华科&清华最新DeepThinkVLA:如何让模型 “会思考、能落地”?
机器人操作中“思考先于行动”是解决端到端策略数据依赖的关键,但现有视觉-语言-动作(VLA)模型面临核心矛盾:单一解码器需同时处理序列化推理与高维并行动作,导致控制精度下降与因果关联缺失。华中科技大学与清华大学团队提出DeepThinkVLA,通过混合注意力解码器(自回归推理+并行动作生成)与两阶段训练(监督微调+强化学习),实现推理与动作的高效协同。在LIBERO基准测试中,模型以97.0%成功
在机器人操作领域,“思考先于行动”(Think Before Acting)是突破端到端政策数据饥饿性的关键方向,但现有视觉 - 语言 - 动作(VLA)模型始终面临核心矛盾:单一自回归解码器既要处理序列化推理,又要生成高维并行动作,导致运动控制精度下降、推理与动作缺乏强因果关联。
华中科技大学、清华大学等团队联合提出的 DeepThinkVLA,通过 “混合注意力解码器 + 两阶段训练 pipeline” 的创新设计,完美化解这一冲突——既让模型具备连贯推理能力,又保障动作生成的高效与精准,最终在 LIBERO 基准测试中实现 97.0% 的任务成功率,树立了 VLA 模型的性能新标杆。
DeepThinkVLA 官方代码库:https://github.com/wadeKeith/DeepThinkVLA
为什么 VLA 模型需要 “重构推理 - 动作架构”?
当前 VLA 方案陷入 “双重瓶颈”:要么采用端到端直接映射,依赖海量高质量演示数据;要么虽引入思维链(CoT)推理,但架构与训练策略脱节,无法实现推理与动作的有效协同,核心问题可归结为 “模态适配冲突” 与 “训练目标偏差”:
| 方案类型 | 代表思路 | 核心缺陷 |
|---|---|---|
| 传统端到端模型 | 感知 - 动作直接映射 | 1. 数据需求极大,泛化能力弱;2. 缺乏推理机制,面对复杂任务易失败 |
| 现有 CoT 增强模型 | 单一自回归解码器 + 监督微调(SFT) | 1. 推理(序列化语言)与动作(并行化高维向量)模态冲突,降低运动控制精度;2. 仅依赖 SFT 导致推理 “死记硬背”,与动作缺乏因果关联;3. 动作生成 latency 高,难以支撑大规模强化学习 |
这些方案忽略了一个关键:VLA 模型的推理与动作具有本质不同的模态属性——推理需遵循语言的时序逻辑,而动作需兼顾维度并行性与低延迟要求。DeepThinkVLA 正是抓住这一核心,通过 “架构适配模态特性 + 训练对齐任务目标” 的双轮驱动,实现了推理与动作的深度协同。
DeepThinkVLA:如何让模型 “会思考、能落地”?
