400赫兹。同时,机器人安装的序列配备了Robosense BPearl5 LiDAR以10赫兹采样率,八个全向摄像头以10赫兹采样率,以及Xsens MTi-670IMU以200赫兹采样率。在两种情况下,都使用前视摄像头。
对于所有正在评估的系统。通过运动捕捉系统(MoCap)或总站[54]获得毫米级的真实地面,为每个序列提供。请注意,Hilti数据集的真实地面不是开源的;因此,这些数据集上的算法结果是通过Hilti官方网站进行评估的。由于“Site 3”在Hilti’23中没有提供深入分析图(例如RMSE),我们排除了这四个序列,但我们的评分结果仍可在其官方网站上找到6。NTU-VIRAL和Hilti总共贡献了25个序列。
MARS-LVIG数据集提供了高海拔、面向地面的测绘数据,涵盖了诸如丛林、山脉和岛屿等多样化的无结构地形。该数据集通过配备Livox Avia7激光雷达(内置BMI088 IMU)和高分辨率全局快门相机的DJI M300 RTK四旋翼无人机采集,这两者均以每秒10次触发。这与前面提到的NTU-VIRAL和Hilti数据集明显不同,后者使用的是752×480灰度图像,而MARS数据集则采用2448×2048彩色RGB图像,从而方便生成清晰且密集的颜色点云。因此,我们利用这个公开的数据集来验证我们在高海拔航空测绘应用中的能力。
B. FAST-LIVO2 私有数据集
为了验证系统在更极端条件下的性能(例如,激光雷达退化、低照明度、剧烈曝光变化和无激光雷达测量的情况),我们创建了一个名为FAST-LIVO2的私人数据集。该数据集、硬件设备以及硬件同步方案与本文代码一起发布,以方便复制我们的工作。
1)平台:我们的数据采集平台,如图9所示,配备了一个工业相机(MV-CA013-21UC)、一个Livox Avia激光雷达和一个DJI manifold-2c(Intel i7-8550u CPU 和 8GB RAM),作为机载计算机。相机的视场角为70.6°×68.5°,激光雷达的视场角为70.4°×77.2°。所有传感器都通过由STM32同步定时器产生的10Hz触发信号进行硬同步。
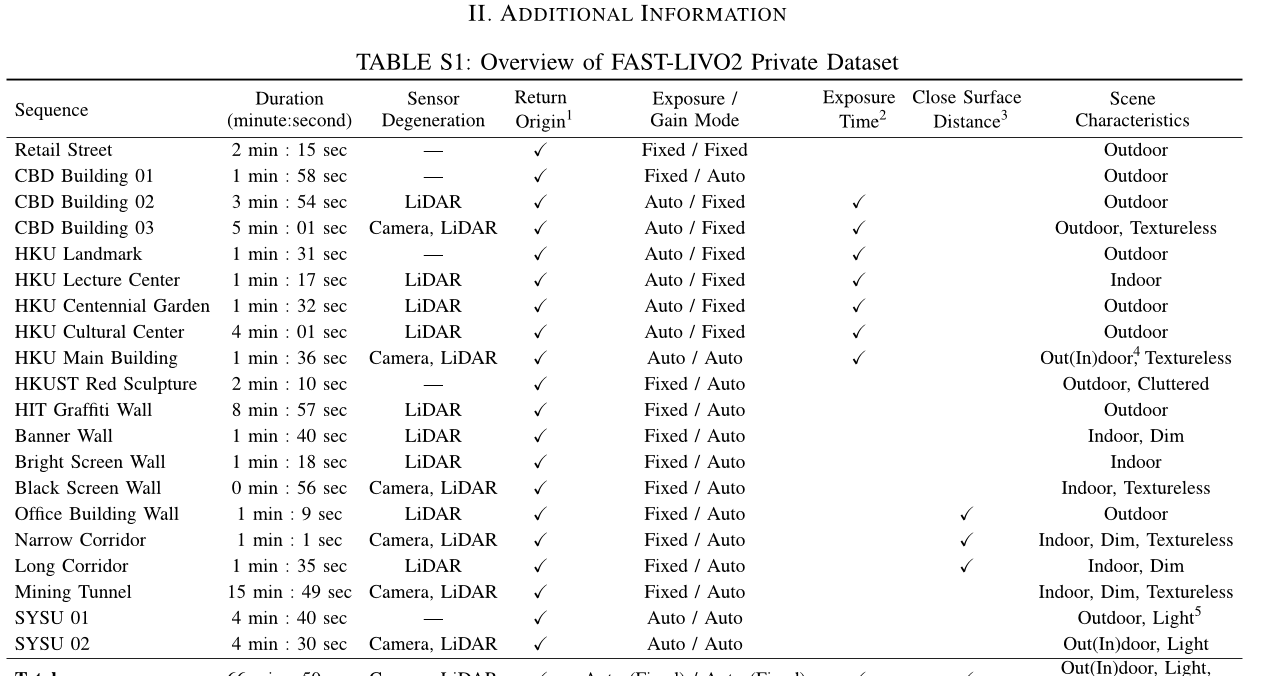
2)序列描述:如补充材料中表S1所示,FAST-LIVO2私有数据集包含20个序列,覆盖各种场景(例如校园、街道等)。
建筑物、走廊、地下室、采矿隧道等)具有结构不完整、杂乱无章、昏暗、光线变化和纹理弱的环境,持续时间总计为66.9分钟。大多数序列表现出视觉或激光雷达退化现象,如面对单一平面或纹理缺失的平面,穿过极窄或黑暗的隧道,并经历从室内到室外的光照条件的变化(见补充材料中的图S7)。为了保证相机与激光雷达之间的同步数据采集增强,我们在大部分场景中将相机设置为固定曝光时间和自动增益模式。对于剩余的自动曝光序列,我们记录其真实曝光时间。在所有序列中,平台返回起点,这使得可以评估漂移。
IX、实验结果
在本节中,我们进行了广泛的实验来评估我们的系统。
A. 实施和系统配置
我们用C ++和机器人操作系统(ROS)实现了所提出的FAST-LIVO2系统。在默认配置中,曝光时间估计启用,而正常向量细化被禁用。扫描中的激光雷达点以1:3的比例按时间下采样。体积图的根体素大小设置为0.5米,内部八叉树的最大层为3。图像块大小分别为8×8用于图像对齐和11×11用于正常细化。在连续ESIKF设置中,在所有实验中,相机光度噪声设置为常数值100。Livox Avia激光雷达和OS1-16深度误差和航向角误差调整为0.02米和0.05°,PandarXT-32为0.001米和0.001°,Robosense BPearl激光雷达为0.008米和0.01°。激光束发散角度分别设置为Livox Avia激光雷达和OS1-16的0.15°,以及PandarXT-32和Robosense BPearl激光雷达的0.001°。我们的系统使用相同的参数处理所有数据集的所有序列,并且具有相同传感器设置。所有实验的计算平台是配备Intel i7-10700K CPU和32GB内存的台式机。对于FAST-LIVO2,我们也测试了它在嵌入式系统中常用的基于ARM处理器上运行的情况。ARM平台是RB58,带有Qualcomm Kryo585 CPU和8GB内存。我们将基于ARM平台实现的FAST-LIVO2称为“FAST-LIVO2 (ARM)” 。
B.基准实验
在这个实验中,我们对来自NTU-VIRAL、Hilti’22和23个开放数据集的25个序列进行了定量评估。我们的方法与几个最先进的开源里程计系统进行了基准测试,包括R3LIVE [36] ,一个稠密直接激光雷达惯性视觉里程计系统;FAST-LIO2 [13] ,一个直接激光雷达惯性里程计系统;
×表示系统完全失败。
SDV-LOAM[40],一种半直接的激光雷达视觉里程计系统;LVI-SAM[35],一种基于特征的激光雷达惯性视觉SLAM系统;以及我们的先前工作FAST-LIVO[8]。
这些系统是从其各自的GitHub存储库中下载的。对于FAST-LIO2、FAST-LIVO和LVI-SAM,我们使用室内和室外场景中的多线激光雷达传感器推荐设置。对于R3LIVE,我们将系统适应与鱼眼相机模型和外部IMU(默认配置仅支持内部IMU)配合使用的多线激光雷达。由于数据集中的不足IMU激励导致不利优化,我们禁用了相机内参和外参CTI的实时优化。其他参数,包括光流跟踪窗口大小和金字塔级别,当前扫描点云和全局地图的下采样分辨率,都进行了微调以实现最佳性能。由于只有SDV-LOAM的视觉模块是开源的,我们松散地将它集成到LeGO-LOAM [7] 中,并遵循原始论文[40]描述的方法学。这个增强系统继续细化来自视觉模块的姿态,并且我们也将其在GitHub上公开。鉴于所有比较系统的都是没有回环闭合的里程计,除了LVI-SAM之外,我们移除LVI-SAM的回环闭合模块,以确保公平的比较。此外,我们对曝光时间估计模块、正常细化模块和参考补丁更新策略进行消融研究。默认的FAST-LIVO2具有实时曝光估计和参考补丁更新,但不进行正常的细化。
