97.4%成功率!阿里达摩院新模型RynnVLA-002让机器人“边看边想边干”
作者|岑俊 阿里巴巴达摩院算法工程师
导语
我们提出了RynnVLA-002,将具身视觉-语言-动作(Vision-Language-Action, VLA)模型与世界模型统一到了一个模型中。 世界模型利用动作和视觉输入来预测未来的图像状态,通过学习环境的底层物理规律来优化动作生成。 相反,VLA 模型从图像观测中生成后续动作,提升视觉理解能力,从而提升世界模型的图像生成能力。 RynnVLA-002 的统一框架实现了环境动态与动作规划的联合学习。我们的实验表明,RynnVLA-002 的性能优于单独的 VLA 模型和世界模型,并展示了它们在统一的框架中可以互相促进。 我们在仿真环境和真机任务中对 RynnVLA-002 进行了评估。在 LIBERO 仿真环境测试中,RynnVLA-002 在没有预训练的情况下取得了97.4%的成功率;而在真机LeRobot实验中,世界模型的融入使整体成功率提升了 50%。
Github链接:https://github.com/alibaba-damo-academy/RynnVLA-00

研究背景与现有方案的缺陷
视觉-语言-动作(VLA)模型能够根据文本指令和观测信息输出动作信号控制机械臂。大多数VLA模型基于大规模预训练的多模态大语言模型,使得 VLA 模型能够在广泛的机器人任务中表现出更强的泛化能力。然而,标准的 VLA 架构面临三个缺陷。
-
动作模态理解能力不足。现有VLA无法完全理解动作,因为动作只存在于输出端,这使得模型无法形成对动作模态学习到本质理解特征
-
缺乏预测未来能力。现有VLA不会预测在给定候选动作的情况下世界会如何演变,这阻碍了模型的预见能力和反事实推理能力。
-
