RoboMIND 2.0:面向通用化具身智能的大规模双臂移动操作数据集
近期北京人形机器人和北京大学团队发布RoboMIND 2.0:一款面向通用化具身智能的大规模双臂移动操作数据集,通过整合 6 种异构机器人平台的 310K 轨迹数据、多模态感知信息(含触觉)、高保真数字孪生资产及标准化标注体系,填补了现有数据集在双臂协调、移动操作、跨形态泛化等维度的空白。
近期北京人形机器人和北京大学团队发布RoboMIND 2.0:一款面向通用化具身智能的大规模双臂移动操作数据集,通过整合 6 种异构机器人平台的 310K 轨迹数据、多模态感知信息(含触觉)、高保真数字孪生资产及标准化标注体系,填补了现有数据集在双臂协调、移动操作、跨形态泛化等维度的空白。配套提出的MIND-2 快慢双系统框架(高层 VLM 规划 + 低层 VLA 执行),基于离线强化学习融合成功与失败轨迹训练,在长时域复杂任务、多机器人协作场景中显著超越传统模仿学习与现有 VLA 模型,为机器人通用化操作能力的提升提供了数据支撑与算法范式。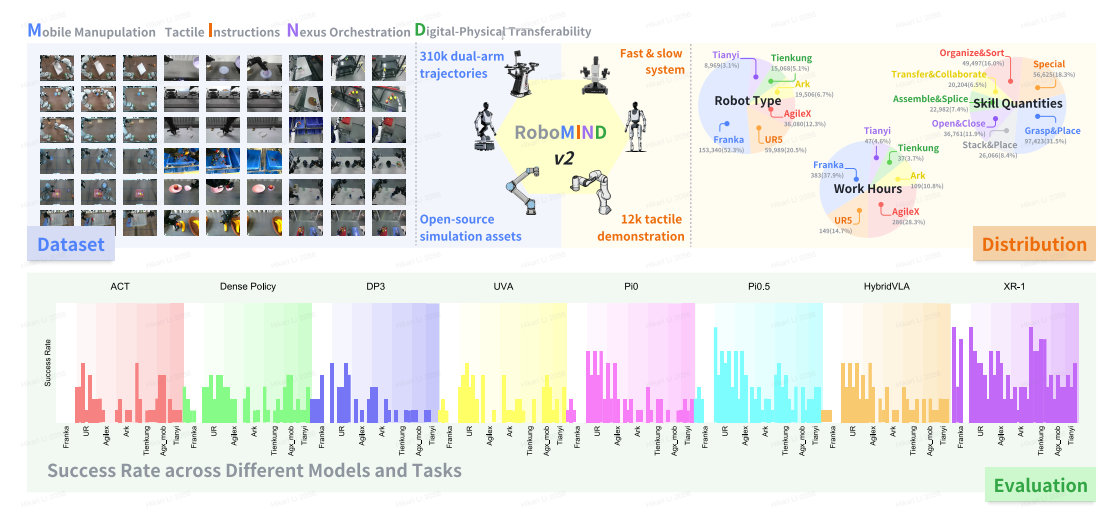
机器人操作领域的瓶颈和痛点
在机器人操作领域,数据驱动的模仿学习已成为突破传统控制局限的核心路径,但现有数据集与算法体系仍面临多重瓶颈,严重制约了机器人在真实场景中的通用化部署:
1. 数据集维度单一,缺乏综合多样性
现有数据集多聚焦单一维度的多样性(如仅覆盖单一机器人形态、单一任务类型或单一环境),难以支撑跨场景、跨硬件的泛化学习。例如,多数主流数据集以单臂固定基座操作数据为主,缺乏双臂协同、移动操作的大规模样本;部分数据集虽引入双臂数据,但局限于单一机器人平台,无法满足跨形态政策迁移的需求。
2. 感知模态残缺,精细操作能力不足
几乎所有现有数据集仅依赖视觉观测与基础驱动状态,缺失触觉、力扭矩等关键物理交互反馈。而在真实世界中,接触检测、防滑动、精细装配等任务高度依赖触觉感知,模态残缺导致模型难以应对接触密集型场景,限制了机器人的操作灵巧性。
3. 长时域任务数据稀缺,复杂场景适配困难
现有数据集中的任务多为短时域单一操作(如简单拾取放置),缺乏长时域、多步骤的移动操作数据(如跨房间物品运输+装配)。这导致模型在需要连续决策、环境动态变化的复杂场景中表现不佳,难以实现类人级的复杂任务执行能力。
4. 虚实迁移成本高,数据扩充效率低
尽管模拟数据集具备低成本、可重复的优势,但现有模拟资产与真实场景的几何、物理一致性不足,导致“虚实鸿沟”显著,模拟数据难以有效辅助真实机器人训练。同时,真实数据采集依赖昂贵硬件与人工监督,数据规模扩充面临效率与成本瓶颈。
5. 双臂协同数据缺失,贴近真实需求不足