所有方法的结果如表II所示。可以看到,我们的方法在所有序列中均取得了最高的总体精度,平均RMSE为0.044米,是第二名FAST-LIVO的三倍(0.137米)。我们的系统在大多数序列中表现最佳,除了“室外建筑”和“大房间(黑暗)”,在这两个序列中,我们的系统与仅使用LiDAR惯性里程计的FAST-LIO2相比,在毫米级上略微更高一些误差。这种差异可以归因于这些序列中的丰富结构特征但照明条件较差,导致图像昏暗且模糊。因此,融合这些低质量图像不会提高里程计精度。排除这两个序列后,利用紧密耦合的LiDAR、惯性和视觉信息的方法显著优于FAST-LIO2、我们的LIO子系统以及仅使用LiDAR和视觉里程计的SDV-LOAM。值得注意的是,由于缺乏与IMU测量的紧密集成,SDV-LOAM在Hilti数据集上的性能特别差,导致LO子系统的漂移。此外,LiDAR和视觉观测之间的松散耦合,以及VO初始值不佳,往往会导致局部最优或甚至负优化。由于我们对每个LiDAR点更准确的噪声建模,我们的LIO子系统通常优于FAST-LIO2。在FAST-LIO2稍胜一筹的几个序列中,差异微乎其微,仅为毫米级,并不明显。此外,我们的系统在整个序列中的精度远超其他紧密耦合的LiDAR惯性视觉系统。其中,LVI-SAM在九个序列中失败的主要原因是基于特征的LIO和VIO子系统。
没有充分利用原始测量数据,这降低了其在具有微妙几何或纹理特征的环境中的鲁棒性。R3LIVE通常表现良好,但在“Construction Stairs”,“Cupola”和“Attic to Upper Gallery”序列中表现不佳,甚至比FAST-LIO2更差。这是因为结构不明显的楼梯旋转导致姿态先验不足,在对当前帧进行彩色地图点对齐时产生局部最优解,并最终导致负优化。通过基于贴图的图像对齐,FAST-LIVO和FAST-LIVO2克服了这些挑战。此外,传感器靠近墙壁的情况突出了FAST-LIVO2中射线投射的有效性,如补充材料[53]中的图S8所示。另一方面,FAST-LIVO在NTU-VIRAL数据集上被R3LIVE和FAST-LIVO2超越,尤其是在诸如“nya”序列等无序场景中,基于常数深度假设的仿射变形效果不准确。相比之下,R3LIVE的像素级对齐以及FAST-LIVO2平面先验(或精化)不会遇到此类问题。
比较FAST-LIVO2的不同变体,我们观察到与默认值相比,在没有实时曝光时间估计的情况下,平均精度降低了6mm。这是因为曝光时间估计可以主动补偿环境中的照明变化。另一方面,没有参考补丁更新的平均精度比默认值低了44mm,因为参考补丁更新策略有效地选择了更高分辨率的补丁,并避免选择异常补丁。最后,正常细化增加了平均精度1mm,但精度改进在所有序列中并不一致。有限的改进主要是因为在简单结构化场景中具有良好的图像观测时,正常向量细化仅产生正优化。在NTU-VIRAL数据集中,“eee”和“nya”序列的图像非常暗且模糊,其中负优化特别严重。为了进一步研究不同模块的有效性,包括曝光时间估计、仿射变形、参考补丁更新、正常收敛、按需射线投射以及ESIKF顺序更新,我们在私人数据集和MARS-LVIG数据集上进行了全面的研究。结果由于空间限制,将在补充材料[53]的第I部分(系统模块验证)中呈现。正如结果所证实的那样,我们的系统可以在结构化和非结构化的环境中实现稳健准确的姿态估计,在严重的光照变化下,在长期高速数据采集的大规模场景中,甚至在狭窄的空间中几乎没有LiDAR测量。
C.激光雷达退化和视觉挑战环境
在这个实验中,我们评估了我们的系统在经历LiDAR退化和/或视觉挑战的环境下的稳健性,并将其与FAST-LIVO和R3LIVE在8个序列中的定性映射结果进行比较。
在图10和11中。图10展示了LiDAR退化序列,其中LiDAR沿着墙壁从一侧移动到另一侧时面对着一个大墙。由于只有观察到的单个墙面平面,因此几何约束不存在,LIO方法会失败。值得注意的是,“HIT Graffiti Wall”序列几乎覆盖了800米的距离,并且LiDAR始终面向墙壁,导致显著退化。在所有序列中,FAST-LIVO2明显展示其对长期退化的稳健性以及提供高精度彩色点云地图的能力。相比之下,FAST-LIVO成功地获得了几何结构但纹理完全模糊不清。R3LIVE在几何结构和清晰度方面都存在问题。图11展示了更复杂场景下的测试,在这些场景中,LiDAR和/或相机偶尔都会出现退化现象。退化方向由相应的箭头指示。“HKU Cultural Center”(图11(a))展示了FAST-LIVO2、R3LIVE和FAST-LIVO的地图结果。如图所示,R3LIVE和FAST-LIVO具有扭曲的点云地图、模糊的纹理和超过1m的偏移。相反,FAST-LIVO2成功返回起点,实现小于0.01m的端到端误差,同时保持一致的点云地图和清晰的纹理。“CBD Building03”(图11 (b)) 和 “Mining Tunnel”(图11 ©)仅显示FAST-LIVO2的结果,因为R3LIVE和FAST-LIVO失败了。在图11 (b),蓝色箭头代表向纯黑色屏幕运动的方向,表明同时存在LiDAR和相机退化。在图11 (c1)和(c2),红色点表示该位置的LiDAR扫描,说明由于只观察到单个平面而导致的LiDAR退化区域。此外,"Mining Tunnel"在整个序列中表现出非常昏暗的照明条件,伴随着频繁的视觉和LiDAR退化。尽管面临这些挑战,FAST-LIVO2仍然能够在两个序列中以小于0.01m的端到端误差返回起点。
