自动驾驶中的传感器技术87——Sensor Fusion(10)
自动驾驶算法架构的演进推动传感器数据融合层级不断前移:从早期的目标级后融合(模块化规则算法),到BEV特征级融合(多任务联合感知),再到全链路特征交互(UniAD)和原始数据级融合(端到端系统),最终发展为多模态语义对齐(具身智能)。这一演进过程体现了算力提升、算法优化和神经网络能力的增强,使得融合点从末端结果融合逐步推进到最前端的原始特征融合,实现了更高效、更拟人化的自动驾驶决策能力。
自动驾驶算法架构的演进,直接决定了传感器数据融合发生的层级。
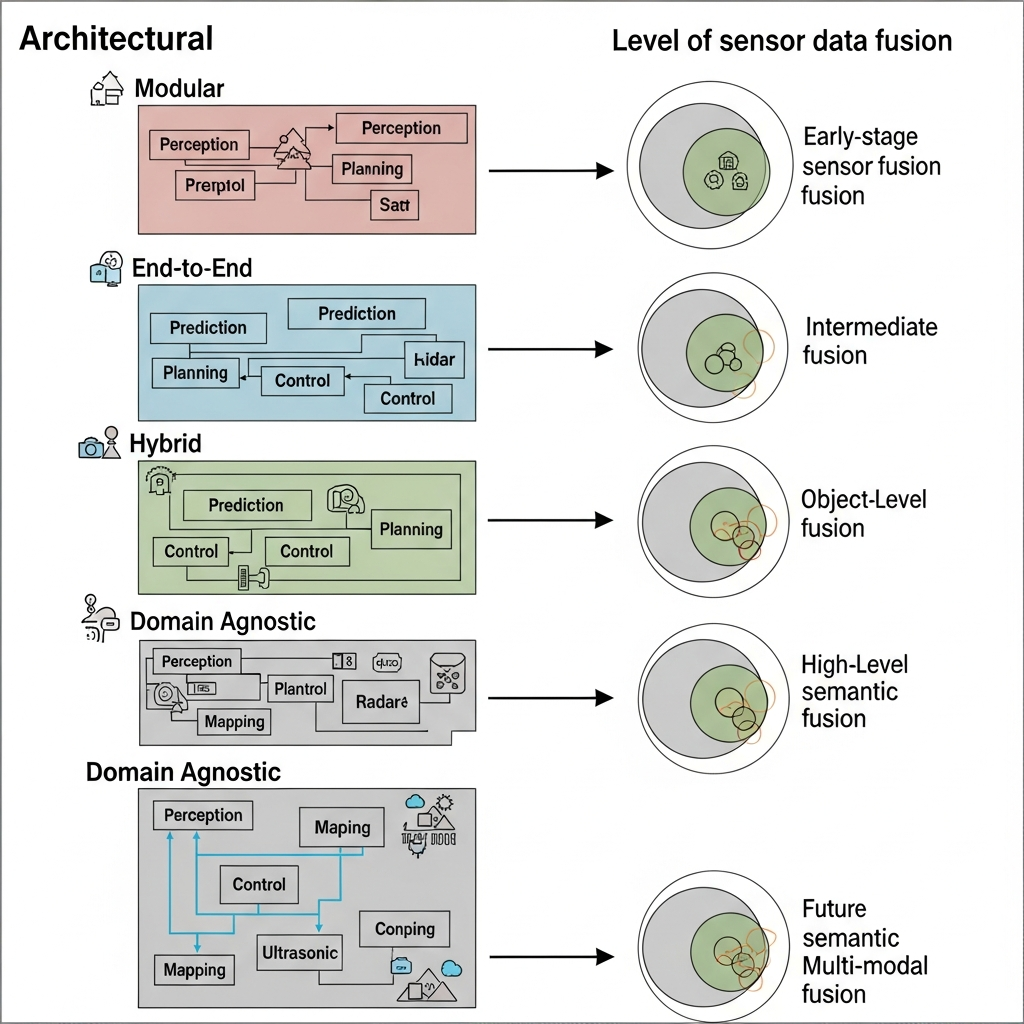
随着算法从“规则驱动”转向“数据驱动”,融合点(Fusion Point)在数据处理流程中不断前移,从最末端的“结果融合”一路推向最前端的“原始特征融合”。
以下是各阶段对融合层级的具体要求:
第一阶段:模块化规则算法 —— 目标级后融合 (Object-Level / Late Fusion)
-
融合层级: 最晚期 (Late Fusion)。
-
传感器要求:
-
每个传感器(Camera, Radar, LiDAR)必须是智能传感器 (Smart Sensor)。
-
传感器内部必须自带 ECU/ISP,先跑一遍自己的检测算法,吐出目标列表 (Object List)。
-
融合逻辑:
-
Camera 说:“前方 50 米有辆车 (ID:1)”。
-
Radar 说:“前方 52 米有个障碍物 (ID:2)”。
-
融合算法(在域控 CPU 上跑卡尔曼滤波)负责把 ID:1 和 ID:2 关联起来,加权平均输出最终位置。
-
为什么是这级? 早期算力不足,无法处理多路原始数据,且责任划分明确(Radar 供应商对 Radar 结果负责)。
第二阶段:多任务联合感知 (HydraNet) —— BEV 特征级融合 (Feature-Level / Middle Fusion)
-
融合层级: 中期 (Middle Fusion),通常在 BEV (Bird's Eye View) 空间进行。
-
传感器要求:
-
传感器退化为哑巴传感器,只输出半成品数据。
-
Camera: 输出图像特征图 (Feature Map) 或 PV (Perspective View) 特征。
-
LiDAR: 输出体素化特征 (Voxel Features)。
-
Radar: 输出点云 (Point Cloud) 而非目标列表。
-
融合逻辑:
-
将 Camera 的 2D 特征投影到 3D BEV 空间。
-
将 LiDAR/Radar 的 3D 特征对齐到同一个 3D BEV 空间。
-
在这个统一的“上帝视角”特征图上进行 Concat (拼接) 或 Cross-Attention (交叉注意力)。
-
One Model Fits All: 融合后的特征送入同一个 Head,直接输出最终融合结果。
-
为什么是这级? 为了解决跨模态的信息互补(如:LiDAR 测距准但不知颜色,Camera 懂语义但测距差),BEV 是最佳的统一表示空间。
第三阶段:感知决策一体化 (UniAD) —— 全链路特征交互 (Full-Stack Feature Interaction)
-
融合层级: 特征级融合 + 任务间 Query 融合。
-
传感器要求: 同第二阶段,但对数据的时间同步性和特征的语义一致性要求更高。
-
融合逻辑:
-
不仅在感知阶段做传感器融合。
-
