王鹤团队最新工作!解决VLA 模型多依赖单视角图像,缺乏精准几何信息的问题
在机器人操作领域,VLA模型通过端到端框架将视觉输入与语言指令映射为动作,实现了多样化技能学习。然而,现有 VLA 模型多依赖单视角 RGB 图像,缺乏精准空间几何信息,难以满足高精度操纵需求。,创新性地融合立体视觉的丰富几何线索,通过 “几何 - 语义特征提取 - 交互区域深度估计 - 多场景验证” 的技术体系,首次系统性解决了 VLA 模型空间感知不足的核心问题,为机器人精准操纵提供了全新解决
在机器人操作领域,VLA模型通过端到端框架将视觉输入与语言指令映射为动作,实现了多样化技能学习。然而,现有 VLA 模型多依赖单视角 RGB 图像,缺乏精准空间几何信息,难以满足高精度操纵需求。由 Galbot、北京大学、香港大学等团队联合提出的 StereoVLA 模型,创新性地融合立体视觉的丰富几何线索,通过 “几何 - 语义特征提取 - 交互区域深度估计 - 多场景验证” 的技术体系,首次系统性解决了 VLA 模型空间感知不足的核心问题,为机器人精准操纵提供了全新解决方案。
论文题目:StereoVLA: Enhancing Vision-Language-Action Models with Stereo Vision
项目链接:https://shengliangd.github.io/StereoVLA-Webpage
问题根源:VLA 模型空间感知的三大核心挑战
StereoVLA 的设计源于对现有 VLA 模型空间感知痛点的深刻洞察,三大核心挑战构成技术突破的起点:
单模态视觉局限
传统 VLA 模型依赖单视角 RGB 图像,存在深度模糊问题,无法精准捕捉物体三维空间关系,导致高精度操纵任务(如抓取细小物体、条形物体)表现不佳。
补充传感器缺陷
现有解决方案中,手腕相机视野有限且易遮挡、增加碰撞风险;深度传感器对透明或镜面物体测量噪声大;多相机配置则增加硬件复杂度,且泛化性受相机姿态影响显著。
几何与语义融合难题
立体视觉虽能提供丰富空间线索,但现有 VLA 模型缺乏有效机制融合几何信息与语义理解,直接输入立体图像会因视角差异细微导致性能次优。
