AI驱动的多尺度医学预测:从分子机制到临床前瞻干预
作者:刘培源
导语
人工智能正在深刻改变医学。生成式模型、虚拟细胞、器官芯片与大规模真实世界数据,正在共同塑造一种由分子到群体的全新医学图景。其核心趋势,是将预测前移到疾病尚未发生或症状尚未显现之时,以实现风险量化和前瞻干预。本文围绕分子、细胞、组织-器官以及个体等层级,梳理AI驱动的代表性进展,揭示多模态数据、多尺度方法的关键挑战,并探讨走向临床应用的可能路径。
本文为文章作者的观点/研究数据,仅供参考,不代表本账号的观点和研究内容。

引言
生命的奥秘根植于多尺度结构之中:从分子、细胞到组织、器官乃至个体层面,复杂的生理与病理机制紧密交织,共同决定健康与疾病的状态。在AI驱动下,这一奥秘正在逐渐被揭开。2024年,Science杂志发表美国国家医学院院士、Scripps研究所创办人Eric Topol的评论文章,首次正式提出医学预测(Medical Forecasting)的概念,即通过AI预测个体具体、可干预的高风险因素,以预防疾病或严重急性事件的发生。2025年7月,Topol等在Cell杂志的综述中进一步提出多尺度医学预测(Multiscale Medical Forecasting),指出AI工具通过持续监测、多模态数据融合与跨尺度预测,正推动医学预测从被动响应转变为主动、个性化的临床干预。
多尺度预测的思想早已有之。以机理驱动的“虚拟生理人”(Virtual Physiological Human, VPH)为代表的跨尺度建模框架,早已尝试通过整合生理学、药理学与计算模型,模拟人体多个器官系统的复杂动力学,以辅助药物研发与临床决策。然而,这类传统跨尺度建模长期停留于理论与实验室阶段,受到数据稀缺、参数复杂性、计算成本高昂,以及尺度之间高度非线性的现实挑战严重制约,难以有效地在真实医学环境中实现可靠的预测与泛化。
与此同时,以基础模型(Foundation Models)与生成式AI(Generative AI)为代表的新一代人工智能技术,正为多尺度医学预测带来突破。这些技术不仅能够在大规模、多模态医学数据中自动提取跨尺度特征,更能在缺乏统一预测金标准的情况下,提出可被实验与临床验证的预测假设与机制解释。例如,近期AI制药公司Recursion旗下Valence Labs团队提出“预测-解释-发现(Predict-Explain-Discover, P-E-D)”范式,即AI模型预测与结构化生物数据相结合,构建既能有效预测又可解释的跨尺度医学预测链,并在“lab-in-the-loop”流程中持续迭代、生成与验证新的生物学假设与干预策略。这类方法论已初步展现出从虚拟细胞延展到器官芯片和数字孪生患者(Digital Twin)的路径,进一步支持精准医疗与模型指导精准给药(Model-Informed Precision Dosing, MIPD)的实际应用场景。
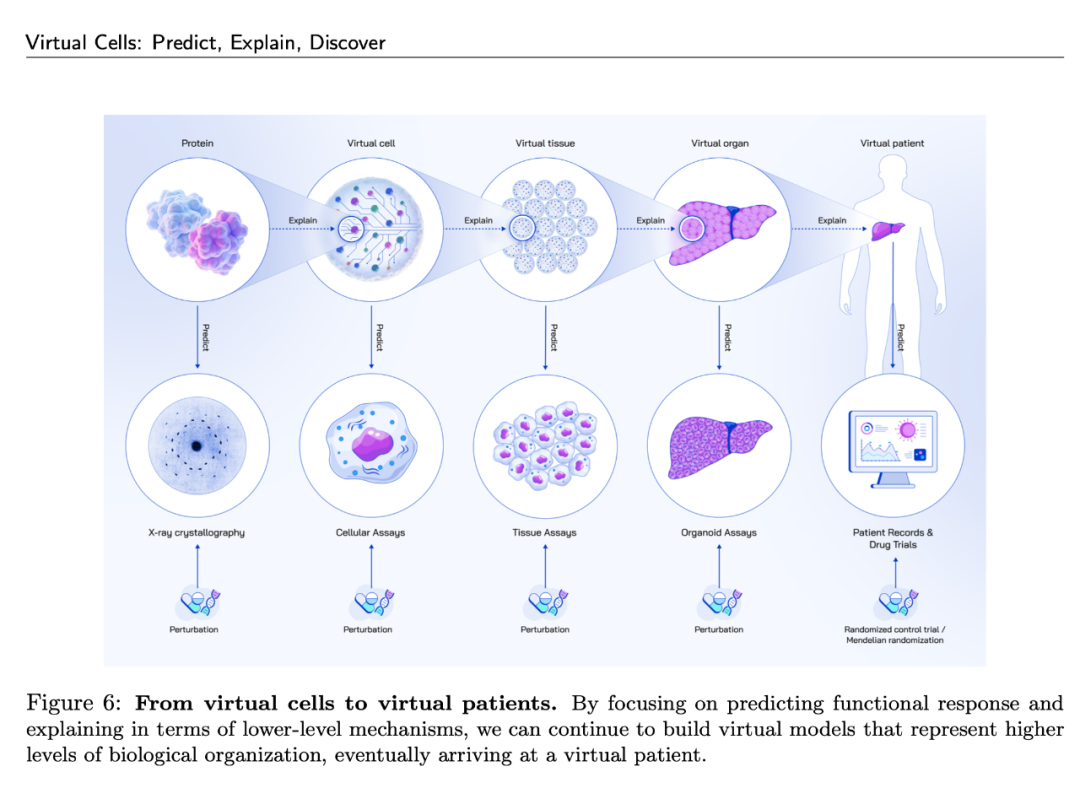
图1:从虚拟细胞到虚拟患者。从虚拟细胞尺度上应用“解释-预测-发现”的研究思路,并层层拓展到虚拟患者尺度,最终形成多尺度的生物医学建模
