OpenVLA论文精读
大型策略(AI模型)预先在互联网规模的视觉-语言数据和多样机器人演示上训练,有潜力改变我们教机器人新技能的方式:而不是从零训练新行为,我们可以微调这样的视觉-语言-动作(VLA)模型,得到 robust(稳健的)、generalizable(能泛化的)策略,用于视觉运动控制。然而,VLA在机器人领域的广泛采用面临挑战,因为。
链接:https://openvla.github.io
标题
OpenVLA: An Open-Source Vision-Language-Action Model
摘要(Abstract)
大型策略(AI模型)预先在互联网规模的视觉-语言数据和多样机器人演示上训练,有潜力改变我们教机器人新技能的方式:而不是从零训练新行为,我们可以微调这样的视觉-语言-动作(VLA)模型,得到 robust(稳健的)、generalizable(能泛化的)策略,用于视觉运动控制。然而,VLA在机器人领域的广泛采用面临挑战,因为1)现有VLA大多封闭,不对公众开放;2)之前的工作没探索高效微调VLA到新任务的方法,这是采用的关键。
为了解决这些挑战,我们介绍OpenVLA,一个70亿参数的开源VLA,在970k真实世界机器人演示的多样集合上训练。OpenVLA基于Llama 2语言模型,加上融合DINOv2和SigLIP预训练特征的视觉编码器。由于增加了数据多样性和新模型组件,OpenVLA在通用操作中表现出色,比封闭模型如RT-2-X(550亿参数)在29个任务和多个机器人身上的成功率高16.5%,参数却少7倍。我们进一步显示,可以有效微调OpenVLA到新设置,尤其在涉及多个对象和强语言grounding(理解)的多任务环境中泛化好,比从零模仿学习方法如Diffusion Policy高20.4%。我们也探索计算效率,作为独立贡献,我们显示OpenVLA可以用现代低秩适应方法在消费级GPU上微调,并通过量化高效served(运行),不影响下游成功率。最后,我们发布模型检查点、微调笔记本,和PyTorch代码库,支持大规模训练VLA在Open X-Embodiment数据集上。

图1:展示OpenVLA
解释:
现在机器人AI弱,因为只能学自己见过的东西,不能泛化(比如新物体、新指令)。但用大模型(像ChatGPT那种)预训练,能让机器人聪明点。问题:以前模型不公开,不好改。现在作者做了OpenVLA,公开的,用970k机器人视频训练,比别人小但强(成功率高16.5%)。还能在普通电脑上改,跑得快。总之,这是机器人界的“开源革命”。
图1的上半部分展示了一个流程:左侧是“Large-Scale Robot Training Data”(大规模机器人训练数据),包括970k个机器人episode(演示片段)的示例照片,这些数据来自Open X-Embodiment数据集,用于训练模型;中间是“OpenVLA”(视觉-语言-动作模型),它基于Llama 2 7B参数的基底VLM(视觉语言模型),结合ViT(视觉Transformer)来微调,输入是图像观察和语言指令,输出是机器人动作(如位置、抓取变化);右侧是“Closed-Loop Robot Control Policy”(闭环机器人控制策略),示例中用户指令“Wipe the table”(擦桌子),模型输出动作序列如[Δx, Δy, ΔGrip],并配以机器人臂执行的图标,强调实时控制。
图1的下半部分左侧是“Multi-Robot Control & Efficient Fine-Tuning”(多机器人控制和高效微调),展示了多张照片,包括不同机器人臂执行任务如洗碗、抓苹果/香蕉/可乐/鼠标,突出模型支持多种机器人类型并可快速适应新域;右侧是“Fully Open-Source”(完全开源),用图标表示Data(数据)、Weights(权重)和Code(代码),强调模型检查点、训练管道和PyTorch代码均开源,可从HuggingFace下载。这张图整体 ilustrates OpenVLA如何通过大规模数据和预训练VLM实现通用机器人操纵的SOTA(state-of-the-art),比封闭模型如RT-2-X强16.5%,参数少7倍,并支持高效微调和开源生态。
1. 引言(Introduction)
学习策略(AI模型)在机器人操作中的关键弱点是无法超出训练数据泛化:虽然现有策略训练单个技能或语言指令,能推断到新初始条件如物体位置或灯光,但对场景干扰物或新物体不robust(不稳),执行未见任务指令也难。
