盘点|2025CoRL顶级机器人学习会议无人机前沿研究
为此,该研究提出了一种基于模仿学习的解决方案,旨在训练一个神经网络来模仿名为TOPPQuad的、基于模型的、高精度的规划器,从而大幅加速轨迹的生成过程。为解决此问题,研究者提出了分层协同自博弈框架,一种分层强化学习方法,它将复杂的控制策略分解为两个层次:一个负责团队战术的、中心化的“事件驱动式”高层策略,以及一个负责具体飞行动作的、去中心化的底层。2025年,在顶级机器人学习会议CoRL上,研究者
前言
2025年,在顶级机器人学习会议CoRL上,研究者们聚焦于两大核心议题的探索:一是群体智能的涌现与物理协同的深化,二是个体能力的极限探索与交互范式的革新。
在群体智能层面,无人机不只是作为独立单元,而是一个能够自适应、自组织的空中协作网络单元。研究者们不再满足于预设轨迹的集群飞行,而是致力于发展在动态、非结构化环境中“即时团队”。通过深度强化学习与博弈论的结合,无人机群不仅能在对抗环境中演化出复杂的攻防策略,还能共同完成单个无人机不能完成的操控任务。目前,对“陌生”无人机适应性的问题被提上议程,为了赋予无人机在开放环境中与未知伙伴快速形成有效协作的能力,这标志着无人机协同正从封闭系统的“内循环”迈向开放生态的“外循环”。
与此同时,在个体能力上,研究正从“飞得稳”转向“飞多快”。通过将先进的序列建模技术与动力学模型相融合,用算法规划出无人机穿梭于复杂障碍间的、时间最优的极限速度轨迹,这不仅是竞速领域的突破,更将提高紧急避障与快速响应任务的效率。而在交互范式上,正在不断消除人机隔阂。无人机不再只是被控制的工具,而是能够理解指令、融入人们工作的智能伙伴。
1. AT-Drone: Benchmarking Adaptive Teaming in Multi-Drone Pursuit


发表期刊: Proceedings of The 9th Conference on Robot Learning
机构:UniversityofManchester
作者: Yang Li, Junfan Chen,Feng Xue,Jiabin Qiu, Wenbin Li, Qingrui Zhang, Ying Wen, Wei Pan
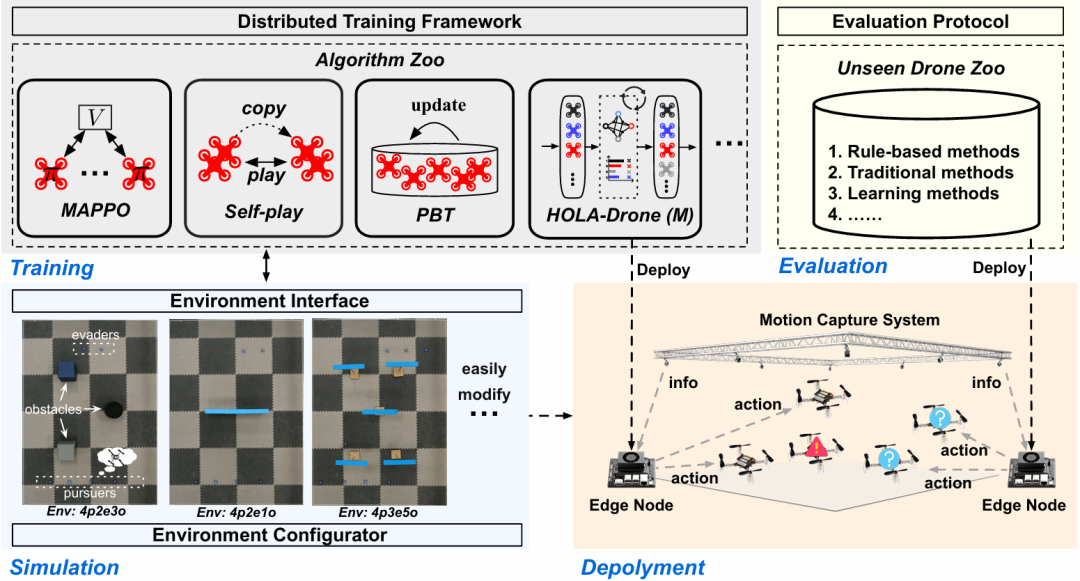
