港中文最新!无需微调即可部署VLA模型
本文提出VLA-Pilot方法,用于提升预训练视觉语言动作(VLA)模型在机器人操作任务中的零样本部署性能。该方法通过推理时策略引导,无需微调即可实现:1)利用多模态大语言模型(MLLM)构建具身策略引导思维链(EPSCoT)模块,推断任务对齐的引导目标;2)设计进化扩散算法优化动作候选,结合扩散模型和进化搜索提升任务对齐度;3)引入迭代引导优化机制进行闭环修正。实验表明,VLA-Pilot在六种
现有问题分析
VLA模型在现实世界机器人操作任务中展现出巨大潜力。然而,预训练的VLA策略在下游部署过程中仍会出现显著的性能下降。尽管微调可以缓解这一问题,但它依赖于高昂的演示数据收集成本和密集型计算,在现实场景中并不实用。这里提出了VLA-Pilot,一种即插即用的推理时策略引导方法,无需额外微调或数据收集,即可实现预训练VLA模型的零样本部署。
在两种不同机器人形态的六个现实世界下游操作任务中对VLA-Pilot进行了评估,涵盖分布内和分布外场景。实验结果表明,VLA-Pilot大幅提升了现成预训练VLA策略的成功率,实现了对多样化任务和机器人形态的稳健零样本泛化。
实验视频和代码:https://rip4kobe.github.io/vla-pilot/。
原文链接:港中文最新!无需微调即可部署VLA模型
背景介绍&创新点
近年来,VLA模型的进步显著提升了机器人操作的泛化能力。通过从大规模演示数据中学习,这些生成式基础策略使机器人能够掌握丰富的技能库。在推理阶段,机器人可以通过从所学技能分布中随机采样动作,执行多样化且符合context 的任务。尽管取得了这些进展,预训练VLA策略在部署到下游任务时往往会出现性能下降。缓解此类部署失败的常用方法是使用任务特定数据进行微调。虽然这种策略有效,但由于数据收集和计算资源成本高昂,且存在损害预训练策略通用能力的风险,在实际应用中并不可行。事实上,此类部署失败并不一定意味着预训练VLA策略无法生成正确行为——期望的行为模式可能已存在于策略的生成分布中,但由于运行时模式选择不当,导致无法可靠执行。
推理时策略引导为预训练生成式机器人策略的模式选择问题提供了一种优雅的解决方案。通过利用外部验证器评估并选择预训练策略提出的与任务对齐的候选动作,可以在无需策略微调的情况下,在运行时有效引导机器人行为。然而,现有方法存在两个关键局限性:首先,这些方法中使用的验证器通常需要额外训练,且由于训练数据分布较窄,泛化能力有限;其次,这些方法仅依赖于从固定候选集中选择动作。但在复杂下游任务中,预训练VLA策略可能无法生成任何与任务context 对齐的候选动作,此时验证器仅通过选择无法恢复成功行为,导致部署时引导失败。