物理规律理解能力不足。现有VLA不能捕捉物理动态,模型无法内化物体间的交互、接触或稳定性。
世界模型(World models)通过学习基于当前图像和动作来预测未来的观测,提供了具备动作感知能力的内部状态、想象力,以及一个蕴含物理信息的环境动态表征,从而直接解决了这些局限性。尽管有此优势,世界模型却因无法直接生成动作输出来控制机器人。
为了解决 VLA 模型和世界模型各自固有的局限性,我们提出了 RynnVLA-002,这是一个用于统一动作和图像理解与生成的自回归动作世界模型。如下图所示,RynnVLA-002 采用三个独立的 tokenizer(编码器)来分别对图像、文本和动作进行编码。来自不同模态的 token 共享同一个词表,这样,跨模态的理解和生成就可以在单一的 LLM 架构中得以统一。世界模型组件通过基于输入动作生成视觉表征,来捕捉环境底层的物理动态。这种根据动作和学习环境物理规律的过程,对于 VLA 模型内部实现有效决策至关重要。与此同时,嵌入在 RynnVLA-002 中的 VLA 模型会提升对视觉数据的理解,从而提高世界模型生成图像的精度。这种双向增强机制创造了一个更鲁棒、更全面的模型,使其能够同时理解和生成动作与图像。
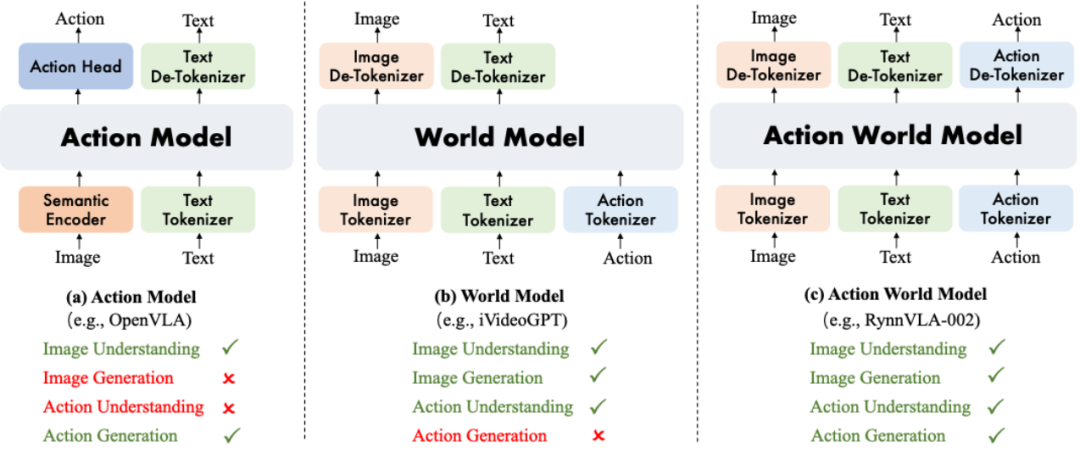

技术方案
-
文本、视觉、动作多模态统一编码
RynnVLA-002总体架构图如下图所示,在一个统一的LLM架构下,我们训练过程中集成了VLA模型的数据和世界模型的数据进行混合训练。训练完的模型可以根据用户的输入来提供VLA或世界模型的功能。
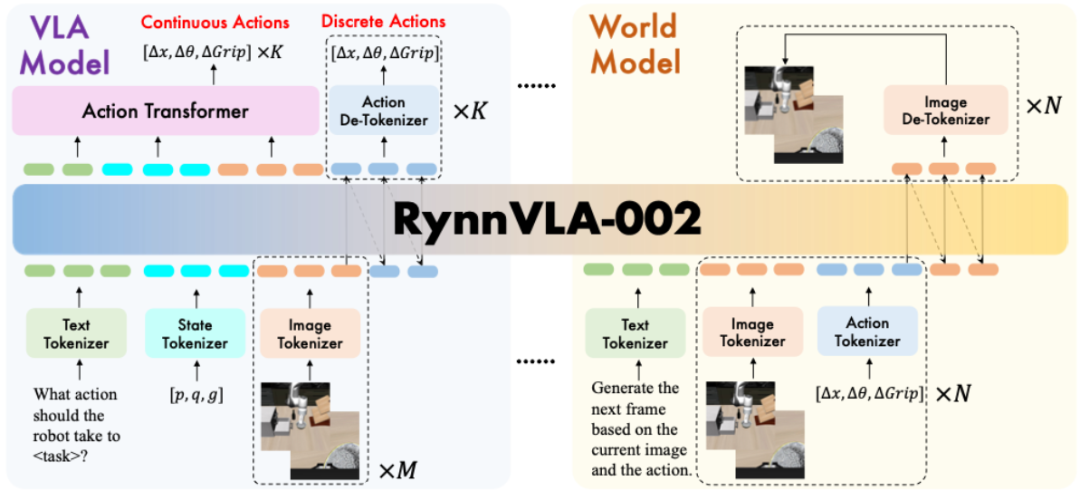
