达摩院 NeurIPS'25|多模态大模型在第一视角下的动态时空物体认知能力如何?
作者|袁瑜谦 阿里巴巴达摩院实习生
引言
在厨房手忙脚乱时,你问AI助手:“我煮的菜熟了吗?”——它却连已经煮了几分钟都记不得。现有多模态大模型(MLLMs)在动态第一视角场景中近乎“盲人”:认不出已经清洗过的碗;预测不了即将烧焦的锅;记不住3秒前剪刀位置......
浙大和达摩院重磅推出EOC-Bench——首个聚焦第一视角下「动态物体时空认知」的评测基准,用3277道灵魂拷问揭穿MLLMs的认知黑洞!

EOC-Bench共包含11类问题,3277条问答数据,包含四种类别的问答,及多种类型的评估方式。
论文链接:https://arxiv.org/abs/2506.05287
项目主页:https://circleradon.github.io/EOCBench/
代码仓库:https://github.com/alibaba-damo-academy/EOCBench
Huggingface数据:https://huggingface.co/datasets/CircleRadon/EOC-Bench

痛点直击:为什么无法准确理解动态世界?
当前的视觉语言模型在大规模图文数据中学到的大多是基于静态视角的理解,缺乏对于动态世界的感知和推理能力。因此,当面对高动态第一视角场景的视频时,这些模型往往难以应用。
现有的评估基准主要测试物体的空间感知能力,比如桌子的长宽、房间的面积等静态物体属性,却对于动态操作场景却显得力不从心。例如(下图所示),在复杂且纷乱的厨房环境中,判断某个碗是否已经被清洗过,这种复杂交互操作的动态场景对模型的认知能力提出了巨大挑战。

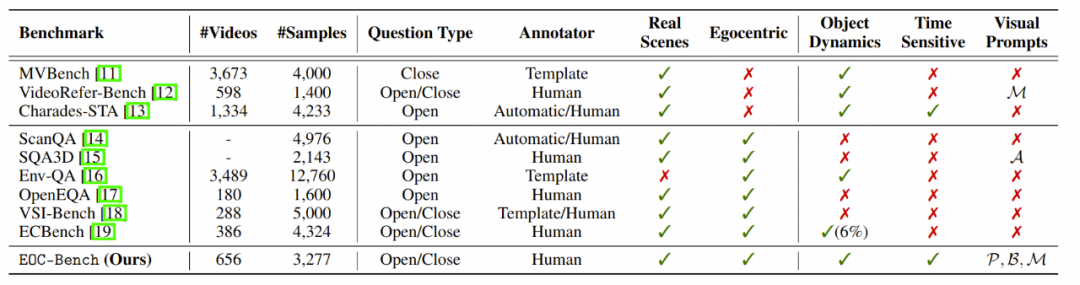
EOC-Bench和现有相关Benchmark的比较

EOC-Bench如何重构认知评估?
一、 三种时间维度
-
Past:回溯历史状态(如:"水已经烧多久了?")
-
Object State Retrospection 物体状态回溯
-
Object Location Retrospection 物体位置回溯
-
Object Relationship Evolution 物体关系回溯
-
Absolute Time Perception 绝对时间感知
-
-
Present:抵抗视觉欺骗(如:"看似在加热的锅——其实火已关")
-
Immediate State Recognition 当前状态识别
-
Purpose and Function Inference 物体用途推理
-
Object Relationship 当前物体关系识别
-
Anomaly Perception 物体异常检测
-
-
Future:预判动态风险(如:“物体放在这里是否会有危险?”)