但在机器人外,现有视觉和语言基础模型如CLIP、SigLIP、Llama 2能这种泛化,因为它们从互联网规模预训练数据集捕捉先验知识。虽然为机器人重现这种规模预训练还是开放挑战——即使最大机器人操作数据集只有10万到100万例子——这种不平衡暗示机会:用现有视觉和语言基础模型作为核心构建块,训练机器人策略,能超出训练数据的物体、场景、任务泛化。
为此,现有工作探索整合预训练语言和视觉-语言模型用于机器人表示学习,以及模块系统用于任务规划和执行。最近,它们用于直接学习视觉-语言-动作模型(VLA)用于控制。VLA提供直接实例,用预训练视觉-语言基础模型直接微调视觉条件语言模型如PaLI生成机器人控制动作。通过基于互联网规模数据强基础模型,VLA如RT-2展示impressive(令人印象深刻)的robust结果,以及泛化到新物体和任务的能力,设定通用机器人策略新标准。然而,有两个关键原因阻止现有VLA广泛使用:1)当前模型封闭,对模型架构、训练程序、数据混合可见度有限;2)现有工作没提供最佳实践部署和适应VLA到新机器人、环境、任务——尤其在消费硬件如消费级GPU上。我们认为,要开发未来研究和开发的丰富基础,机器人需要开源、通用VLA,支持有效微调和适应,像现有开源语言模型生态一样。
为此,我们介绍OpenVLA,一个70亿参数开源VLA,建立通用机器人操作策略新state of the art。OpenVLA包括预训练视觉条件语言模型骨干,捕捉多粒度视觉特征,在Open-X Embodiment数据集970k机器人操作轨迹的大多样数据集上微调——数据集跨越广泛机器人实施、任务、场景。由于增加数据多样性和新模型组件,OpenVLA超出550亿参数RT-2-X模型,先前state-of-the-art VLA,在WidowX和Google Robot上的29个评估任务成功率绝对高16.5%。我们额外调查VLA高效微调策略,先前工作没探索的新贡献,跨越7个多样操作任务,从物体捡放到清理桌子。我们发现微调OpenVLA策略清楚超出微调预训练策略如Octo。比从零模仿学习用diffusion policies,微调OpenVLA在涉及语言到行为grounding的多任务设置中显示实质改善。跟随这些结果,我们是第一个展示计算高效微调方法用低秩适应和模型量化来促进适应OpenVLA模型在消费级GPU而不是大服务器节点,而不牺牲性能。作为最终贡献,我们开源所有模型、部署和微调笔记本,和OpenVLA代码库用于大规模训练VLA,希望这些资源启用未来工作探索和适应VLA用于机器人。
解释:
引言部分首先指出现有机器人学习策略(AI模型)的核心缺陷,即泛化能力弱:它们虽能处理训练过的单一技能或语言指令,并在物体位置或灯光等小变化上推断,但面对场景干扰、新物体或未见指令时表现不稳(不robust)。然后,作者对比了机器人领域外的视觉和语言基础模型(如CLIP、SigLIP、Llama 2),这些模型通过互联网规模预训练数据捕捉先验知识,实现强大泛化;尽管机器人数据规模小(仅10万-100万例子),但这暗示机会——用这些预训练模型作为基础,构建能超出训练数据的机器人策略。接着,引言回顾现有工作:从整合预训练模型用于表示学习或任务规划,到最近的VLA(视觉-语言-动作模型),如直接微调PaLI生成动作,RT-2等展示出robust和泛化优势,设定新标准。但现有VLA有两大障碍:封闭性(架构、训练、数据不透明)和缺乏高效适应指南(尤其在消费级GPU上)。作者认为,机器人需要开源通用VLA,像开源语言模型生态那样支持微调。为此,他们介绍OpenVLA:一个70亿参数开源VLA,基于预训练视觉-语言骨干,在970k Open-X数据集上微调,跨越多机器人、任务、场景;它比550亿参数RT-2-X成功率高16.5%,并首次探索高效微调(如LoRA和量化),在多任务语言grounding上超Octo和Diffusion Policy 20.4%;最终开源一切,促进未来研究。
2 相关工作(Related Work)