(1)编码器(Tokenizers)。我们使用Chameleon作为基座模型,并且继承了对应的图片和文本tokenizer。图片tokenizer是一个VQGAN模型,负责把图片的patch映射到离散的数字编号,codebook的长度为8192。文本tokenizer是一个训练好的BPE编码器。动作编码器 (Action Tokenizer)和状态编码器(State Tokenizer)将动作和状态切分成256份,根据对应数字的大小得到对应的编号。
(2)VLA模型数据。VLA模型根据文本指令,机器人状态,和前视角图片和腕部视角图片观测来输出动作。
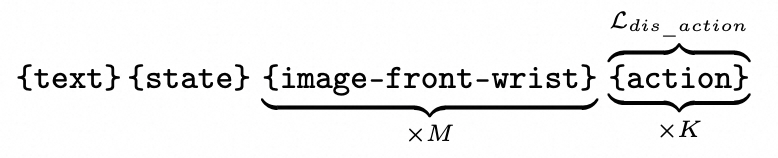
文本输入为“What action should the robot take to + <task>+ ?”. <task>指希望机器人做的任务。Ldis_action指对动作token的离散交叉熵损失。
(3)世界模型数据。世界模型根据当前时刻的前视角图片和腕部视角图片以及机器人动作输入,来预测下一时刻的前视角图片和腕部视角图片。
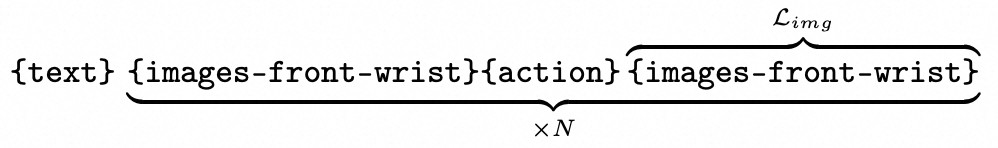
世界模型的文本指令固定为“Generate the next frame based on the current image and the action.”与当前机器人所执行的任务无关,因为机器人的动作可以完全决定世界物理状态的变化。Limg为图片token的离散交叉熵损失。
-
动作块(Action Chunk)生成方式探索
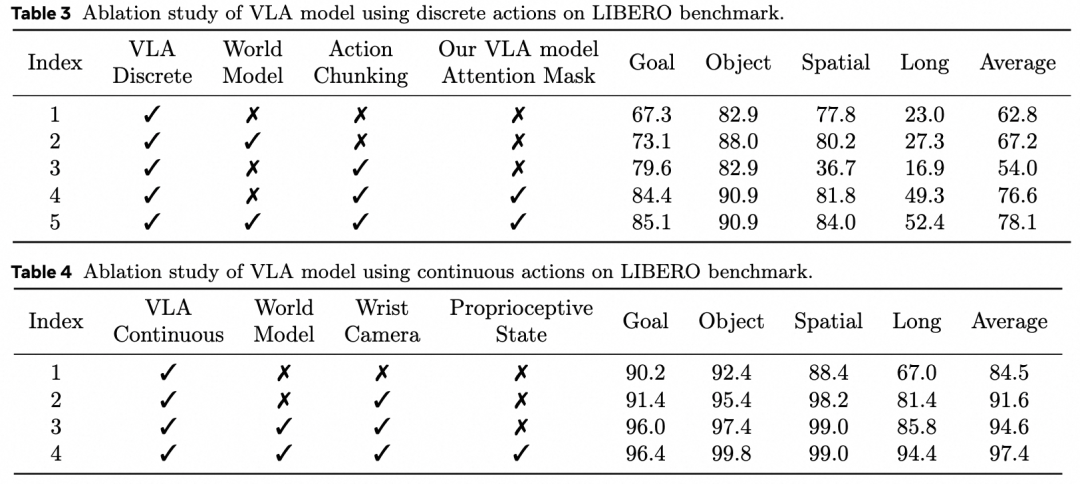
(1)为离散动作块生成设计的注意力掩码策略。一次性生成多个动作对机器人执行的效率和性能非常重要。我们发现离散自回归模型中直接连续生成多个动作会导致性能下降。尽管基础的多模态大语言模型在图像和文本领域表现出较强的泛化能力,但其在动作领域的有效泛化能力相对有限。