LangChain Model I/O 全解析:三大模型类型与实战调用指南
LangChain的ModelI/O模块将大语言模型抽象为三种类型:LLMs(非对话模型)适用于单次文本生成任务,输入输出为文本字符串;ChatModels(对话模型)支持多轮对话,使用结构化消息对象维护上下文;EmbeddingModels(嵌入模型)将文本转换为向量表示。该模块统一了不同模型的调用方式,适用于文案创作、客服机器人、语义搜索等多种应用场景。开发者可通过简单API实现模型调用,支持
一、Model I/O 模块核心价值:统一大模型交互入口
LangChain 作为大模型应用开发的一站式框架,其 Model I/O 模块是连接开发者与各类大语言模型的核心桥梁。它通过抽象封装,将不同类型、不同厂商的模型统一为标准化接口,解决了传统开发中 “模型类型各异、调用方式碎片化” 的痛点。
简单来说,Model I/O 的核心作用是:屏蔽模型底层差异,让开发者用一致的逻辑调用各类大模型,无论是文本生成、多轮对话还是文本向量化任务,都能通过统一的 API 实现。本文将聚焦 Model I/O 模块的三大核心模型类型(LLMs、Chat Models、Embedding Models),结合实战代码详解其特点、适用场景与调用方法。
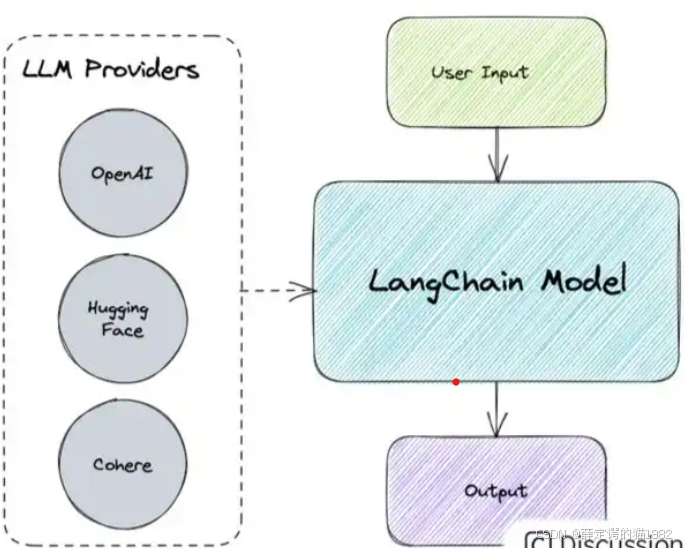
二、三大模型类型:特点、场景与区别
LangChain 将大模型抽象为三类核心类型,各自对应不同的业务场景,其核心差异可通过下表快速区分:
| 模型类型 | 核心功能 | 输入格式 | 输出格式 | 核心特点 | 典型应用场景 |
|---|---|---|---|---|---|
| LLMs(非对话模型) | 文本补全与单次生成 | 纯文本字符串(Prompt) | 纯文本字符串 | 无上下文记忆,单次独立调用 | 文案创作、翻译、代码补全、单次问答 |
| Chat Models(对话模型) | 多轮对话交互 | 结构化消息列表(如 SystemMessage、HumanMessage) | 结构化消息对象(AIMessage) | 支持上下文维护,适配对话场景 | 智能客服、聊天机器人、多轮对话助手 |
| Embedding Models(嵌入模型) | 文本向量化表示 | 文本字符串(单条 / 批量) | 浮点数列表(语义向量) | 捕捉文本语义特征 | 语义搜索、文档聚类、RAG 系统核心组件 |
关键区分点:
- LLMs vs Chat Models:LLMs 是 “单次任务导向”,无上下文记忆;Chat Models 是 “对话导向”,通过结构化消息维护历史交互逻辑。
- Embedding Models:不生成文本,而是将文本转为可计算的向量,是语义理解类任务的基础。
三、实战调用:三大模型类型代码示例
3.1 环境准备
首先安装核心依赖,确保 LangChain 及模型调用相关库已就绪:
# 核心依赖:LangChain 框架
pip install langchain langchain-core langchain-openai langchain-community
# 环境变量管理
pip install python-dotenv
# 第三方模型依赖(如智谱AI)
pip install pyjwt
同时需准备对应模型的 API Key:
- 通义千问:前往阿里云百炼控制台申请;
- 智谱 AI:前往智谱 AI 开放平台申请;
- DeepSeek:前往 DeepSeek 开放平台申请。
创建 .env 文件存储 API Key(避免硬编码):
env
# .env 文件内容
DASHSCOPE_API_KEY=你的通义千问API密钥
DEEPSEEK_API_KEY=你的DeepSeekAPI密钥
ZHIPUAI_API_KEY=你的智谱AIAPI密钥
3.2 LLMs(非对话模型):单次文本生成
LLMs 专为独立的单次文本任务设计,输入输出均为纯文本,适合无需上下文的场景(如文本补全、翻译、代码生成)。
实战代码:调用通义千问 LLM 实现文本补全
from dotenv import load_dotenv
import os
from openai import OpenAI
# 加载环境变量(读取 API Key)
load_dotenv()
# 初始化 LLM 客户端(通义千问兼容 OpenAI 接口)
client = OpenAI(
