VLN 领域首个双系统基础模型,三大基准 SOTA,重新定义导航技术上限!
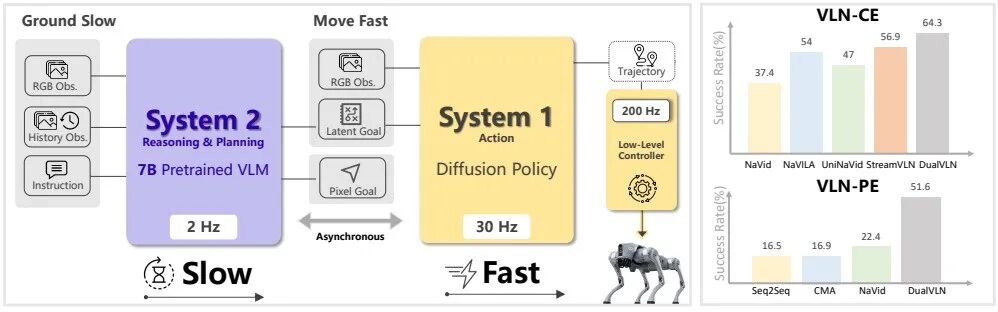
这种异步推理实现了连续且流畅的导航过程。这是一个轻量级的扩散Transformer策略,以高达 30 Hz 的频率运行,接收系统2输出的像素目标及其隐含的语义特征,结合当前高频RGB图像,生成平滑、连续、避障的轨迹。这是一个基于 Qwen-VL-2.5 的全局规划器,以约 2 Hz 的频率运行,负责理解指令、观察环境,并预测一个像素级目标点,作为中期导航的视觉路标。:为此,模型使用一个轻量模块,将
目录
System 2 的核心功能——从3D路径到2D路标的自动生成
System 1 的核心功能——将“目标点”变成“平滑轨迹”
对于视觉语言导航领域,一个长期存在的基本矛盾始终难以解决:
强大的推理能力需要“慢思考”,而流畅的导航行动却需要“快反应”。
这一矛盾直接转化为行业困境:
-
大模型虽能理解复杂指令,但其计算架构无法支撑高频实时控制;
-
而轻量化策略虽能快速响应,却又缺乏对任务语义的深层理解与环境泛化能力。
近日,来自上海人工智能实验室的研究团队提出了 DualVLN,以 “慢思考、快行动” 的双系统架构破局,改变了过去端到端模型的工作方式;
更以 VLN 领域首个双系统基础模型的定位,兼具通用性与强迁移性,可直接部署于轮式、四足、人形等多种机器人平台。

当前主流 VLN 方案仍普遍采用端到端紧耦合架构:
模型直接接收视觉图像与语言指令输入,输出 “前进 0.25 米”“左转 15°” 等离散化瞬时动作指令。
这种设计虽简化了模型流程,却在实际部署中暴露了三大核心瓶颈:
-
动作碎片化:每一步都需要调用大模型,导致机器人动作不连贯、不自然;
-
响应延迟高:大模型推理速度慢,无法实现高频控制;
-
缺乏层次协调:语义理解、全局规划和局部避障耦合在一起,难以应对动态变化。
这就像开车时,每秒钟都要重新规划路线,根本无法应对突发的行人或车辆。
▲双系统框架将高层次推理与低层次控制进行解耦。这种异步推理实现了连续且流畅的导航过程。DualVLN在VLN-CE和VLN-PE领域开创了新的前沿水平,并在实际部署中展现出强大的泛化能力。
这种设计严重限制了机器人在真实场景中的部署能力。于是,首个支持长视程导航的异步双系统就此提出。