推荐理由:这是首个专门为多无人机“适应性组队”问题设计的基准测试平台。它为了应对从仿真到现实部署的问题,提供了一套完整的解决方案。同时,AT-Drone不仅仅是一个模拟器,它包含四大核心组件:可定制的仿真环境、真实的部署流程、多样化的算法库和标准化的评估协议。这为研究人员提供了一个综合性研究工具,通过提供统一的评估指标、难度递增的测试场景,确保了不同算法可以在一个公平、标准化的环境下进行比较,增强了研究的可复现性。该研究还成功地将机器学习中关于“零样本协调”和“即时团队协作”等理论,应用并扩展到了现实世界中具有连续动作空间的无人机上,这是连接AI理论与机器人实践的成功案例。
论文内容:这篇论文针对“适应性组队”在现实多机器人应用中的研究空白,推出了首个专门用于多无人机追捕场景的基准测试平台AT-Drone。当前的多无人机协作方法严重依赖预定义的协调机制,难以适应新加入或未曾见过的队友,而机器学习领域的相关研究又大多局限于动作离散的虚拟游戏环境,无法直接应用于机器人。为了解决这一问题,AT-Drone提供了一个集成了仿真、部署、训练和评估的完整框架。该平台的核心组件包括:一个高度可定制的仿真环境,其中预设了四种难度从易到难的追捕任务,以便对算法进行严格测试;一套简化的现实世界部署流程,能够将仿真中训练好的策略迁移到由边缘计算设备驱动的Crazyflie微型无人机上进行物理验证;一个创新的算法库,首次将七种适应性组队算法从离散环境扩展到多追捕者、多逃逸者的连续动作空间任务中,并结合了分布式训练框架;以及一套标准化的评估协议,其最大创新是设计了三种包含不同行为策略的“陌生”无人机库,用以全面评估算法在面对不可预测队友时的协作能力与鲁棒性。通过这套综合性工具,AT-Drone能够系统性地推进适应性组队研究,并能够有效推进前沿理论在现实世界的应用。
论文主页:https://openreview.net/forum?id=xPryDEv2YH#discussion
2. Decentralized Aerial Manipulation of a Cable-Suspended Load Using Multi-Agent Reinforcement Learning