-
State Change Prediction 物体状态预测
-
Dynamic Relationship Prediction 动态物体关系预测
-
Trajectory and Motion Prediction 物体轨迹预测
-
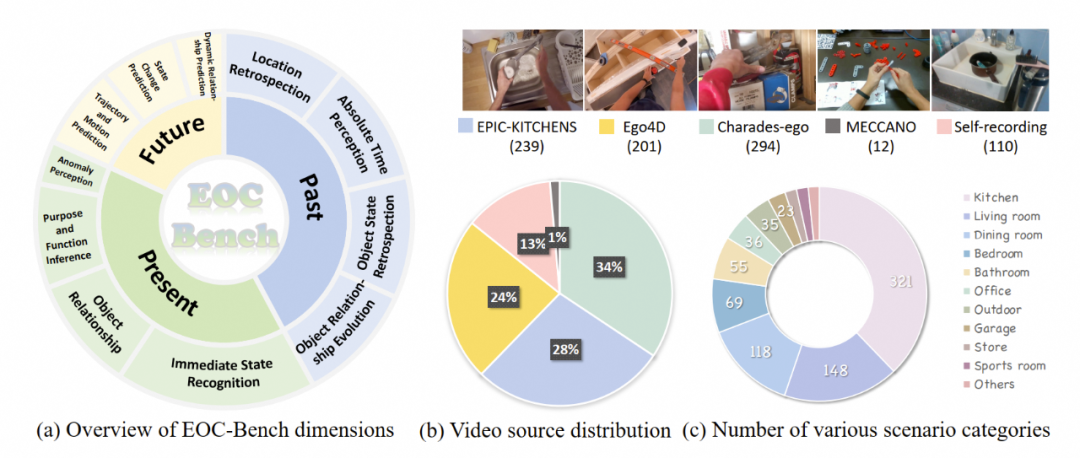
EOC-Bench数据分布情况
二、多种评估体系
-
混合问题:判断题/单选/多选/开放问答,模拟真实人机对话场景,典型示例如下
-
时序准确率评估:设计Multi-Scale Temporal Accuracy指标,精确灵活地衡量时间感知精度。通过对人工误差边界值的分析,设置阈值
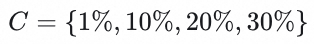
及阈值边界
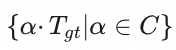
,得到时间维度的准确率计算公式:
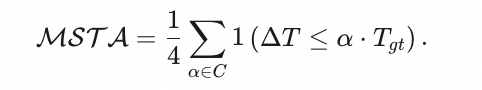
通过设置不同的阈值,该指标在严格性和灵活性之间取得了平衡:较低的阈值要求精确的回答,而较高的阈值则允许回答的多样性。

评测结果
文中对20+个开源与闭源模型进行了评测,包括:
-
闭源模型: GPT-4o, GPT-4o-mini, Gemini-2.0-flash。
-
开源基础模型:Qwen系列、InternVL系列、VideoLLaMA系列、LLaVA系列等。