多尺度医学预测的独特之处在于,它能把疾病的动态过程贯穿在分子、细胞、组织、器官到个体的连续层级上加以理解和预测。这种跨尺度视角让研究者不仅能在分子水平上识别致病突变或药物靶点,还能追踪这些改变如何在细胞群体和器官功能上级联放大,最终表现为临床症状。并且,跨尺度预测模型则更清晰地解释患者间个体差异、疾病亚型、疗效异质性背后的生物机制来源,进一步提高临床决策的质量与可解释性。同时,我们应当看到,医学界目前尚无统一的健康预测金标准,多模态AI模型对电子健康记录(EHR)、可穿戴设备、肠道微生物组等数据的整合仍处于早期阶段,对健康状态的持续检测、多模态整合与跨尺度预测仍然有诸多挑战。
本文将从分子、细胞、组织与器官、个体等尺度分别切入,探讨AI技术引发的基础医学革命,并梳理当前最新进展与挑战。

分子尺度:从结构预测到生成式药物设计
近年来,AI技术在蛋白质结构预测、靶点识别与药物分子设计等方面取得显著突破,为生命科学、基础医学以及药物研发提供了强大的工具与技术支持。在分子尺度,我们能够清晰、准确地测量数据、定义关系,并在可控的实验条件进行操控和验证。
2025年6月,AI制药公司Insilico Medicine(英矽智能)宣布,其通过生成式AI发现新靶点并设计的小分子药物Rentosertib(TNIK抑制剂)在特发性肺纤维化(IPF)的IIa期临床试验中取得关键突破,显著改善患者肺功能[8]。这是迄今公开的首个由生成式AI识别新靶点并设计药物分子、并在II期临床试验中获得阳性结果的案例,标志着AI药物研发从概念验证进入临床验证阶段。
靶点识别是药物研发的第一步,AI正显著加速这一环节。传统靶点发现方法主要依赖实验室大规模试错,周期长且成本高昂。2024年诺贝尔化学奖得主、DeepMind 与Isomorphic Labs 的CEO Demis Hassabis近期在采访中指出:“未来几年内,AI将在新药靶点识别中发挥主导作用”。Rentosertib的研发正体现了这种趋势:Insilico借助AI平台PandaOmics,从海量多组学数据与文献证据中快速确定关键新靶点TNIK。随后通过Chemistry42药物生成平台快速设计并优化候选分子,使药物迅速推进临床。此外,药物靶点预测工具DrugnomeAI也通过深度学习在基因组尺度系统评估靶点可成药性,有效提高了靶点发现的成功概率。
蛋白质结构预测为药物研发和医学预测提供了基础支持。2024年10月,DeepMind发布AlphaFold 3,首次实现蛋白质与小分子、核酸等复合物结构的一次性高精度预测。结构预测正逐渐成为精准医学预测的重要计算基础,AI的加入彻底改变了药物发现与临床预测节奏。与此同时,DeepMind的AlphaMissense工具则在基因组尺度预测蛋白质突变的致病风险,明确预测疾病相关基因变异可能引发的健康风险,为临床前瞻性干预提供了重要依据。不过,AlphaFold当前以静态结构预测为主,实际蛋白质功能涉及复杂动态过程,这使得结构预测与真实功能之间存在鸿沟。