视觉条件语言模型(Visually-Conditioned Language Models) 视觉条件语言模型(VLM),这些模型在互联网规模数据上训练,能从输入图像和语言提示生成自然语言,已被用于各种应用,如视觉问答[28–31]和物体定位[32, 33]。最近VLM的关键进步在于模型架构:它们把预训练视觉编码器[8, 9, 25]的特征与预训练语言模型[10, 23, 34–36]桥接起来,直接利用计算机视觉和自然语言建模的最新进展,打造出强大的多模态模型。早期工作探索了各种跨注意力架构来连接视觉和语言特征[37–41],但新的开源VLM[20, 42–44]基本都收敛到更简单的“patch-as-token”方法:把预训练视觉Transformer的patch特征当做token,然后投影到语言模型的输入空间。这种简单性让它很容易用大规模语言模型训练工具来训VLM。我们在这工作中就用了这些工具来规模化VLA训练,特别用了Karamcheti et al. [44]的Prismatic-7B VLM作为预训练骨干,因为它用多分辨率视觉特征训练,融合了DINOv2[25]的低级空间信息和SigLIP[9]的高级语义,帮助视觉泛化。
通用机器人策略(Generalist Robot Policies) 最近机器人领域的一个趋势是,在大规模多样机器人数据集[1, 2, 6, 11, 45–56]上训练多任务“通用”机器人策略[2, 6, 45–49],覆盖很多不同机器人实施[1, 5, 53, 57–66]。特别值得一提的是Octo[5],它训练了一个通用策略,能开箱即用地控制多种机器人,并支持灵活微调到新机器人设置。OpenVLA和这些方法的主要区别在于模型架构。之前像Octo这样的工作通常把预训练组件(如语言嵌入或视觉编码器)跟从零初始化的额外组件组合起来,在策略训练过程中“缝合”它们。而OpenVLA采用更端到端的做法:直接把VLM微调成生成机器人动作,把动作当做语言模型词汇里的token。我们实验评估显示,这种简单但可规模化的pipeline,比之前通用策略在性能和泛化能力上大幅提升。
视觉-语言-动作模型(Vision-Language-Action Models) 很多工作探索了用VLM做机器人,比如用作视觉状态表示[12, 13]、物体检测[67]、高级规划[16],或提供反馈信号[68–71]。还有一些把VLM直接整合到端到端视觉运动策略[14, 15],但往往需要额外结构或标定相机,限制了适用性。最近一些工作用了类似我们的配方,直接把大型预训练VLM微调成预测机器人动作[1, 7, 17, 18, 72–74]。这类模型通常叫视觉-语言-动作模型(VLA),因为它们把机器人控制动作直接融合进VLM骨干。这有三大好处:(1) 在大规模互联网视觉-语言数据集上对齐预训练视觉和语言组件;(2) 用通用架构(不是机器人定制的),能利用现代VLM训练的可扩展基础设施[75–77],用很少代码改动就训出亿参数策略;(3) 给机器人提供直接路径受益于VLM的快速进步。现有VLA要么专注在单一机器人或模拟环境训练评估[72–74, 78],泛化差;要么封闭,不支持高效微调到新机器人设置[1, 7, 17, 18]。最相关的RT-2-X[1]在Open X-Embodiment数据集上训了一个55B参数VLA,展示了通用操作策略的state-of-the-art性能。但我们的工作在多个关键方面不同:(1) 结合强开源VLM骨干和更丰富机器人预训练数据集,OpenVLA在实验中超出RT-2-X,但参数少一个数量级;(2) 我们深入调查OpenVLA微调到新目标设置,而RT-2-X没研究微调场景;(3) 我们是第一个展示现代参数高效微调和量化方法对VLA的有效性;(4) OpenVLA是第一个通用开源VLA,支持未来研究VLA训练、数据混合、目标、推理。
解释:
讲别人做了啥。视觉语言模型(VLM)是基础,能看图懂话。通用机器人策略是多任务AI。VLA是结合的。作者说他们是第一个开源通用的VLA。
3. OpenVLA模型细节(The OpenVLA Model)
我们介绍OpenVLA模型,一个70亿参数的视觉-语言-动作模型(VLA),在Open X-Embodiment数据集的970k机器人演示上训练。开发VLA模型的最佳实践还有很多未探索的问题,比如用什么模型骨干、数据集、超参数最好。下面,我们详细说明我们开发OpenVLA的方法,并总结关键经验。具体来说,我们先简要概述现代视觉语言模型(VLM),它们是OpenVLA的骨干(3.1节);然后描述基本训练配方和数据集(3.2和3.3节);讨论关键设计决定(3.4节);最后提供训练和推理用到的基础设施细节(3.5节)。
3.1 预备知识:视觉语言模型(Preliminaries: Vision-Language Models)