-
物体级别的多模态大模型:VideoRefer、Osprey、SPHINX-V、ViP-LLaVA。
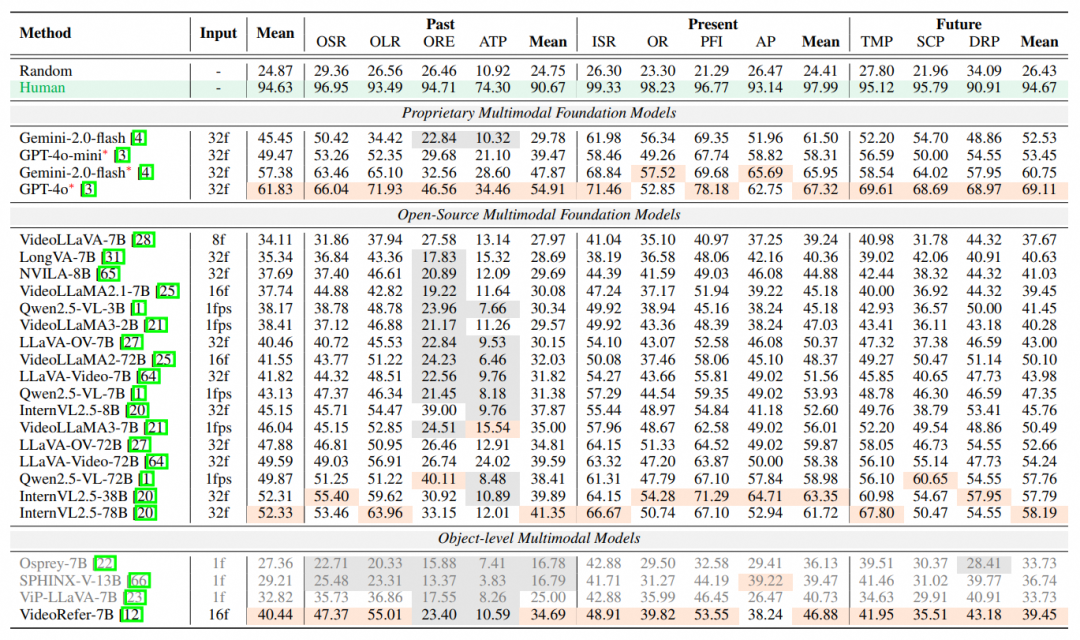
典型多模态大模型在EOC-Bench上的表现。最优的结果用橙色标记,灰色代表结果低于随机猜测
通过评测,作者发现模型在物体关系回溯(ORE)和绝对时间感知(ATP)两个指标上存在显著偏差,大多数指标低于随机猜测。在添加了时间戳的基础上,GPT-4o的表现依旧没有及格,这表明现有模型在感知和记忆时间变化的能力仍十分有限。
进一步,按不同类别的问题进行了评测:
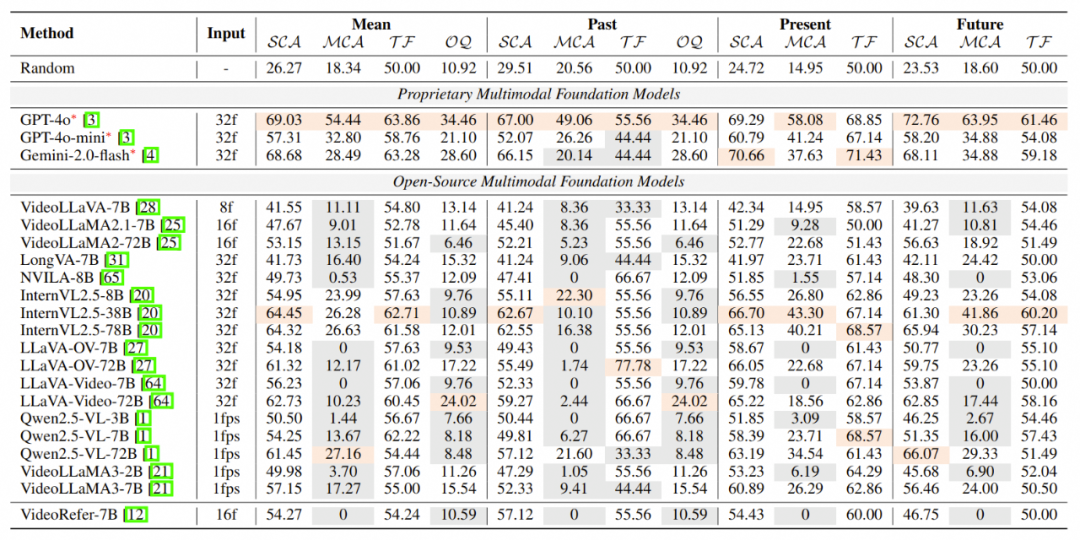
典型多模态大模型在EOC-Bench不同人物类型上的表现:SCA(单选题),MCA(多选题),TF(判断题),OQ(开放问答题)
根据上述表格得到了以下结论:
小模型大多答不了多选题。许多模型在回答多项选择题(MCA)时面临挑战,分数往往低于随机猜测(以灰色标记表示)。这一问题在较小的模型中尤为突出,这些模型参数为7B或更少。作者推测,这些较小的模型在训练过程中已经过度拟合于简单的单项选择题,妨碍了它们根据说明处理多选题的能力。