D. 高精度地图
在这个实验中,我们验证了我们系统的高精度定位能力。为了探索不同算法的映射精度并确保公平性,我们在具有丰富纹理和结构化环境的场景中比较我们的系统与FAST-LIO2、R3LIVE和FAST-LIVO。我们以“SYSU 01”,“HKU Landmark” 和“CBD Building 01”为例。补充材料中的图S9显示了这些序列在实时重建的彩色点云地图。我们可以清楚地观察到,由FAST-LIVO2生成的点云地图保留了所有系统中最精细的细节,放大后的彩色点云地图类似于实际RGB图像。在“SYSU 01”序列中,由于我们使用恢复的曝光时间来合理调整图像颜色,并且很少出现过曝的彩色点云地图,因此我们的算法在标志牌上产生的白色噪点更少。在“CBD Building 01”中对人类和摩托车的重建也展示了我们能够重建无结构物体的细节的能力。在整个序列中,估计的最终位置返回到起始
点与端到端误差小于0.01米。我们还在剩余的私有数据集序列中测试了FAST-LIVO2,映射结果如补充材料中的图S10-S13所示。
E. 运行时间分析
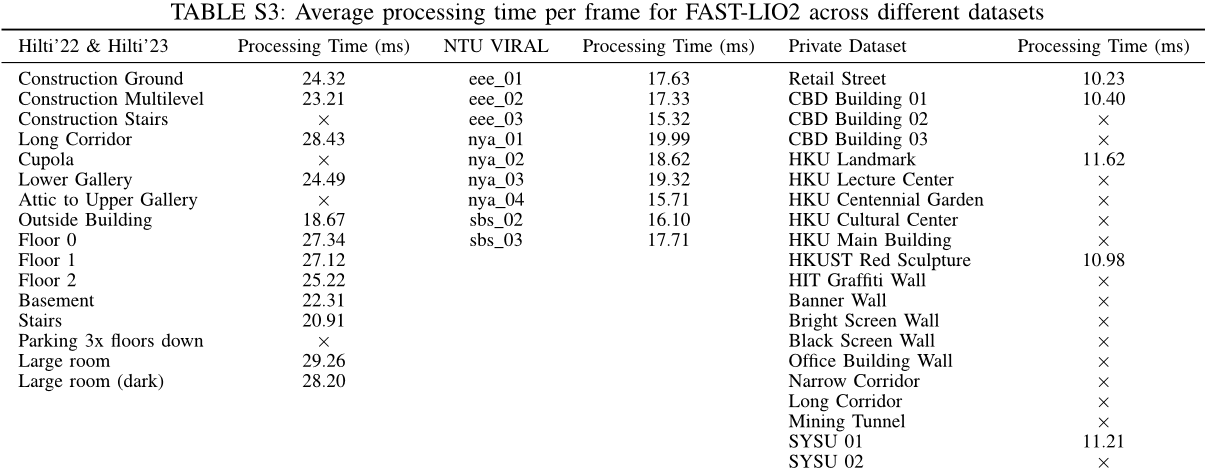
在本节中,我们评估了我们的系统在每台计算机上进行的激光雷达扫描和图像帧的平均计算时间。该系统是在配备英特尔i7-10700K中央处理器和32GB内存的桌面PC上测试的。我们的评估涵盖了公共数据集Hilti’22、Hilti’23和NTU-VIRAL以及我们的私有数据集。如表III所示,在所有序列中,我们的系统具有最低的处理时间。Intel i7处理器上的平均计算时间为仅30.03毫秒(每个激光雷达扫描为17.13毫秒,每个图像帧为12.90毫秒),满足10Hz实时操作。此外,我们的系统甚至可以在ARM处理器上以每个帧仅为78.44毫秒的平均处理时间实现实时运行。LVI-SAM中的LIDAR和视觉特征提取模块在LIO和VIO中耗时。除了LIO和VIO消耗的时间外,LVI-SAM还通过图因子将IMU预集成约束、视觉里程计约束和LIDAR里程计约束整合到一个因素图中,进一步增加了整体
处理时间。对于R3LIVE,尽管也采用了直接方法,但由于其像素级图像对齐需要使用大量视觉地图点,因此效率较低。相比之下,我们的方法使用稀疏点和参考块进行对齐,从而实现高效的对齐。此外,R3LIVE维护一个彩色地图,并且随着地图分辨率的提高,该地图会经历贝叶斯更新,这显著增加了计算负载。对于FAST-LIO2,每帧的平均处理时间(由于篇幅限制,在补充材料中为表S3)约为FAST-LIVO2的10.35毫秒,因为没有处理额外的图像测量。
FAST-LIVO2在FAST-LIVO的基础上也取得了显著的改进。主要改进来自我们对稀疏图像对齐中逆成分形式的应用。基于LiDAR点的平面先验进行仿射变形进一步提高了我们的方法的收敛效率。因此,FAST-LIVO2将每个金字塔层的迭代次数从10次减少到3次,同时仍保持了更高的精度。
X、应用
为了展示FAST-LIVO2在实际应用中的优异性能和多功能性,我们开发了多个
×表示系统完全失败。
解决方案,包括完全自主的无人机导航、空中测绘、纹理网格生成和三维场景表示的3D高斯溅射重建。
A. 全面自主无人机导航
鉴于FAST-LIVO2的高精度和稳健定位性能,以及其实时能力,我们进行了闭环自主无人机飞行。
系统配置:硬件和软件设置如图12所示。对于硬件,我们使用NUC(Intel i7-1360P CPU和32GB RAM)作为机载计算机。在软件方面,本地化组件由FAST-LIVO2提供动力,以每秒10赫兹的速度提供位置反馈。定位结果被馈送到飞行控制器,以实现每秒200赫兹的位置、速度和姿态反馈。
除了本地化,FAST-LIVO2还向规划模块提供密集的注册点云,该模块使用Bubble Planner [55]进行平滑轨迹规划,然后由在飞行控制器上运行的Model Predictive Control (MPC) [56]跟踪。MPC计算所需的角速度和推力,这些值分别由低级角速率控制器跟踪。重要的是,MPC、Planner 和 FAST-LIVO2 都实时运行在机载计算机上。
2)无人机自主导航:我们进行了4次完全在机载的无人机自主导航实验,“地下室”,“树林”,“狭窄通道”和“中山大学校园”(补充材料中的表S2)。 “地下室” 和“树林”的实验是完全自主飞行,包括所有规划、MPC和FAST-LIVO2模块;而“狭窄通道”和“中山大学校园”则是手动飞行。
仅使用MPC和FAST-LIVO2(不包含规划组件)。如图所示,“地下室”和“树林”展示了无人机的自主导航和避障成功。在“狭窄开口”,无人机被命令飞到墙壁附近,导致很少的LiDAR点测量。然而,射线投射模块会唤起更多的视觉地图点,提供丰富的定位约束,从而实现稳定的定位。“地下室”和“狭窄开口”经历LiDAR退化,只观察到单面墙(见图1 (e1) 和 (e4),图13 (b1-b4)) ,以及显著的曝光变化(见图1 (e5-e6)) 。尽管面临这些挑战,我们的无人机系统表现优异。“树林”涉及无人机以高达3米/秒的速度移动,要求整个无人机系统快速响应(见图13 (a1-a4)) 。非退化的场景“中山大学校园”主要演示了机载高精度测绘能力(见补充材料中的图S14) 。最后值得一提的是,在这四次无人机飞行中都发生了严重的照明变化。FAST-LIVO2能够估计接近地面真实值的曝光时间(见补充材料中的图S15) 。