发表期刊:Proceedings of the 9th Conference on Robot Learning
机构:Delft University of Technology
作者:Jack Zeng, Andreu Matoses Gimenez, Eugene Vinitsky, Javier Alonso-Mora, Sihao Sun
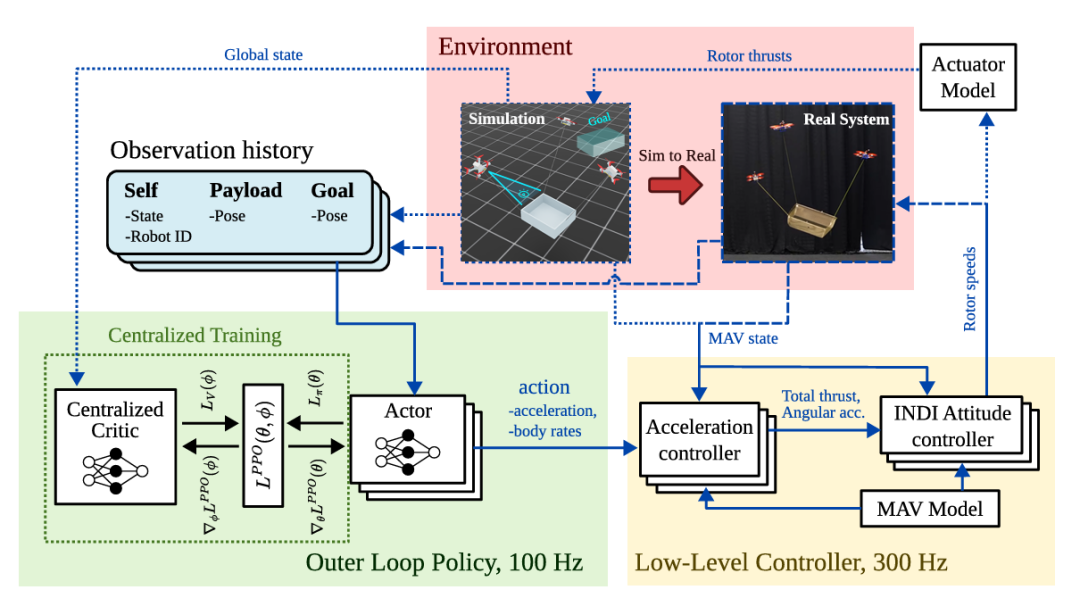
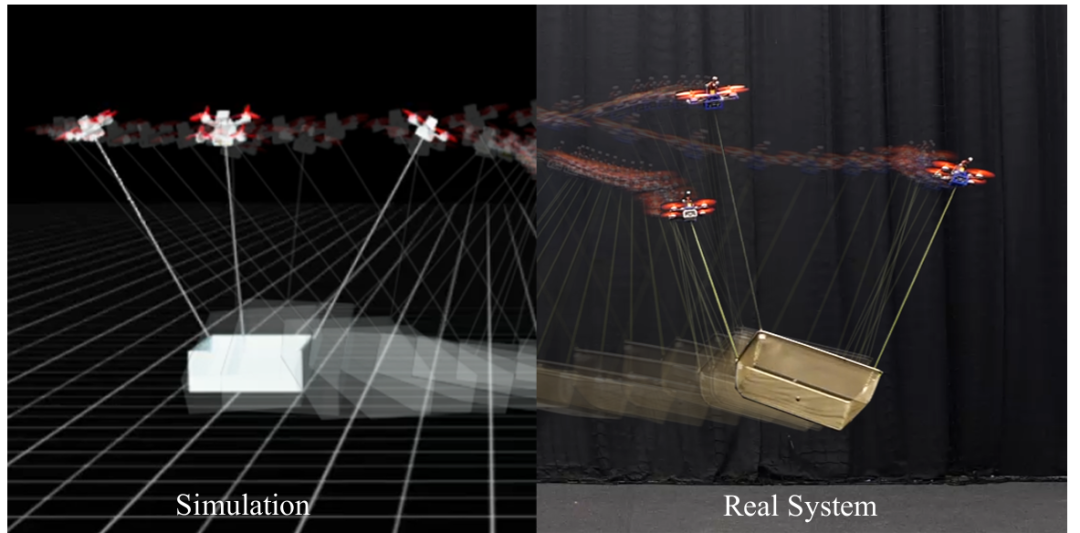
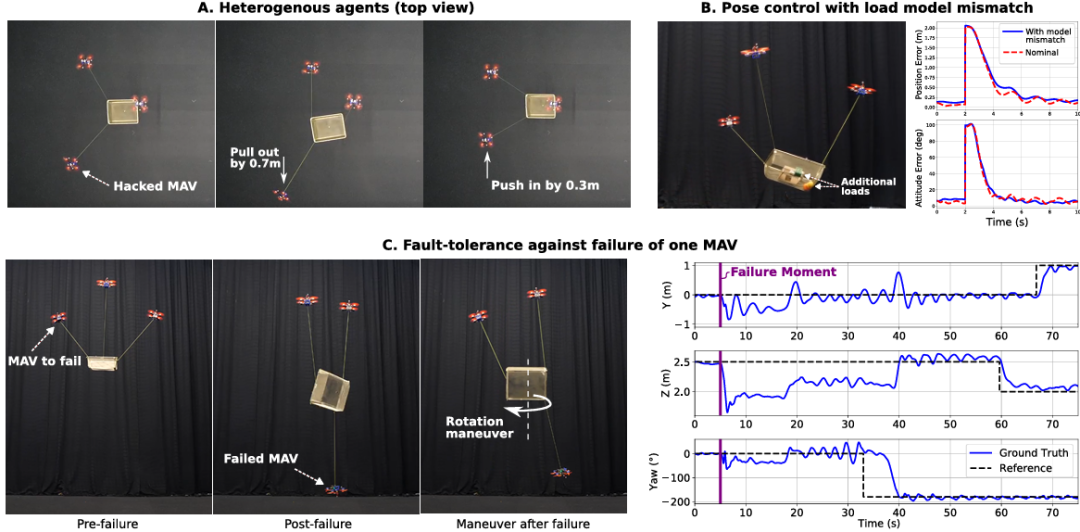
推荐理由:在该研究中成功实现了在现实世界中对缆绳悬挂负载的六自由度操控。这意味着每个无人机都能独立决策,不用中央枢纽的指挥,也不用互相通信,极大地提升了系统的灵活性和可扩展性。实验表明,即使在负载的质量和质心发生未知的变化时,或者在团队中混入“陌生”的无人机时,系统依然能稳定工作。即使团队中有一架无人机在飞行中完全失灵并坠落,剩余的无人机也能迅速接管并继续完成操控任务,展现了该方法极高的鲁棒性。并且通过创新的动作空间设计和一个强大的底层控制器,成功实现了从仿真环境到真实物理环境的“零样本”迁移。这意味着在仿真中训练好的策略可以直接部署到现实无人机上,有效应对了机器人学习领域的一大核心问题。由于其去中心化的特性,该方法的计算成本极低,并且计算时间不随无人机数量的增加而增加。这使得策略可以完全在无人机机载的微型计算机上运行,为未来大规模无人机集群的应用奠定了基础。
论文内容:这篇论文提出并首次在现实世界中验证了一种完全去中心化的方法,通过多智能体强化学习技术,实现了由一组无人机对一个缆绳悬挂的负载进行的六自由度操控。传统方法大多采用中心化控制,虽然精确但存在计算成本高、扩展性差以及依赖全局状态信息和内部通信等缺点。为解决这些问题,该研究的策略在执行时完全去中心化,每个无人机仅根据自身的局部观测,来进行独立决策,无需与其他无人机通信或获取其状态。每个无人机之间通过共同观察负载的姿态变化来进行调整,从而实现协同合作。该方法采用“中心化训练,去中心化执行”的范式,在仿真训练中利用一个能获取全局信息的中心来稳定学习过程,而在实际部署时则完全独立运行,这使得策略能够部署在机载计算设备上。