真实世界中,人类超过 70% 的复杂操作依赖双臂协同(如装配、物品交接、协作搬运),但现有数据集多以单臂操作为主,双臂协调相关的大规模、高质量数据极度稀缺,导致机器人在这类核心场景中缺乏学习样本。
RoboMIND 2.0 数据集核心设计与优势
RoboMIND 2.0 针对上述痛点,构建了一套多维度、多模态、虚实融合的大规模双臂移动操作数据集。
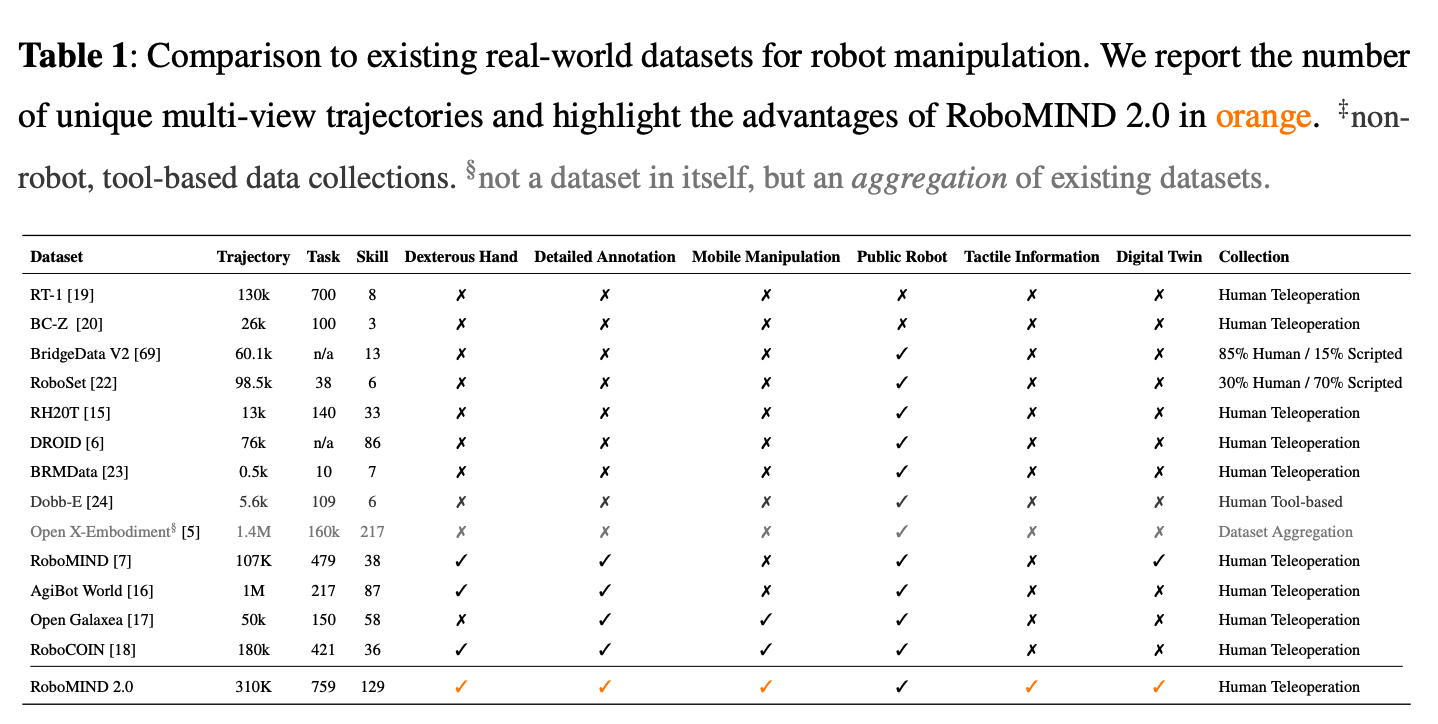
其核心设计围绕“多样性、标准化、实用性”三大原则展开,具体特点如下:
1. 规模与覆盖范围:全方位覆盖复杂场景与任务
- 数据体量:包含 310K 条双臂操作轨迹,累计操作时长超 1000 小时,覆盖 759 个复杂任务、129 项核心机器人技能(如抓取放置、装配拼接、开关操作、协作搬运等)。
- 机器人形态:涵盖 6 种异构机器人平台,包括固定基座双臂机器人(Franka、UR5e)、轮式移动双臂机器人(AgileX、ARX、Tian Yi)、人形双臂机器人(Tien Kung),覆盖对称/非对称臂结构、固定/移动基座、普通夹爪/灵巧手等多种形态。
- 任务与场景:任务类型分为固定场景操作(桌面级精细操作)与移动场景操作(跨空间连续任务),场景涵盖家庭环境(厨房、卧室、客厅、儿童房)、工业环境(物流分拣、装配线、生物实验室)、商业场景(超市),其中工业与家庭场景数据占比均衡。
- 操作对象:涉及 1139 种不同物体,分为食品、日用品、厨具、文具、玩具等 6 大类,包含不同形状、材质、尺寸的物体,支持物体级泛化能力训练。
2. 数据采集:标准化流程保障数据质量
数据集通过统一的遥操作协议与采集流程构建,针对不同机器人形态设计了专属采集方案,确保数据的一致性与可靠性:
(1)分平台采集方案
- Franka 与 UR5e:采用 HACTS 遥操作系统,该系统由低成本硬件(Dynamixel 舵机、3D 打印框架等,总成本低于 300 美元)与软件组成,支持主从臂运动映射,操作员通过控制两个独立从臂完成双臂协同任务,数据同步包含多视角 RGB-D 信息与本体感受状态。
- AgileX 与 ARX:AgileX 采用类 Mobile ALOHA 的双边遥操作设备,通过辅助机械臂控制主臂,同时记录操作员推动机器人基座产生的线性与角速度数据;ARX 采用 VR 头显捕捉人体手臂运动,映射至机器人双臂,移动基座通过 VR 控制器控制,同步记录运动轨迹与环境信息。
- Tien Kung 与人形 Tian Yi:Tien Kung 采用运动捕捉服记录人体关节运动,映射至人形机器人完成操作;Tian Yi 由两名操作员协同控制,一人通过 HTACTS 设备控制双臂操作,另一人推动基座记录移动数据,实现移动与操作的协同采集。
(2)多模态数据同步采集