生成式AI进一步推动药物设计的创新。2024年诺贝尔化学奖得主、华盛顿大学教授David Baker团队开发的RFdiffusion工具利用扩散模型高效设计功能蛋白,体现了生成式蛋白设计的潜力。目前,日本武田制药推进的乳糜泻在研蛋白酶药物TAK-062,也体现了AI蛋白质设计走向临床转化的趋势。此外,Recursion公司2023年宣布使用NVIDIA超算平台完成约360亿蛋白-配体组合的预测,为后续药物研发与医学风险预测提供了强大的计算基础。
生成式AI进一步推动了药物设计创新。2024年诺贝尔化学奖得主、华盛顿大学教授David Baker团队开发的RFdiffusion工具基于扩散模型原理高效设计新型功能蛋白,体现了生成式蛋白设计的巨大潜力。目前,日本武田制药推进的乳糜泻治疗蛋白酶药物TAK-062,也体现了AI蛋白质设计走向临床转化的趋势。MIT James Collins教授团队则利用深度神经网络快速筛选出新型窄谱抗生素Abaucin,通过干扰细菌LolE脂蛋白转运发挥抗菌作用,展示了AI在抗药菌研究领域的优势。
尽管如此,生成式AI药物设计仍面临现实合成难度高与预测假阳性率偏高的问题。Exscientia与Insilico公司在生成模型中均引入合成可行性评分与多目标优化策略,以确保生成分子的现实可合成性。数据偏倚与泛化不足同样受到关注,Geneformer模型利用大规模单细胞数据预训练再微调,提升预测模型稳健性与泛化性能。
随着AI药物研发进入临床递交阶段,美国FDA药品审评研究中心(CDER)2025年发布了AI药物开发监管框架草案,提出基于风险的可信度评估与数据支持要求,以确保AI预测结果的可解释性和临床适用性。
David Baker预测,AI驱动的蛋白质设计将推动药物研发进入工程化设计新时代。Chan Zuckerberg Initiative科学主管Stephen Quake在2025年7月接受Nature采访时提出:“生命科学研究正逐渐从当前的90%实验+10%计算,转变为10%实验+90%计算”。
依托AI结构预测(如AlphaFold3与AlphaMissense)、生成式药物设计(如RFdiffusion与Chemistry42)、多组学靶点识别(如DrugnomeAI与Geneformer)及监管框架,我们已开始在分子尺度实现对疾病机制的前瞻预测与精准干预。这为细胞、组织、个体乃至群体尺度的医学预测奠定了重要的基础支撑。

细胞尺度:多模态数据与细胞模型
细胞尺度联通了分子机制与组织病理,是理解健康、疾病状态变化及病例进展的关键环节。近年来,单细胞测序、空间组学与显微成像等高维数据的兴起,使AI驱动的细胞状态前瞻性预测成为可能。这不仅有助于精准判别细胞命运和发育过程,还为靶点发现和药物预测提供了新途径。与传统分类不同,这种预测强调对未来状态转归的风险量化与可行动干预,而非简单描述当前细胞状态。
单细胞组学数据正成为细胞状态预测的核心驱动力。CellTypist团队构建了基于单细胞RNA测序(scRNA-seq)的自动细胞类型注释模型,通过高效集成学习提升了跨数据集泛化性能,广泛应用于主流数据库。scTour模型融合深度学习与轨迹推断,能在无先验时间标签条件下精准重构细胞发育轨迹,提升了细胞状态动态转变的建模预测能力。2025年,Xaira Therapeutics发布X-Atlas/Orion平台,公开约800万细胞的Perturb-seq扰动数据,涵盖基因扰动的剂量-响应-时间设计,为虚拟细胞建模提供了高分辨率数据资源。Insitro则利用多模态AI分析人类干细胞疾病模型,在肌萎缩性侧索硬化症(ALS)等疾病研究中发现了多个潜在治疗靶点并完成实验验证,成为数据驱动预测与靶点发现的成功范例。