很少的模型对时间敏感。OQ指标测量模型感知过去时间的能力,表明某些模型的表现低于随机猜测水平,仅有9/21。即使是最强的开源模型也仅得分24.02%,比随机猜测高出13.1%。这强调了大多数模型中缺乏的重要能力,而这在具身AI领域是必不可少的。
较大的模型更能处理好未来的预测。未来的预测任务需要结合常识推理和广泛的知识。随着模型规模的增加,其推理能力也随之提升。例如,具有3B、7B和72B参数的Qwen2.5-VL以及具有2B和7B参数的VideoLLaMA3在这些任务中的表现显著提高。这表明较大的MLLM更好地应对需要前瞻思维和预测推理的问题。
面向过去的问题对MLLM构成更大挑战。通过对类似问题类型的比较分析,作者发现模型在与过去事件相关的问题上总体表现较差。这种准确回忆和处理过去信息的困难在当前MLLM中普遍存在,表明其设计和训练中需要显著改进的领域。
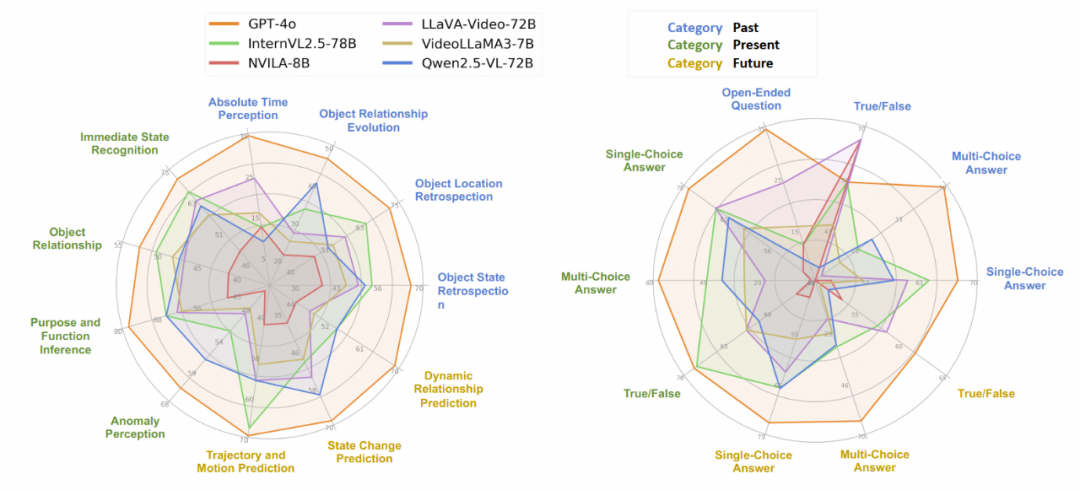
为了评估不同帧数量对评估结果的影响,文章进一步评估了EOC-Bench中1帧、8帧和32帧的结果增益:

结果表明,闭源模型GPT-4o和Gemini-2.0-flash在从单帧输入转为32帧输入设置时表现出显著的性能提升,分别提高了24.6%和20.1%。这种改进特别明显体现在面向过去的任务中,改进幅度为49.2%和60.2%。这些发现强调了多帧推理在EOC-Bench中的关键作用,尤其是在记忆回溯任务中,从此前帧中访问信息的能力可以显著增强表现。其他开源模型,如InternVL2.5和VideoLLaMA3也表现出了相同的趋势。