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key=os.getenv("DASHSCOPE_API_KEY")
)
# 调用模型进行文本补全
completion = client.completions.create(
model="qwen2.5-coder-32b-instruct", # 代码生成类 LLM 模型
prompt="我今天真", # 输入文本(Prompt)
max_tokens=20 # 限制生成文本长度
)
# 输出结果
print("LLM 文本补全结果:", completion.choices[0].text)
关键说明:
completions.create:LLMs 专属调用方法,专注于文本补全;- 无上下文维护:每次调用都是独立的,模型不会记住上一轮输入;
- 适用场景:短文本生成、代码片段补全、单次翻译等简单任务。
3.3 Chat Models(对话模型):多轮交互与上下文维护
Chat Models 是在 LLMs 基础上优化的对话专用模型,通过结构化消息对象(SystemMessage、HumanMessage、AIMessage)实现上下文管理,是构建聊天机器人、智能客服的核心。
示例 1:调用 DeepSeek 对话模型实现单次问答
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from pydantic import SecretStr
load_dotenv()
# 初始化对话模型
llm = ChatOpenAI(
base_url="https://api.deepseek.com/v1", # DeepSeek 接口地址
model="deepseek-chat", # 对话模型名称
api_key=SecretStr(os.environ["DEEPSEEK_API_KEY"]), # 安全传入 API Key
)
# 单次对话调用
response = llm.invoke("大模型是什么?")
# 输出结果(结构化消息对象需通过 content 属性获取文本)
print("对话模型单次问答结果:")
print("完整消息对象:", response)
print("="*50)
print("文本内容:", response.content)
示例 2:调用智谱 AI 对话模型(GLM-4)
pip install pyjwt
智谱AI开放平台 (bigmodel.cn)

from langchain_community.chat_models import ChatZhipuAI
import os
from dotenv import load_dotenv
load_dotenv()
# 初始化智谱 AI 对话模型
zhipu_api_key = os.getenv("ZHIPUAI_API_KEY")
llm = ChatZhipuAI(
model="glm-4-flash", # 智谱普惠模型,支持免费调用
temperature=0.5, # 控制生成随机性(0~1,值越低越精准)
api_key=zhipu_api_key
)
# 调用模型
res = llm.invoke("大模型是什么")
print("智谱 GLM-4 回答:", res.content)
示例 3:多轮对话(维护上下文)
from langchain_core.messages import SystemMessage, HumanMessage
from langchain_openai import ChatOpenAI
import os
from dotenv import load_dotenv
from pydantic import SecretStr
load_dotenv()
# 初始化通义千问对话模型
llm = ChatOpenAI(
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
model="qwen-plus",
api_key=SecretStr(os.environ["DASHSCOPE_API_KEY"]),
)
# 构建多轮对话消息列表(包含系统消息和用户消息)
messages = [
SystemMessage(content="你是一位乐于助人的助手。你叫王老师"), # 系统指令(定义角色)
HumanMessage(content="你是谁?") # 用户问题