DualVLN的核心思想是解耦:将高级语义理解与低级轨迹执行分开,形成两个互补的系统。
系统2:慢思考的“大脑”
-
专注于 “慢接地”(mid-term waypoint 预测、视角调整)
这是一个基于 Qwen-VL-2.5 的全局规划器,以约 2 Hz 的频率运行,负责理解指令、观察环境,并预测一个像素级目标点,作为中期导航的视觉路标。
这个系统还会自主决定是否调整视角,比如转头或低头查看地面:“左转 / 右转 15°、抬头 / 低头 15°” 等离散动作,最多支持 4 次连续视角调整。
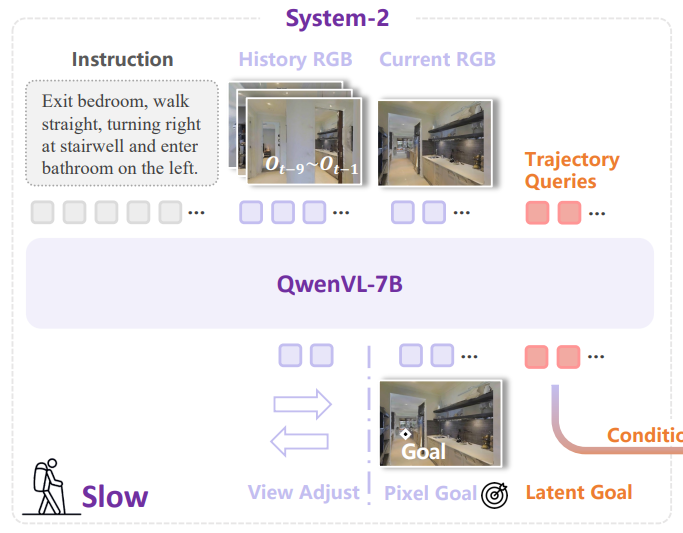
▲系统2接收一系列以自我为中心的图像序列以及用于预测视调整操作或图像中下一个导航目标点的 2D 像素坐标的指令作为输入。
系统1:快行动的“小脑”
-
专注于 “快执行”(高频轨迹生成、动态避障)
这是一个轻量级的扩散Transformer策略,以高达 30 Hz 的频率运行,接收系统2输出的像素目标及其隐含的语义特征,结合当前高频RGB图像,生成平滑、连续、避障的轨迹。
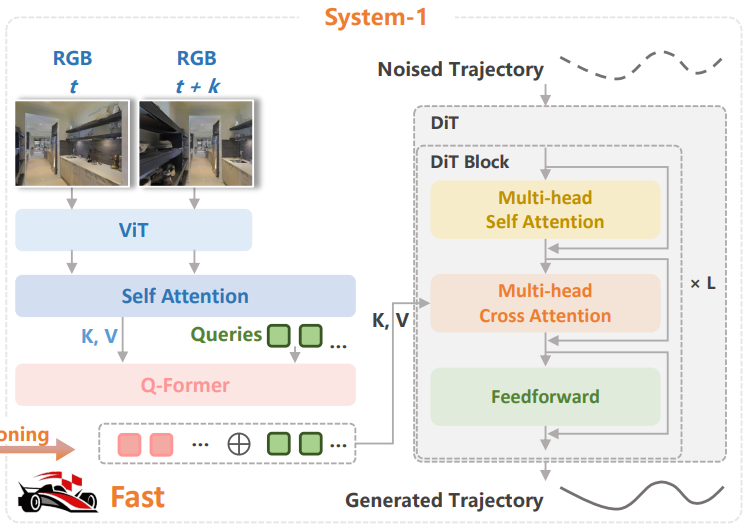
▲系统1同时接收隐式目标嵌入和高频 RGB 输入,随后通过基于扩散的策略生成机器人需遵循的连续轨迹。
于是,系统2每0.5秒规划一个新目标,系统1每0.03秒更新一次轨迹,实现“大脑想一步,小脑走十步”的高效控制。

System 2 的核心功能——从3D路径到2D路标的自动生成
但是,传统 VLM 本身不具备导航规划能力,如何为其赋予这一核心能力?
关键突破在于将复杂的 3D 导航任务,转化为直观的 2D 像素级目标定位 ——
DualVLN 将导航规划重构为一个 “最远像素目标 grounding”问题。
训练数据并非手工标注,而是通过三维到二维投影,自动生成:
-
在仿真环境中,已有机器人行走的3D轨迹;
-
将未来一段轨迹上的点,投影到当前机器人第一视角的2D图像上;
-
利用深度信息过滤:只保留在当前视角下实际可见(未被遮挡)的点;
-
从这些可见点中,选择最远的一个点作为当前时刻的“像素目标”。
这样,系统2的学习目标就变成了:
根据当前看到的图像和语言指令,在图中指出下一步应该走向哪个像素位置。
▲DualVLN 的双系统框架,将高层推理与低层控制解耦
然而,直接预测可能失败——
如果机器人正对着墙,目标点根本不在视野里。
为此,系统2被赋予一项智能:自主决定何时调整视角。
如果模型判断当前视角不佳,会输出如“左转15°”、“低头15°”等离散动作,主动寻找更佳视野。
这一机制模仿了人类在陌生环境中寻路时的自然行为:先环顾四周,看清环境,再决定走向哪里。
System 1 的核心功能——将“目标点”变成“平滑轨迹”
如何将 System 2 输出的 “目标点”(像素目标 + 语义意图),转化为机器人底盘可直接执行的 “平滑连续轨迹”(32个密集路径点)?
这便是系统1的主要目的。
它采用 “条件扩散模型” 架构,融合 “低频语义条件” 与 “高频视觉条件”,解决了 “高层意图与实时环境的适配问题”——
确保轨迹生成既符合导航目标,又能应对动态变化。
-
低频语义条件(来自系统2)
来源:系统2在生成像素目标的同时,其内部隐藏状态蕴含了丰富的任务语义(例如“去厨房”、“绕过桌子”)。
提取机制:DualVLN设计了 4个可学习的潜在查询向量,像“提问”一样从系统2的隐藏状态中提取出与当前导航任务最相关的语义特征。
作用:这些特征作为高级指引,告诉系统1“意图是什么”。