![]()
错误分析
以表现最好的GPT-4o模型为例进行分析:
-
感知错误。这种错误涉及当前帧中的感知问题,包括来自先前帧的干扰、对细节的关注不足、计数错误和帧内干扰。
-
记忆错误。这种错误类型反映了对先前帧信息观察或回忆的不正确,包括来自当前帧的干扰和遗漏的观察,抽样帧不足以回答与记忆相关的问题。
-
关系推理错误。这种错误涉及在感知或推断物体之间的简单关系时遇到困难。
-
知识错误。这个类别涵盖了推理、常识和计算方面的错误。
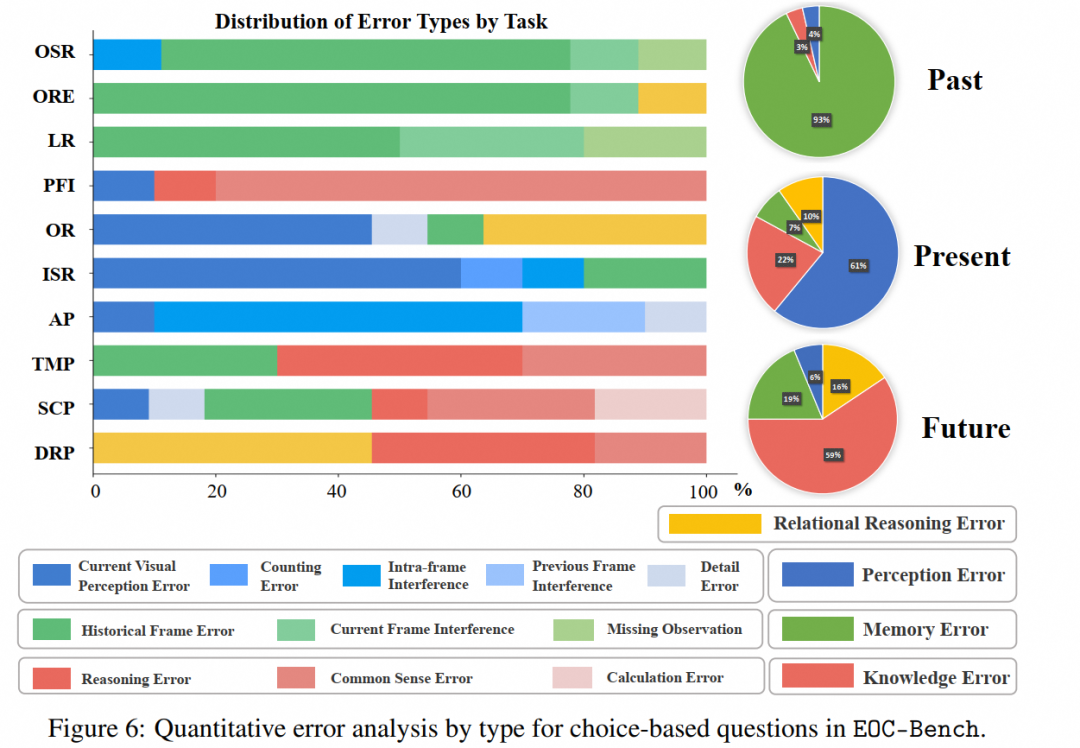
在过去类别中,记忆错误占据主导地位,占错误的93%。这些主要是由于历史帧处理不足(73%)和当前帧干扰(17%)。剩下的10%是遗漏观察错误,这突显了固定帧采样策略的固有限制。
在当前类别中,感知错误占61%,其次是知识错误(22%)和记忆错误(7%)。值得注意的是,帧内干扰构成了感知错误的重要部分,揭示了模型在区域级别视觉感知上的限制及其对幻觉性伪影的易感性。
在未来类别中,大约59%的错误是知识相关问题,表明推理能力和常识理解的限制。
对于动态场景下时间感知准确性,文章进行了密度分析,分析结果如下:
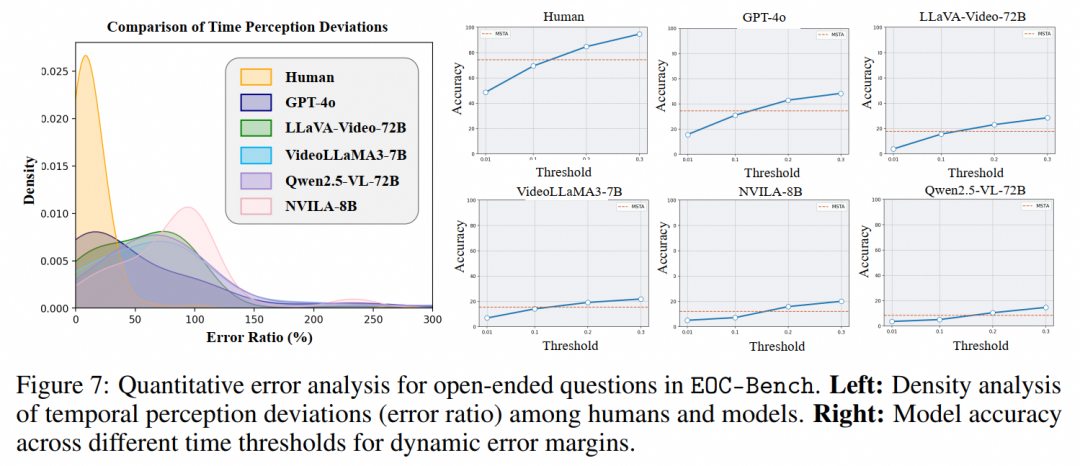