因此,在默认的注意力掩码方式下,早期动作产生的错误会传播到后续动作,造成性能退化。为了解决这一问题,我们提出了一种专门为动作生成设计的替代注意力掩码,如下图(b)所示。该改进的掩码确保当前动作仅依赖文本和视觉输入,同时禁止访问先前的动作。这样的设计使自回归框架生成的多个动作之间保持独立性,从而缓解错误累积问题。而世界模型部分则遵循传统的注意力掩码设计,如下图 (c) 所示。

(2)为生成连续动作快生成设计的Action Transformer。尽管我们的离散动作分块模型在仿真中表现可观,但在真实机器人实验中却很少成功。这是因为真机实验对泛化能力的要求更高,比如光照和物体位置在真机实验中都会显著发生变化,但在仿真中并不需要这样的能力。全离散模型在真实环境中失败的原因主要有两点。首先,参数量巨大的自回归架构在有限的真机数据集的情况下容易发生严重的过拟合,导致泛化能力差。其次,我们所设计的注意力掩码使自回归模型在同一动作块块内将每个动作孤立生成,无法保证轨迹的连续性,从而引发严重抖动和不平滑的运动,显著降低成功率。
为了解决这些挑战,我们加入一个Action Transformer来生成连续动作序列。该模块会根据完整的上下文信息,包括语言、图像和状态 token来并行输出整个连续动作分块。此设计带来了两个显著优势。首先,Action Transformer 更小的参数量在有限数据条件下不易过拟合,从而提高泛化能力,并生成流畅、稳定的动作。其次,它可以在一次前向推理中并行生成所有动作,相比需要一个个生成动作的自回归方式,显著加快了推理速度。

实验结果
-
基础任务对比
(1)在仿真环境benchmark LIBERO中,RynnVLA-002在没有预训练的情况下,使用连续的动作达到了平均97.4%的成功率,使用离散的动作达到了93.3%的成功率,与许多经过预训练的模型具有更高或者不相上下的性能。