为解决这些局限性,港中文的团队提出了VLA-Pilot:一种无需训练的推理时策略引导方法,可同时提升预训练VLA策略在下游部署中的泛化能力和任务对齐度。
核心思路是利用多模态大型语言模型(MLLM)作为开放世界验证器以增强泛化能力,并采用进化扩散过程作为动作优化器以提高任务对齐度。给定下游任务context ,VLA-Pilot首先通过具身策略引导思维链(EPSCoT)模块,利用多模态大型语言模型的开放世界推理能力推断引导目标奖励,无需训练任务特定验证器,显著提升了对分布外任务的泛化能力;其次,引入新颖的进化扩散算法优化从预训练VLA策略采样的动作候选。与以往基于选择的引导方法不同,进化扩散不仅进行选择,还能将动作候选朝着与任务对齐的分布进化,即使初始候选动作次优或不可行,也能实现有效的策略引导;最后,VLA-Pilot整合了迭代引导优化机制进行闭环修正,提升引导精度和稳健性。
本工作专注于在推理阶段最大化现有VLA模型的效用,而非追求规模日益庞大的数据集和模型架构。实验证明预训练VLA模型已蕴含解决新任务的足够潜在知识,通过所提出的引导机制可以有效提取这些知识并与任务目标对齐。
VLA-Pilot方法详解
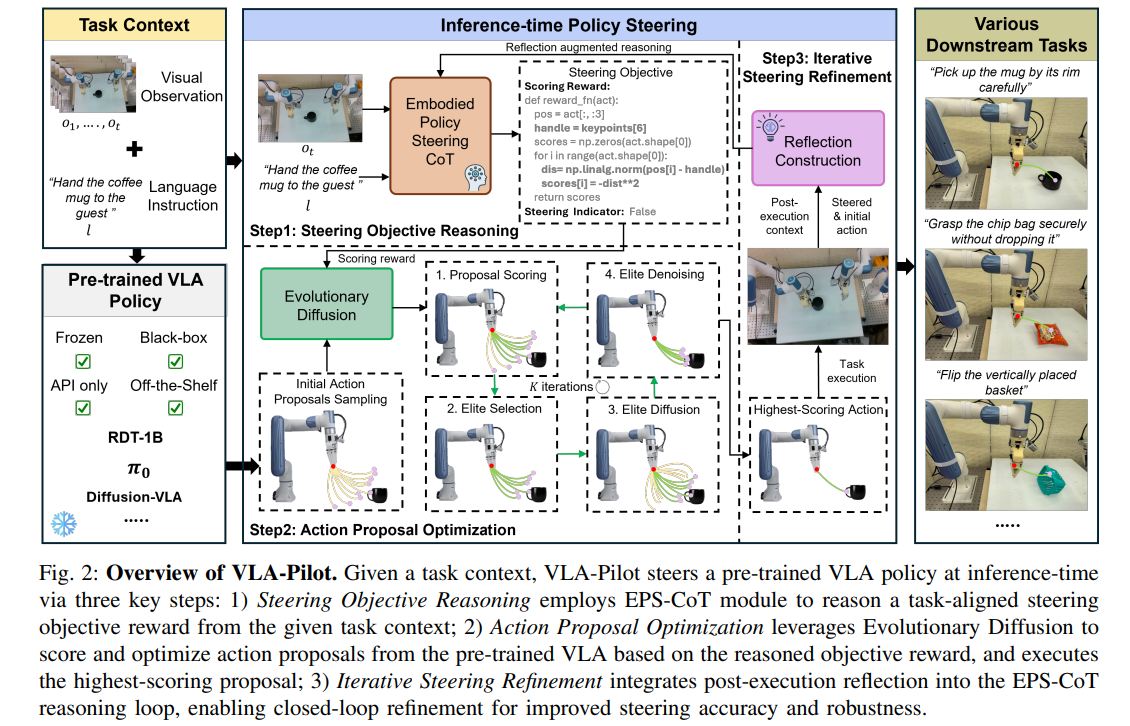
(一)问题表述
给定包含视觉观测 o t o_{t} ot和语言指令 l l l的下游任务context c t = ( o t , l ) c_{t}=(o_{t}, l) ct=(ot,l),本工作研究冻结VLA策略 π v l a ( a t ∣ c t ) \pi_{vla}(a_{t} | c_{t}) πvla(at∣ct)的策略引导问题。目标是在运行时识别与 c t c_{t} ct最对齐的动作候选 a t ∗ a_{t}^{*} at∗:
a t ∗ = a r g max a t ∈ { a t i } i = 1 M R ( a t ; c t ) ( 1 ) a_{t}^{*}=arg \operatorname* {max}_{a_{t} \in\{ a_{t}^{i}\}_{i=1}^{M}} R\left(a_{t} ; c_{t}\right) (1) at∗=argat∈{ati}i=1MmaxR(at;ct)(1)
其中, a t i i = 1 M π v l a ( a t ∣ c t ) {a_{t}^{i}}_{i=1}^{M} ~ \pi_{vla}(a_{t} | c_{t}) atii=1M πvla(at∣ct)表示从预训练VLA策略采样的 M M M个独立同分布动作候选, R ( a t ; c t ) R(a_{t} ; c_{t}) R(at;ct)是衡量动作 a t a_{t} at与任务context c t c_{t} ct对齐程度的引导目标奖励。