- 核心模态包括:多视角 RGB-D 视觉数据(前视、腕部、头部等不同视角)、机器人本体感受数据(关节位置、速度、力矩)、触觉数据(通过 Tashan 触觉传感器采集法向力、切向力及力的方向)、力扭矩数据,其中触觉数据覆盖 12K 条轨迹,支持接触密集型任务研究。
- 数据存储格式统一为 HDF5 文件,整合单条轨迹的所有模态信息,便于后续模型训练与数据管理。
3. 质量控制:多阶段流程过滤异常数据
由于遥操作过程中存在操作员疲劳、分心等问题,数据集设计了三阶段质量控制流程,过滤 12 类数据异常,确保数据可信度:
(1)质量控制标准(12 类异常类型)
- 无意识接触:机械臂与非目标物体意外接触,干扰轨迹记录;
- 运动不流畅:因操作员犹豫导致的动作中断、重复微调或突变;
- 重复抓取:首次抓取失败后多次尝试,影响时间一致性;
- 抓取前碰撞:抓取前与目标物体或障碍物碰撞,破坏场景状态;
- 数据异常:传感器故障导致的帧丢失、画面冻结等;
- 放置失败:物体未稳定放置在目标位置(掉落、倾斜、偏移);
- 轨迹异常:轨迹偏离合理路径(多余绕行、过度修正);
- 速度过快:动作速度远超人类遥操作正常范围,影响物理真实性;
- 视觉伪影:相机失真(闪烁、色偏、固定视角);
- 机械臂异常:机械臂抖动、振荡等不稳定行为;
- 非标准操作:未按协议返回初始姿态或暂停时间不符合要求;
- 目标位移:意外移动本应静止的物体。
(2)三阶段质控流程
- 初步检查:每日采集结束后,自动整理原始日志与视频,随机抽样检测帧丢失、画面冻结等重大技术问题;
- 详细检查:由专职质控人员逐帧或慢放审查视频,标注上述 12 类异常的时间戳与描述;
- 数据过滤与重采:剔除严重异常轨迹,对部分缺失或低质量数据进行重新采集,最终确保所有发布轨迹符合质量标准。
4. 数据标注:语义化拆解支撑长时域任务学习
为支持语言引导的政策学习与长时域任务分解,数据集采用“自动生成+人工修正”的标注方案,为每条轨迹提供精细的自然语言注释:
- 标注流程:首先利用大语言模型 Gemini 2.5 Pro 对长时域任务进行语义分割,以“导航-操作”转换为边界,将连续任务拆分为子任务单元(如“前往冰箱→拿起购物篮→等待另一机器人放置物品→前往收银台”);然后由人工对自动标注结果进行修正,确保子任务划分的合理性与语言描述的准确性。
- 标注内容:每个子任务包含动作描述、对应的图像帧、动作类型标签(自我操作、他人协作、移动),形成“视觉-语言-动作”的多模态对齐标注,支持 VLA 模型的结构化训练。
5. 虚实融合:高保真数字孪生降低迁移成本
数据集不仅提供真实世界数据,还配套发布高保真模拟资产与模拟轨迹,实现虚实数据的无缝融合:
- 模拟资产构建:所有真实场景中的物体、环境均构建数字孪生模型,遵循“装配-模块-网格”三级结构,统一坐标系,添加精确的关节动力学参数、碰撞模型与材质纹理,采用 RTX 物理渲染(PBR)确保视觉真实性,通过光学运动捕捉验证物理精度(误差≤0.1mm)。
- 模拟数据集:在 Isaac Sim 中采集 20K 条模拟轨迹,涵盖 Franka 与 Tien Kung 两种代表性机器人平台,模拟任务与真实任务在结构、物体配置、语言指令上完全一致,支持虚实混合训练。
6. 多样性分析:多维度支撑泛化能力训练
RoboMIND 2.0 的核心优势在于其多维度的多样性设计,涵盖五大核心维度,远超现有数据集的单一维度覆盖:
(1)形态多样性
- 运动学结构:包含对称双臂(Franka 平行部署)、非对称双臂(UR5e 人形部署)、人形上半身结构(Tien Kung);
- 移动能力:覆盖固定基座(Franka、UR5e)与移动基座(AgileX、ARX、Tian Yi),支持静态操作与移动操作的联合训练;
- 感知布局:采用多种传感器(RealSense D435i、Orbbec Gemini 335 等),涵盖不同视角(环境安装、头部、腕部)与参数,支持视角不变性感知学习;
- 遥操作模态:包含主从控制(HACTS)、VR 控制、物理引导三种方式,捕捉不同人类控制策略的差异。
(2)任务多样性
- 技能:7 大类核心技能,其中抓取放置(97K+ 样本)、特殊动作操作(56K+ 样本)、整理分类(49K+ 样本)占比最高,同时包含装配拼接、协作搬运等复杂技能;
- 时域长度:涵盖短时域精细操作(如单次抓取)与长时域连续任务(如多步骤装配+跨空间运输);
- 协作类型:包含单机器人双臂协同与多机器人异构协作(如 AgileX 与 Tian Yi 协同完成超市购物任务)。
(3)物体多样性
- 覆盖 6 大类 1139 种物体,包含不同视觉特征(颜色、形状)、物理属性(材质、重量、刚度)的物体;
- 同一物体在不同场景、不同任务中重复出现,支持上下文依赖的操作策略学习。
(4)信息多样性
- 首次在大规模数据集中整合触觉反馈,与视觉、本体感受、力扭矩数据同步,支持多模态融合的政策学习;
- 触觉数据包含法向力、切向力及力的方向,采样频率与动作数据保持一致,可直接用于模型输入。
(5)模拟多样性
- 模拟数据与真实数据在任务结构、物体配置上完全对齐,支持“真实+模拟”混合训练,降低数据采集成本;
- 模拟环境可灵活调整参数(如物体位置、环境光照),支持数据增强与鲁棒性训练。
MIND-2 双系统框架:适配长时域双臂移动操作
为充分发挥 RoboMIND 2.0 数据集的价值,针对长时域复杂任务中“高层规划”与“低层执行”的协同需求,提出 MIND-2 快慢双系统框架,实现从自然语言指令到机器人动作的端到端映射。