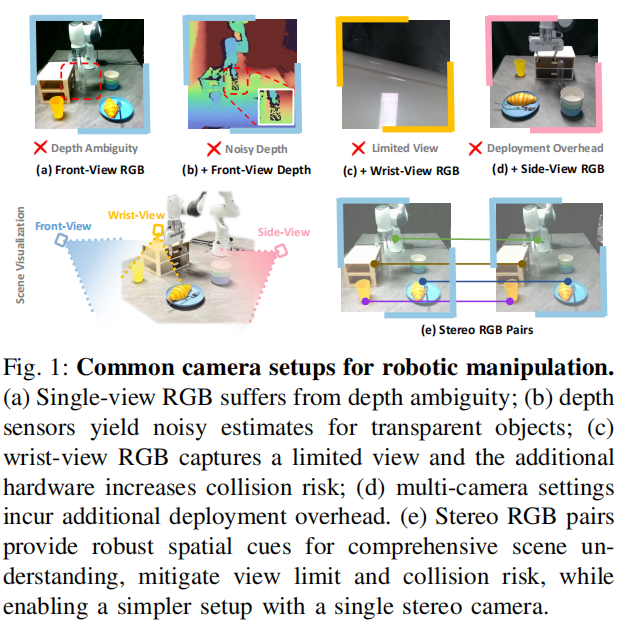
方案设计:StereoVLA 的三层技术架构
针对上述挑战,StereoVLA 构建了 “特征提取 - 辅助训练 - 数据支撑” 的完整技术架构,实现几何感知与语义理解的深度融合:
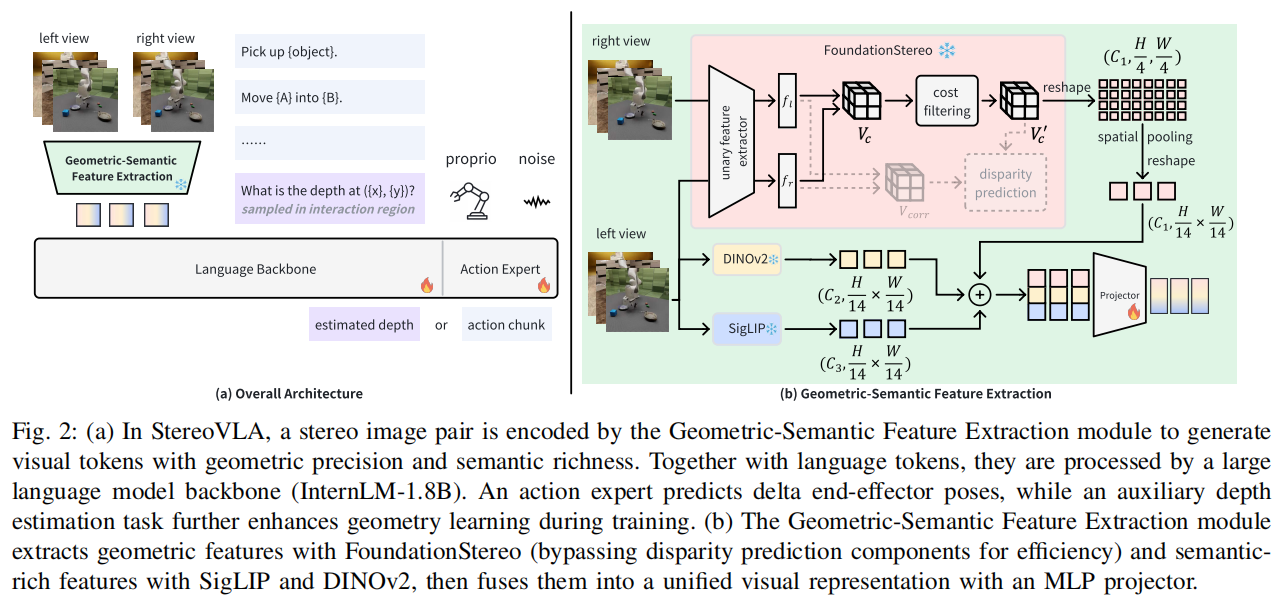
第一层:几何 - 语义特征提取模块 —— 双模态精准融合
创新设计的特征提取模块,高效整合立体视觉的几何线索与单视角的语义信息:
- 几何特征提取:基于 FoundationStereo 预训练模型,提取过滤后的代价体积( V c ′ V_{c}' Vc′)作为几何特征源。该特征通过注意力混合代价过滤模块,捕捉长程空间关联,且无需额外深度估计计算,兼顾精度与效率;
- 语义特征提取:针对立体视觉模型语义信息不足的问题,利用 SigLIP(捕捉高级语义)与 DINOv2(提取视觉细节),仅对左视角图像进行处理(减少视图冗余),获取富含语义的视觉令牌;
- 特征融合策略:通过空间池化统一几何特征与语义特征的分辨率,采用通道维度拼接方式融合特征,避免令牌序列拼接带来的计算开销,生成兼具几何精度与语义丰富度的混合特征表示。
第二层:辅助训练任务 —— 交互区域深度估计
为强化模型细粒度空间感知能力,设计辅助协同训练任务:
- 聚焦交互区域:不同于全图像均匀采样,将采样范围限制在夹持器与目标物体的交互区域(通过物体 2D 边界框定位),引导模型关注关键空间细节;
- metric 深度预测:基于合成数据集的真实深度标签,训练模型预测交互区域内采样点的度量深度,提升操纵精度的同时加速模型收敛,且不增加推理阶段计算负担。
第三层:大规模数据支撑 —— 合成与真实场景数据构建
为解决立体视觉 VLA 数据稀缺问题,构建多维度数据集:
- 合成数据生成:利用 MuJoCo 与 Isaac Sim 生成 500 万条合成抓取 - 放置动作序列,渲染立体图像对,相机内参与姿态在真实 Zed Mini 相机参数的 5% 范围内随机化,模拟真实场景变化;
- 语义增强数据:融入互联网规模接地数据集 GRIT,新增 2D 边界框预测辅助任务,提升模型语义接地能力;