关于在机计算时间,需要在机载计算机上运行MPC(每秒100次)和规划(每秒10次),消耗了计算资源和内存,限制了FAST-LIVO2可用的计算资源。尽管同时执行控制和规划,如图14所示,FAST-LIVO2每LiDAR扫描和图像帧的平均在机处理时间为53.47毫秒,仍然远远低于100毫秒的帧周期。规划和MPC的平均处理时间分别为8.43毫秒和18.5毫秒。总平均处理时间为80.4毫秒,很好地满足了机载操作的实时要求。
机载无人机实验时间成本
图14:在“地下室”、“树林”、“狭窄通道”和“中山大学校园”的自主导航实验中,每个模块的处理时间和总处理时间。MPC以100Hz执行规划,FAST-LIVO2以10Hz执行,因此其计算时间被计为10次。
B. 空中测绘
航空测绘在测绘应用中是一项关键任务。为了评估FAST-LIVO2是否适合这一应用,我们使用了公共数据集MARS-LVIG[52]进行航空测绘实验,该数据集的硬件配置详见第八章A节。我们对两个序列“HKairport01”和“HKisland01”进行了评估,
其实时映射结果如图1(a-c)所示,其中(a)和(c)对应“HKisland01”,(b)描绘了“HKairport01”。这些结果表明FAST-LIVO2在森林、岛屿等无结构环境中具有有效性。系统成功捕获了许多精细的结构和锐利的颜色效果,包括建筑物、道路车道标记、路缘石、树冠以及岩石,所有这些都清晰可见。与R3LIVE相比,这些序列的APE (RMSE)分别为0.64米和0.27米,而FAST-LIVO2为0.27米;平均处理时间在桌面PC上(第IX章A节),分别为约25.2毫秒和21.8毫秒,而R3LIVE分别为110.5毫秒和100.2毫秒。
C.支持三维场景应用:网格生成、纹理和高斯溅射
利用FAST-LIVO2获得的高精度传感器定位和密集三维彩色点云,我们开发了渲染管道软件应用程序,包括网格化和纹理化,以及新兴的NeRF样式的渲染管道,如3D高斯散射(3DGS)。对于网格化,我们在“CBD建筑01”,图15 (a)中基于TSDF的VDB融合上使用它。柱子上的锐利边缘和屋顶的明显结构清晰可见,展示了网格的高质量。这种细节水平是由于FAST-LIVO2点云的高度密度和结构重建的出色准确性而实现的。在网格构建之后,我们使用OpenMVS [58]对“CBD建筑01”和“零售街”的估计相机姿态进行纹理映射,如图15 (b-c)所示。在图15 (c1-c2),三角形面片上应用的纹理图像无缝且准确地对齐,导致高度清晰和精确的纹理映射。这归因于FAST-LIVO2像素级图像对齐。
FAST-LIVO2的密集颜色点云也可以直接作为3DGS的输入。我们利用“CBD Building 01”的序列进行了测试,使用了300帧数据集。
总共1,180张图像。结果如图16所示。与COLMAP [59]相比,我们的方法显著减少了从9小时到21秒获得稠密点云和姿态的时间。然而,训练时间从10分59秒增加到15分30秒。这种增加归因于更密集的点云(下采样至5厘米),这引入了更多参数进行优化。尽管如此,我们点云的密度和精度提高导致PSNR比COLMAP输入的PSNR略高。
XI 结论与未来工作
本文提出了一种直接的LIVO框架FAST-LIVO2,该框架在重建地图的同时实现了快速、准确和鲁棒的状态估计。FAST-LIVO2可以在严重LiDAR或视觉退化的情况下实现高定位精度。
速度的提高归功于在高效的ESIKF框架中使用了顺序更新的原始LiDAR、惯性以及相机测量。在图像更新中,采用逆成分形式和稀疏块图像对齐进一步提高了效率。准确性的提高归功于从LiDAR点中使用(甚至细化)平面先验来增强图像对齐的准确性。此外,使用单个统一的体素图来同时管理地图点和观察到的高分辨率图像测量。开发并验证了支持几何构造和更新、视觉地图点生成和更新、参考块更新的体素图结构。由于实时估计曝光时间,有效地处理环境照明变化,并根据需要进行体素射线投射以应对激光雷达近距离盲区,因此获得了鲁棒性。FAST-LIVO2在广泛的公共数据集上评估了其效率和精度,而每个系统模块的稳健性和有效性则在私人数据集中进行了评估。还演示了FAST-LIVO2在实际机器人应用中的应用,例如无人机导航、三维建模和模型渲染。
作为里程计,FAST-LIVO2可能在长距离上存在偏移。在未来,我们可以集成环路闭合和
通过滑动窗口优化FAST-LIVO2来缓解这种长期漂移。此外,精确且密集的彩色点图可用于提取对象级语义映射的语义信息。
参考文献
[1]R.Mur-Artal和J.D.Tardo的,“Orb-SLAM2:一种开源单目、立体和RGB-D相机的SLAM系统”,IEEE机器人学杂志,卷33,第5期,页1255-1262,2017。
[2] J. Engel,V. Koltun,and D. Cremers,“直接稀疏里程计”,IEEE模式分析与机器智能杂志,卷40,第3期,页611-625,2017。
[3]J. Engel,T. Scho¨ps和D. Cremers,“Lsd-slam:大规模直接单目SLAM”,欧洲计算机视觉会议。Springer出版社,2014年,第834-849页。
[4] C. Forster,Z. Zhang,M. Gassner,M. Werlberger和D. Scaramuzza,“SVO:半直接视觉里程计用于单目和多相机系统”,IEEE机器人学杂志,卷33,第2期,页249-265,2016。