显微成像驱动的细胞状态预测同样取得显著进展。Recursion Pharmaceuticals构建了自动化高通量细胞成像筛选平台,通过Vision Transformer等自监督模型对大规模细胞图像进行分析,创建了高效的表型组学图谱,用于药物筛选与靶点发现。这些模型可滚动预测风险与置信度,推动形成“预测—筛选—验证”的高效闭环。斯坦福大学Pranav Rajpurkar团队开发了Med-Flamingo模型,将医学影像与医学文本数据整合到大规模多模态模型中,展示了在医学视觉问答、病理解读等任务上的泛化能力[32]。近期也有研究利用细胞级时序成像判别发育与命运阶段,从形态轨迹中提取前瞻性预测信号。
空间组学则是连接细胞尺度与组织尺度的重要桥梁。空间转录组与空间蛋白组技术在保持空间位置信息的基础上,揭示细胞亚群在组织微环境中的空间分布、邻域关系与功能互作。代表性技术包括Spatial Transcriptomics、MERFISH与Imaging Mass Cytometry(IMC)。空间组学可作为单细胞模型的空间约束和影像模型的分子锚点,为虚拟细胞的组织级预测和跨尺度预测提供重要数据支撑。
近期势头正猛的AI虚拟细胞(AIVC)进一步打开想象空间:通过大规模扰动数据与多模态数据整合,建立能泛化预测干预措施下细胞状态变化的模型。2025年,Arc Institute先发起“虚拟细胞挑战赛”以建立统一评测框架,随后发布State模型预印本。虚拟细胞挑战赛提供了统一的高质量标准扰动数据和开放的评测框架,被业界普遍视作该领域的“类ImageNet”范式,推动了虚拟细胞预测模型的规范化比较与迭代优化。State模型基于超大规模扰动单细胞数据训练,可准确预测药物、基因敲除或细胞因子刺激的短期与中期细胞状态变化,在未知细胞和未见扰动条件下表现出良好泛化能力。同时,多模态数据也在尺度进入虚拟细胞研究的范畴。例如Noetik公司在2025年AACR大会发布了融合单细胞转录组、空间蛋白与细胞影像的多模态Transformer模型OCTO,并搭配Perturb-map平台收集系统性的体内扰动—免疫表型数据,直接服务于免疫治疗的患者分层预测。
尽管进展迅速,细胞模型探索仍然面临可解释性不足、临床前验证机制缺乏与产业监管框架尚未完善等挑战。Insitro创始人Daphne Koller强调:“真正重要的是理解疾病背后的因果机制,而非仅仅识别数据中的相关模式,只有深入解读细胞内机制,AI预测才能真正转化为可靠的临床干预依据”[29]。Demis Hassabis则指出:“尽管距离完全替代湿实验的虚拟细胞模型仍有距离,但五年内一定能看到关键的技术突破与大规模前瞻验证”。
当前,以数据驱动、前瞻预测和功能验证为核心的细胞尺度医学预测体系的逐渐形成。未来几年,这一体系能否实现机制解释、数据互通与临床转化的融合,将决定虚拟细胞与细胞尺度精准医学预测能否真正成为医学领域的重要基础设施之一。