为了成功从仿真迁移到现实,研究者设计了一种创新的动作空间,即直接输出期望的线加速度和机体角速度,并结合一个强大的底层控制器来跟踪这些指令,有效应对了缆绳张力等不确定性的问题。大量的实验证明,该方法的跟踪性能可与最先进的中心化方法相媲美,同时计算效率大幅提升。更重要的是,该系统展现了极高的鲁棒性,能够有效应对负载模型不确定变化,解决存在异构智能体和某个飞行器在飞行中完全失灵的情况。这为实现可扩展、鲁棒且高效的空中协同操控提供了有效的解决方案。
论文主页:https://openreview.net/forum?id=IuiB5iaMxy#discussion
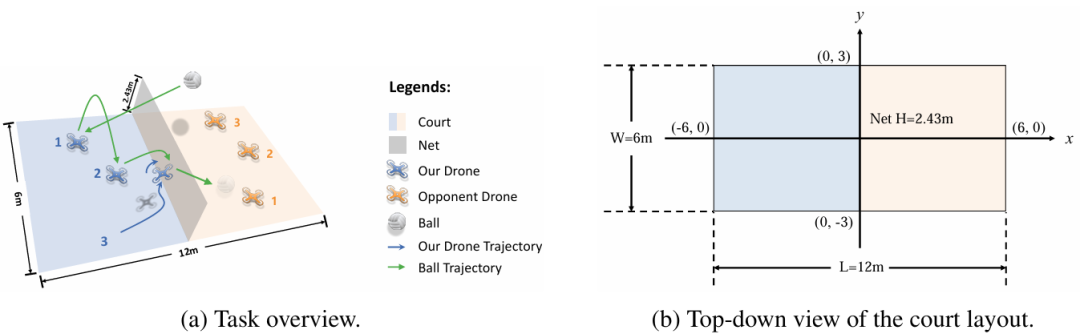
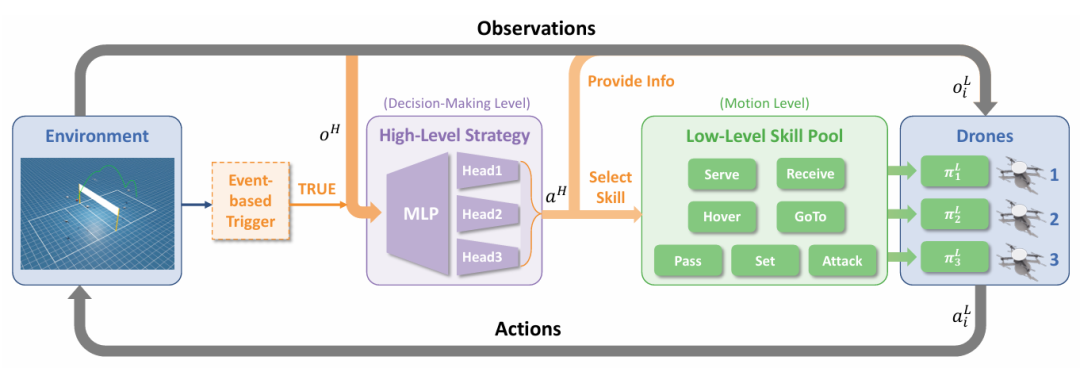
3. Mastering Multi-Drone Volleyball through Hierarchical Co-Self-Play Reinforcement Learning

发表期刊: Proceedings of The 9th Conference on Robot Learning
机构: Tsinghua University
作者:Ruize Zhang, Sirui Xiang, Zelai Xu, Feng Gao, Shilong Ji, Wenhao Tang, Wenbo Ding, Chao Yu, Yu Wang
推荐理由:该论文首次系统性进行了“3v3多无人机排球”的研究。该任务融合了高层面的团队战术策略和底层的无人机高机动性的精准操控,是“具身智能”领域一个全新的测试基准。为应对该任务的复杂挑战,论文提出了分层协同自博弈框架。该框架将复杂的控制策略有效分解为两个层次:一个负责团队战术的、在离散关键节点激活“事件驱动式”高层中心化策略,以及一个负责个体敏捷操控的、连续运行的底层去中心化核心。这种设计为解决具有相似层级结构的机器人协作问题提供了清晰高效的架构。通过技能获取、策略预训练与最终的协同自博弈三个阶段,智能体能够从零开始,通过自我博弈探索并掌握复杂的运动技能和团队策略,摆脱对模仿学习的依赖。