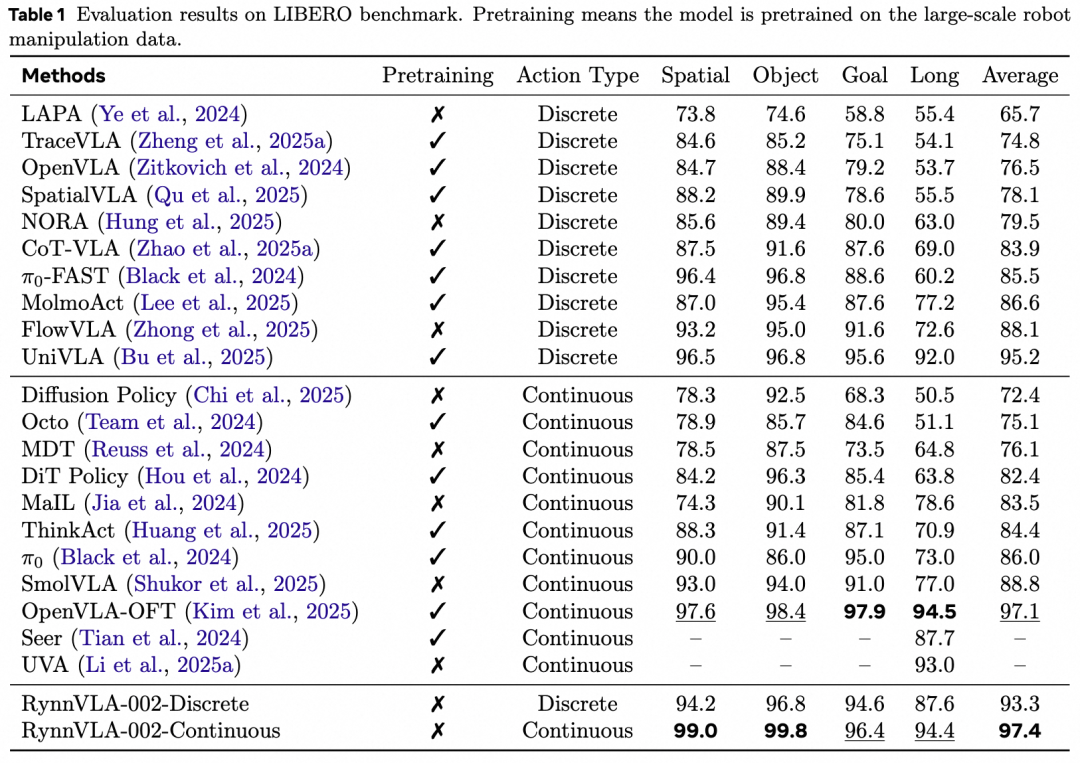
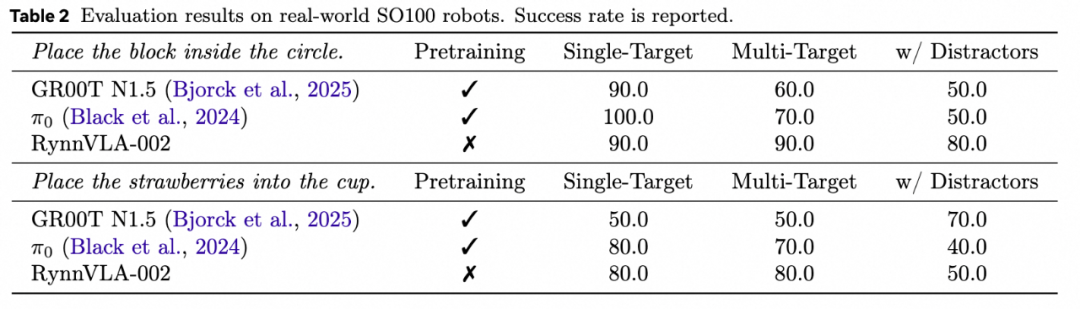
(2)真机实验我们使用LeRobot SO100进行验证。我们使用“将方块放入胶带” 任务和“将草莓放入杯子” 任务进行展示。实验结果显示RynnVLA-002在没有预训练的情况下和有大量预训练的pi0和GR00T N1.5总体有着相仿的性能,在多目标和有干扰物体的情况下有时甚至有更高的成功率。
-
核心技术消融实验
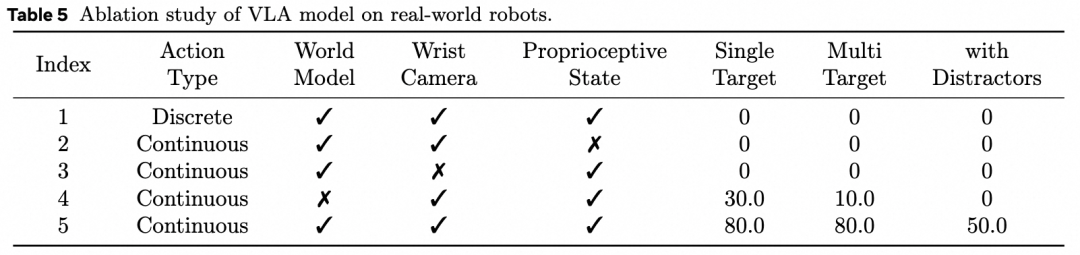
(1)世界模型对于VLA模型性能的增强。下面三张表格显示,在仿真环境中使用离散和连续的动作时,训练过程中加入世界模型分别有这4.4%和3.0%的成功率提升。真机实验中加入世界模型的数据可以大幅提升50%的成功率。
(2)VLA模型对世界模型的增强。VLA模型可以提升对于图片的理解能力,从而增强世界模型的图片生成能力。

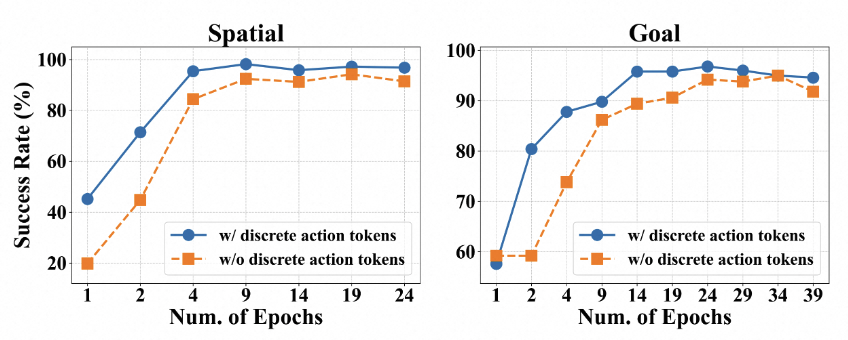
(3)离散动作与连续动作。下图显示仿真环境中连续的动作比离散的动作收敛的更快,并且最终性能更高。在真机实验中离散的动作由于泛化性比较弱几乎不能完成任务,而连续的动作则具有更强的泛化性。但是如果训练过程中去掉离散的动作监督,我们发现连续的动作收敛速度会变慢,最终性能也会降低,原因是离散的动作更符合基础模型的自回归训练方式,并且可以学习到更好的图片文本状态表征。


DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 0
0 0
0- 0



 已为社区贡献119条内容
已为社区贡献119条内容

所有评论(0)