组织与器官尺度:从类器官到器官芯片的临床前预测的技术跨越
组织与器官尺度衔接着分子与细胞层次,直接影响药物和医疗干预措施在临床中的有效性。然而,从分子与细胞层面的精准预测到更接近人体生理的组织尺度,一直存在挑战。近年来,以类器官和器官芯片为代表的组织尺度模型,通过AI的辅助分析,已逐渐成为医学预测领域重要的临床前工具。
类器官技术可在体外重现人体组织的生理结构,已被广泛用于药物疗效与安全性评估。Emulate公司与AbbVie合作的肠道芯片(Intestine-Chip)能在AI支持下精准预测药物治疗IBD的疗效反应。类似地,Boehringer Ingelheim利用肝脏芯片和肾脏芯片评估ADC药物毒性,也取得了明显优于动物模型的预测准确性。
尽管如此,不同实验室的类器官模型间存在较大的数据差异,限制了预测结果的泛化能力。为此,罗氏、ETH Zürich、Helmholtz Munich和人类细胞图谱联盟(HCA)共同建立了标准化的类器官细胞图谱,通过深度学习算法,有效统一和校正了跨实验室数据差异。这一进展为类器官模型的医学预测建立了坚实的数据基础。
空间多组学与数字病理的结合,同样推动了组织尺度医学预测的精细化。深度学习模型现已能直接从H&E染色的病理切片预测组织空间基因表达特征。病理基础模型,如Prov-GigaPath,也展现出跨癌种和临床任务的强泛化能力。这些方法使组织尺度预测不再局限于形态学判断,而能够更准确地预测分子生物学状态与临床风险。
此外,离体器官机灌注技术的进步,使临床预测有了更加直接的体外模型。EVLP肺灌注技术结合AI模型InsighTx,已成功用于肺器官功能恢复和移植成功率预测。肝脏和肾脏的离体机灌注(NMP)也提供了更精准、更临床可操作的体外到体内外推预测模式。
更复杂的系统级预测也在逐步推进。研究者构建了多器官组装模型(Assembloids),实现了神经疾病研究和药物反应评估在更高组织系统水平的落地。Emulate和CN Bio等公司的多器官芯片技术,也开始在药物代谢、毒性和治疗反应的前瞻性预测中发挥重要作用。
产业与监管环境的积极变化则进一步推动组织尺度医学预测的实际应用。FDA在2025年宣布,未来3至5年内,将逐步减少药物安全性试验中动物实验的使用,鼓励类器官与器官芯片模型的广泛应用。哈佛Wyss研究所的Donald Ingber指出,器官芯片与AI技术结合能显著提高药物测试的人体相关性,医学预测正逐步迈向更具临床现实价值的方向。
类器官、器官芯片和空间多组学技术正逐渐走出实验室,为精准的临床预测提供了扎实的数据基础。随着空间组学与虚拟细胞技术的快速进步,组织与器官尺度的建模和预测能力还将获得进一步提升。

个体尺度:预测未来的临床风险
个体尺度的医学预测聚焦于对未来具体事件的风险进行量化,包括事件发生的时间窗、风险阈值以及相应的干预措施。例如,AI模型可预测患者在未来12个月内的再入院风险、未来18个月内认知功能下降的概率,或治疗后出现不良反应的可能性,并输出校准后的风险区间与反事实情景,用于指导临床决策。
