轻量级VLA模型Evo-1:仅凭0.77b参数取得SOTA,解决低成本训练与实时部署
视觉-语言-动作(VLA)模型将感知、语言和控制能力统一起来,使机器人能够通过多模态理解执行多样化任务。然而,当前的VLA模型通常包含海量参数,且高度依赖大规模机器人数据预训练,导致训练过程中的计算成本高昂,同时限制了其在实时推理中的部署能力。此外,多数训练范式常导致视觉-语言backbone模型的感知表征退化,引发过拟合并削弱对下游任务的泛化能力。
1.写在前面&出发点
视觉-语言-动作(VLA)模型将感知、语言和控制能力统一起来,使机器人能够通过多模态理解执行多样化任务。然而,当前的VLA模型通常包含海量参数,且高度依赖大规模机器人数据预训练,导致训练过程中的计算成本高昂,同时限制了其在实时推理中的部署能力。此外,多数训练范式常导致视觉-语言backbone模型的感知表征退化,引发过拟合并削弱对下游任务的泛化能力。
论文名称:Evo-1: Lightweight Vision-Language-Action Model with Preserved Semantic Alignment
论文链接: https://arxiv.org/abs/2511.04555来自上海交大、CMU、剑桥大学的团队提出轻量级VLA模型Evo-1,在无需机器人数据预训练的前提下,既降低计算成本又提升部署效率,同时保持强劲性能。Evo-1基于原生多模态视觉语言模型(VLM),融合创新的交叉调制扩散变换器与优化集成模块,构建高效架构。这里还进一步引入两阶段训练范式,通过逐步协调动作与感知,完整保留VLM的表征能力。
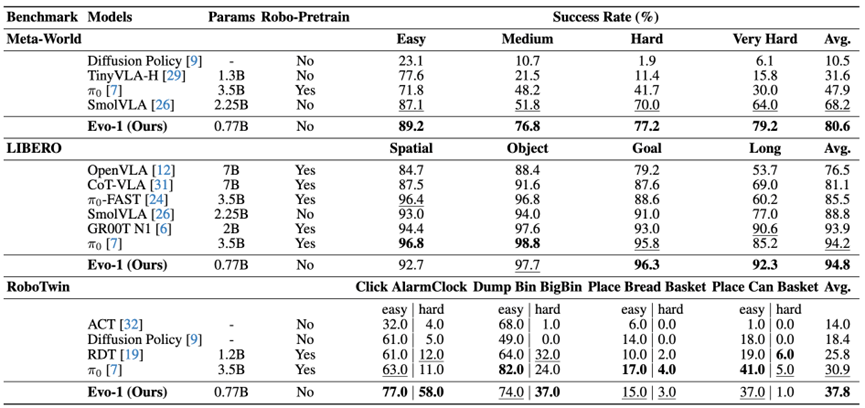
值得注意的是,仅凭0.77b参数,Evo-1在MetaWorld和RoboTwin测试集上均取得最先进成果,分别超越前沿模型12.4%和6.9%,并在LIBERO测试中获得94.8%的竞争性结果。在真实世界评估中,Evo-1以高推理频率和低内存开销实现了78%的成功率,超越所有基线方法。我们开源代码、数据集及模型权重,以推动轻量高效视觉学习代理模型的后续研究。
2.行业痛点
现有VLA模型仍面临多重关键局限:首先,其海量参数(常达数十亿级)导致训练与推理阶段GPU内存消耗巨大且计算成本高昂; 其次,高计算开销导致控制频率低下,限制了模型在交互式机器人任务中的实时响应能力。第三,广泛采用的端到端训练范式常会退化视觉-语言backbone的表征空间,导致下游任务泛化能力差且易过拟合。第四,这些模型大多依赖于大规模机器人数据集(如OXE、DROID)的长期训练,而此类数据集的收集过程既耗费人力又成本高昂。
3.Evo-1方法及效果
基于此痛点,这里提出轻量级视觉语言模型Evo-1,旨在实现低成本训练与实时部署。