解决公式(1)定义的策略引导问题需要两项关键能力:引导目标推理和动作候选优化。前者涉及从context c t c_{t} ct中推断与任务对齐的目标奖励 R ( a t ; c t ) R(a_{t} ; c_{t}) R(at;ct),VLA-Pilot通过EPSCoT模块利用多模态大型语言模型实现开放世界引导目标的推理;后者涉及在预训练VLA策略的动作分布中搜索可行动作,VLA-Pilot通过进化扩散实现:基于引导奖励 R ( a t ; c t ) R(a_{t} ; c_{t}) R(at;ct)迭代评分和变异采样的动作候选,从而有效适应下游任务需求。
(二)引导目标推理
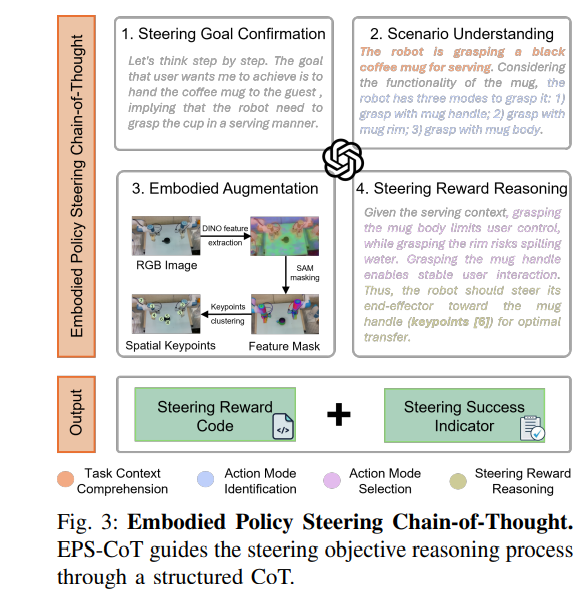
策略引导的第一步是从给定context c t c_{t} ct中推断与任务对齐的引导目标奖励 R ( a t ; c t ) R(a_{t} ; c_{t}) R(at;ct)。本研究的核心见解是:机器人基础模型中的策略引导问题与大型语言模型LLM中的提示工程问题高度相似。因此,受思维链CoT提示在大型语言模型中的有效性启发,这里提出具身策略引导思维链 F E P S − C o T F_{EPS-CoT } FEPS−CoT:一种结构化推理模块,用于生成引导目标奖励:
R ( a t ; c t ) = F E P S − C o T ( Φ M L L M ( c t ) ) R\left(a_{t} ; c_{t}\right)=\mathcal{F}_{EPS-CoT}\left(\Phi_{MLLM}\left(c_{t}\right)\right) R(at;ct)=FEPS−CoT(ΦMLLM(ct))
EPS-CoT将推理过程分解为四个交错阶段:首先是引导目标确认,通过提示多模态大型语言模型重新表述并验证语言指令,确保任务需求与引导目标对齐;其次是场景理解,多模态大型语言模型解释任务context 并基于视觉观测识别潜在动作模式,这一步骤有助于实现对任务场景的高层理解,包括环境可用性、空间关系和任务相关实体;为了在推理过程中进一步融入具身信息,EPS-CoT整合了具身增强:通过视觉基础模型(DINO和SAM)提取机器人末端执行器位置和物体位置的空间关键点,增强推理能力;
最后,基于场景理解和具身信息,EPS-CoT推断与任务对齐的引导目标并生成相应的评分奖励代码。考虑到自然语言指令固有的模糊性和不精确性,这里将奖励实现为非可微黑盒评分函数,这种表述既有效捕捉了语言中模糊但目标导向的特性,又简化了多模态大型语言模型所需的推理过程。