大多数最近的VLM架构包括三个主要部分(见图2):(1) 视觉编码器,把图像输入映射成很多“图像补丁嵌入”(image patch embeddings);(2) 投影器,把视觉编码器的输出嵌入映射到语言模型的输入空间;(3) 大语言模型(LLM)骨干。在VLM训练时,用下一个文本token预测目标,在各种互联网来源的配对或交织视觉-语言数据上端到端训练。
在这工作中,我们基于Prismatic-7B VLM [44]。Prismatic遵循标准架构:600M参数视觉编码器(融合预训练SigLIP [9] 和 DinoV2 [25] 模型)、小2层MLP投影器、7B参数Llama 2语言模型骨干 [10]。输入图像补丁分别通过SigLIP和DinoV2编码器,输出特征向量通道级拼接(concatenate)。相比常用CLIP或纯SigLIP编码器,加DinoV2特征已被证明有助于提升空间推理 [44],对机器人控制特别有用。
SigLIP、DinoV2和Llama 2不公开训练数据细节(很可能万亿token互联网图像-文本、纯图像、纯文本数据)。Prismatic VLM在这些组件上用LLaVA 1.5数据混合微调 [43],包含约100万图像-文本和纯文本样本来自开源数据集 [29, 42, 81–83]。
3.2 OpenVLA训练程序(OpenVLA Training Procedure)
我们通过微调预训练Prismatic-7B VLM来让它预测机器人动作(见图2)。把动作预测当成“视觉-语言”任务:输入图像观察+自然语言指令,输出机器人动作字符串。为了让VLM的语言模型骨干预测动作,我们把连续机器人动作离散化成离散token。每个动作维度独立离散成256个bin,用训练数据1st到99th分位数均匀划分(忽略outlier,避免扩展bin宽度降低粒度)。这样得到N维动作的N个整数∈[0...255]。
Llama分词器只有100个特殊token可用于新引入token,256个不够。我们简单覆盖Llama词汇中最不常用的256个token(最后256个)来放动作token。一旦动作处理成token序列,就用标准下一个token预测目标训练,只算动作token的交叉熵损失。我们在3.4节讨论关键实现决定。接下来描述训练用的机器人数据集。
3.3 训练数据(Training Data)
构建OpenVLA训练数据集的目标是捕捉大量机器人实施、场景、任务的多样性。这样最终模型才能开箱控制多种机器人,并容易微调到新设置。我们用Open X-Embodiment数据集(OpenX)[1]作为基础来curate训练数据。写论文时,完整OpenX有超过70个独立机器人数据集、200多万轨迹,由社区大努力整合成统一易用格式。
为了让训练实用,我们对原始数据做了多步清洗:(1) 确保所有训练数据输入输出空间一致;(2) 最终混合里实施、任务、场景平衡。为了(1),我们只选有至少一个第三人称相机的操作数据集,并用单臂末端执行器控制(follow [1,5])。为了(2),我们用Octo [5]的混合权重,对通过第一轮过滤的数据集启发式降权/移除低多样性数据集,提升高多样性数据集。我们也试加了Octo发布后新加的DROID数据集 [11],但权重保守10%。实践中DROID动作token准确率一直低,说明需要更大权重或更大模型来fit它的多样性。为了不影响最终质量,我们在训练最后1/3去掉了DROID。完整数据集列表和混合权重见附录A。
3.4 OpenVLA设计决定(OpenVLA Design Decisions)
开发OpenVLA时,我们在小规模实验(用BridgeData V2 [6]评估)里探索了很多决定,以加速迭代、降低成本。关键经验总结如下:
- VLM骨干:试了多个,包括Prismatic [44]、IDEFICS-1 [84]、LLaVA [85]。LLaVA和IDEFICS-1在单物体任务差不多,但LLaVA在多物体语言grounding上强35%(BridgeData V2 sink环境5个任务平均)。Prismatic再提升10%,归功于SigLIP+DinoV2融合的空间推理能力。Prismatic代码也模块化好用,所以最终选它。
- 图像分辨率:比了224×224和384×384,没性能差,但后者训3倍时间。所以最终用224×224。注意很多VLM基准高分辨率有用,但VLA这里还没看到。
- 微调视觉编码器:VLM通常冻结视觉编码器保留互联网预训特征,但我们发现VLA必须全微调视觉编码器才好。猜想预训视觉骨干对机器人关键细粒度空间细节的捕捉不充分。