DeepThinkVLA 的核心设计可概括为 “以混合架构解决模态冲突,以两阶段训练强化因果关联,串联‘基础推理学习 - 推理 - 动作对齐 - 高效任务执行’ ”。它既尊重推理与动作的本质差异,又通过强化学习让推理真正服务于任务成功,具体分为三大核心组件与两大关键创新:
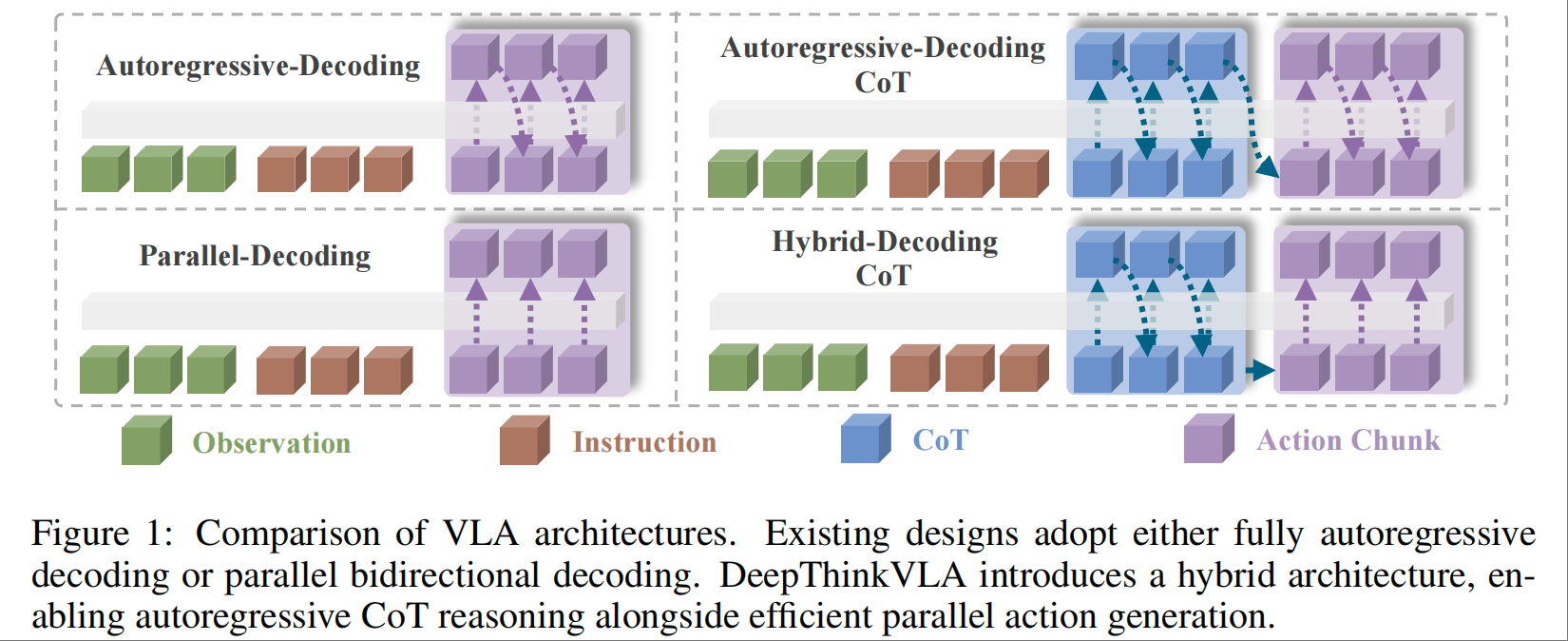
核心组件 1:混合注意力解码器——破解模态冲突的 “架构核心”
针对推理与动作的模态差异,DeepThinkVLA 设计了动态切换的混合注意力机制,在单一解码器中实现两种模态的高效处理:
推理生成阶段(CoT Generation)
- 采用自回归因果注意力(Causal Attention),遵循语言的序列化特性,每一步推理 token 基于前文生成,保障思维链的连贯性;
- 利用 VLM backbone 已有的语义与推理能力,通过少量具身 CoT 数据微调即可适配机器人领域。
动作生成阶段(Action Generation)
- 切换为双向注意力(Bidirectional Attention),支持高维动作向量的并行解码,同时处理末端执行器的平移、旋转等多个维度;