(三)动作候选优化
为提高初始动作候选的任务对齐度,VLA-Pilot引入一种进化扩散算法,协同利用扩散过程的多模态表达能力和进化搜索的黑盒优化能力。该算法首先利用预训练VLA策略采样(M)个动作作为初始动作候选 A 0 A_{0} A0:
A 0 = { a t i } i = 1 M ∼ π v l a ( a t ∣ c t ) , ( 3 ) A^{0}=\left\{a_{t}^{i}\right\}_{i=1}^{M} \sim \pi_{vla}\left(a_{t} | c_{t}\right), (3) A0={ati}i=1M∼πvla(at∣ct),(3)
然后执行进化搜索循环,基于引导目标奖励 R ( a t ; c t ) R(a_{t} ; c_{t}) R(at;ct)迭代评估和变异初始候选集。具体而言,在每个进化迭代步骤k中,对候选集 R ( a t i ; c t ) ∣ a t i ∈ A k i = 1 M {R(a_{t}^{i} ; c_{t}) | a_{t}^{i} \in A^{k}}_{i=1}^{M} R(ati;ct)∣ati∈Aki=1M进行评分,并选择高分精英候选 E k + 1 ⊆ A k E^{k+1} \subseteq A^{k} Ek+1⊆Ak:
q ( α t ) = e x p ( τ R ( a t ; c t ) ) ∑ i = 1 M e x p ( τ R ( a t i ; c t ) ) ( 4 ) q(\alpha _{t})=\frac {exp \left( \tau R(a_{t};c_{t})\right) }{\sum _{i=1}^{M}exp \left( \tau R(a_{t}^{i};c_{t})\right) } (4) q(αt)=∑i=1Mexp(τR(ati;ct))exp(τR(at;ct))(4)
E k + 1 = { a t i ∼ i i d q ( a t ) } i = 1 M , ( 5 ) E^{k+1}=\left\{a_{t}^{i} \stackrel{ iid }{\sim} q\left(a_{t}\right)\right\}_{i=1}^{M},(5) Ek+1={ati∼iidq(at)}i=1M,(5)
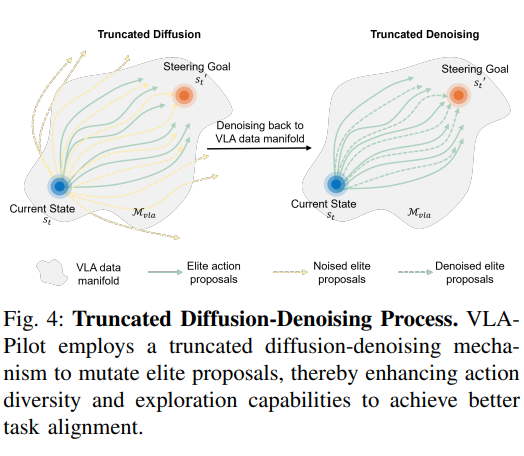
其中 τ \tau τ是控制q尖锐度的可调温度参数。为进一步增强候选多样性并探索与任务对齐的动作,对精英候选 E k + 1 E^{k+1} Ek+1应用截断扩散去噪过程:
首先执行前向扩散过程的前(n)步,获得带噪精英候选 E ˉ k + 1 \bar{E}^{k+1} Eˉk+1:
E ‾ k + 1 = { α ‾ N a t + 1 − α ‾ N ϵ ∣ a t ∈ E k + 1 } , ( 6 ) \overline{E}^{k+1}=\left\{\sqrt{\overline{\alpha}_{N}} a_{t}+\sqrt{1-\overline{\alpha}_{N}} \epsilon | a_{t} \in E^{k+1}\right\}, \quad(6) Ek+1={αNat+1−αNϵ∣at∈Ek+1},(6)
其中 ϵ N ( 0 , 1 ) \epsilon ~ N(0,1) ϵ N(0,1)。然而,由于噪声的随机性,直接应用前向扩散可能导致 E ˉ k + 1 \bar{E}^{k+1} Eˉk+1偏离原始VLA分布,因此后续执行反向扩散过程的最后n步,利用预训练VLA策略的噪声预测器对 E k + 1 E^{k+1} Ek+1进行去噪,得到用于传播的优化候选 A k + 1 A^{k+1} Ak+1,确保其位于原始数据流形内:
A k + 1 = { a t ‾ ∼ π v l a ( a t ‾ ∣ c t ) ∣ a t ‾ ∈ E ‾ k + 1 } . ( 7 ) A^{k+1}=\left\{ \overline {a_{t}} \sim \pi _{vla}(\overline {a_{t}}| c_{t})| \overline {a_{t}}\in \overline {E}^{k+1}\right\} . (7) Ak+1={at∼πvla(at∣ct)∣at∈Ek+1}.(7)
最后,进化搜索循环完成后,选择与引导目标最对齐的最高分精英动作执行。
(四)迭代引导优化
本研究还引入迭代引导优化机制,实现引导目标和结果动作的闭环修正。在原始EPS-CoT推理模块中增加反思步骤,通过四个关键组件提示多模态大型语言模型:初始动作候选 a 0 a_{0} a0、执行动作候选 a t ∗ a_{t}^{*} at∗、执行后任务context c ˉ t \bar{c}_{t} cˉt以及前一EPS-CoT步骤的推理历史 H t H_{t} Ht。基于这种增强反思的输入,多模态大型语言模型作为自我批判者优化引导奖励 R ( a t i ; c t ) R(a_{t}^{i} ; c_{t}) R(ati;ct)并生成引导成功指示器s:
s = F E P S − C o T ( Φ M L L M ( a 0 , a t ∗ , c ‾ t , H t ) ) ( 8 ) s=\mathcal {F}_{EPS-CoT}\left( \Phi _{MLLM}(a_{0},a_{t}^{* },\overline {c}_{t},\mathcal {H}_{t})\right) (8) s=FEPS−CoT(ΦMLLM(a0,at∗,ct,Ht))(8)