论文内容:这篇论文首次系统性地研究了“3v3多无人机排球”这一全新的对抗任务,这要求智能体同时掌握高层面的团队战术与底层的敏捷飞行控制。该任务因决策时长、多智能体间的耦合,以及无人机自身的欠驱动动力学而具有极高挑战性。为解决此问题,研究者提出了分层协同自博弈框架,一种分层强化学习方法,它将复杂的控制策略分解为两个层次:一个负责团队战术的、中心化的“事件驱动式”高层策略,以及一个负责具体飞行动作的、去中心化的底层核心。高层策略仅在击球或球过网等关键时刻被激活,而底层技能则以高频率连续运行。论文设计了一个三阶段训练流程:第一阶段,通过“策略链”技术训练出多种可靠的底层运动技能,如发球、传球和扣球;第二阶段,在冻结底层技能的基础上,通过自博弈预训练高层策略,使其掌握基本的战术组合;第三阶段,通过“协同博弈”对高层策略和底层技能进行联合微调,使二者相互适应并共同进步。实验结果表明,HCSP取得了优异的性能,对阵多个基准方法的平均胜率达到82.9%。最关键的发现是,在第三阶段的协同训练中,无人机团队出现了研究者未曾设计的、更高级的战术行为,例如一种出其不意的“二次球进攻”,这充分证明了该框架能够有效促进智能体创造性策略生成。
论文主页:https://openreview.net/forum?id=23FdMTxEh7#discussion
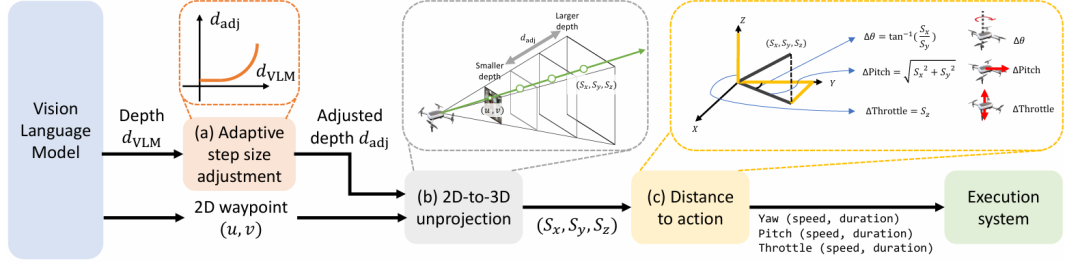
4. See, Point, Fly: A Learning-Free VLM Framework for Universal Unmanned Aerial Navigation


发表期刊:Proceedings of The 9th Conference on Robot Learning
机构: National Yang Ming Chiao Tung University
作者:Chih Yao Hu, Yang-Sen Lin, Yuna Lee, Chih-Hai Su, Jie-Ying Lee, Shr-Ruei Tsai, Chin-Yang Lin, Kuan-Wen Chen, Tsung-Wei Ke, Yu-Lun Liu
