YOLO模型核心优化策略:7大技巧让实时目标检测又快又准
YOLO模型的优化没有“万能公式”,关键是根据场景需求找到“速度-精度-资源”的平衡点:实时场景(如自动驾驶):优先用TensorRT加速、INT8量化、320×320分辨率;低功耗设备(如Jetson Nano):选YOLOv11n、模型剪枝或MobileNetV3 backbone;高精度需求(如医疗影像):用640×640分辨率、知识蒸馏,适当牺牲速度。随着YOLO版本的持续迭代和优化技术的
小伙伴们好,我是小嬛。专注于人工智能、计算机视觉领域相关分享研究。【目标检测、图像分类、图像分割、目标跟踪等项目都可做,也可做不同模型对比实验;需要的可联系(备注来意)。】
《------正文------》
引言
计算机视觉技术正席卷各行各业——从自动驾驶、安防系统到医疗影像和工业自动化,目标检测模型的性能直接决定了应用的落地效果。在众多模型中,YOLO(You Only Look Once)凭借“速度与精度兼顾”的特性脱颖而出。本文将深入解析YOLO模型的核心优势、工作原理,以及针对实时场景的7大优化技术,帮你轻松搞定模型落地难题。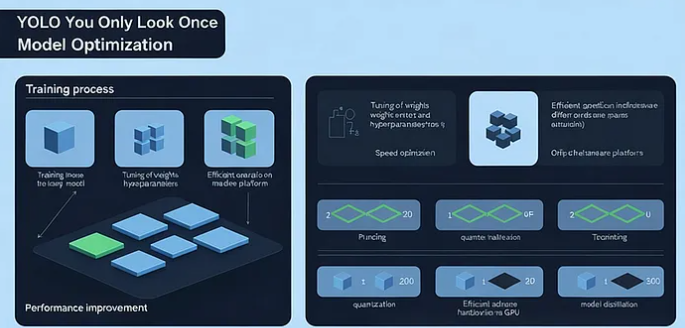
为什么YOLO在计算机视觉中不可替代?
YOLO采用“单阶段检测”架构,与R-CNN等两阶段模型相比,它的优势堪称“降维打击”:
-
速度碾压:单网络一次性完成检测,每秒帧率(FPS)远超传统模型,完美适配实时场景(如自动驾驶的实时路况识别)。
-
架构简洁:单阶段设计让实现和优化更简单,开发者上手门槛更低。
-
泛用性强:能高效检测不同类别、不同尺寸的目标,从微小的工业零件到大型车辆都能覆盖。
-
社区加持:作为开源框架,YOLO持续迭代(目前已到v13版本),开发者社区贡献了大量优化方案。
为什么必须优化YOLO?
在实时应用中(如监控摄像头、自动驾驶决策系统),“低延迟”和“高FPS”是硬性指标。但高精度模型往往架构复杂,需要更多计算资源,容易陷入“精度高则速度慢,速度快则精度差”的困境。优化的核心目标,就是打破这个僵局:
-
适配资源受限设备:在手机、嵌入式设备(如Jetson Nano)上运行时,必须降低模型的内存和能耗需求。
-
满足实时性要求:多数实时场景需要至少30 FPS的处理速度,否则会出现卡顿、延迟。
-
提升泛化能力:优化能让模型在不同数据集和场景中更稳定(比如白天/黑夜、晴天/雨天均能准确检测)。
YOLO是如何工作的?