- 大幅降低推理 latency,为后续大规模强化学习的高速 rollout 提供可能,解决传统自回归模型动作生成缓慢的痛点。
核心组件 2:两阶段训练 pipeline—— 强化因果关联的 “训练关键”
通过 “监督微调(SFT)+ 强化学习(RL)” 的组合,既让模型 “会思考”,又让思考 “能落地”:
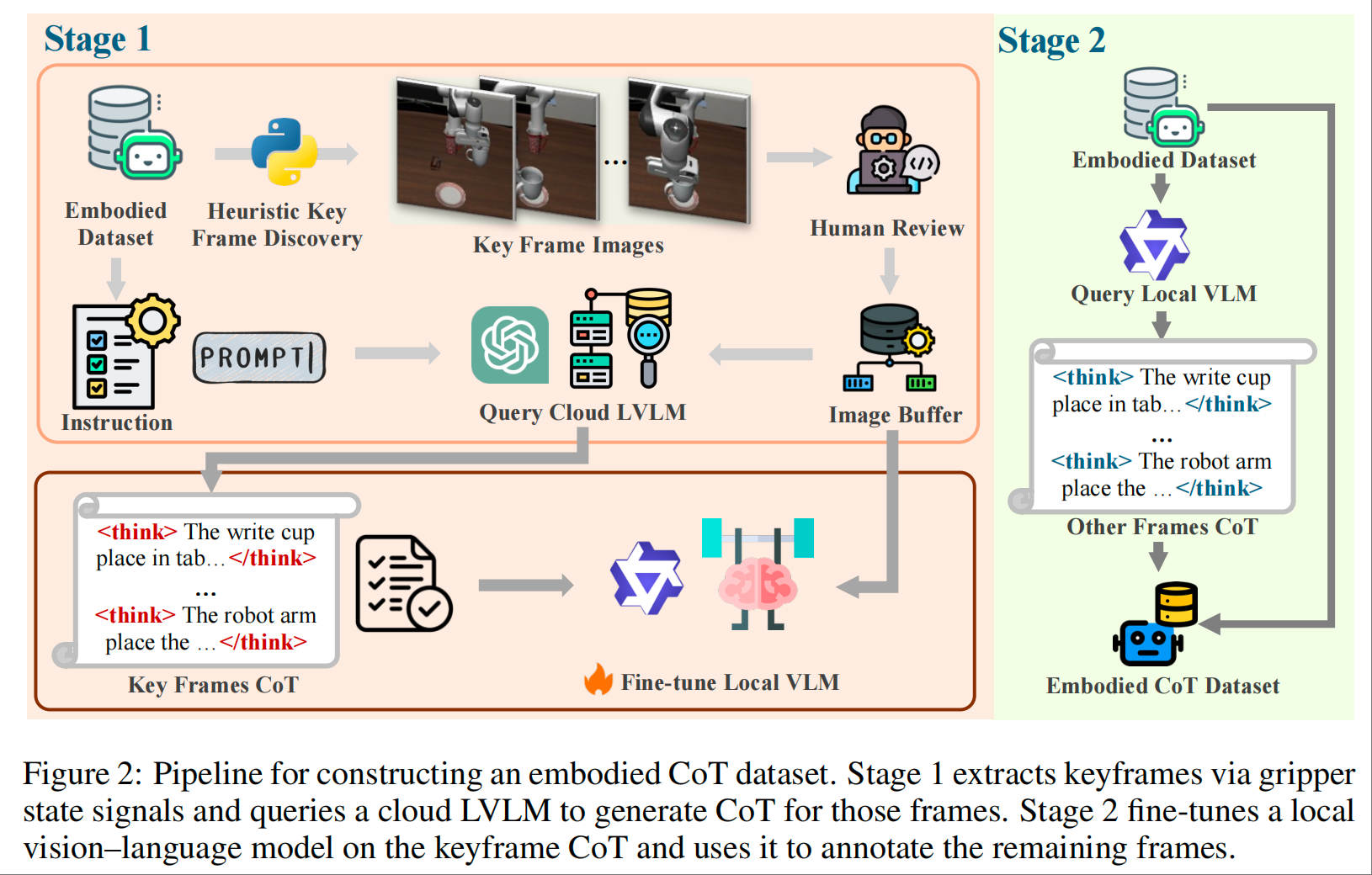
阶段 1:SFT 冷启动——构建基础推理能力
-
数据准备:针对现有具身数据集缺乏 CoT 标注的问题,设计两阶段数据增强 pipeline:
关键帧提取:通过检测夹爪状态变化,识别子任务边界,获取关键帧;
标注生成:先用云端强 VLM 为关键帧生成高质量 CoT 标注,再微调本地小 VLM 为中间帧自动标注,通过 schema 检查保障数据一致性;
-
训练目标:采用 token 级交叉熵损失,让模型学习 “观察 - 指令 - 推理 - 动作” 的基础映射,掌握核心推理逻辑。
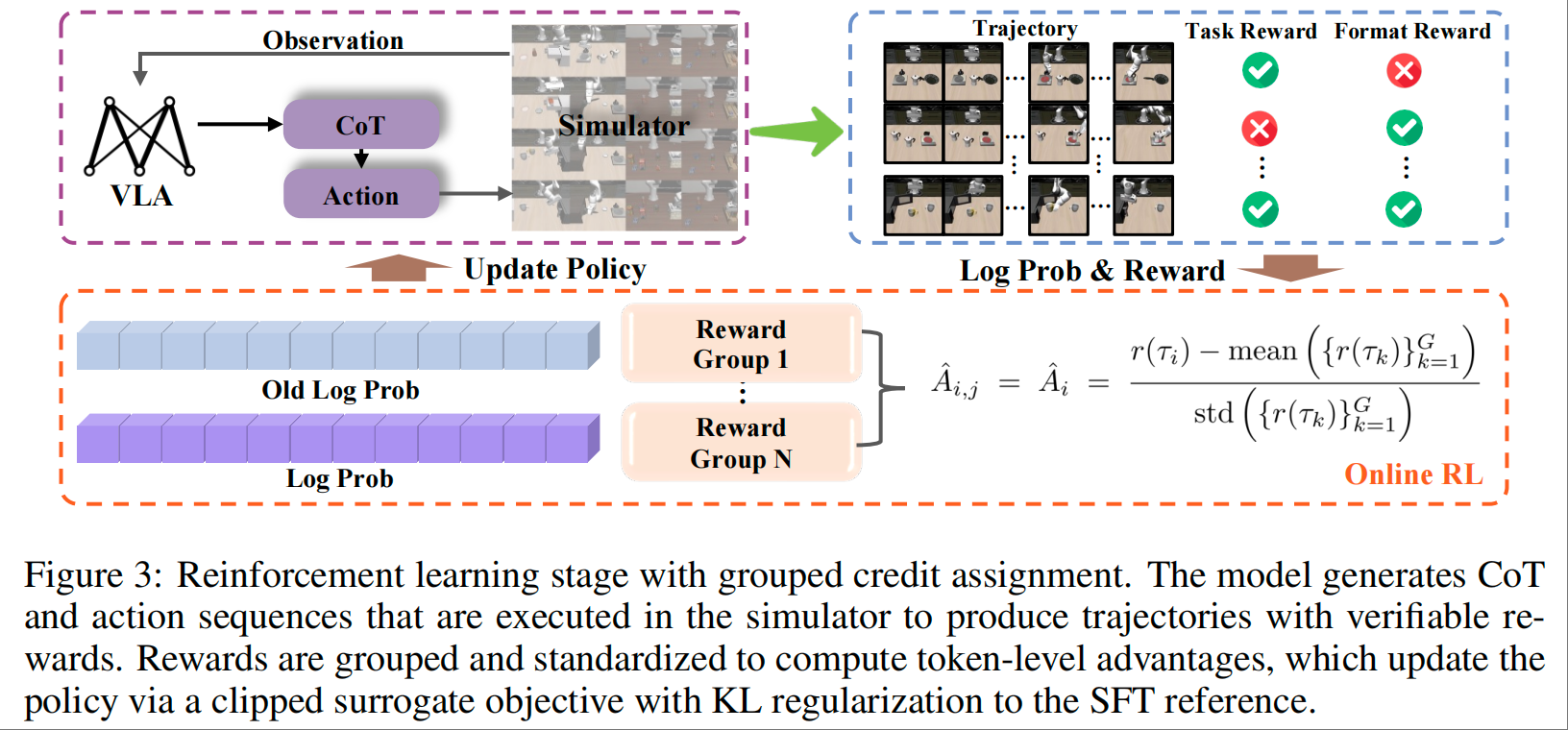