从图中可以看出,人类回答的分布呈现出明显的峰值,随后迅速衰减,这表明大多数人类答案实现了最低错误率,只有偶尔出现较高不准确性的情况。相比之下,五个表现最好的模型GPT-4o、LLaVA-Video-72B、VideoLLaMA3-7B、Qwen2.5-VL-72B和NVILA-8B显示出更平缓的分布,具有更宽泛的扩散。这表明现有的模型在时间感知方面表现出更大的随机性和误差性。

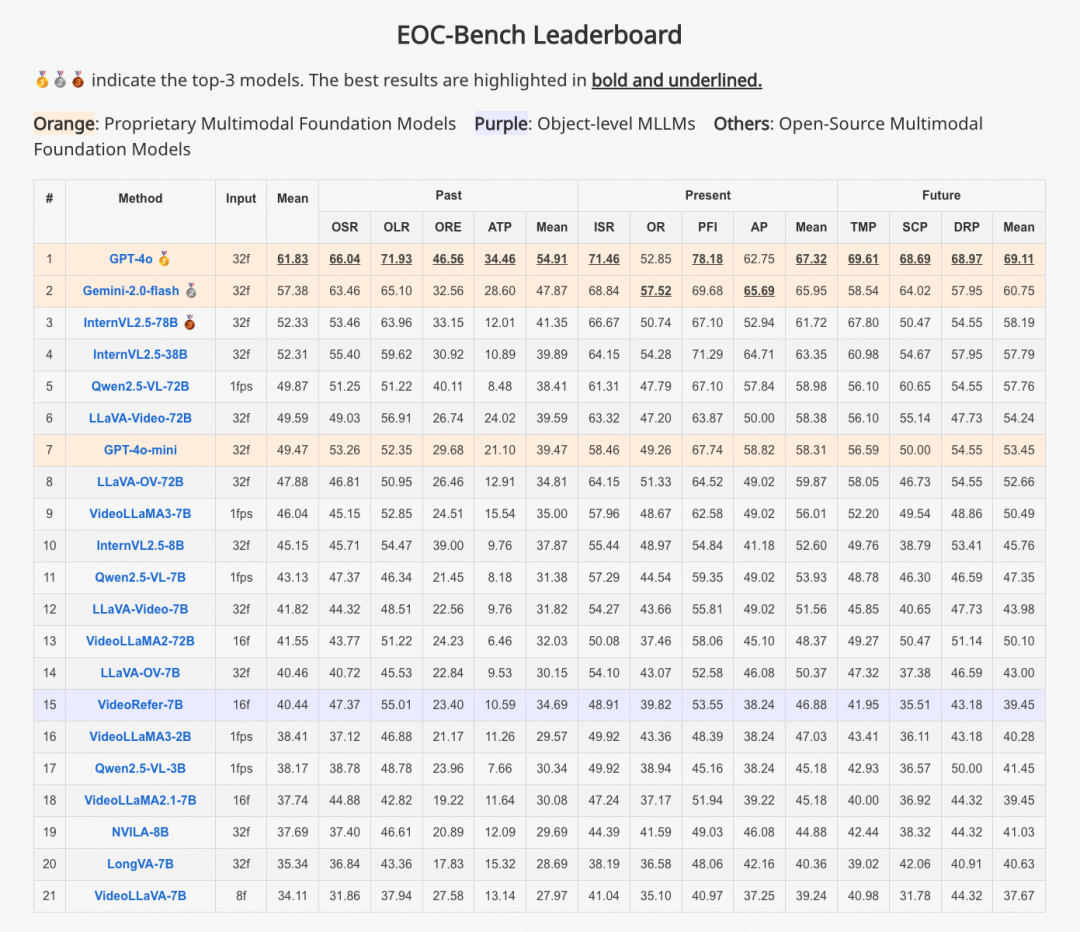
Leaderboard
此外,作者团队建立了leaderboard,快来试试你的模型表现如何吧。

总结
EOC-Bench旨在评估多模态大语言模型第一视角下的物体级认知能力。EOC-Bench在涉及动态以自我为中心互动的场景中全面评估MLLMs,包括过去、现在和未来三个时间维度。
为了确保高质量,EOC-Bench设计了多种题型的任务模式,并引入了多尺度时间准确率指标,以提高开放性问题的精确度。针对多种专有和开源模型进行的广泛评估显示,许多MLLMs在具身物体认知任务上面临挑战,特别是在回忆和处理过去信息以及绝对时间感知方面,希望EOC-Bench将推动开发能够理解更复杂和多样化的物理世界的模型的进步。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 0
0 0
0- 0



 已为社区贡献122条内容
已为社区贡献122条内容

所有评论(0)