]
# 调用模型(传入消息列表,自动维护上下文)
res = llm.invoke(messages)
print("多轮对话结果:", res.content) # 预期输出:我是王老师,一位乐于助人的助手~
关键说明:
- 结构化消息:
SystemMessage用于定义角色 / 规则,HumanMessage是用户输入,AIMessage是模型输出; - 上下文维护:多次调用时,只需将历史消息列表传入
invoke方法,模型会自动理解对话逻辑; - 适用场景:智能客服、聊天机器人、多轮咨询等需要上下文的场景。
3.4 Embedding Models(嵌入模型):文本向量化核心
Embedding Models 负责将文本转为语义向量(浮点数列表),是语义检索、RAG 系统、文档聚类等任务的基础。虽然参考文档未提供完整调用示例,但结合 LangChain 生态,以下是标准实战代码:
from dotenv import load_dotenv
import os
from langchain_community.embeddings import DashScopeEmbeddings
load_dotenv()
# 初始化嵌入模型(通义千问嵌入模型)
embeddings = DashScopeEmbeddings(
model="text-embedding-v1", # 嵌入模型名称
dashscope_api_key=os.getenv("DASHSCOPE_API_KEY")
)
# 单条文本向量化
text = "LangChain Model I/O 模块"
query_vector = embeddings.embed_query(text)
print("单条文本向量(前5个值):", query_vector[:5])
# 批量文本向量化(适合文档处理)
texts = ["模型类型", "对话模型", "嵌入模型"]
doc_vectors = embeddings.embed_documents(texts)
print("批量文本向量数量:", len(doc_vectors))
print("第一条向量(前5个值):", doc_vectors[0][:5])
关键说明:
- 向量维度:不同模型生成的向量维度不同(如 768 维、1536 维),需根据任务选择;
- 核心作用:向量可用于计算文本相似度(如余弦相似度),是 RAG 系统中 “检索相关文档” 的核心逻辑;
- 适用场景:语义搜索、文档聚类、RAG 系统、文本相似度计算等。
四、核心总结与最佳实践
4.1 模型选型指南
- 若需单次文本生成(无上下文):选择 LLMs;
- 若需多轮对话(需维护上下文):选择 Chat Models;
- 若需文本语义理解(向量化):选择 Embedding Models。
4.2 开发最佳实践
- 环境变量管理:使用
python-dotenv存储 API Key,避免硬编码泄露; - 结构化消息设计:Chat Models 中,通过
SystemMessage明确角色和规则,提升回答准确性; - 向量归一化:Embedding Models 生成向量后,建议归一化处理(
normalize_embeddings=True),提升检索精度; - 模型兼容:LangChain 支持主流模型(OpenAI、通义千问、智谱 AI 等),切换模型时只需修改
base_url和model参数,无需重构核心逻辑。
4.3 扩展方向
- 本地模型部署:通过
ChatOllama调用本地部署的 LLaMA、Qwen 等模型,摆脱 API 依赖; - 模型链组合:将 Chat Models 与 Embedding Models 结合,构建完整 RAG 系统(检索 + 生成);
- 输出解析:通过 LangChain 的
OutputParser模块,将模型输出转为结构化数据(如 JSON、列表),方便后续处理。
LangChain 的 Model I/O 模块通过标准化抽象,极大降低了大模型应用开发的门槛。掌握三大模型类型的特点与调用方法,是搭建各类大模型应用(如智能客服、RAG 知识库、文本生成工具)的基础。根据实际业务场景选择合适的模型类型,结合 LangChain 的其他模块(如 Chains、VectorStores),可快速实现复杂的大模型应用落地。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)