Evo-1采用统一的视觉-语言backbone,在单阶段多模态范式下预训练而成。该范式通过联合学习感知与语言表征(无需后对齐),实现了强大的多模态感知与理解能力。这种紧凑型VLM设计显著缩减了整体模型规模,在训练和推理阶段均降低了GPU内存需求与计算负载。在此backbone之上,我们设计了跨调制扩散变换器来建模连续动作轨迹,实现高效的时间推理以生成连贯运动。该设计同时提升模型紧凑性,大幅提高推理频率,支持实时交互机器人场景中的响应行为。
我们进一步引入优化集成模块,将融合的视觉-语言表征与机器人的本体感知信息对齐,从而实现多模态特征在后续控制中的无缝整合。为在保留多模态表征能力与适应下游动作生成需求间取得平衡,我们提出两阶段训练范式:通过逐步对齐感知与控制模块,显著减轻视觉语言模型语义空间的畸变。该模型在继承原生语义空间的同时,无需机器人数据预训练即可展现强泛化能力与竞争性结果。
Evo-1在三项主流模拟基准测试中均取得优异成绩: 在Meta-World(80.6%)和RoboTwin套件(37.8%)上创下新纪录,分别超越了68.2%和30.9%的先前最佳成绩;在LIBERO上达到94.8%,展现出其在单臂与双臂操作任务中的适应性。在四个典型机器人任务的真实世界评估中,Evo-1整体成功率达78%,持续超越其他基线模型。其在紧凑GPU内存占用下仍保持高推理频率,展现出物理部署中的计算效率与稳定控制能力。我们的贡献总结如下:
(1)轻量高效架构。提出仅含0.77b参数的轻量级VLA架构Evo-1,显著降低训练成本并提升推理速度,支持消费级GPU实时部署。
(2)语义保留提升泛化能力。引入两阶段训练范式,在保留VLM固有的多模态理解能力与适应下游动作生成需求之间取得平衡,有效提升了跨多样化操作任务的泛化能力。
(3)无需预训练即可实现强劲性能。通过模拟与真实世界任务的广泛实验验证,Evo-1在无需依赖大规模机器人数据预训练的情况下达到最先进水平,显著降低了高成本、高耗时的数据采集需求。
4.方法详解
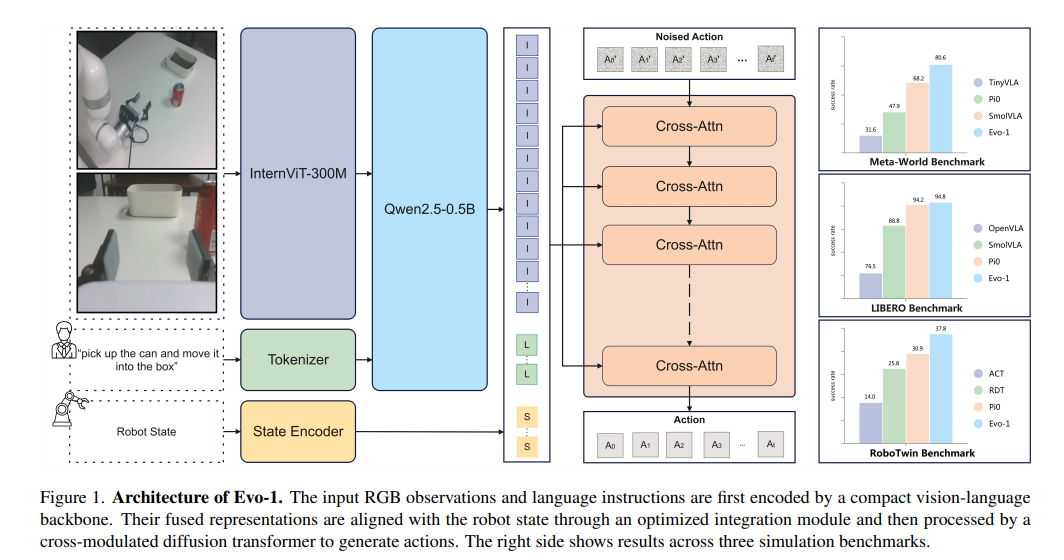
4.1 视觉-语言backbone
Evo-1采用InternVL3-1B模型作为其视觉语言融合的backbone架构,该模型在原生多模态范式下预训练而成。不同于事后对纯文本大型语言模型进行图像适配的对齐pipeline,InternVL3通过大规模多模态与文本语料库协同学习语言理解与视觉理解能力,从而实现紧密的跨模态对齐与高效的特征融合。
4.2 交叉调制扩散transformer
Evo-1采用条件去噪模块作为动作专家,从视觉-语言backbone生成的融合多模态嵌入中预测连续控制动作。遵循流匹配范式,该模块学习一个随时间变化的向量场,逐步将初始噪声动作转换为真实目标。具体而言,该动作专家以扩散变换器(DiT)形式实现,仅依赖堆叠的交叉注意力层,区别于先前模型采用的交替自注意力与交叉注意力结构。
4.3 集成模块