- 数据多样性设计:针对相机姿态鲁棒性验证,生成三种不同随机化范围的数据集(小 / 中 / 大),覆盖 15×10×15cm 至 150×50×60cm 的空间变化。
验证逻辑:从定量指标到场景适配的全面性能验证
StereoVLA 通过 “任务性能 - 相机配置对比 - 模块消融” 的三级验证体系,充分证明其技术有效性:
核心任务性能突破
在真实世界三类关键任务中,StereoVLA 显著优于现有基线模型:
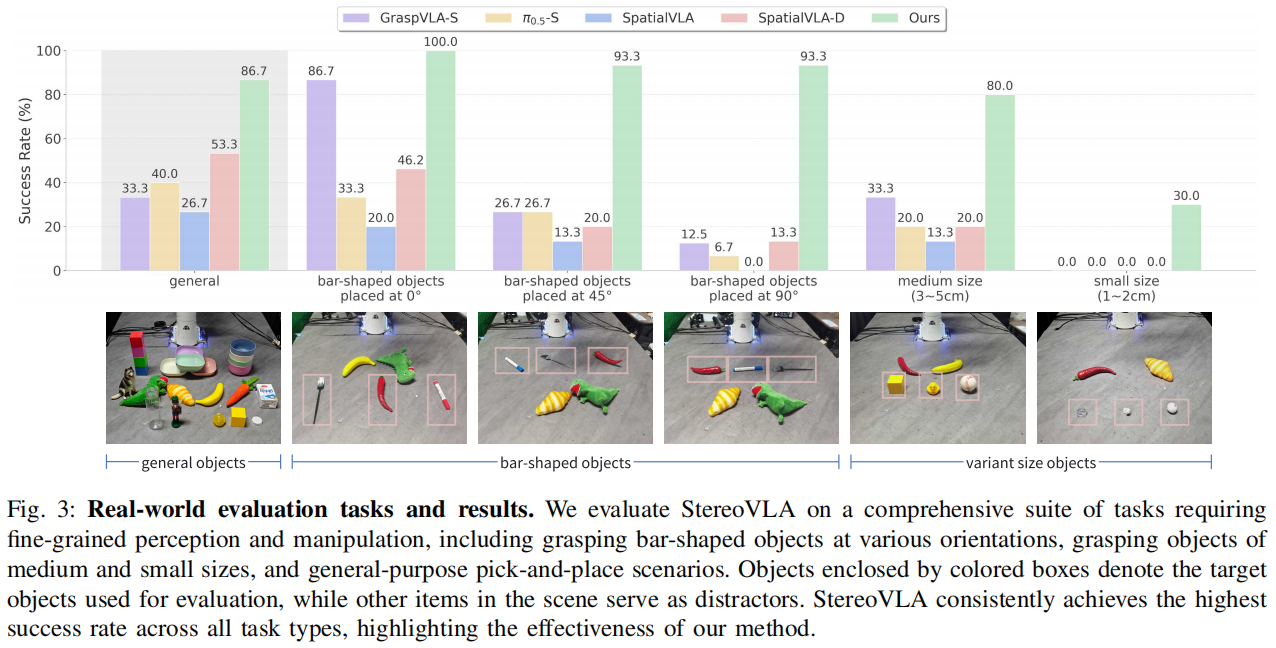
- 通用操纵任务:包括常见物体抓取 / 放置、立方体堆叠等,成功率较基线提升明显(小相机姿态随机化场景);
- 条形物体抓取:针对 0°、45°、90° 三种 orientations 的条形物体(笔、叉子等),实现近完美抓取成功率,解决了长轴视觉重叠导致的定位难题;
- 中小尺寸物体抓取:在 1-2cm 小型物体抓取任务中,以 30.0% 的成功率成为唯一有效模型,其他基线模型完全失败,验证了细粒度空间感知能力。
相机配置鲁棒性对比
在四种主流相机配置的对比中,StereoVLA 展现出最优的性能 - 鲁棒性平衡:
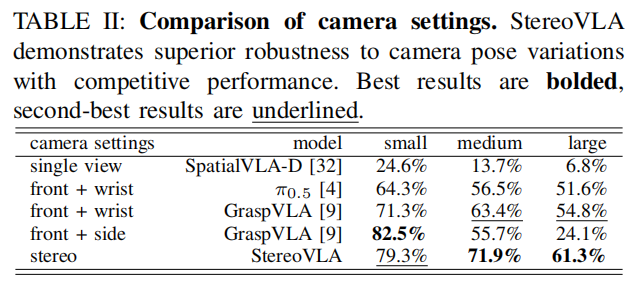
- 立体视觉配置在中、大姿态随机化场景下性能优势显著,较其他配置降低了相机姿态变化对操纵的影响;
- 相比前 + 侧面配置,StereoVLA 在大姿态随机化场景下成功率提升 157%,且部署更简洁,无需多相机校准。
核心模块消融验证
通过系统消融实验,验证各关键设计的必要性:
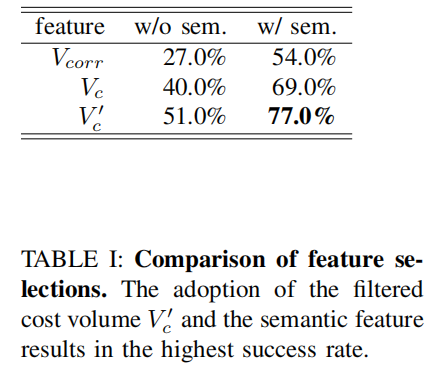
- 几何特征选择:过滤后的代价体积( V c ′ V_{c}' Vc′)表现最优,较相关体积( V c o r r V_{corr} Vcorr)+ 语义特征的组合,成功率从 54.0% 提升至 77.0%,证明长程空间关联捕捉的重要性;
- 语义特征作用:缺失语义特征时,模型抓取错误物体的概率显著增加,成功率平均下降 20% 以上,验证语义 - 几何融合的必要性;