推荐理由:该论文最大的特点是提出了一个“免训练”(training-free)的框架。它不依赖任何特定的训练数据集或耗时的模型微调,而是直接利用已有的视觉语言模型的能力。这使得该方法能够泛化到任何未曾见过的环境,并理解任意形式的自然语言指令,实现真正的“通用”无人机导航。另一个特点是将3D导航任务转化为2D图像定位,与以往让VLM直接生成文本格式的飞行指令不同,该论文的核心是预测复杂的无人机动作,巧妙地转化为一个VLM更擅长的“2D空间定位”任务。它引导VLM在无人机拍摄的实时图像上标记下一个航点的位置,然后通过几何变换将这个2D坐标转换为3D空间中的飞行动作指令。这种方法更符合VLM的能力模型,从而实现了更精准的控制。而且无论是在模拟环境还是现实世界中,SPF框架的性能都大幅领先于现有的基准方法。在DRL仿真测试中,其成功率比之前最好的方法高出63%,而在现实世界测试中,其平均成功率高达92.7%,有力地证明了该框架的有效性和可靠性。
论文内容:这篇论文详细介绍了一种名为“看、指、飞”的、无需额外训练的无人机视觉语言导航框架。该框架的核心思想是将复杂的自主导航问题,巧妙地分解为一个大型视觉语言模型更擅长的2D空间定位任务。其工作流程在一个闭环控制中迭代进行:首先,系统将无人机当前的第一视角图像与用户的自然语言指令一同输入到一个未经修改的VLM中。VLM并不会直接生成模糊的文本动作,而是输出一个结构化的JSON对象,精确地标注目标在当前图像上的2D像素坐标,以其作为一个航点,并附带一个离散的深度标签,表示其预测的行进距离。接着,为了提升飞行的效率与安全性,自适应步长调整模块会利用一个非线性缩放曲线,将这个离散的深度标签转化为一个更平滑、更适应环境的实际步长,使得无人机在开阔地带可以飞得更快更远,在接近目标或障碍时则会自动减小步长。随后,系统通过一个基于针孔相机模型的几何变换过程,将2D图像航点和调整后的步长共同反投影成三维空间位移向量。最后,这个三维位移向量被进一步分解为无人机底层控制器可以执行的具体指令,即偏航、俯仰和油门的控制量。整个“感知-规划-行动”的循环不断重复,使无人机能够持续修正路线,从而实现对静态和动态目标的精准导航。
论文主页:https://openreview.net/forum?id=AE299O0tph#discussion
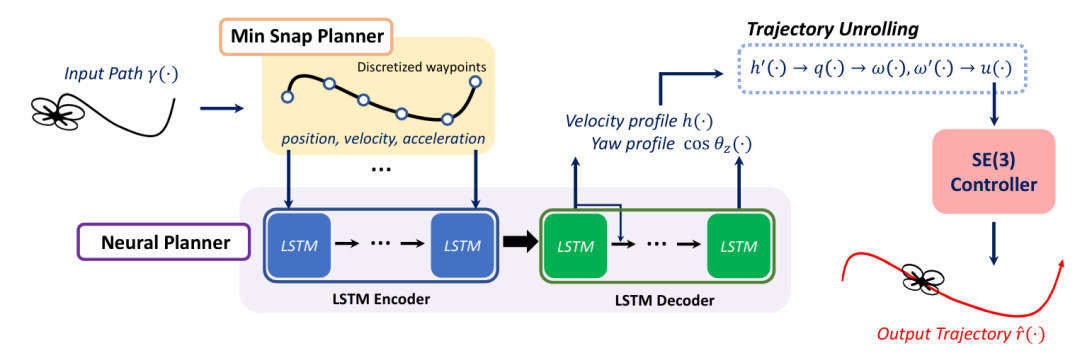