- 训练轮数:LLM/VLM通常1-2epoch,但VLA要多迭代,直到动作token准确率>95%。最终跑了27epoch。
- 学习率:扫了很多量级,最好是固定2e-5(和VLM预训一样),学习率warmup没有带来好处。
3.5 训练和推理基础设施(Infrastructure for Training and Inference)
最终模型在64个A100 GPU上训14天(总21,500 A100小时),batch size 2048。用混合精度、FlashAttention、FSDP。推理:bfloat16下15GB显存,RTX 4090上约6Hz(没编译、speculative decoding等加速)。量化后内存更小,性能不掉(见5.4节)。各种消费/服务器GPU推理速度见图6。我们实现了远程VLA推理服务器,实时流式输出动作到机器人(不用本地强算力)。这个远程方案开源在代码库里(第4节)。
解释:
这节是论文的“核心技术解剖”,详细告诉你OpenVLA到底是怎么造出来的、用什么零件、怎么训的,像拆解一台机器一样。作者说OpenVLA不是从零建,而是拿一个现成的强视觉语言模型Prismatic-7B(基于Llama 2 7B + 融合SigLIP懂意思+DinoV2懂空间的视觉编码器)当底子,直接微调它来预测机器人动作。关键创新:把连续动作离散成256个“特殊词”(token),覆盖掉Llama词汇里最没用的256个,让大模型像生成文字一样生成动作序列,然后解码成真实机器人控制信号(7维相对动作)。训练数据精选970k高质量机器人视频,确保多样性(多机器人、多任务、多场景)。设计上特别强调:必须全微调视觉部分(不能冻结)、用224分辨率、训很多轮(27epoch)、低学习率稳定。训练花了64张A100两周,推理在游戏卡4090上也能6次/秒跑。整体解释:这节在证明OpenVLA“简单但牛”——继承了互联网级VLM的强大视觉语言理解,再加机器人数据微调,就成了通用机器人“大脑”,参数小(7B)但泛化强、易微调、开源友好。“OpenVLA就是把ChatGPT改造成机器人教练:看图、懂话、直接吐动作指令!”这部分奠定了模型的技术基础,后面的实验就是拿这个模型去测牛不牛。
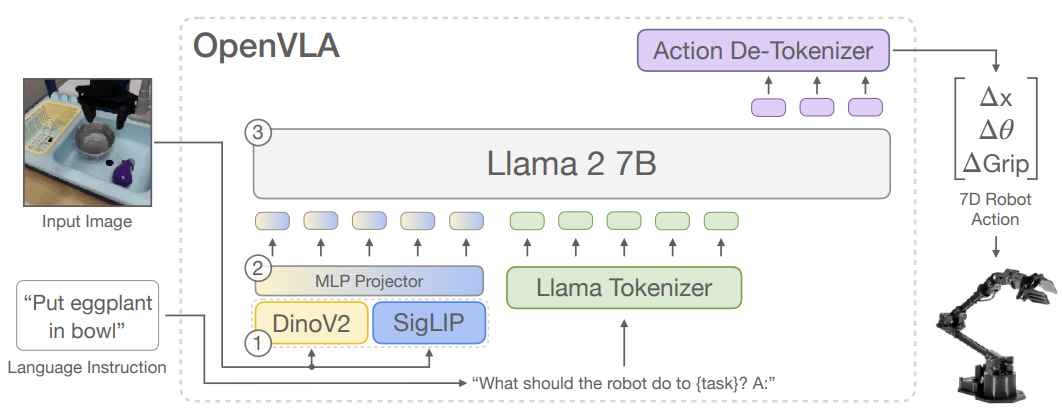
图2:OpenVLA架构。输入图像+语言指令 → 融合视觉编码器(DinoV2 + SigLIP) → 投影器 → Llama 2 7B → 输出离散化动作token → 解码成连续7维动作(Δx, Δy, Δz, Δroll, Δpitch, Δyaw, Δgrip)。
4. OpenVLA代码库(The OpenVLA Codebase)
作者说:除了模型本身,我们还发布了OpenVLA代码库,一个模块化的PyTorch代码库,用于训练VLA模型(详见https://openvla.github.io)。它能从小规模单张GPU微调VLA扩展到多节点GPU集群训亿参数VLA,支持现代大transformer训练技术,如自动混合精度(AMP, PyTorch)、FlashAttention、完全分片数据并行(FSDP)。开箱即用支持在Open X数据集上训练,整合HuggingFace的AutoModel类,支持LoRA微调和量化模型推理。
解释:
代码库(GitHub: openvla/openvla)是模块化PyTorch写的,超级灵活:从小家用GPU(消费级)微调模型,到大集群训超大VLA都行;内置了省内存/加速神器(AMP混合精度、FlashAttention快注意力、FSDP分布式训练);直接支持Open X-Embodiment数据集训练;完美对接HuggingFace(AutoModel轻松加载/保存模型);特别强调LoRA参数高效微调(只改很少参数,1.4%就能接近全微调效果)和量化推理(int4压缩,内存减半,跑得快,不掉性能)。
5. 实验(Experiments)
我们实验评估目标是测试OpenVLA作为强大多机器人控制策略的能力,开箱即用,以及好初始化用于微调到新机器人任务。具体,我们旨在回答以下问题:
- OpenVLA比先前通用机器人策略如何,当评估在多个机器人和各种泛化类型?
- OpenVLA能有效微调到新机器人设置和任务,如何比state-of-the-art数据高效模仿学习方法?
- 我们能用参数高效微调和量化减少训练和推理计算需求,让它们更accessible?性能-计算trade-off是什么?