电子健康记录(EHR)数据是当前最具可用性的个体预测数据基础。例如,NYUTron模型基于超过400万份住院病历进行训练,可在不同医疗机构之间精准预测住院死亡、再入院、住院时长以及医保拒付等未来事件。NYUTron已完成跨机构的外部验证和实际临床部署,体现了EHR数据在纵向覆盖与时序分析方面的显著优势。然而,单一模态数据的预测能力上限已较为明晰,因此需要结合其他模态数据以提高预测的提前量和实际干预的可操作性。
阿尔茨海默病的预测实践展现了多模态数据融合的价值。通过整合国家级登记系统中的大规模EHR时序数据,AI模型可在临床确诊前约7年识别显著升高的个体患病风险,为干预和密切监测创造了提前窗口。在遗传层面,多基因风险评分(PRS)已经通过临床级验证;例如eMERGE网络在多族裔人群中对多种疾病进行了PRS评估,提供了低成本、可扩展的个体风险分层工具。血液生物标志物(如p-tau217)与未来病程存在剂量-反应关系,可与遗传风险评分互补使用;而蛋白质组学驱动的“脑龄”或“认知衰老钟”则进一步细化了个体间的风险排序。
影像技术也在多模态预测中提供了额外的非侵入式信号,例如通过视网膜成像表型作为神经退行性疾病的早期筛查工具,提升了筛查的覆盖面与可行性。此外,可穿戴设备与居家传感器采集的睡眠、步态、活动节律、心率变异等高频数字生物标志物,已在神经退行、代谢疾病和心律失常的早期风险预测中表现出明显的价值。将上述模态数据整合为分层递进的个体化风险函数,有助于临床决策者确定行动阈值,提前启动干预方案或个性化的随访管理。
胰腺癌预测则体现了个体预测在低患病率与早期隐匿疾病中的挑战与价值。大规模研究证实,基于EHR时序的学习模型能够在诊断前3至36个月识别出高风险个体,以触发定向影像复核路径。研究还发现新发2型糖尿病与胰腺癌的近期风险跃升存在紧密关联,适合作为规则化结构特征嵌入到预测模型中。在影像诊断层面,端到端的CT AI模型在真实世界数据集中表现出较高的灵敏度,可提前识别可疑病灶,形成从EHR预警到影像复核再到临床介入诊断的完整预测路径。
多癌种的群体级早筛研究进一步凸显了个体化预测的重要性。在PATHFINDER研究中,6621名受试者中仅1.4%检测出癌症信号,真阳性率仅为0.5%,揭示传统“一次性群体筛查”的局限性。研究者由此强调,应基于个体化风险预测的前置分层提高筛查效率与干预的性价比。阿里巴巴达摩院团队的系列工作,则进一步展示了影像AI如何在大规模癌症筛查中实现更精细的风险分层与个体化预测,从而克服传统大规模筛查在医学统计上的疏漏。同时,对于阿尔茨海默病等慢病,越来越多证据支持将环境暴露(如PM2.5和NO2)纳入个体化风险函数,并作为医学预测与环境干预闭环的重要组成部分。
个体医学预测的有效交付,需要明确输出风险概率区间与事件发生的具体时间分布,并给出与临床决策直接关联的行动阈值。这些预测的临床价值,必须通过外部队列的性能、公平性与稳健性等多维度验证进行严格评估。同时,模型评价标准也应从单纯的预测准确率,转向更具实际意义的预测提前量、临床转归改善以及减少不必要检查等具体维度。
跨尺度的数据整合可提升个体预测的可靠性:向下,利用组织器官与通路层的数据和机制知识提高预测结果的生物合理性;向上,则基于真实世界数据的个体预测轨迹,辅助临床试验设计与公共卫生策略优化,形成从机制解释到群体决策的完整路径。最终,通过广泛和深入的数据收集与模型分析,我们能够将未来的健康风险转化为可提前实施的干预计划,并在真实医疗场景的实践与外部验证中不断完善校准。