▲System 1 对像素目标偏差的鲁棒性—— 当 System 2 输出的像素目标存在 “方向正确但位置偏差(如靠近障碍物)” 时,System 1 仍能通过实时 RGB 图像修正轨迹,生成物理可行的路径;
-
高频视觉条件(来自当前实时画面)
输入特征:系统1以30Hz频率接收最新的RGB图像。
核心挑战:由于系统2运行较慢(0.5秒一次),系统1必须能理解“过时”的语义目标与“最新”视觉画面之间的关系。
方法:为此,模型使用一个轻量模块,将系统2输出目标时的旧图像特征与当前最新图像特征进行融合,从而动态理解机器人已走了多远、环境发生了何变化。

此外,为了更真实地评估导航模型在动态环境中的表现,团队构建了 Social-VLN 基准——
-
在原有 VLN-CE 环境中加入了动态行走的人形机器人,并沿任务路径放置,大大增加了交互概率;
-
除了传统指标,还首次引入了 Human Collision Rate 来量化与行人的不安全交互次数。

▲Social-VLN 基准的典型场景示意图

仿真测试
仿真实验聚焦三大核心基准(静态、物理真实、动态社交),验证 DualVLN 的规划精度、物理适配性与动态环境应对能力,实验平台基于 Habitat 模拟器。
在 VLN-CE 和 VLN-PE 两大仿真基准上,DualVLN 均取得了最佳成绩,尤其在 R2R 和 RxR 的未见场景中,成功率显著领先于所有基线模型。

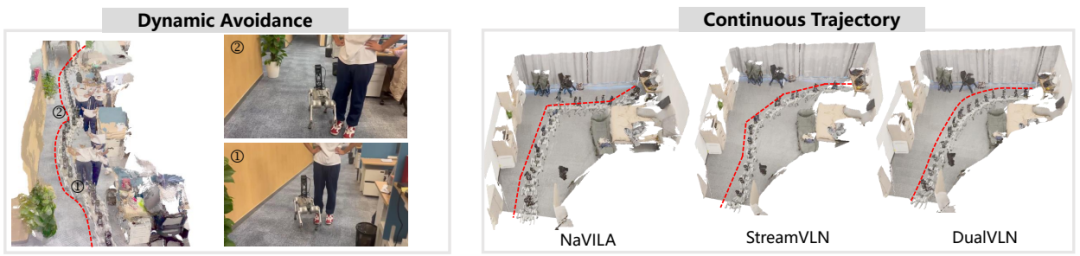
▲基线比较。左中右:NaVILA、DualVLN、StreamVLN
真机实验
机器人平台:轮式(Turtlebot4)、四足(Unitree Go2)、人形(Unitree G1),均仅搭载 Intel RealSense D455 单目 RGB 相机;

DualVLN 在办公室、食堂、街道、便利店等多种场景中均表现出色,能够规划平滑路径、避开动态行人、处理楼梯等复杂地形。

▲零样本迁移至长视程导航-户外自主探索

DualVLN 的实践印证了一个在具身智能领域逐渐清晰的认知范式:
将分层认知与实时控制解耦,是构建强泛化、高可靠导航系统的有效路径。
重新定义了 VLN 领域快慢系统的协作方式,通过 "慢思考、快行动" 的协同执行架构,解决了传统端到端模型的三大痛点:
语义理解与实时控制的矛盾、动作碎片化、动态环境适应性差。
这一架构不仅为视觉语言导航提供了新的基础模型方案,其所体现的“慢规划-快执行”协同机制,也为更广泛的具身决策任务提供了可扩展的框架参考(如机器人操作、交互式导航乃至通用移动操作)——
如何进一步优化跨层表征对齐、提升系统在极端扰动下的鲁棒性,以及实现更高效的仿真到现实迁移,仍是值得持续探索的方向。
Ref
论文题目:GROUND SLOW, MOVE FAST: A DUAL-SYSTEM FOUNDATION MODEL FOR GENERALIZABLE VISIONAND-LANGUAGE NAVIGATION
论文地址:https://arxiv.org/pdf/2512.08186v1
论文作者:Meng Wei, Chenyang Wan, Jiaqi Peng, Xiqian Yu, Yuqiang Yang, Delin Feng, Wenzhe Cai, Chenming Zhu, Tai Wang, Jiangmiao Pang, Xihui Liu
项目主页:https://internrobotics.github.io/internvla-n1-dualvln.github.io/
代码地址:https://github.com/InternRobotics/InternNav

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 11
11 0
0- 0



 已为社区贡献45条内容
已为社区贡献45条内容

所有评论(0)