Evo-1采用基于交叉注意力的集成模块,在对交叉调制扩散transformer进行条件处理前,有效融合多模态与本体感觉信息。融合后的多模态表示 zt 从视觉-语言backbone的第14层提取,捕捉到平衡视觉与语言特征的中间层语义。为完整保留感知嵌入与机器人本体感知状态的信息,我们采用特征拼接而非投影至共享嵌入空间的方式处理zt与机器人状态st。该拼接特征作为动作专家模型中Transformer模块的键值输入,为动作生成提供全局性且信息完备的上下文。其他集成变体及其对比结果详见消融研究部分。
4.4 两阶段训练流程
为在保留视觉语言backbone模型的多模态理解能力与适应下游动作生成需求之间取得平衡,这里采用两阶段训练范式。保留预训练的多模态语义对维持模型在多样化视觉语言场景中的泛化能力至关重要,可避免对特定操作任务的过拟合。同时,有效适配动作生成需求至关重要,这能确保融合后的感知表征精准引导基于扩散的动作专家模型,从而提升下游控制任务的成功率。直接采用端到端训练可能破坏预训练表征,削弱模型固有的多模态理解能力,导致在特定下游任务上过拟合,最终损害其泛化能力。
第一阶段:动作专家对齐。在第一阶段,将整个视觉-语言backbone冻结,仅对动作专家与集成模块进行训练。这种设置使动作专家中随机初始化的权重能够逐步与多模态嵌入空间对齐,同时避免将噪声梯度反向传播至预训练的backbone。由此,模型能在全面微调前建立视觉语言模型特征与动作专家之间的协同对齐关系。
第二阶段:全局微调。当整合模块与动作模块充分协同后,我们将解冻视觉语言模型主干,并对整个架构进行全局微调。此阶段可实现预训练视觉语言主干与动作专家的协同优化,确保更深度的融合,并更好地适应多样化的操作任务。
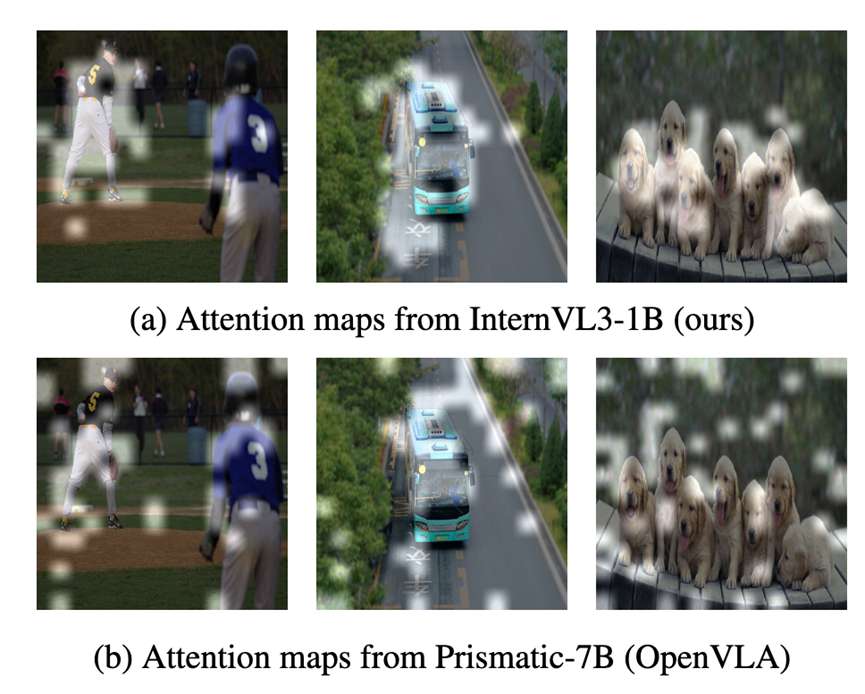
保持多模态语义一致性。为进一步验证训练策略的优势,我们对比了InternVL3-1B(经两阶段训练后的Evo1模型)与Prismatic-7B VLM(OpenVLA中采用的模型)生成的图像文本注意力图。
如图所示,经过机器人操作数据训练后,InternVL3-1B的嵌入向量保留了更清晰的结构和语义一致的注意力区域,而Prismatic-7B则出现显著的语义漂移和对齐失效。该结果表明,我们的训练流程有效保留了原始语义空间,使模型在适应下游控制任务的同时,仍能保持强大的视觉语言理解能力。
5.仿真测试结果
在Meta-World(80.6%)和RoboTwin套件(37.8%)上实现了新sota,分别超越了68.2%和30.9%的先前最佳成绩;在LIBERO上达到94.8%,展现了其在单臂和双臂操作任务中的适应性。
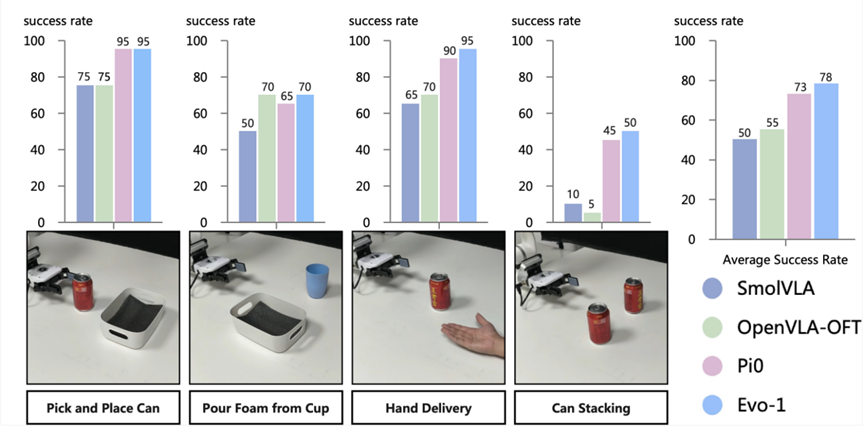
6.真机实验结果
Evo-1在四个真实世界任务中平均成功率达78%,显著优于SmolVLA(50%)和OpenVLAOFT(55%)。该模型仅拥有0.77b参数(约为3.5b参数的π0模型的四分之一规模),其性能仍超越π0模型(73%),彰显出其卓越的效率与实际应用价值。