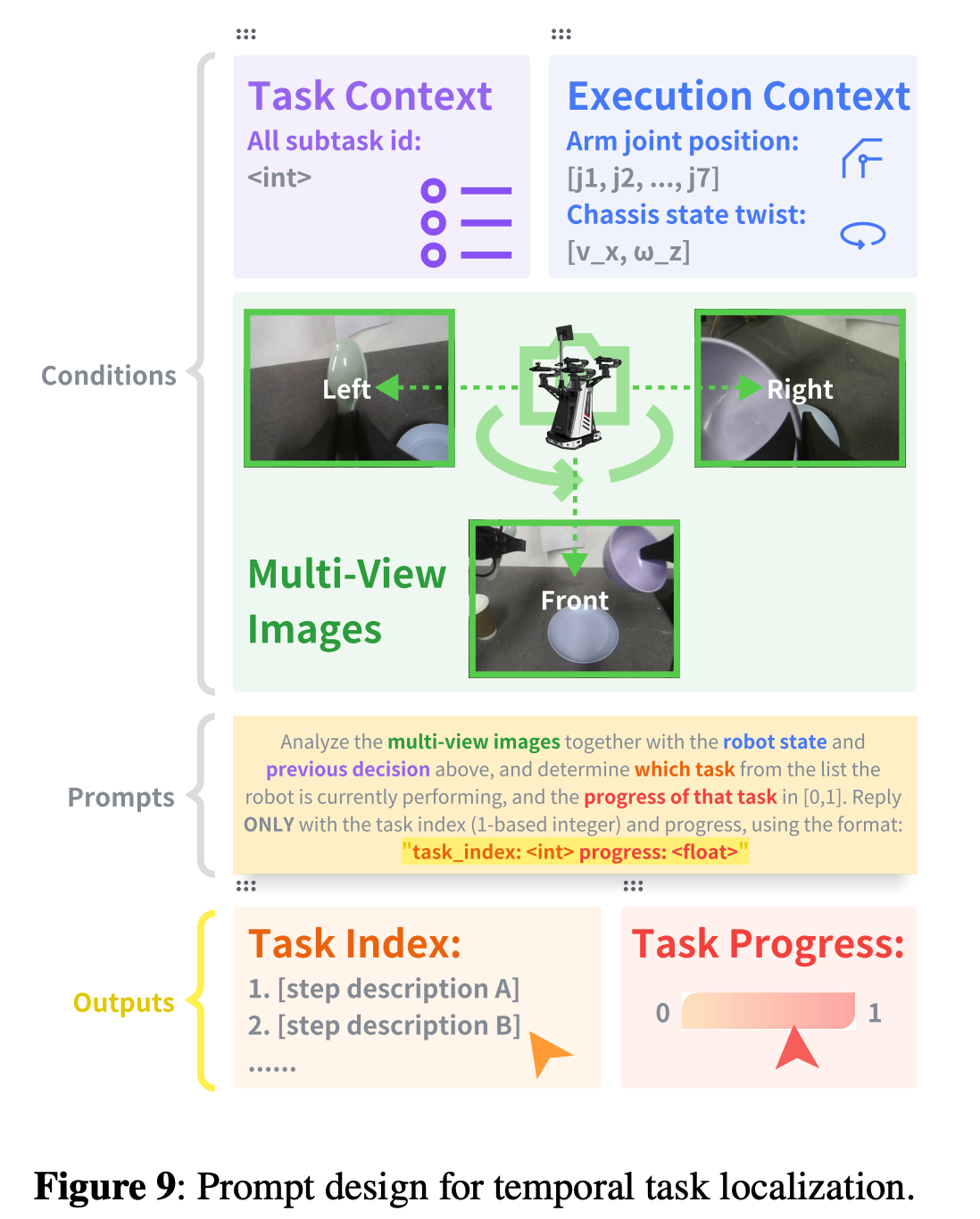
1. 框架整体设计理念
MIND-2 的核心设计思路是“分层协作”:高层系统(慢系统)负责语义级任务规划与进度监控,低层系统(快系统)负责感知-动作映射与精准执行,两者通过子任务指令实现协同,适配长时域、动态环境下的复杂操作需求。
2. 高层规划系统(MIND-2-VLM):机器人的“大脑”
MIND-2-VLM 基于开源 VLM 模型 InternVL3-8B 微调,功能是将抽象的自然语言指令拆解为可执行的子目标,并实时跟踪任务进度,为低层执行系统提供明确的操作指引。
(1)输入与输出设计
- 输入内容:
- 多视角视觉上下文:前视、左腕、右腕三个视角的同步 RGB-D 图像;
- 任务上下文:长时域任务的所有子任务列表(如“1. 拿起购物篮;2. 接收物品;3. 前往收银台”);
- 执行上下文:机器人实时状态(关节位置、底盘速度)、上一帧的子任务索引(初始帧为“None”)。
- 输出格式:标准化文本输出,包含子任务索引与执行进度(0-1 之间的数值),例如“task index: 2; progress: 0.6”,确保低层系统可直接解析。
(2)训练方式
- 训练数据来自 RoboMIND 2.0 的标注数据集,每个训练样本为“输入prompt-输出文本”的单轮对话对;
- 采用端到端微调,损失函数为交叉熵损失,目标是让模型学习从多模态输入到子任务索引与进度的映射关系。
3.低层执行系统(MIND-2-VLA):机器人的“小脑”
MIND-2-VLA 是一款视觉-语言-动作(VLA)模型,负责将高层系统输出的子任务指令转换为精准的机器人控制动作,支持不同机器人形态的适配。
(1)训练范式:离线强化学习(IQL)
- 核心创新:同时利用数据集中的成功轨迹与失败轨迹,通过 IQL 算法学习最优动作策略,同时规避错误操作模式;
- 奖励设计:
- 成功轨迹:终端步骤奖励为 +1,前面步骤的奖励按 γ=0.999 指数衰减(r_t = γ^(T-t)),形成正向回报;
- 失败轨迹:终端步骤奖励为 -1,前面步骤的奖励按 γ=0.999 反向衰减(r_t = -γ^(T-t)),强化对错误动作的规避。
(2)损失函数设计
- 价值函数损失(L_V):通过非对称分位数损失学习状态价值函数 V(s),拟合数据集中行为政策的期望回报;
- Q 函数损失(L_Q):采用时序差分(TD)学习更新 Q 函数,目标值由即时奖励与下一状态价值函数计算得出;
- 政策损失(L_π):通过优势加权回归更新政策,聚焦于在每个状态下表现优于平均水平的动作,提升政策的鲁棒性。
(3)多模态融合