结语:跨尺度融合与医学数据生态展望
生命系统的多尺度特性使医学预测的有效临床落地高度依赖于跨尺度融合方法。近期涌现的实践案例证明,通过合适的接口设计,就能实现低尺度的机制理解向高尺度的临床风险预测转化。例如,LUCID模型通过跨模态注意机制整合病理影像、放射影像与基因表达数据,成功预测了肺癌患者的预后与分子亚型。药物肝毒性(DILI)数字孪生模型则将全身药代动力学与细胞毒性机制耦合,精准预测患者的肝损伤风险,完成了严谨的外部队列验证。此外,前述Recursion团队提出的P-E-D(预测-解释-发现)方法论,也已展示跨尺度模型如何在细胞尺度向器官尺度与个体尺度逐步泛化。
然而,跨尺度方法的有效实施必须依赖高质量的数据生态支撑。Human Cell Atlas细胞图谱绘制了健康与疾病状态下的细胞类型与分子标记,为细胞尺度预测提供了参照体系。组织尺度方面,癌症影像档案(TCIA)整合了大量肿瘤影像与临床治疗、预后数据,支持了组织尺度的精准风险预测。而个体尺度则受益于MIMIC-IV数据库,这一资源整合了数万名重症患者的连续电子健康记录数据,已广泛用于临床风险的时序预测与患者结局的前瞻预警。此外,UK Biobank与All of Us等长期随访数据也已显示出对个体尺度健康风险前瞻性预测的重要价值。
尽管如此,目前跨尺度预测与数据生态建设仍然面临严峻的现实挑战,其中数据标准化与跨尺度对齐最为突出。医学数据生态的构建需要严格的数据术语体系与标准数据模型,例如OHDSI的OMOP通用数据模型与HL7的FHIR数据交换标准,但这些标准在实践层面尚未实现充分有效的执行。此外,多模态数据的整合与跨尺度预测的可信性问题也尚未完全解决,临床上仍缺乏统一的预测金标准与的可信性验证框架。目前主流的验证-确认-不确定性量化(VVUQ)方法,要求跨尺度接口必须有对输入变量的统计分布与不确定性评估,然而在临床应用中尚未广泛实施。
因此,当前阶段医学预测走向真实临床应用的关键,绝不是继续盲目增加模型与数据的复杂性,而是优先解决跨尺度接口方法的稳定性与数据生态的可信性问题。跨尺度融合接口和高质量的数据生态建设,仅是实现临床前瞻性预测的第一步,只有在此基础上落实临床环境下的可信性验证,才能真正使医学预测走出实验室,成为个体化临床决策与前瞻干预的有效工具。
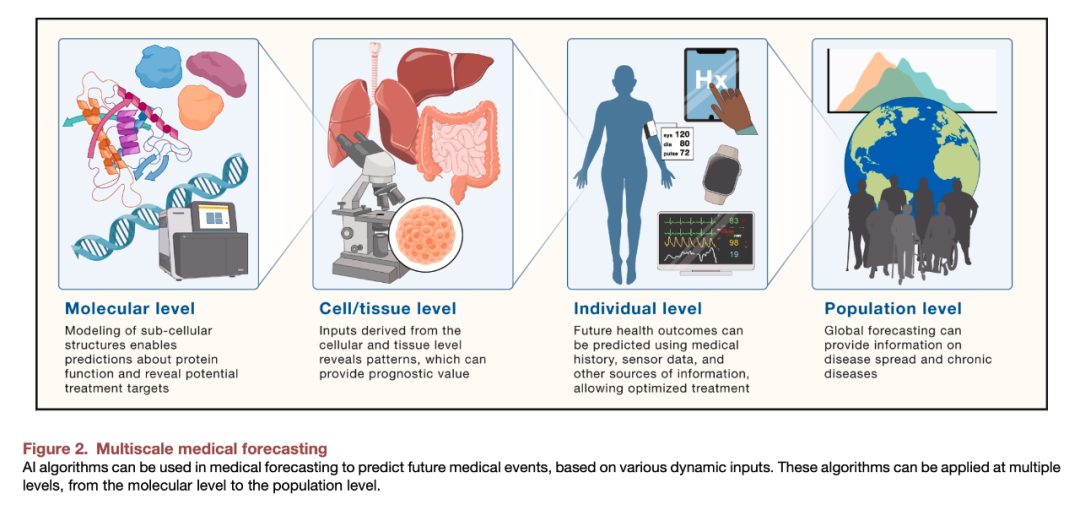
图2:多尺度医学预测概览
从经典的“基因型—表型”生物医学框架,到当前“多模态数据+多尺度模型”的新兴路径,我们愈发认识到,仅靠单一尺度的建模与预测已不足以精准描述疾病过程,更难以有效指导个体患者的临床干预。随着人工智能(AI)等技术快速发展,多尺度医学预测的框架正在形成:整合多维度、多尺度的数据与机制,以更完整地预测疾病的发生、进展与个体差异,并为精准医疗提供依据。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 0
0 0
0- 0



 已为社区贡献119条内容
已为社区贡献119条内容

所有评论(0)