[5] 张杰和辛格,“Loam:实时激光雷达里程计和地图绘制。”在机器人学:科学与系统,卷。2,第9期,2014年。
[6]林杰和张飞,“洛马Livox:一种快速、稳健且高精度的激光雷达里程计和地图包”,在2020年IEEE国际机器人与自动化会议(ICRA)。IEEE,2020,第3126-3131页。
[7] T. Shan 和 B. Englot,“乐高粘土:在地形变化的地面优化激光雷达里程计和地图”,IEEE/RSJ国际智能机器人与系统会议(IROS),IEEE,2018年,第4758-4765页。
[8] 郑超,朱强,徐文,刘旭,郭庆和张飞,“Fast-LIVO:快速且耦合紧密的稀疏直接激光雷达惯性视觉里程计”,在2022年IEEE/RSJ国际智能机器人与系统会议(IROS)。IEEE出版社,2022年,第4003-4009页。
[9]T.Qin,P.Li和S.Shen,“Vins-mono:一种稳健且通用的单目视觉惯性状态估计器”,IEEE机器人学杂志,卷。34,第4期,页。1004-1020,2018年。
[10]R.Mur-Artal,J.M.M.Montiel和J.D.Tardos,“Orb-SLAM:一种多功能且准确的单目SLAM系统”,IEEE机器人学杂志,卷。31,第5期,页。1147-1163,2015年。
[11] M. Irani 和 P. Anandan,“关于直接方法的一切”,在“视觉算法,理论实践”研讨会论文集,1999年,第267-277页。
[12] C. Forster,M. Pizzoli和D. Scaramuzza,“SVO:快速半直接单目视觉里程计”,在2014年IEEE国际机器人与自动化会议(ICRA)。IEEE,2014,第15-22页。
[13] 徐文,蔡毅,何栋,林杰和张飞,“快速LIO2:快速直接激光雷达惯性里程计”,《IEEE机器人学杂志》,第1页至第21页,2022年。
[14] YUAN Chuan, XU Wei, LIU Xiaoyu, HONG Xin, ZHANG Fei, “Efficient and Probabilistic Adaptive Voxel Mapping for Accurate Online Lidar Odometry,” IEEE Robotics and Automation Letters, Vol. 7, No. 3, pp. 8518-8525, 2022。
[15] M. Meilland,A.I.Comport和P.Rives,“在大照明变化下的实时密集视觉跟踪”,英国机器视觉会议。英国机器视觉协会,2011年,第45-1页。
[16]T.Tykkala,C.Audras,A.I.Comport,“Direct Iterative Closest Point for Real-Time Visual Odometry”,in 2011 IEEE International Conference on Computer Vision Workshops (ICCV Workshops),IEEE,2011,pages 2050-2056。
[17] C. Kerl,J. Sturm和D. Cremers,“RGB-D相机的鲁棒里程计估计”,在2013年IEEE国际机器人与自动化会议。IEEE,2013,第3748-3754页。
[18] J. Engel,J. Sturm和D. Cremers,“单目相机的半稠密视觉里程计”,IEEE国际计算机视觉会议论文集,2013年,第1449-1456页。
[19]Chen K., Nemiroff R., and Lopez BT, “Direct Lidar-Inertial Odometry: Lightweight LIO with Continuous-Time Motion Correction,” in 2023 IEEE International Conference on Robotics and Automation (ICRA), IEEE, 2023, pp. 3983-3989.
[20] 王泽,张磊,沈宇,周扬,“D-LiOM:直接激光雷达惯性里程计和地图构建的紧密耦合”,IEEE多媒体杂志,2022。
[21] 张杰和辛格,“具有高鲁棒性和低漂移的激光-视觉-惯性里程计与地图”,《现场机器人学杂志》,第35卷,第8期,第1242-1264页,2018年。
[22]王少,维贾亚拉甘,李春,康托尔,“立体视觉惯性激光雷达同步定位与建图”,IEEE国际智能机器人和系统会议(IROS),2019年,第370-377页。
[23] 张杰,卡斯,辛格,“一种用于增强视觉里程计的实时方法”,自主机器人,卷。 41,第31-43页,2017年。
[24] J. Graeter,A. Wilczynski和M. Lauer,“Limo:基于激光雷达单目视觉里程计”,在2018年IEEE/RSJ国际智能机器人与系统会议(IROS)。IEEE,2018,第7872-7879页。
[25] Zhu Y., Zheng C., Yuan C., Huang X., and Hong X., “Camvox: a low-cost and accurate lidar-assisted visual SLAM system,” in 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), IEEE, 2021, pp. 6387-6393.