YOLO的核心逻辑可以概括为“分而治之”:
-
图像网格划分:将输入图像分割成S×S的网格,每个网格负责检测其范围内的目标。
-
多维度预测:每个网格输出多个候选边界框、目标类别概率和置信度(判断框内是否有目标)。
-
非极大值抑制(NMS):过滤重叠的冗余边界框,保留最准确的预测结果。
-
损失函数优化:通过反向传播优化“分类损失”“定位损失”和“置信度损失”,提升整体精度。
这种单阶段设计让YOLO天生具备速度优势,但想进一步突破性能瓶颈,还需针对性优化。
7大优化技术:让YOLO性能飙升
1. 选对版本:YOLO型号直接决定基础性能
YOLO各版本(如v11n、v11s、v11m、v11l、v11x)的尺寸和复杂度差异显著,选择时需结合“平均精度均值(mAP)”和“每秒帧率(FPS)”两个指标:
-
mAP越接近1,精度越高;FPS越高,速度越快。
以A100 GPU测试为例,YOLOv11系列的表现如下: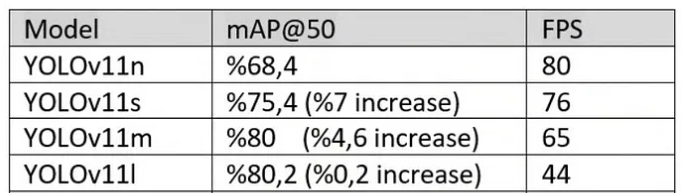 结论:YOLOv11m是“性价比之王”——与更高精度的型号相比,mAP仅差0.2个百分点,但FPS高出20,完美平衡速度与精度。
结论:YOLOv11m是“性价比之王”——与更高精度的型号相比,mAP仅差0.2个百分点,但FPS高出20,完美平衡速度与精度。
2. 调整图像尺寸
输入图像的尺寸直接影响模型的计算量。以YOLOv8n为例:
-
320×320分辨率:FPS可达120,但小目标检测精度下降;
-
640×640分辨率:mAP提升至37.3%,但FPS降至80。
在T4 GPU上测试YOLOv8l的结果更明显:640×640分辨率下FPS仅35(接近实时临界值),而320×320分辨率的FPS更高,更适合实时场景。
建议:根据场景需求选择——实时性优先选320×320,精度优先(如医疗影像)选640×640及以上。
3. 半精度计算(FP16)
半精度(16位浮点数)能大幅降低内存占用和计算量,尤其在NVIDIA GPU上(借助Tensor Core加速)效果显著:
-
优势:训练/推理速度提升20-30%,内存占用减少一半;
-
代价:mAP仅下降0.5-1%,多数场景可接受。
测试显示,YOLOv8l在T4 GPU上启用FP16后,FPS提升明显且mAP基本不变,是性价比极高的优化手段。
4. 超参数调优
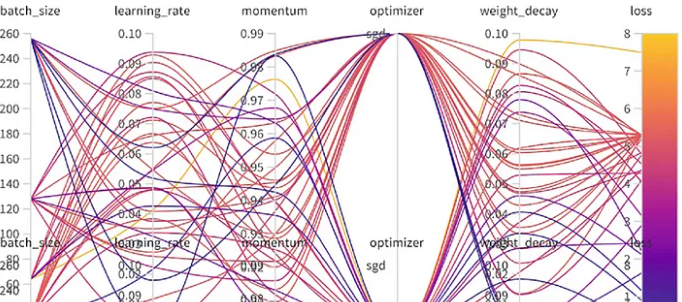 超参数直接影响模型的训练速度和最终性能,关键参数及建议如下(以YOLO训练命令为例):
超参数直接影响模型的训练速度和最终性能,关键参数及建议如下(以YOLO训练命令为例):
yolo train data=coco8.yaml model=yolo11n.pt epochs=100 batch=16 workers=8 lr0=0.002 momentum=0.9 weight_decay=0.0005 warmup_epochs=3 warmup_momentum=0.8 warmup_bias_lr=0.1 optimizer=AdamW patience=30-
workers:数据加载线程数,建议4-16(根据硬件内存调整,过多会增加负载);
-