如果多模态大型语言模型检测到推断引导奖励存在不一致,则重新生成新奖励;类似地,如果执行动作与任务context 不对齐(即 s = F a l s e s= False s=False),VLA-Pilot继续引导过程直至任务完成。这种闭环优化确保了引导过程的精度和context 相关性的提升。

实验对比分析
本研究通过大量真实机器人实验研究以下问题:1)VLA-Pilot能否提升现成预训练VLA策略的下游操作性能?2)VLA-Pilot与最先进的策略引导基线方法相比表现如何?3)VLA-Pilot与VLA策略的直接微调相比表现如何?4)VLA-Pilot能否实现跨形态泛化?
(一)实验设置
实验使用双臂系统DOBOT X-Trainer,该系统包含两个配备1自由度夹持器的6自由度Nova2机械臂,采用三个Intel RealSense相机捕捉RGB图像观测。
实现细节:多模态大型语言模型采用GPT-4o,温度参数设为0.2,最大输出长度为1000个token;进化扩散方面,采样32个动作候选作为初始种群,执行10步进化搜索以迭代优化动作,在推理过程中平衡搜索多样性和计算效率。
基线方法,这里将VLA-Pilot与六种基线方法进行比较:
- Diffusion-VLA(DiVLA):一种20亿参数的预训练VLA策略,整合自回归与扩散模型;
- RDT-1B:一种基于扩散的VLA策略,适用于通用机器人操作;
- V-GPS:一种推理时VLA策略引导方法,利用训练后的基于价值函数的验证器选择最优动作;
- FOREWARN:一种视觉语言模型协作的策略引导方法,利用微调后的视觉语言模型作为验证器进行动作排序和选择;
- DiVLA-finetune:在50个任务演示上微调的DiVLA策略;
- RDT-1B-finetune:在50个任务演示上微调的RDT-1B策略。
任务设置:实验采用六个下游任务,包括四个简单单臂任务和两个复杂双臂操作任务。为评估泛化能力,设计了两种任务场景:分布内(ID)和分布外(OOD),具体取决于基线方法使用的外部验证器在训练过程中是否遇到过该场景。每个场景提供五个任务特定的语言指令,用于评估每种方法的性能。
评估指标:采用两项定量指标评估所提方法:操作成功率(MSR)——引导后机器人动作成功完成下游操作任务的比例;引导目标对齐度(SOA)——所选动作候选与预期引导目标对齐的比例。每种方法和任务场景执行20次试验,报告平均性能。
(二)实验结果