[26] 黄世胜,马志远,穆天杰,傅海,胡思明,“基于点和线特征的激光雷达单目视觉里程计”,IEEE国际机器人与自动化会议(ICRA),2020年,第1091-1097页。
[27] C. Campos,R. Elvira,J.J.G. Rodríguez,J.M. Montiel和J.D.Tardós,“Orb-SLAM3:一个准确的开源视觉、视觉-惯性多地图SLAM库”,IEEE机器人学杂志,卷37,第6期,页1874-1890,2021。
[28] Y.-S. Shin,Y. S. Park和A. Kim,“Dvl-slam:稀疏深度增强的直接视觉-激光雷达SLAM”,自主机器人,卷。44,第2期,页。115-130,2020年。
[29] X. Zuo,P. Geneva,W. Lee,Y. Liu,and G. Huang,“Lic-fusion:Lidar-inertial-camera odometry”,in 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS),2019,pp. 5848-5854。
[30] Sun K., Mohta K., Pfrommer B., Watterson M., Liu S., Mulgaonkar Y., Taylor C.J., Kumar V., “Robust Stereo Visual Inertial Odometry for Fast Autonomous Flight,” IEEE Robotics and Automation Letters, Vol. 3, No. 2, pp. 965-972, 2018。
[31] X. Zuo,Y. Yang,P. Geneva,J. Lv,Y. Liu,G. Huang,and M. Pollefeys,“Lic-fusion 2.0:Lidar-inertial-camera odometry with sliding-window plane-feature tracking”,in 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS).IEEE,2020,pp. 5112-5119。
[32] D. Wisth,M. Camurri,S. Das和M. Fallon,“紧密耦合的激光雷达视觉惯性里程计中的统一多模态地标跟踪”,《IEEE机器人与自动化快报》,第6卷,第2期,第1004-1011页,2021年。
[33] 林杰,郑超,徐文,张飞,“R2Live:一种鲁棒、实时的激光雷达惯性视觉紧密耦合状态估计器和地图”,IEEE机器人与自动化快报,卷6,第4期,页7469 - 7476,2021。
[34] C.F.W.Bell,B.M.“迭代卡尔曼滤波更新作为高斯牛顿方法”,自动控制IEEE交易,卷。38,第2期,页。294-297,1993年。
[35] Shan T., Englot B., Ratti C., and Rus D., “Lvi-SAM: tightly coupled lidar-visual-inertial odometry through smoothing and mapping,” in 2021IEEE International Conference on Robotics and Automation (ICRA), IEEE, 2021, pp. 5692-5698.
[36]林杰和张飞,“R 3实时:一种稳健的、实时的、彩色RGB激光雷达惯性视觉紧密耦合状态估计与映射包”,在2022年国际机器人与自动化会议(ICRA)。IEEE,2022,第10672 - 10678页。
[37]——,“R 3 live++:一个稳健的、实时的辐射重建包,具有紧密耦合的激光雷达惯性视觉状态估计器”,arXiv预印本arXiv:2209.03666,2022。
[38] J. Engel,V. Usenko和D. Cremers,“基于光度校准的单目视觉里程计基准”,arXiv预印本arXiv:1607.02555,2016。
[39] 王伟,刘杰,王超,罗斌,张春,“Dv-LOAM:直接视觉激光雷达里程计和地图”,《遥感》,第13卷,第16期,第3340页,2021年。
[40] Yuan Z., Wang Q., Cheng K., Hao T., and Yang X., “SDV-LOAM: Semi-Direct Visual-LiDAR Odometry and Mapping,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023。
[41] 张海,杜亮,鲍帅,袁杰,马胜,“Lvio-fusion:在退化环境中紧密耦合的激光雷达视觉惯性里程计和地图构建”,IEEE机器人与自动化快报,卷9,第4期,页3783-3790,2024。
[42] XU Wei and ZHANG Fei, “Fast-lio: Fast, Robust Lidar-Inertial Odometry Package Based on Tight Coupling Iterative Kalman Filter,” IEEE Robotics and Automation Letters, pp. 1–1, 2021.
[43] 徐伟,何德,张飞,“基于曼哈顿的迭代误差状态扩展卡尔曼滤波器符号表示和工具箱开发”,工业电子学杂志,2023。
[44]D.Willner,C.-B.Chang和K.-P.Dunn,“多传感器系统的卡尔曼滤波算法”,在1976年IEEE决策与控制会议包括第十五届自适应过程研讨会。IEEE,1976,pp. 570-574。
[45] 马杰,孙世,“具有相关噪声的多传感器系统全局最优分布式和顺序状态融合滤波器”,信息融合,第101885页,2023。
[46] Ren Y., Cai Y., Zhu F., Liang S., and Zhang F., “Rog-map: An Efficient Robocentric Occupancy Grid Map for Large-Scene and High-Resolution Lidar-Based Motion Planning,” arXiv preprint arXiv:2302.14819, 2023.