输入融合视觉信息(多视角 RGB-D)、语言指令(子任务描述)、本体感受(关节状态、底盘速度)与触觉数据(力的大小与方向),通过统一的特征编码器实现多模态信息的对齐与融合,提升复杂场景下的动作决策精度。
4. 双系统协同机制
- 高层系统(MIND-2-VLM)每帧接收机器人状态与环境视觉信息,输出当前应执行的子任务与进度;
- 低层系统(MIND-2-VLA)根据子任务指令、多模态感知输入,生成机器人底盘移动指令与双臂操作指令;
- 当低层系统完成当前子任务(进度达到 1.0),高层系统自动触发下一个子任务,实现长时域任务的连续执行;
- 支持多机器人协作:MIND-2-VLM 可同时监控多个异构机器人的状态,为每个机器人分配专属子任务,实现协同操作。
关键实验结果与分析
为验证 RoboMIND 2.0 数据集的有效性与 MIND-2 框架的性能,开展了多维度实验,涵盖模仿学习与 VLA 模型对比、触觉与虚实数据价值、MIND-2 系统性能、泛化能力验证等核心场景,实验结果如下。
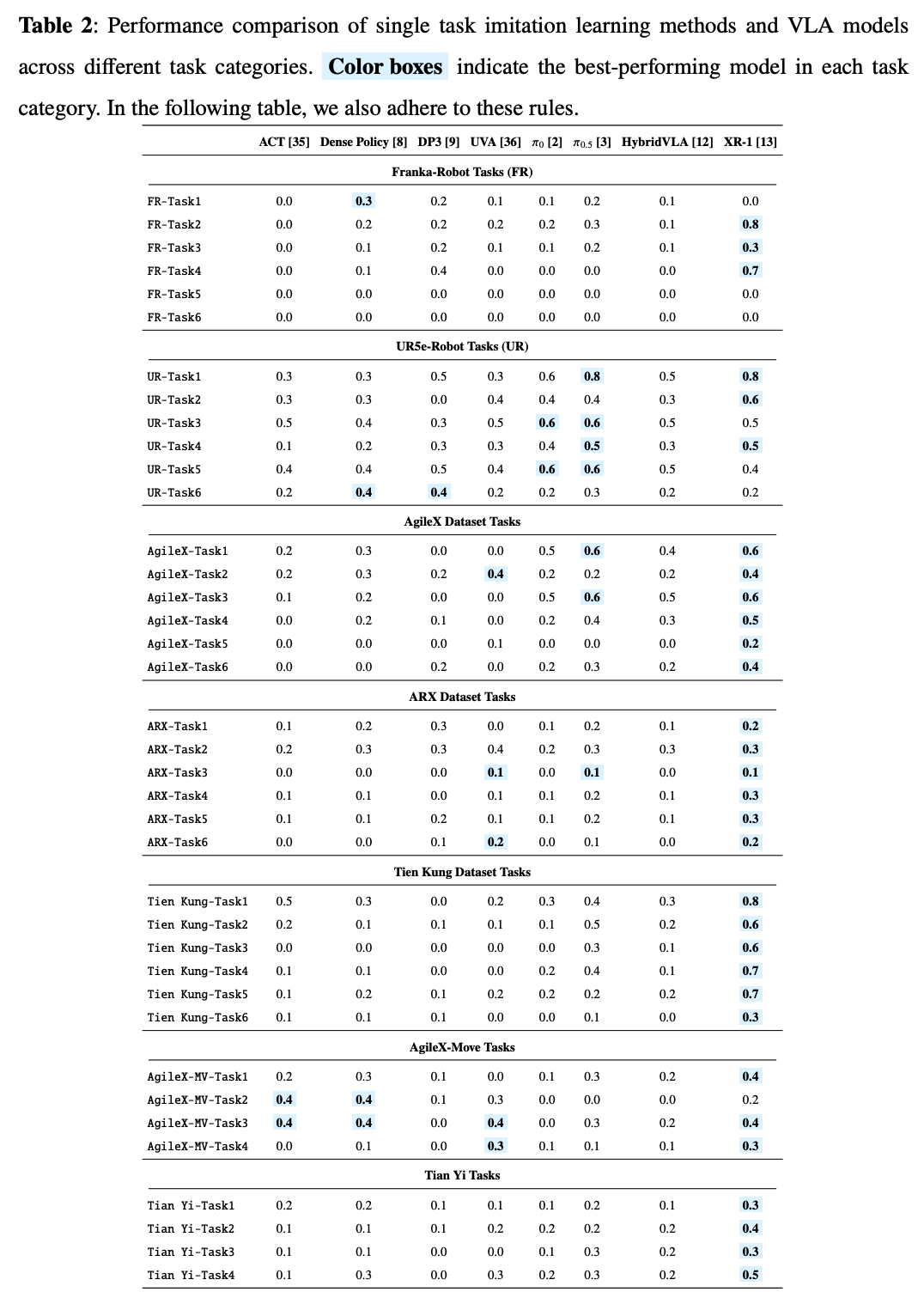
1. 模仿学习算法对比:3D 感知优于 2D 方法
实验选取 4 种代表性模仿学习算法(2D 方法:ACT、UVA;3D 方法:DP3、Dense Policy),在固定场景双臂协调任务中进行评估:
- 核心发现:3D 感知类算法(DP3、Dense Policy)的成功率显著高于 2D 方法,尤其在需要双臂空间协同的任务(如物品交接、装配)中优势明显;
- 原因分析:3D 方法能够更好地建模双臂与环境、物体的空间关系,捕捉双臂协同的动态特征,而 2D 方法因缺乏深度信息,难以准确表征复杂空间交互;
- 具体表现:DP3 在 Franka 与 UR5e 的固定场景任务中成功率可达 0.5-0.8,而 2D 方法 ACT 的成功率多在 0.1-0.4 之间;Dense Policy 表现更为均衡,在移动平台任务中仍保持 0.2-0.5 的成功率,展现更强的跨形态适配性。
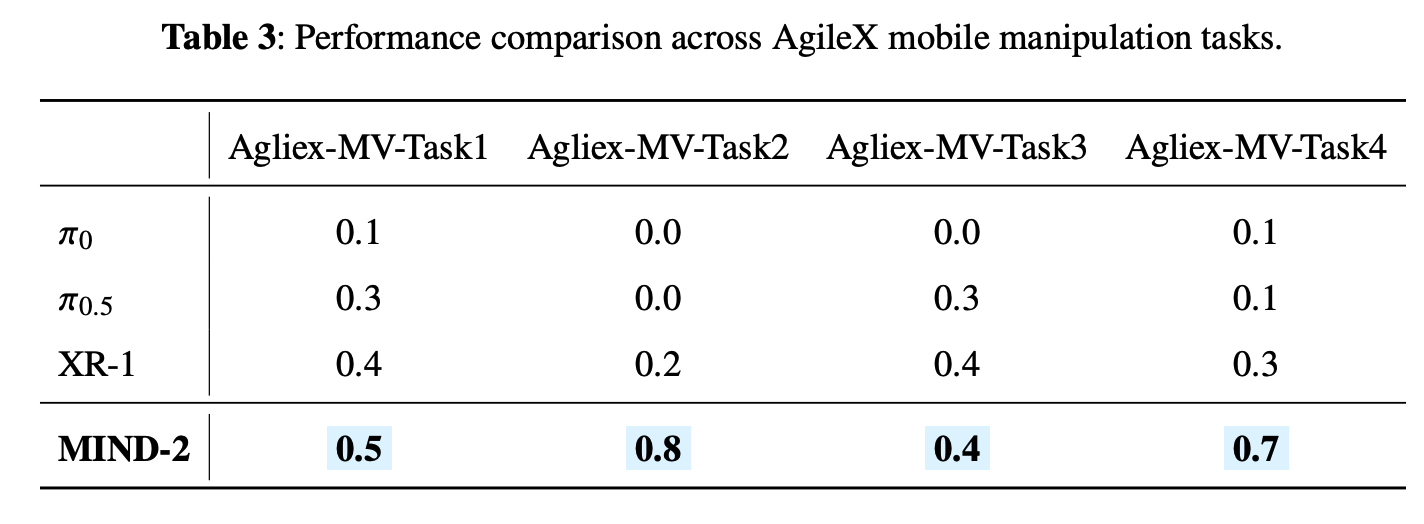
2. VLA 模型对比:跨形态模型泛化性最优
实验选取 4 种主流 VLA 模型(π₀、π₀.₅、HybridVLA、XR-1),在 6 种机器人平台的任务中进行评估:
- 模型表现排序:XR-1 > π₀.₅ > HybridVLA ≈ π₀;
- 关键结论:
- XR-1 作为跨形态 VLA 模型,在固定基座、移动平台、人形机器人上均保持高成功率(0.3-0.8),核心优势是其统一的视觉-运动表征与多模态融合能力;
- π₀.₅ 经机器人数据微调后,在固定场景任务中表现优异(成功率 0.6-0.8),但在移动操作与人形机器人任务中性能下降明显,说明其跨形态泛化能力有限;