5.1 多机器人平台直接评估(Direct Evaluations on Multiple Robot Platforms) 机器人设置和任务:
我们测OpenVLA“开箱”性能在两个机器人上:BridgeData V2的WidowX机器人(见图1左)和RT-1/RT-2的移动操作机器人(“Google机器人”,见图1中)。这两个平台之前被广泛用来评通用机器人策略。我们定义全面评估任务,覆盖各种泛化轴:视觉(未见背景、干扰物、颜色/外观);运动(未见物体位置/朝向);物理(未见物体大小/形状);语义(未见目标物体、指令、互联网概念)。还测语言条件能力:在多物体场景,看策略能不能按用户prompt操作正确物体。BridgeData V2和Google机器人任务示例见图3和图4底部行。总体:BridgeData V2每个方法170次rollout(17任务×10次);Google机器人60次(12任务×5次)。所有任务和训练数据区别详见附录B。本节及后续评估都用A/B公平比较(相同任务、相同初始状态)。
比较:我们比三个之前通用操作策略:RT-1-X [1]、RT-2-X [1]、Octo [5]。RT-1-X(35M参数)和Octo(93M参数)是从OpenX子集从零训的transformer;Octo是开源SOTA。RT-2-X(55B参数)是封闭SOTA VLA,用互联网预训视觉语言骨干。结果总结在图3(BridgeData V2)和图4(Google机器人),每任务分解见附录表4和表6。我们发现RT-1-X和Octo在测试任务挣扎,常抓错物体(尤其有干扰时),有时机器人乱挥臂。注意我们的评估泛化难度更大,来挑战互联网预训VLA,所以没预训的模型低性能正常。RT-2-X明显超RT-1-X和Octo,证明大预训VLM对机器人好处。
值得注意:OpenVLA在Google机器人评估和RT-2-X相当,在BridgeData V2大幅超RT-2-X,尽管参数少一个数量级(7B vs 55B)。定性看,RT-2-X和OpenVLA都比其他模型robust得多:有干扰时靠近正确物体、正确对齐末端执行器方向、甚至从抓不稳恢复(见https://openvla.github.io 定性视频)。RT-2-X在语义泛化上更高(图3),预期因为它用更大互联网预训+机器人数据co-fine-tune,保留预训知识更好,而OpenVLA只在机器人数据上微调。但OpenVLA在BridgeData V2和Google机器人其他所有类别相当或更好。性能差来自:我们curate了更大训练集970k轨迹(vs RT-2-X 350k);更仔细清洗数据(如过滤Bridge零动作,见附录C);用融合视觉编码器结合语义+空间特征。ablation见附录D。
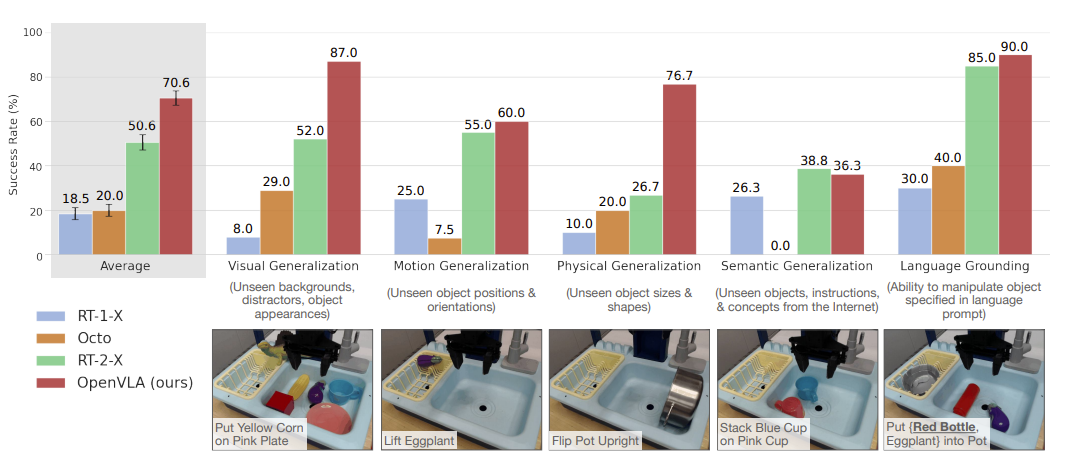
图3:OpenVLA在BridgeData V2数据集上的WidowX机器人(一个常见的桌面机械臂)评估表现
注:Average(整体平均成功率)、Visual Generalization(视觉泛化:未见背景、干扰物、物体外观)Motion Generalization(运动泛化:未见物体位置/朝向)、Physical Generalization(物理泛化:未见物体大小/形状)、Semantic Generalization(语义泛化:未见物体、指令、互联网概念)、Language Grounding(语言grounding:能根据语言提示操作指定物体,比如“把红瓶和茄子放进锅里”)
图3中OpenVLA参数只有RT-2-X的1/7,却在BridgeData V2 WidowX的29个任务上整体成功率高16.5%,尤其在视觉/物理/语言理解上完胜封闭大模型,证明“开源+聪明设计+数据多样性”能打败参数碾压!”
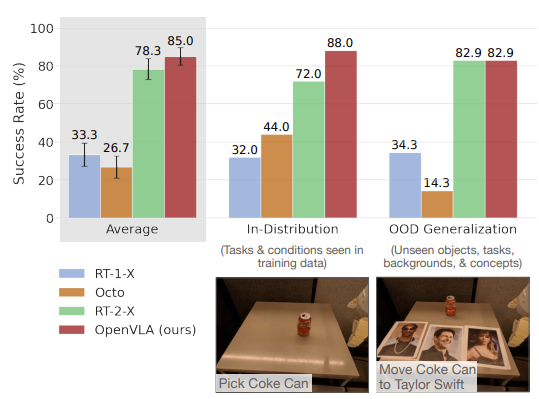
图4:Google机器人(移动机械臂平台,和RT-1/RT-2系列用的一样)上的“开箱即用”(zero-shot)评估,比较OpenVLA和之前通用机器人策略的表现
图4中OpenVLA在Google移动机器人上和RT-2-X势均力敌甚至略胜(平均85% vs 78.3%),参数却少7倍,尤其在分布内任务和基本OOD上全面领先,只在纯“互联网概念”泛化(如认Taylor Swift)上稍落后;整体和Figure 3一起,秀出OpenVLA小巧却强悍的通用性!“Google机器人上,红色OpenVLA柱子又一次霸榜,85%平均成功率,基本和谷歌55B大佬打平手,还更省参数!”