[47] R.M.Stereopsis,“精确,密集和鲁棒的多视点立体视觉”,IEEE模式分析与机器智能杂志,卷。32,第8期,2010年。
[48]S. Baker和I. Matthews,“Lucas-Kanade二十年:统一框架”,计算机视觉国际期刊,卷。 56,第221 - 255页,2004年。
[49] T.-M. Nguyen,S. Yuan,M. Cao,Y. Lyu,T. H. Nguyen和L. Xie,“Ntu Viral:一个从空中车辆视角的视觉-惯性定位激光雷达数据集”,《机器人学国际期刊》,第41卷,第3期,第270-280页,2022年。
[50] M. Helmberger,K. Morin,B. Berner,N. Kumar,G. Cioffi,and D. Scaramuzza,“Hilti Slam Challenge Dataset”,IEEE Robotics and Automation Letters,Vol. 7,No. 3,pp. 7518-7525,2022。
[51] 张磊,赫尔姆伯格,傅立夫,维斯蒂,卡穆里,斯卡拉穆萨和法伦,“希尔蒂牛津数据集:同步定位与建图的毫米级基准”,IEEE机器人与自动化快报,第8卷,第1期,第408 - 415页,2022年。
[52] 李浩,邹宇,陈宁,林杰,刘旭,徐文,郑超,李睿,何栋,孔凡等,“火星数据集:多传感器空中机器人激光雷达视觉惯性全球导航卫星系统融合的SLAM数据集”,《国际机器人学杂志》,第02783649241227968页,2024年。
[53]“补充材料:Fast-livo2:快速,直接的激光雷达惯性视觉里程计”,在线可用:https://github.com/hku-mars/FAST-LIVO2/blob/main/Supplementary/LIVO2 supplementary.pdf。
[54] C. Klug,C. Arth,D. Schmalstieg和T. Gloor,“机器人全站仪模拟测量不确定度分析”,在IEEE工业电子学会第44届年度会议IECON 2018上。IEEE出版社,2018年,第2576页至2582页。
[55] Ren Y., Zhu F., Liu W., Wang Z., Lin Y., Gao F., and Zhang F., “Bubble Planner: Planning High-Speed Smooth Quadrotor Trajectories Using Receding Corridors,” in 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), IEEE, 2022, pp. 6332-6339.
[56]Lu G., Xu W., and Zhang F., “Manifold-based Model Predictive Control for Trajectory Tracking in Robotic Systems,” IEEE Transactions on Industrial Electronics, Vol. 70, No. 9, pp. 9192-9202, 2022。
[57]I.Vizzo,T.Guadagnino,J.Behley和C.Stachniss,“Vdbfusion:范围传感器数据的灵活且高效的tsdf集成”,Sensors,卷。22,第3期,2022年在线。可用:https://www.mdpi.com/1424-8220/22/3/1296
[58] D. Cernea,“Openmvs:多视点立体重建库。2020”,URL:https://cdcseacave.github.io/openMVS,卷5,第6期,页7,2020年。
[59] J.L.Scho¨nberger和J.-M.Frahm,“运动从结构中重新审视”,在2016年IEEE计算机视觉与模式识别会议(CVPR),2016,第4104-4113页。
FAST-LIVO2的补充材料:快速,直接的激光雷达惯性视觉里程计
I. 系统模块验证
在本节中,我们验证了系统的关键模块,包括仿射变形、法向细化、参考贴图更新、按需线性扫描查询、曝光时间估计和使用FAST-LIVO2私有数据集和MARS-LVIG数据集的ESIKF顺序更新。
A. 仿射变形评估
在本实验中,我们旨在基于常深度假设(一种半稠密方法常用的技术)、点云的平面先验和我们提出的系统的精细平面法线(分别表示为“常深度”,“平面先验”和“平面法线精化”)对各种仿射变形效果进行综合评估。为了实现这一目标,我们在“CBD建筑02”和“办公大楼外墙”上比较了三种方法的映射结果和漂移度量。如图S2所示,“平面法线精化”提供了最清晰准确的映射结果,并且“平面先验”的次优结果紧随其后。“平面法线精化”在地面上和墙壁上的文本和图案以及车道标记上呈现出令人印象深刻的高度清晰度。此外,“平面先验”和“平面法线精化”的漂移均保持在0.01米以下,而“常深度”并未返回起始位置,经历了一段0.22米的漂移。这些结果证实了基于平面先验的仿射变形性能提升及其通过平面法线精化的改进。
此外,我们基于“常深度”和“平面先验”,比较了序列“CBD Building 02” 和“办公室外墙”的扭曲投影效果。我们随机从这两个序列中选择几个图像帧进行定性分析。对于每个帧,我们将视觉地图点可见的参考贴图投影到当前帧的空白图像上。这个过程产生了一个新颖的RGB图像。如果对齐和平移估计都做得很好,则贴图投影区域将产生无缝且轻微失真的外观,与原始RGB图像非常相似。扭曲贴图的对比结果如图S1所示。结果显示,“平面先验”下的姿态精度和扭曲性能显著优于“常深度”。
B.参考补丁更新和正常收敛的评估
在本实验中,我们验证了参考贴图更新策略和正常收敛对“HIT Graffiti Wall” 和“HKU Centennial Garden”的影响。如图S3所示,(a) 和 (b) 是这两个序列的重建点云。在右侧,从A到H每个区域分别展示了五个不同姿态下捕获的贴图观察,每个观察的大小为40×40像素用于可视化。这些贴图是在左列对应编号上的相机帧上观察到的。可以发现,我们的参考路径更新策略倾向于选择一个高分辨率的面向平面的参考贴图。此外还注意到,在非平面位置(例如树叶子、树干和灯柱)生成视觉地图点和贴图时,整体映射质量仍然很高。
我们还评估了我们提出的在区域A到H的正常估计的收敛性。每个块大小为11× 11像素。初始法向矢量是从激光雷达点估计出来的。收敛曲线,代表迭代次数中初始和优化法向矢量之间的角度变化,在图S3中显示。区域A、C、D和E是结构化区域,而区域B、F、G和H是非结构化区域。可以观察到,对于结构化区域,法向矢量在6次迭代内快速收敛(法向细化范围为2至4度),因为由点云提供的初始法向相对准确。在非结构化区域,如灌木丛和树叶(即B和F)需要9次迭代来收敛,并且具有显著的法向细化(最大可达9度)。总体而言,这些8个区域的法向细化显示出良好的收敛特性。