阶段 2:强化学习对齐——让推理服务于任务成功
-
奖励设计:采用基于结果的稀疏奖励(Task-Success Reward)+ 格式正则化奖励(Format Reward),仅关注任务最终成功与否,避免中间推理语义的干扰;
-
信用分配:借鉴 GRPO 策略,将轨迹奖励标准化后分配到每个 token,鼓励生成对任务成功更有效的推理 - 动作序列;
-
正则化机制:引入 KL 散度惩罚,避免模型遗忘 SFT 阶段学到的基础推理能力,保障训练稳定性。
核心组件 3:具身 CoT 数据集——支撑基础训练的 “数据底座”
通过两阶段标注 pipeline 构建高质量数据集,包含 273,465 个标注帧,覆盖 LIBERO 基准的各类任务;
- 数据特性:每个样本包含 “视觉观察(V)- 任务指令(L)- 思维链(R)- 动作(A)” 完整序列,确保 SFT 阶段的全面监督;
- 标注优势:兼顾质量与效率,关键帧由强 VLM 生成高精度标注,中间帧由本地模型高效补全,平衡标注成本与数据质量。
两大关键创新:从 “能思考” 到 “善执行”
创新 1:推理 - 动作的概率分解
将传统的 “观察 - 指令→动作” 直接映射,分解为 “观察 - 指令→推理” 与 “观察 - 指令 - 推理→动作” 两步:
- 优势 1:推理学习更高效,复用 VLM 已有能力,无需海量数据;
- 优势 2:动作学习更简单,推理作为显式规划,将 “一对多” 的模糊映射转化为 “推理步骤→动作” 的明确映射,降低学习难度。
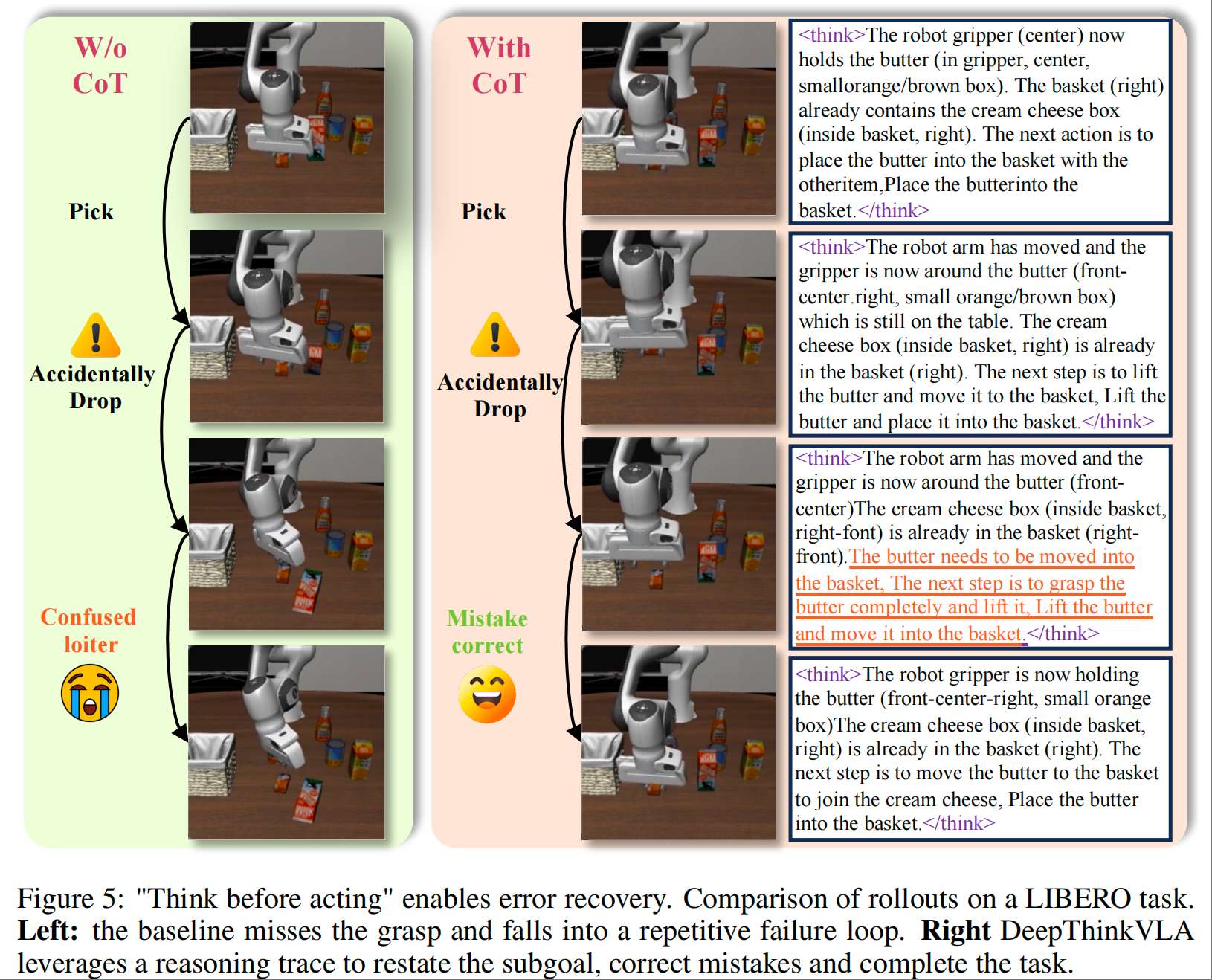
创新 2:错误恢复机制
通过思维链的显式引导,模型在执行错误时能重新明确子目标,实现自我修正。例如在物体抓取失败后,推理会提示 “需要重新抓取目标并放入篮筐”,引导机器人再次尝试,而传统模型易陷入重复失败循环。
实验结果:性能与鲁棒性双突破
DeepThinkVLA 在 LIBERO 基准的四大任务套件(Object、Spatial、Goal、Long)中开展全面评估,对比 autoregressive、diffusion、parallel-decoding 等主流方案,核心结论可概括为 “架构决定基础性能,RL 实现上限突破,推理赋能鲁棒执行”:
核心性能:刷新 SOTA 记录
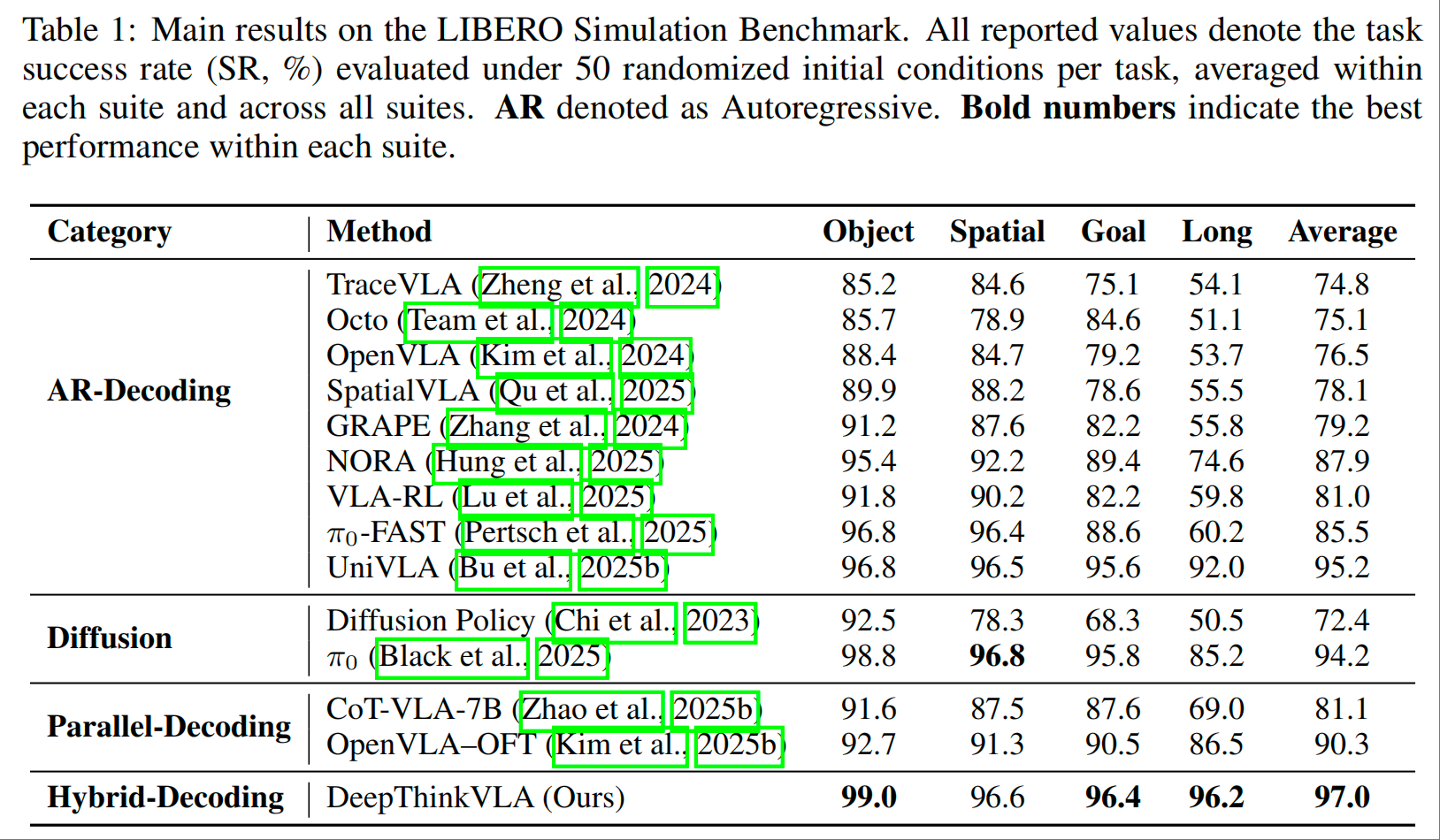
- 平均成功率达 97.0%,超越所有基线模型,其中 Object 任务成功率 99.0%、Goal 任务 96.4%,Long 长程任务 96.2%;
- 相较于顶级自回归模型 UniVLA(平均 95.2%),在 Object、Spatial、Goal 任务中表现更优,鲁棒性更强;
- 相较于扩散模型 π₀(平均 94.2%),在 Object、Goal 任务及整体性能上形成显著优势。
ablation 实验:验证核心设计有效性
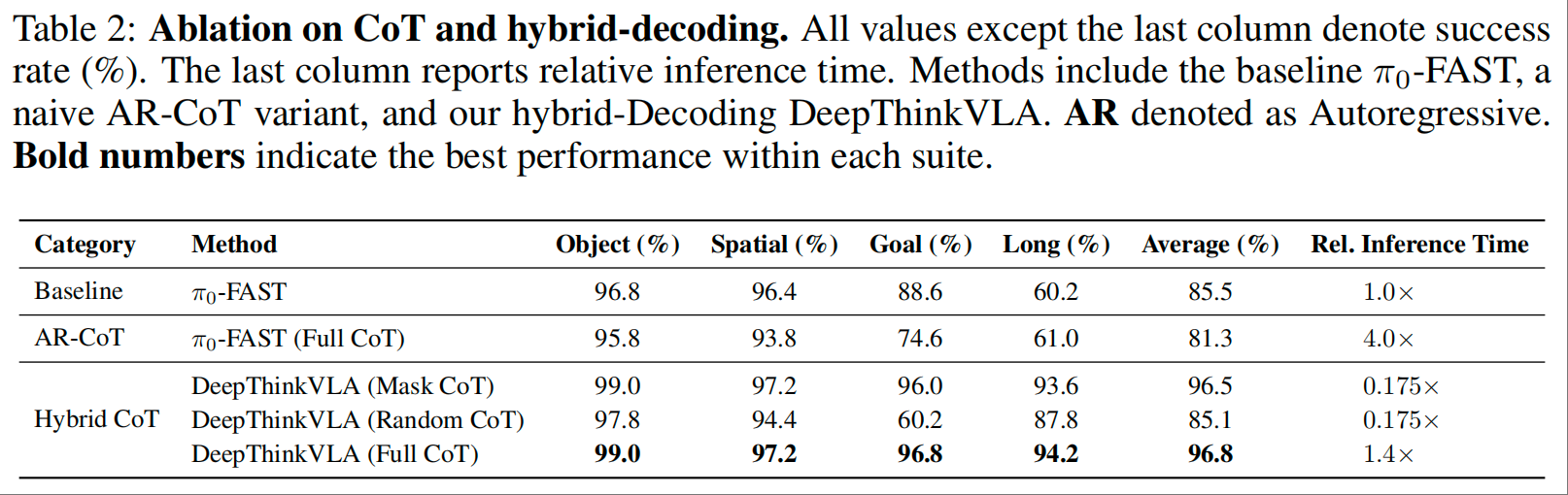
关键发现:推理的双重价值
-
训练价值:即使推理在推理时被屏蔽(Mask CoT),模型仍保持 96.5% 的高成功率,说明 CoT 训练能增强模型内部表征;
-
推理价值:若推理语义混乱(Random CoT),成功率骤降至 85.1%,说明推理的语义连贯性是引导动作执行的关键。
关键结论与未来方向