5.2 数据高效适应新机器人设置(Data-Efficient Adaptation to New Robot Setups)
之前工作主要测VLA开箱 [1,7,16],VLA有效微调到新任务/新设置基本没探索,但这是广泛采用的关键。我们这里测OpenVLA快速适应新真实世界机器人设置能力。(模拟微调见附录E)
机器人设置和任务:我们用简单微调配方:全参数微调,用10–150个目标任务演示(见图5;参数高效微调见5.3)。测试两个设置:Franka-Tabletop(固定桌装Franka Emika Panda 7-DoF臂,5Hz非阻塞控制器);Franka-DROID(DROID数据集 [11] 的Franka臂,装在移动站立桌上,15Hz)。选Franka因为社区常用,是OpenVLA微调常见目标。不同控制频率测适用性。
比较:比Diffusion Policy [3](SOTA数据高效模仿,从零训);Diffusion Policy (matched)(匹配OpenVLA输入输出规格);Octo [5]微调(开源SOTA支持微调,RT-2-X API不支持微调);OpenVLA微调;ablation:OpenVLA (scratch)(直接微调底层Prismatic VLM,而非OpenX预训OpenVLA,测大规模机器人预训好处)。结果见图5,每任务分解见附录表7。
我们发现Diffusion Policy两个版本在窄单指令任务(如“Put Carrot in Bowl”“Pour Corn into Pot”)竞争或超通用策略,但预训通用策略在多样微调任务(多物体+语言条件)更好。OpenX预训让Octo和OpenVLA更好适应这些语言grounding重要的任务(OpenVLA scratch性能低证明这点)。总体OpenVLA平均性能最高。大多数之前方法只在窄单指令或多样多指令上强,成功率波动大。只有OpenVLA所有任务≥50%成功率,是模仿学习任务强默认选项,尤其多语言指令时。对于窄但高灵巧任务,Diffusion Policy轨迹更平滑精确;未来加action chunking+时序平滑可能帮OpenVLA达到同级灵巧(见第6节局限讨论)。
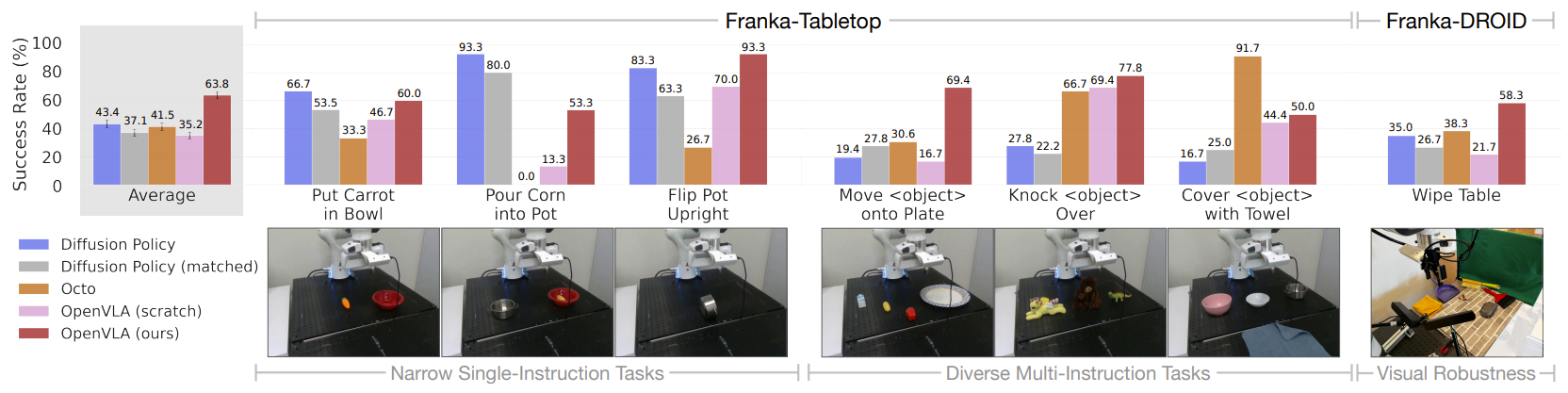
图5:展示OpenVLA“快速适应新机器人设置”能力的核心实验图,对比了不同策略在全新Franka Emika Panda机械臂(7-DoF)上的微调表现
5.3 参数高效微调(Parameter-Efficient Fine-Tuning)
上一节全微调OpenVLA用8张A100 5-15小时/任务(依数据大小)。虽比VLA预训省算力,但这里探索更省算力和参数的微调方法,测效果。
表1:参数高效微调评估。LoRA最佳性能-算力权衡,匹配全微调性能,只训1.4%参数。平均成功率±StdErr基于选Franka-Tabletop任务33次rollout(详见表8)。*:FSDP分片2张GPU。
| 策略 | 成功率 | 训练参数 (×10^6) | VRAM (batch 16) |
|---|---|---|---|
| Full FT | 69.7 ± 7.2 % | 7,188.1 | 163.3 GB* |
| Last layer only | 30.3 ± 6.1 % | 465.1 | 51.4 GB |
| Frozen vision | 47.0 ± 6.9 % | 6,760.4 | 156.2 GB* |
| Sandwich | 62.1 ± 7.9 % | 914.2 | 64.0 GB |
| LoRA, rank=32 | 68.2 ± 7.5% | 97.6 | 59.7 GB |
| rank=64 | 68.2 ± 7.8% | 195.2 | 60.5 GB |
我们对比了以下微调方法:全参数微调(full fine-tuning)(更新所有权重);只微调最后层(last layer only)(只微调transformer最后层+token embedding);冻结视觉编码器(frozen vision)(冻结视觉编码器微调其他);sandwich微调(解冻视觉+token embedding+最后层);LoRA(Hu et al. [26]低秩适应,全线性层,尝试多种rank r)。Franka-Tabletop任务成功率+训练参数+显存见表1。我们发现只微调最后层或冻结视觉性能差,说明视觉特征需进一步适应目标场景。Sandwich性能更好(微调视觉编码器)+省显存(不微调全LLM)。LoRA最佳权衡,超sandwich,匹配全微调,只微调1.4%参数。rank对性能影响小,推荐默认r=32。用LoRA,单张A100 10-15小时微调新任务,比全微调省8倍算力。