- π₀ 与 HybridVLA 性能接近,尽管采用不同的动作生成机制(流匹配 vs 扩散+自回归),但在相同训练数据下表现差异不大,证明数据多样性与模态对齐比动作生成架构更关键。
3. 触觉数据的价值:提升精细操作成功率
实验选取 π₀.₅ 与 XR-1 两种模型,对比“有无触觉输入”在移动操作任务中的表现:
- 核心结果:融入触觉反馈后,两种模型的任务成功率均有显著提升,其中 XR-1 的提升更为明显(平均提升 0.2-0.3);
- 场景适配:触觉数据在接触密集型任务(如精细抓取、防滑动放置、装配)中效果最显著,例如在“堆叠易滑物体”任务中,XR-1 加入触觉后的成功率从 0.4 提升至 0.6;
- 作用机制:触觉数据能够帮助模型检测物体接触状态、判断抓取力度是否充足、及时发现物体滑动,从而调整动作策略,提升操作的稳健性。
4. 虚实混合训练:降低成本并提升性能
实验对比“纯真实数据”“纯模拟数据”“混合数据”三种训练方式在真实机器人上的表现:
- 核心结论:混合真实与模拟数据训练的模型性能显著优于纯模拟数据训练,且接近纯真实数据训练的效果,部分任务甚至超越;
- 最优比例:真实数据与模拟数据的比例为 1:5 时,模型性能达到最优(如 XR-1 在 Tien Kung 任务中的成功率从纯真实数据的 0.9 提升至 1.0);
- 价值体现:模拟数据可低成本扩充训练样本量,尤其在危险场景(如化学实验操作)、稀有物体操作等真实数据难以采集的场景中,模拟数据能够有效填补空白,降低数据采集成本。
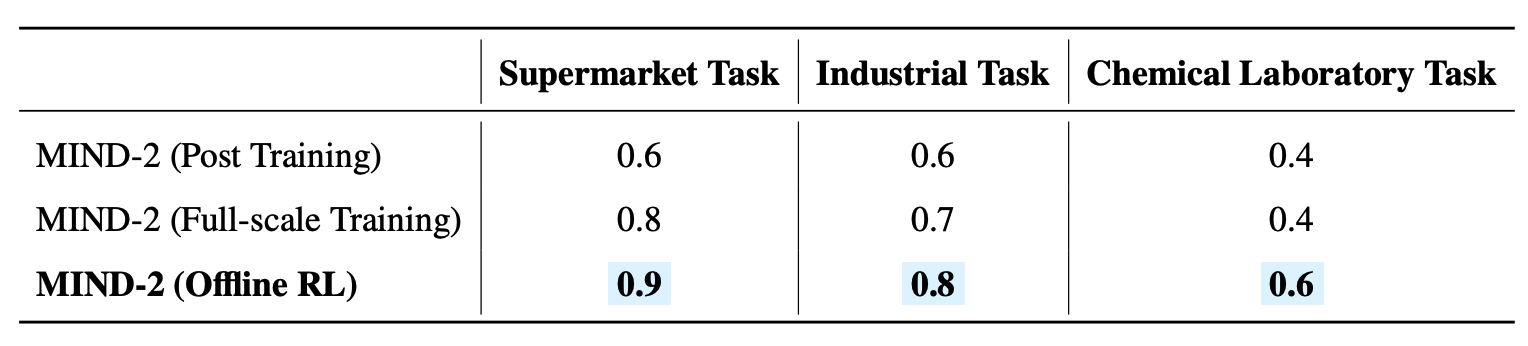
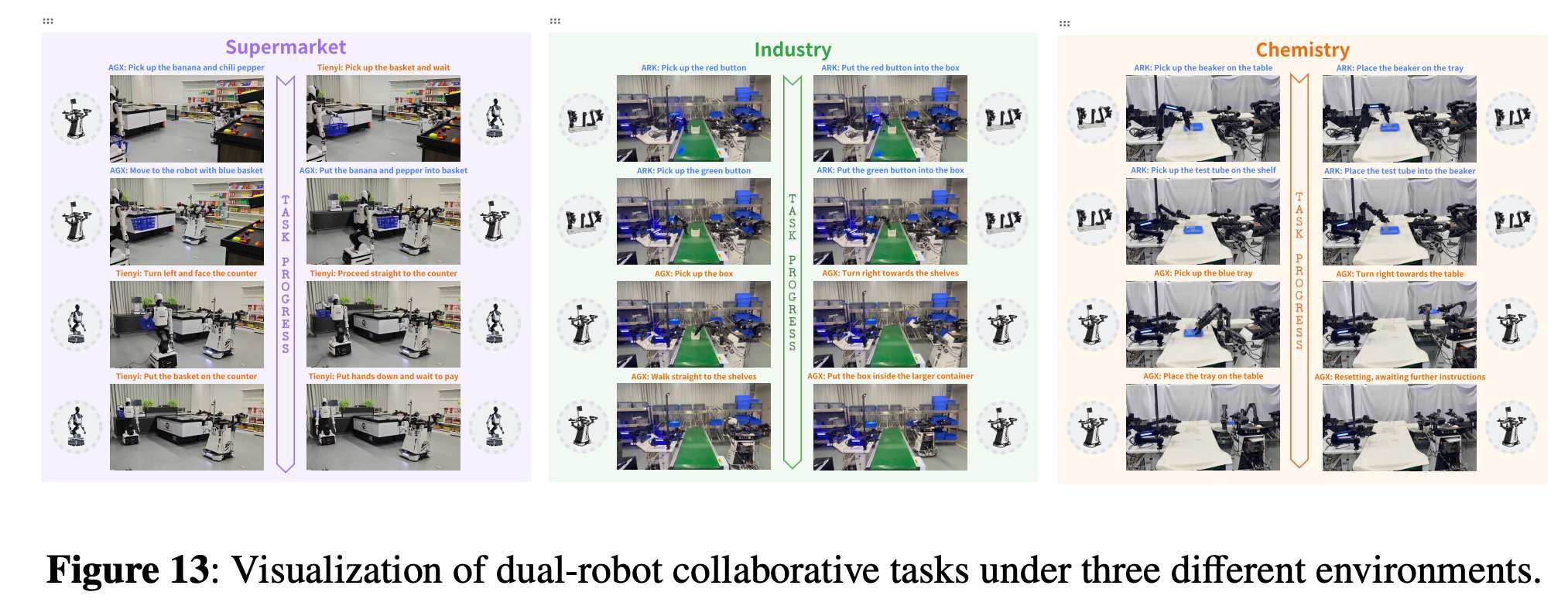
5. MIND-2 系统性能:超越传统方法与现有 VLA 模型
实验在长时域移动操作任务(如餐桌整理、超市结账协助、工业物料分拣)中,对比 MIND-2 与单一模仿学习、现有 VLA 模型的表现:
- 单机器人任务:在 AgileX 移动操作任务中,MIND-2 的成功率(0.4-0.8)显著高于 XR-1(0.2-0.4)、π₀.₅(0.0-0.3),尤其在“擦拭工作台”“试管架放置”等需要连续决策的任务中,MIND-2 的成功率达到 0.8,而现有模型多低于 0.2;
- 多机器人协作任务:设计超市、工业、化学实验室三种协作场景,MIND-2 不同版本的表现如下:
- MIND-2(仅微调):成功率 0.4-0.6,依赖协作任务专属数据微调,泛化能力有限;
- MIND-2(全量预训练):成功率 0.4-0.8,通过 RoboMIND 2.0 全量数据预训练,跨场景适配性提升;