7.真机部署消耗
Evo-1在效率与性能之间实现了最佳平衡。它保持着2.3 GB的低内存消耗,达到16.4 Hz的最高推理频率,并取得78%的顶尖实际成功率。

8. 消融实验
8.1 集成模块分析
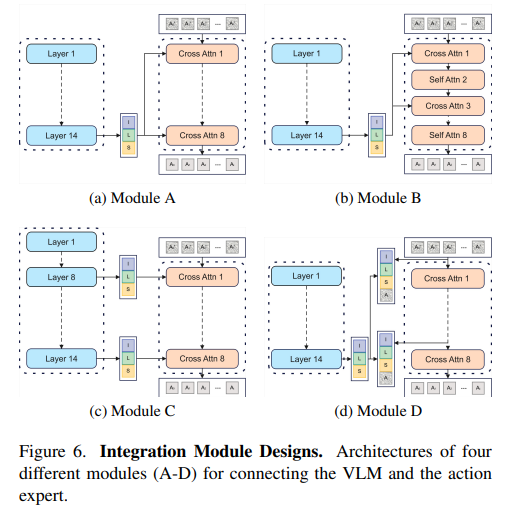
通过实验探究视觉语言模型(VLM)与动作专家之间不同集成策略对整体性能的影响。如图6所示,评估了四种代表性设计(模块A-D),每种设计都提供了融合视觉、语言和动作状态信息的独特方法:
模块A:中间层交叉注意力。该设计从VLM第14层提取融合的多模态特征zt,将其与机器人状态st拼接后,作为所有DiT层的键值输入;其中注入噪声的动作作为交叉注意中的查询。
模块B:中层交错交叉自注意。该设计在DiT内部交错排列交叉注意层与自注意层。每个交叉注意力块先关注拼接后的VLM特征与状态st,随后通过自注意力块优化内部交互。
模块C:分层交叉注意力。该设计将选定中深层VLM层的特征注入DiT,对应层使用配对的VLM特征与状态st作为键值输入,并以带噪音的动作作为查询,实现分层感知-动作对齐。
模块D:联合键值交叉注意力。该设计将VLM特征、机器人状态及噪声注入动作拼接为每个DiT层的联合键值输入,同时带噪音的动作作为查询实现统一的多模态条件处理。
8.2 训练范式比较
将提出的两阶段训练范式与单阶段基线模型进行对比,后者从零开始联合训练所有模块。在两阶段设置中,首先冻结视觉语言模型(VLM),仅训练整合模块和动作专家。待对齐后,解冻VLM并进行全局微调。相比之下,单阶段基线直接同时训练VLM、整合模块和动作专家,不采用任何冻结策略。
注意力可视化。为分析两者差异,对两种模型的注意力图进行可视化处理。如图7所示,两阶段训练范式保留了视觉语言模型的语义注意力模式,持续聚焦于目标区域及任务相关实体。相比之下,单阶段训练破坏了这些模式,导致模型丧失清晰的语义关注点,转而关注无关区域。

具身求职内推来啦
国内最大的具身智能全栈学习社区来啦!
推荐阅读
从零部署π0,π0.5!好用,高性价比!面向具身科研领域打造的轻量级机械臂
工业级真机教程+VLA算法实战(pi0/pi0.5/GR00T/世界模型等)
具身智能算法与落地平台来啦!国内首个面向科研及工业的全栈具身智能机械臂
VLA/VLA+触觉/VLA+RL/具身世界模型等!具身大脑+小脑算法与实战全栈路线来啦~
MuJoCo具身智能实战:从零基础到强化学习与Sim2Real
Diffusion Policy在具身智能领域是怎么应用的?为什么如此重要?
1v1 科研论文辅导来啦!

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 16
16 0
0- 0



 已为社区贡献50条内容
已为社区贡献50条内容

所有评论(0)