图S2:(a)和(b)是“CBD建筑02”和“办公大楼外墙”的FAST-LIVO2默认映射结果。(a1,b1),(a2,b2),(a3,b3)分别使用了“平面法线细化”,“平面先验”和“常深度”对点云进行了放大。
图S3:参考贴片更新的示意图。(a)和(b)分别是序列“HIT Graffiti Wall”和“HKU Centennial Garden”的重建点云。区域A到H涵盖了场景中的结构化和非结构化区域。在右侧,40×40图像块展示了同一区域的各种观察结果,数字表示左侧对应相机帧。每个区域的参考贴片用红色方框突出显示。©显示了从区域A到H的贴片法线收敛性。
C. 评价按需射线投射
在这个实验中,我们评估了在极端条件下(当前和最近的激光雷达扫描由于激光雷达的近距离盲区而几乎没有或根本没有点)需求式射线投射模块的表现。我们使用序列“窄走廊”进行深入分析,如图S4所示。在这个序列中,我们穿过一个非常狭窄的隧道,宽度约为1.9米,并转向面对一侧纹理较弱的墙壁。由于面向墙壁时激光雷达扫描中的点有限,我们只能通过体素查询获得少量视觉地图点(黄色点在图S4 (b) 中)。在这种情况下,射线投射提供了足够的视觉约束来缓解退化(蓝色点在图S4 (b) 中)。可视化结果表明,在面临激光雷达扫描中点数较少的情况下,需求式射线投射模块表现良好。
D. 评估暴露时间估计
在这个实验中,我们验证了曝光时间估计模块的两个部分:1)对于固定曝光和增益的序列,我们对每个接收原始图像的像素乘以一个随着时间变化的正弦函数。通过将估计的曝光时间与应用的正弦函数进行比较来验证我们的估计的有效性。2)对于具有自动曝光和固定或自动增益设置的序列,我们通过将其与从相机API检索的真实值进行比较来评估我们估计的曝光时间的准确性。
在第一部分中,我们对序列“零售街”进行测试,并将曝光因子应用于固定曝光和增益的图像。如图S5所示,估计的相对反向曝光时间与真实值非常吻合,证明了我们在合成条件下曝光估计的收敛性。在第二部分中,我们使用具有显著曝光时间变化的序列“香港大学百年花园”,“香港大学文化花园”和“香港大学主楼”进行测试。我们将估计的相对曝光时间乘以第一个帧来恢复每个帧的实际曝光时间(毫秒)。如图S5所示,估计的曝光时间紧密跟随地面实测值,验证了我们的曝光时间估计模块的有效性。偶尔出现的不匹配可能是由于未建模响应函数和暗角因素造成的[38]。
E. 评价ESIKF序列更新
在这个实验中,我们评估了不同激光雷达和相机状态的ESIKF更新策略。我们将异步更新与同步更新以及标准更新与顺序更新进行比较。具体来说,我们评估三种策略:“异步(标准更新)”,其中相机和激光雷达的状态分别在各自的采样时间更新,而没有扫描重组;“同步(标准更新)”,其中将激光雷达扫描重新组合以同步相机图像,并且使用激光雷达和相机测量值在标准ESIKF中更新状态;“同步(顺序更新)”,其中激光雷达和相机被同步,但首先通过激光雷达测量更新状态,然后通过相机测量更新状态。这些策略是根据精度、鲁棒性和效率来评估的,使用MARS-LVIG数据集中的“AMvalley03”序列。我们选择此序列有几个关键原因:
(1)该序列包括导致LiDAR和视觉退化的斜坡,使其成为具有挑战性的测试案例。
(2)该序列代表了一个极大规模的场景(约901m×500m×130m),具有长期高速的数据采集特性(以每秒12米的速度覆盖600秒),在长时间、高速度条件下,姿态偏差容易发生,并且即使轻微偏移也会导致彩色点云中出现明显的模糊现象(由于规模较大),从而产生更显著的对比结果。
(3)该序列提供了RTK地面真实数据,允许进行更准确的定量比较。
我们比较了三种更新策略的定性映射结果、定量APE和平均处理时间。实验配置如下:LiDAR更新涉及最多5次迭代,视觉更新使用一个三级金字塔,每层最多5次迭代,在标准ESIKF中同时更新相机和LiDAR时不超过3次迭代,并且“同步(标准更新)”中的缩放规范化因子(从视觉光度误差到LiDAR点平面距离)设置为0.0032,经过精心调整以获得最佳性能。
图S6(a-c)显示了该序列的重建彩色点云。很明显,“同步(顺序更新)”策略产生了准确的地图结果,特别是在蓝色和橙色方框突出显示的区域中,这些区域中的山道没有分层重建。相比之下,其他两种策略在这些区域中表现出偏差,尽管“同步(标准更新)”略优于“异步(标准更新)”。 “同步(顺序更新)”策略的优越性能主要归因于其处理显著的LiDAR和视觉退化方面的稳健性,在白色方框(c3)中可以看到这一点。这个区域有一个大型、纹理不明显的斜坡,无人机以高速通过它,高度依赖强大的先验知识。另外两个方法,仅依靠IMU先验知识,难以计算出相对准确的图像梯度下降方向,导致显著的线性化误差。
对于“AMvalley03”序列,分别采用“异步(标准更新)”,“同步(标准更新)”和“同步(顺序更新)”方法时的APE (RMSE)指标分别为3.12米、2.45米和0.68米。在桌面PC上进行处理的时间平均值约为27.6毫秒、49.9毫秒和23.1毫秒。我们提出的“同步(顺序更新)”方法效率最高且精度最佳,“异步(标准更新)”方法精度最低。“同步(标准更新)”方法耗时最长,主要原因是它需要将图像金字塔中每个层次的所有LiDAR测量结果融合在一起。
总体而言,我们提出的“同步(顺序更新)”提供了最佳的准确性和效率,“异步(标准更新)”具有最低的准确性,“同步(标准更新)”是最耗时的。
图S6:(a)、(b)和(c)分别是“异步(标准更新)”、“同步(标准更新)”和“同步(顺序更新)”策略在“AMvalley03”的映射结果。(a1,b1,c1)和(a2,b2,c2)是不同更新策略的点云放大视图。蓝色线表示无人机飞行路径,而(c3)中的红色点代表了当时LiDAR扫描的位置。
序列通过在环形路径上旅行收集,起点和终点相同。
从相机的API读取了两个序列的真实相机曝光时间。
存在三个序列,LiDAR在近距离盲区中无法捕获点云。
4序列包括从室内到室外环境的移动过程。
具有显著照明变化的5个序列。

是禁用的。
总体平均分:19.68
图S8:FAST-LIVO2在Hilti’22数据集中的实时映射结果。(a)“阁楼到上层画廊”,(b)“穹顶”,©“下层画廊”和(d)“施工楼梯”。(a-c)的点云使用强度着色,而(d)则使用灰度图像着色。
图S9:在丰富纹理和结构化的场景中在线实时映射结果。从左到右的点云分别对应“香港大学地标”,“中山大学01号”和“CBD建筑01号”,显示了FAST-LIVO2,FAST-LIVO,R3LIVE和FAST-LIO2彩色点云精度之间的比较。
图S12:“长走廊”中FAST-LIVO2的实时映射结果。(a)彩色点云地图的鸟瞰图,(b)细节放大图,(c)激光雷达面对单面墙导致激光雷达退化。
图S14:(a)是“中山大学校园”实验的放大点云图像。(a1),(a2),和 (a3)代表在相应位置的第三人称视图。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)