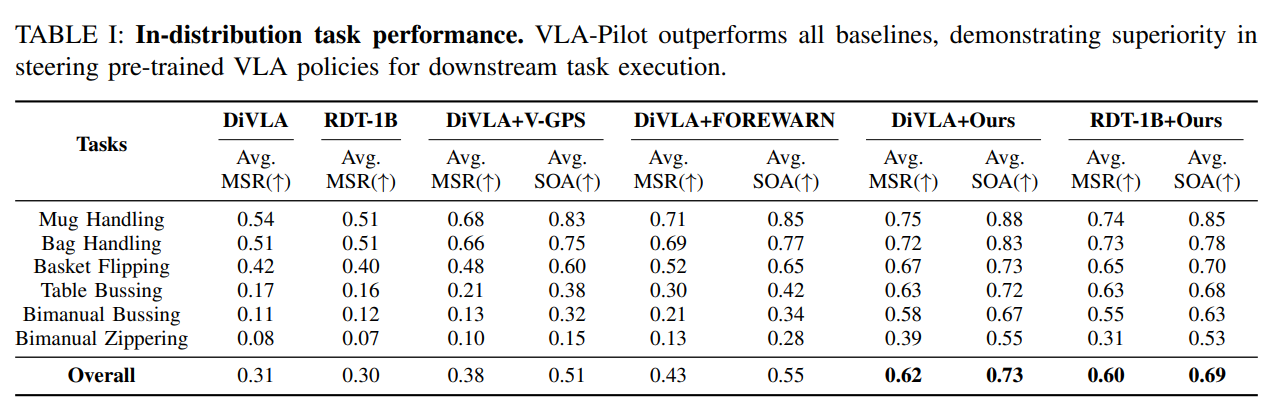
1)分布内任务性能
VLA-Pilot优于所有基线方法,在引导预训练VLA策略执行下游任务方面表现出优越性。
2)分布外任务性能
与基线方法相比,VLA-Pilot对未见过的分布外任务展现出稳健的泛化能力。
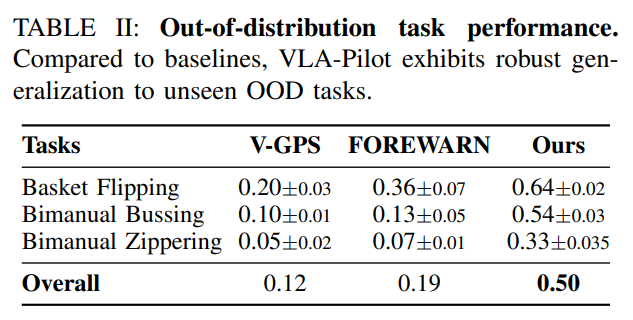
3)跨形态泛化性能
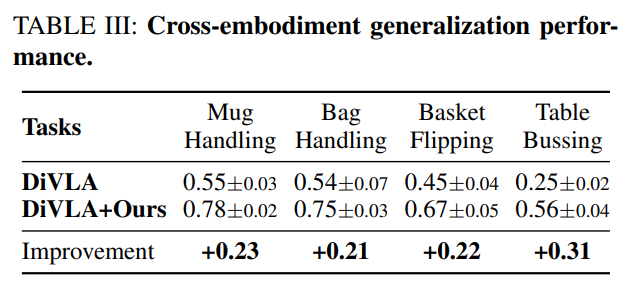
4)其它分析
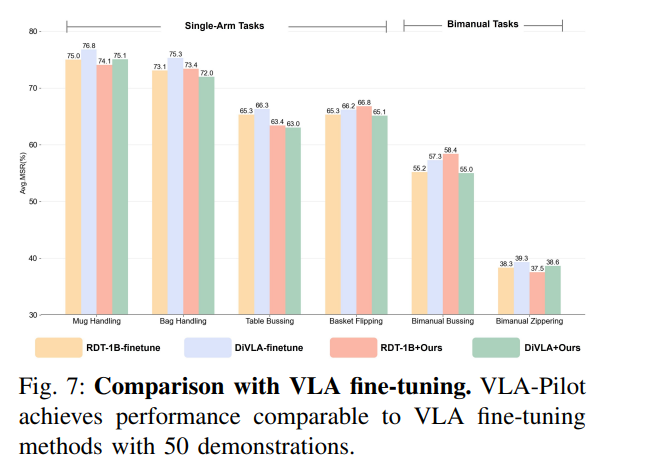
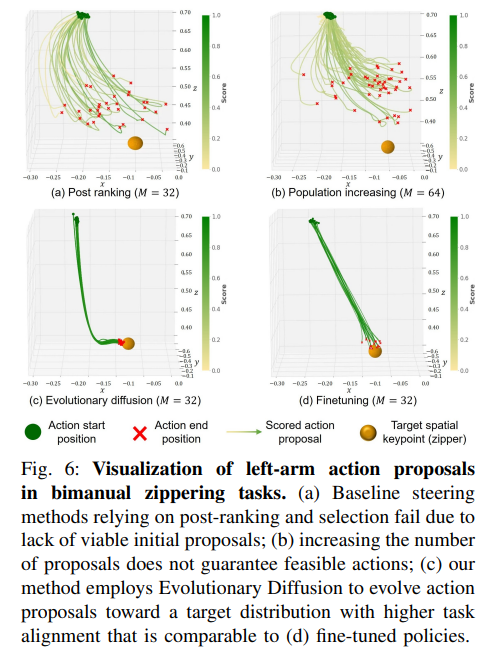
(三)更多分析与讨论
实验结果表明,所提出的VLA-Pilot能够在无需任何微调的情况下,在推理时有效引导预训练VLA策略。与现有方法相比,VLA-Pilot具有两项关键优势:首先,采用多模态大型语言模型作为开放世界外部验证器,无需训练任务特定验证器,增强了对分布外任务的泛化能力;其次,整合进化扩散将高分动作候选朝着与任务对齐的解决方案进化,缓解了以往仅依赖静态选择的方法的关键局限性——当初始候选缺乏可行动作时往往会失败。此外,实验表明VLA-Pilot实现了与使用50个专家演示的监督微调相当的性能。总体而言,VLA-Pilot为预训练VLA策略的推理时控制提供了新的见解,有助于开发更具可扩展性、数据效率和适应性的机器人操作系统。
参考
[1] Towards Deploying VLA without Fine-Tuning: Plug-and-Play Inference-Time VLA Policy Steering via Embodied Evolutionary Diffusion.
具身求职内推来啦
国内最大的具身智能全栈学习社区来啦!
推荐阅读
从零部署π0,π0.5!好用,高性价比!面向具身科研领域打造的轻量级机械臂
工业级真机教程+VLA算法实战(pi0/pi0.5/GR00T/世界模型等)
具身智能算法与落地平台来啦!国内首个面向科研及工业的全栈具身智能机械臂
VLA/VLA+触觉/VLA+RL/具身世界模型等!具身大脑+小脑算法与实战全栈路线来啦~
MuJoCo具身智能实战:从零基础到强化学习与Sim2Real
Diffusion Policy在具身智能领域是怎么应用的?为什么如此重要?
1v1 科研论文辅导来啦!

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 13
13 0
0- 0



 已为社区贡献45条内容
已为社区贡献45条内容

所有评论(0)