5.4 量化内存高效推理(Memory-Efficient Inference via Quantization)
OpenVLA是一个70亿参数模型,推理时显存消耗比之前开源通用策略如Octo(<100M参数)多。我们遵循LLM serving的最佳实践:用bfloat16精度保存和加载OpenVLA进行推理(我们的默认方式),这就把内存占用砍一半,只需16GB GPU就能跑(比如RTX 4090等)。在本节,我们测试是否能进一步降低策略推理所需的内存、扩大VLA策略的可访问性,通过使用为LLM serving开发的现代量化技术[27,88]。这些方法把网络权重加载成更低精度,从而用减少内存需求来换取可能的推理速度和精度损失。
具体来说,我们在8个代表性BridgeData V2任务上测试用8-bit和4-bit精度serving OpenVLA模型。我们在表2中报告内存占用和rollout性能。我们也在图6中报告各种消费级和服务器级GPU上能达到的控制频率。我们观察到:8-bit量化在多数GPU上会减慢推理,因为额外量化操作的开销。4-bit推理反而达到更高吞吐量,因为减少的GPU内存传输抵消了量化开销。
由于推理速度降低,我们看到8-bit量化导致性能大幅下降:在我们评估用的A5000 GPU上,模型只能跑到1.2Hz,这和BridgeData V2任务采集时用的5Hz非阻塞控制器相比,系统动态变化很大(影响真实机器人表现)。值得注意,4-bit量化在性能上和bfloat16半精度推理相当,尽管GPU内存占用不到一半。4-bit量化模型在A5000上能跑到3Hz,更接近数据采集时的系统动态。
表2:量化推理性能。4-bit量化匹配bfloat16性能,显存减半多。平均成功率±StdErr基于8个代表BridgeData V2任务80次rollout(详见表5)。
| 精度 | Bridge成功率 | VRAM |
|---|---|---|
| bfloat16 | 71.3 ± 4.8% | 16.8 GB |
| int8 | 58.1 ± 5.1% | 10.2 GB |
| int4 | 71.9 ± 4.7% | 7.0 GB |
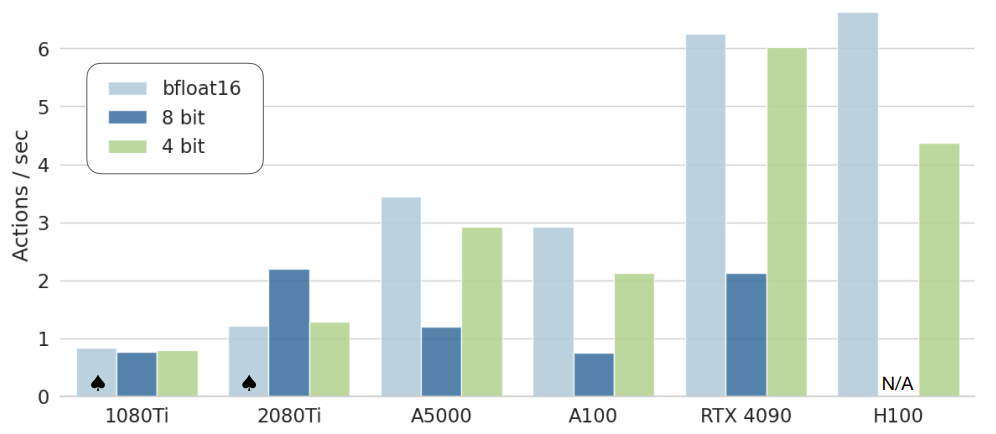
图6:各种GPU推理速度。bfloat16和int4量化吞吐高,尤其Ada Lovelace架构(RTX 4090、H100)。现代LLM推理框架如TensorRT-LLM [89]还能再加速。♠:模型分片2张GPU装下。
6. 讨论和局限(Discussion and Limitations)
在这工作,我们呈现OpenVLA,一个state-of-the-art开源视觉-语言-动作模型,获得跨实施机器人控制强性能开箱。我们也展示OpenVLA能容易适应新机器人设置通过参数高效微调技术。
当前OpenVLA模型有几个局限。首先,它当前只支持单图像观察。现实,真实世界机器人设置异质,有广泛可能感官输入。扩展OpenVLA支持多图像和本体输入以及观察历史是重要未来工作大道。探索用交织图像和文本数据预训练VLM可能促进这样灵活输入VLA微调。
其次,改善OpenVLA推理throughput关键启用VLA控制高频控制设置如ALOHA,跑50Hz。这也将启用测试VLA在更dexterous(灵巧)双臂操作任务比我们调查的。探索动作chunking或备选推理时间优化技术如speculative decoding提供潜在补救。
另外,有进一步性能改善空间。虽然OpenVLA超出先前通用策略,它没提供很高可靠性在测试任务,常<90%成功率。
最后,由于计算限制,许多VLA设计问题仍未探索:基VLM大小对VLA性能有何影响?co-training在机器人动作预测数据和互联网规模视觉-语言数据显著改善VLA性能?什么视觉特征最适合VLA模型?我们希望发布OpenVLA模型和代码库启用社区共同调查这些问题。
解释:
结尾说,OpenVLA牛,但还有问题:只看单图,不懂历史;跑不快,高频控制难;成功率不高;设计问题多。希望大家用开源代码继续研究。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)