5. Sequence Modeling for Time-Optimal Quadrotor Trajectory Optimization with Sampling-based Robustness Analysis
发表期刊:Proceedings of The 9th Conference on Robot Learning
机构:University of Pennsylvania
作者:Katherine Mao, Hongzhan Yu, Ruipeng Zhang, Igor Spasojevic, M Ani Hsieh, Sicun Gao, Vijay Kumar
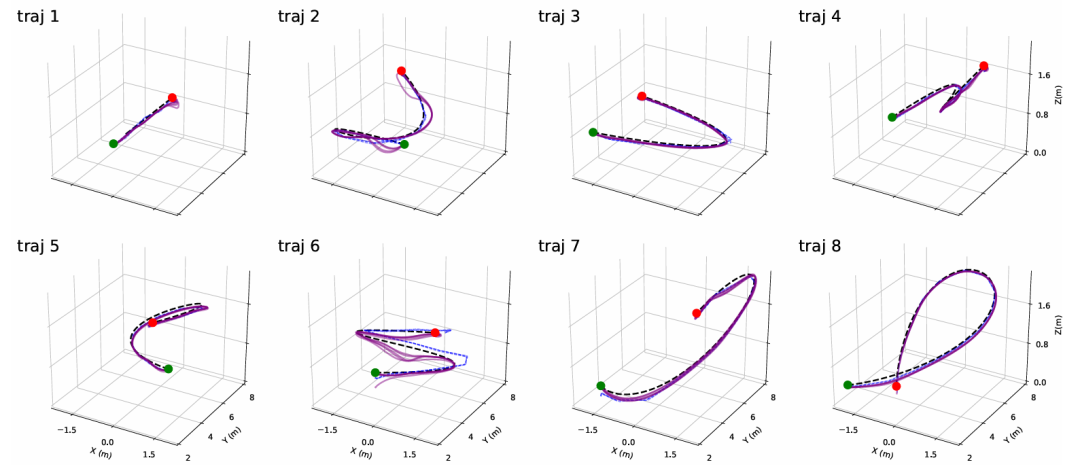
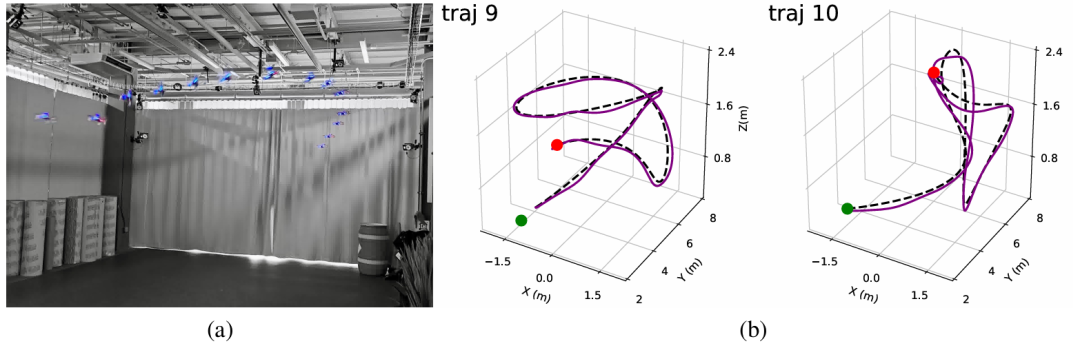
推荐理由:该研究提出了一种创新的基于模仿学习的方法,显著提高了四旋翼无人机最优轨迹生成的销量效率,解决了传统优化方法计算成本高昂、难以实时应用的问题。该方法实现了超过100倍的计算速度提升,并成功在真实的无人机硬件上验证了其实时可行性。其核心创新在于巧妙地将高维轨迹优化问题转换为一个“序列到序列”的学习任务,让模型仅需预测重建轨迹所需的最小变量集,即平方速度剖面和偏航剖面。这种降维设计极大地简化了学习任务,有效避免了过拟合,并提升了模型的鲁棒性。为确保生成轨迹的可靠性,研究还引入了一套严谨的量化分析框架,评估底层控制器稳定跟踪预测轨迹的能力,并通过在训练数据中注入随机数据,进一步增强了模型面对路径变化的适应性。全面的实验证明,该方法不仅能在大幅提速的同时达到接近传统优化方法的性能,并成功部署于真实无人机,展现出对路径几何形状与长度的优秀泛化能力。
论文内容:这篇论文的核心目标是解决四旋翼无人机在计算最优轨迹规划中,存在的计算成本过高、难以实时应用的问题。传统方法虽然能生成无人机动力极限的轨迹,但需要通过迭代非线性优化的方法来求解复杂的非凸问题,过程非常耗时。为此,该研究提出了一种基于模仿学习的解决方案,旨在训练一个神经网络来模仿名为TOPPQuad的、基于模型的、高精度的规划器,从而大幅加速轨迹的生成过程。该方法将复杂的轨迹优化问题创新性地转化为一个“序列到序列”的学习任务。其输入是一个离散化的几何路径,其中包含了路径点的位置及其一阶和二阶导数信息,以便为模型提供明确的几何特征。