跨任务融合: 规划模块(Planning)不仅看预测轨迹,还会通过 Attention 机制直接去“看”上游融合好的 BEV 特征图。这意味着规划器实际上在做感知数据的二次融合,提取它关心的路面细节(如路面坑洼特征)。
-
特点: 融合不再是一次性的步骤,而是贯穿整个网络的信息流 (Information Flow)。
第四阶段:端到端 (End-to-End) —— 原始数据级/隐式融合 (Raw Data / Implicit Fusion)
-
融合层级: 极早期 (Early Fusion) / 隐式融合。
-
传感器要求:
-
输出最原始的 Raw Data。
-
Camera: 原始视频流 (Video Stream),甚至是 RAW 格式。
-
LiDAR/Radar: 原始波形或点云。
-
极高的时空对齐要求: 因为网络内部没有显式的坐标转换模块,必须在输入端通过外参标定将所有像素/点云精确对齐,或者让网络自己学习这种对齐(Soft Alignment)。
-
融合逻辑:
-
所有的模态数据(视频、点云、导航指令、自身速度)在网络的第一层或前几层就被编码(Tokenization)。
-
Transformer 的自注意力机制(Self-Attention)会在海量 Token 之间自动寻找关联。
-
没有显式的“融合算法”: 网络自己学会了“在雨天多看雷达 Token,在白天多看视觉 Token”。
为什么是这级? 相信神经网络的特征提取能力优于人工设计的 BEV 投影或卡尔曼滤波,保留最大信息熵。
第五阶段:VLA (具身智能) —— 多模态语义对齐 (Multimodal Semantic Alignment)
-
融合层级: 语义空间融合 (Semantic Space Fusion)。
-
传感器要求: 数据必须被“Token 化”成大模型能理解的格式。
-
融合逻辑:
-
Image/Video Token: 视觉编码器将画面转为 Token。
-
Text Token: 用户的指令(“去机场”)转为 Token。
-
Action Token: 历史驾驶动作转为 Token。
-
LLM 融合: 在大语言模型的 Embedding 空间里,这些不同模态的 Token 被统一处理。LLM 理解图像中的“红灯” Token 和文本规则中的“停止” Token 具有相同的语义含义。
总结:融合层级演变表
|
算法阶段 |
融合层级 |
输入数据形态 |
融合地点 |
优势 |
|---|---|---|---|---|
|
模块化规则 |
Object Level (后融合) |
目标列表 (List) |
域控 CPU |
算力低,解耦好 |
|
BEV/多任务 |
Feature Level (中融合) |
特征图 (Feature Map) |
BEV Transformer |
互补性强,3D感知准 |
|
UniAD |
Query Level (特征流) |
稀疏向量 (Query) |
全网络 Attention |
任务协同,减少累积误差 |
|
端到端 |
Raw/Token Level (前融合) |
视频流/原始点云 |
神经网络输入层 |
信息无损,拟人化 |
|
VLA |
Semantic Level (语义融合) |
Embedding Token |
LLM 内部 |
具备常识推理能力 |

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 19
19 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)