batch size:单次训练的图像数量,8-32为宜(大batch稳定但耗内存,小batch灵活但梯度波动大);
-
epochs & patience:总训练轮次(100-300)和早停阈值(20-50,防止过拟合);
-
学习率(lr0):初始值0.001-0.01,配合余弦调度策略效果更佳;
-
优化器:优先选AdamW(自带权重衰减,泛化能力更强)。
效果:合理调参可缩短20-30%训练时间,提升1-2% mAP。
5. TensorRT加速
NVIDIA的TensorRT库专为深度学习推理优化,通过三大技术提升YOLO性能:
-
层融合:合并冗余网络层,减少计算步骤;
-
内核优化:针对硬件特性定制计算逻辑;
-
INT8量化:将模型权重转为8位整数,速度提升50%以上。
实测显示,YOLOv8n经TensorRT优化后,FPS从80飙升至120,且精度损失极小。
6. 模型架构改造:从“根源”降低复杂度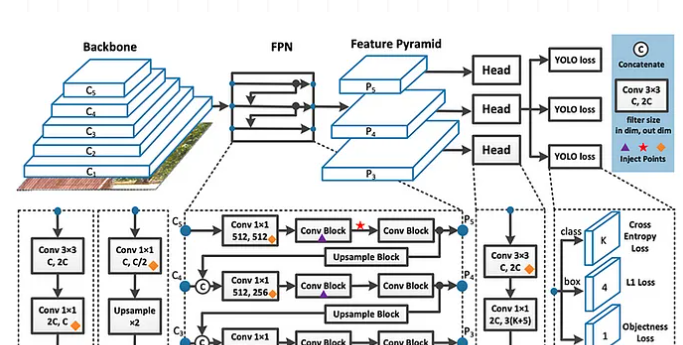
通过修改YOLO的网络结构,可在保证精度的前提下大幅提升速度,常用手段包括:
-
模型剪枝:移除冗余神经元或层,参数减少25%时,FPS提升18%(mAP降0.5%);
-
INT8量化:模型尺寸减半,FPS提升37%(mAP降0.8%),适合嵌入式设备;
-
轻量化 backbone:将CSPDarknet替换为MobileNetV3,FPS提升25%(但mAP降1.4%);
-
知识蒸馏:让小模型(学生)学习大模型(教师)的知识,精度基本不变,速度略提升。
建议:实时场景优先用TensorRT层融合或INT8量化;低功耗设备选剪枝或轻量化backbone。
7. 数据增强:用“数据”提升泛化能力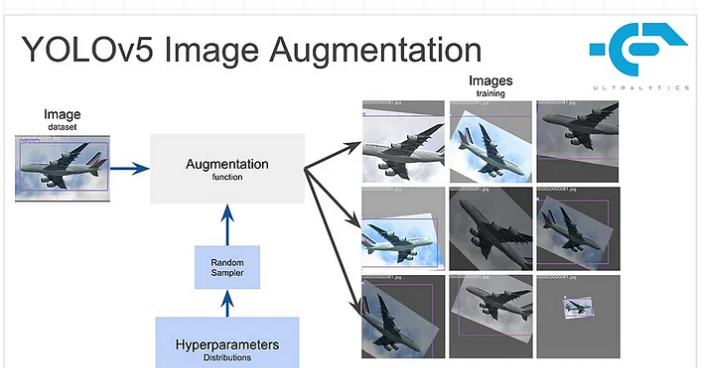
数据增强通过扩展训练集多样性,让模型更适应复杂场景,常用技巧包括:
-
几何变换:旋转、缩放、翻转,提升模型对目标姿态的鲁棒性;
-
色彩调整:改变亮度、对比度、饱和度,适应不同光照条件;
-
马赛克增强:拼接多张图像生成新样本,提升小目标检测能力。
例如,YOLOv8启用马赛克增强后,mAP可提升2-3%。
总结
YOLO模型的优化没有“万能公式”,关键是根据场景需求找到“速度-精度-资源”的平衡点:
-
实时场景(如自动驾驶):优先用TensorRT加速、INT8量化、320×320分辨率;
-
低功耗设备(如Jetson Nano):选YOLOv11n、模型剪枝或MobileNetV3 backbone;
-
高精度需求(如医疗影像):用640×640分辨率、知识蒸馏,适当牺牲速度。
随着YOLO版本的持续迭代和优化技术的发展,它在计算机视觉领域的应用将更加广泛。掌握这些优化技巧,让你的YOLO模型在实战中“快人一步”! 好了,这篇文章就介绍到这里,喜欢的小伙伴感谢给点个赞和关注,更多精彩内容持续更新~~
好了,这篇文章就介绍到这里,喜欢的小伙伴感谢给点个赞和关注,更多精彩内容持续更新~~

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 12
12 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)