- MIND-2(离线 RL 优化):成功率 0.6-0.9,经 IQL 融合成功与失败轨迹后,鲁棒性显著增强,在超市协作任务中成功率达到 0.9;
- 优势原因:MIND-2 的分层设计解决了长时域任务的“规划-执行”脱节问题,高层 VLM 确保任务分解的合理性,低层 VLA 利用多模态反馈实现精准执行,离线 RL 优化进一步提升了对错误模式的规避能力。
6. 泛化能力验证:物体级泛化表现优异
实验通过“物体替换”方式验证模型的泛化能力:训练时使用原始物体(如蓝色碗、木质块),测试时使用功能等效但视觉/几何/材质不同的物体(如紫色碗、锥形碗、泡沫块、磁性块):
- 核心结果:π₀.₅ 与 XR-1 均展现出较强的物体级泛化能力,在颜色/形状替换任务中成功率保持 0.7-0.8(与原始物体接近),在材质替换任务中成功率为 0.3-0.6;
- 关键发现:训练数据的物体多样性是泛化能力的核心保障,RoboMIND 2.0 包含 1139 种不同物体,覆盖多种视觉与物理属性,使模型能够学习物体的功能特征而非表面特征,从而适配全新物体。
7. 模拟数据集质量验证:高保真支撑虚实迁移
实验在 Tien Kung 模拟环境中训练模型,直接部署到真实机器人上,验证模拟数据的虚实迁移效果:
- 模拟环境性能:在模拟任务中,XR-1 成功率达到 0.62-0.96,ACT 与 Diffusion Policy 成功率为 0.36-0.86,证明模拟数据能够支撑模型学习基本操作技能;
- 虚实迁移效果:仅使用模拟数据训练的 XR-1,在真实机器人任务中的成功率为 0.5-0.7,与纯真实数据训练的模型(0.6-0.9)差距较小,验证了模拟资产的高保真特性;
- 混合训练增益:模拟数据与真实数据混合训练后,模型在真实任务中的成功率进一步提升 0.1-0.2,证明模拟数据能够有效补充真实数据的不足。
具身求职内推来啦
国内最大的具身智能全栈学习社区来啦!
推荐阅读
从零部署π0,π0.5!好用,高性价比!面向具身科研领域打造的轻量级机械臂
工业级真机教程+VLA算法实战(pi0/pi0.5/GR00T/世界模型等)
具身智能算法与落地平台来啦!国内首个面向科研及工业的全栈具身智能机械臂
VLA/VLA+触觉/VLA+RL/具身世界模型等!具身大脑+小脑算法与实战全栈路线来啦~
MuJoCo具身智能实战:从零基础到强化学习与Sim2Real
Diffusion Policy在具身智能领域是怎么应用的?为什么如此重要?
1v1 科研论文辅导来啦!

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 26
26 0
0- 0



 已为社区贡献106条内容
已为社区贡献106条内容

所有评论(0)