DeepThinkVLA 的价值,在于为 VLA 模型提供了 “架构适配模态特性,训练对齐任务目标” 的清晰路径,核心启示与未来方向如下:
核心结论
- 架构是基础:解决推理与动作的模态冲突,不能依赖单一解码器,混合注意力设计是实现 “思考先于行动” 的前提;
- 训练是关键:仅靠 SFT 无法建立推理与动作的强因果关联,强化学习通过任务成功奖励,让推理从 “描述性” 变为 “行动性”;
- 推理有双重作用:既在训练中增强表征学习,又在推理时提供显式规划,提升任务鲁棒性与错误恢复能力。
未来方向
- 多模态扩展:整合触觉、力觉等传感器数据,提升复杂操作场景的适应性;
- 任务泛化:扩展至更复杂的长程协作任务,探索推理链的层级化设计;
- 效率优化:进一步降低模型参数与推理 latency,推动真实机器人的部署;
- 数据扩展:构建更大规模、更多场景的具身 CoT 数据集,提升模型泛化能力。
总结
DeepThinkVLA 的出现,打破了 “VLA 模型要么推理与动作脱节,要么性能与效率失衡” 的僵局——它没有陷入 “单一模块优化” 的误区,而是通过 “混合架构化解模态冲突 + 两阶段训练强化因果关联” 的简洁逻辑,让模型真正实现 “会思考、能落地”。对于追求高精度、高鲁棒性的机器人操作任务(如家庭服务、工业装配),这种 “以推理赋能动作” 的方案,为具身智能技术从实验室走向真实世界提供了极具参考价值的范式。
具身求职内推来啦
国内最大的具身智能全栈学习社区来啦!
推荐阅读
从零部署π0,π0.5!好用,高性价比!面向具身科研领域打造的轻量级机械臂
工业级真机教程+VLA算法实战(pi0/pi0.5/GR00T/世界模型等)
具身智能算法与落地平台来啦!国内首个面向科研及工业的全栈具身智能机械臂
VLA/VLA+触觉/VLA+RL/具身世界模型等!具身大脑+小脑算法与实战全栈路线来啦~
MuJoCo具身智能实战:从零基础到强化学习与Sim2Real
Diffusion Policy在具身智能领域是怎么应用的?为什么如此重要?
1v1 科研论文辅导来啦!

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 23
23 0
0- 0



 已为社区贡献50条内容
已为社区贡献50条内容

所有评论(0)