其中一个关键在于,模型被训练来预测最优轨迹所需要的最小变量集,即路径的平方速度剖面偏航角的余弦值。在模型预测出这两个关键序列后,完整的无人机状态轨迹,包括姿态四元数、角速度等,都可以通过动力学方程被精确地计算出来。除了性能,该研究还重点关注了学习模型的鲁棒性,并为此提出了一个严谨的量化分析框架,评估模型预测轨迹能否被底层控制器稳定跟踪,从而量化其动态可行性。为进一步增强鲁棒性,论文还采用了一种数据增强方案,即在训练数据中对输入路径施加随机扰动。实验证明,在这种噪声加入训练模型后,在面对扰动时无人机表现出更强的稳定性和可靠性。全面的实验验证了该方法的有效性,在多种神经网络架构的对比中,LSTM编码器-解码器模型表现最佳;与传统优化器相比,它的计算时间从超过10秒缩短至0.1秒以内,同时轨迹质量和动态可行性仍保持在极高水平。最终,该方法成功部署在真实的CrazyFlie2.0无人机上,并证明了其能够稳定泛化到比训练数据更长的未知路径。
论文主页:https://openreview.net/forum?id=rbMoMEK4m2#discussion
结语
综观CoRL 2025的无人机研究,其显著推动了空中机器人的智能化,尤其是在多智能体协同与个体能力提升方面取得了突破。研究利用多智能体强化学习和自博弈等技术,实现了无人机群的去中心化协调,使其能在无需通信的情况下完成自适应追捕、精准操控悬挂负载,乃至在模拟的团队运动中学习高级战术,并展现出对队友失效等意外情况的强大鲁棒性。在解耦高层战略与底层敏捷控制应用了分层学习框架,促进了复杂涌现行为的产生。同时,个体无人机的智能也得到加强,通过运用大型视觉语言模型,实现了无需训练的通用导航,将3D控制巧妙转化为2D视觉定位,使无人机能零样本理解自然语言指令。此外,序列建模和模仿学习的应用极大地加速了时间最优轨迹的计算,将耗时计算的优化减少至实时可行,接近了无人机的物理极限。这些研究普遍都强调了鲁棒性、仿真到现实的转化以及高效的机载部署,共同塑造了更自主、更协同、更高效的无人机系统。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 11
11 0
0- 0



 已为社区贡献87条内容
已为社区贡献87条内容

所有评论(0)