- 深度估计策略:交互区域深度估计较全图像均匀采样,成功率提升 18%,且避免了背景信息对训练的干扰。
局限与未来方向
StereoVLA 作为立体视觉与 VLA 模型融合的突破性工作,仍存在可优化空间:
- 图像分辨率限制:224×224 分辨率对小型物体(1-2cm)的语义接地与定位精度不足,需在高分辨率与计算成本间寻求平衡;
- 长时程依赖缺失:当前模型未捕捉长时程时间依赖,难以应对复杂连续操纵任务;
- 多机器人适配:验证仅基于 Franka 机械臂,未来需扩展至人形机器人等多 embodiment 场景;
- 特征提取优化:可探索更多立体视觉基础模型(如 VGGT)的适配,进一步提升几何特征质量。
StereoVLA 的范式价值与行业影响
StereoVLA 的核心贡献不仅在于首次将立体视觉系统融入 VLA 模型,更在于建立了 “几何 - 语义融合 - 聚焦式辅助训练 - 鲁棒性验证” 的完整技术链路:通过几何 - 语义特征提取模块破解立体视觉与语义理解的融合难题,通过交互区域深度估计强化细粒度空间感知,通过多相机配置对比验证立体视觉的部署优势。其在条形物体、小型物体抓取等高精度任务中的突破,以及对相机姿态变化的强鲁棒性,为机器人操纵从实验室走向真实复杂场景提供了关键技术支撑,加速了通用自主机器人的落地进程。
具身求职内推来啦
国内最大的具身智能全栈学习社区来啦!
推荐阅读
从零部署π0,π0.5!好用,高性价比!面向具身科研领域打造的轻量级机械臂
工业级真机教程+VLA算法实战(pi0/pi0.5/GR00T/世界模型等)
具身智能算法与落地平台来啦!国内首个面向科研及工业的全栈具身智能机械臂
VLA/VLA+触觉/VLA+RL/具身世界模型等!具身大脑+小脑算法与实战全栈路线来啦~
MuJoCo具身智能实战:从零基础到强化学习与Sim2Real
Diffusion Policy在具身智能领域是怎么应用的?为什么如此重要?
1v1 科研论文辅导来啦!

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 30
30 0
0- 0



 已为社区贡献106条内容
已为社区贡献106条内容

所有评论(0)