HEAD——视觉驱动下的自主配送(本质是VLN):高层规划器发出手部和眼部的目标位置与朝向指令,低层全身控制策略则执行导航与触达,暂无法抓取
前言
我在解读CHIP、WholeBodyVLA这两个工作时,这两都提到了本文要解读的HEDA
第一部分 HEAD之手眼自主配送:人形导航、运动与触达的学习
1.1 引言与相关工作
1.1.1 引言
来自斯坦福的研究者提出了一种面向人形机器人的手眼自主递送(hand-eye autonomous delivery,HEAD)系统,旨在充分利用其类人形态结构,以协调的方式同时完成导航、运动和触达任务
- 论文地址为:Hand-Eye Autonomous Delivery: Learning Humanoid Navigation, Locomotion and Reaching
作者包括
Sirui Chen, Yufei Ye, Zi-Ang Cao, Jennifer Lew, Pei Xu, C. Karen Liu - 项目地址为:stanford-tml.github.io/HEAD
GitHub地址为:github.com/Stanford-TML/HEAD_release
如下图所示,在用户从类人机器人的自我中心视角中选定目标后,人形机器人能够在三维世界中导航并到达该目标
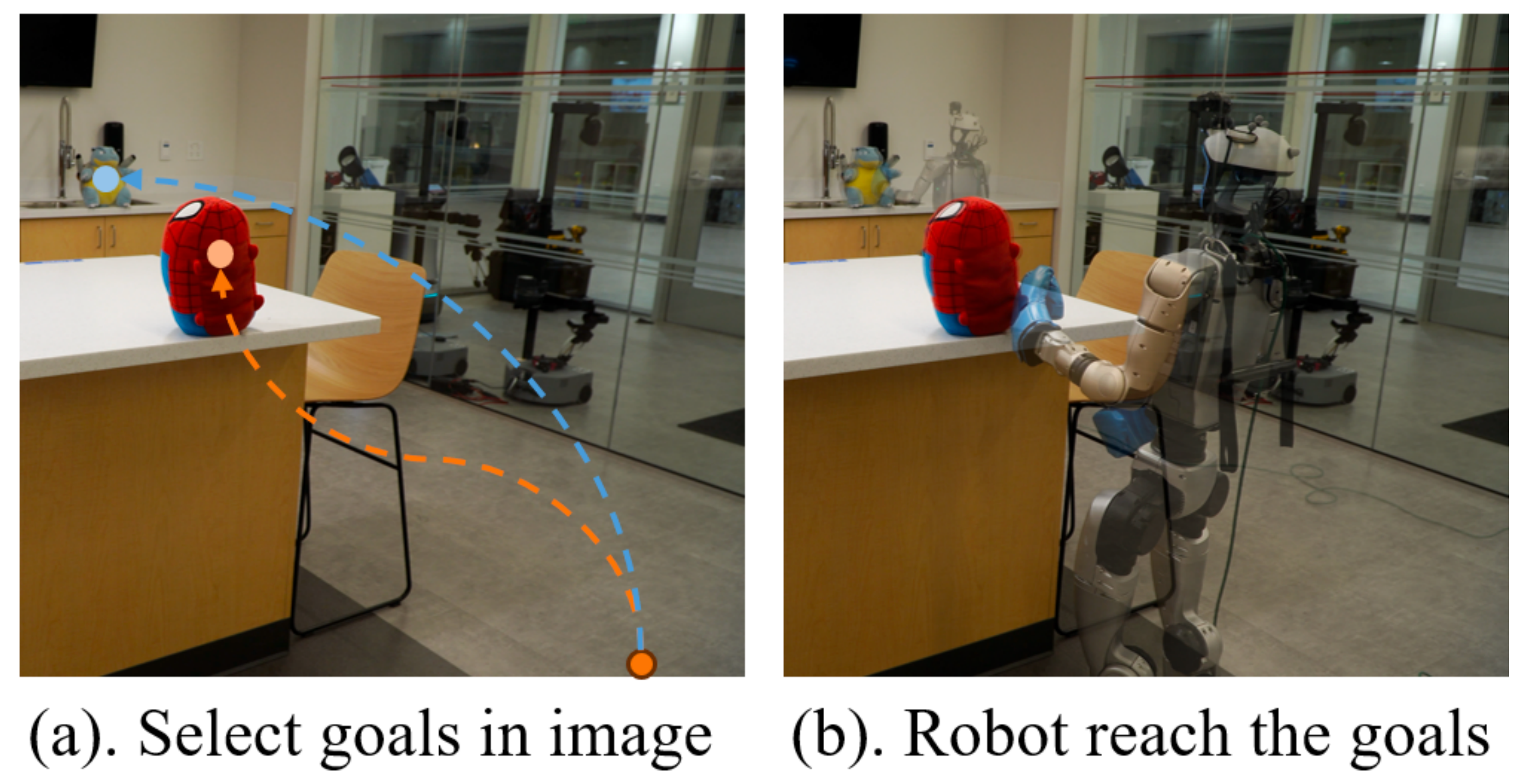
- 尽管从人类示范中学习是一条很有前景的途径,但要端到端训练这三种技能,需要同时包含第一人称视觉和全身动作的异质人类数据
为此,作者采用了一种模块化方法,将自我中心视觉感知与物理动作解耦,从而能够灵活地利用不同来源的人类数据和不同算法来训练全身导航、运动和触达 - 这一设计也缓解了训练统一视觉-运动策略所面临的挑战
HEAD框架由一个高层策略和一个低层控制器构成:高层策略预测仿人机器人眼睛和手部的目标位置与朝向,低层控制器则执行对应的全身运动
在接收到“伸手并触碰某个物体”的指令后,该物体由人形机器人在其感知到的初始RGB 图像中的一个点来指示
- 高层策略预测头部的位置与朝向,从而在保持目标始终处于视野的同时,引导人形机器人朝目标移动并绕开障碍物
当目标进入手臂可及范围后,高层策略还会控制双手与该物体接触
现有的视觉导航方法
1-Learning robotic navigation from experience: principles, methods andrecent results
2-Navila
通常将机器人抽象为质点,将动作限制为在地面平面上的 2D 移动
此类假设适用于轮式机器人,但对于双足人形机器人却远远不够:双足人形机器人必须协调一具多关节身体,在复杂的3D 空间中导航,同时在不同高度上伸手去够物体并避开障碍物 - 为实现这种 3D 导航能力,作者的方法针对不同目的混合利用多种数据集——使用互联网上的大规模人类探索数据集来提升对新场景的泛化能力
在目标环境中收集中等规模的示教数据以缓解感知带来的领域偏移
低层全身控制器通过大规模人体动作捕捉数据进行训练,以跟踪三个关键点——眼睛(其决定朝向)、左手和右手
作者采用基于模仿的RL进行训练,利用大规模数据集的多样性来处理各种各样的目标配置
使用基于模仿的 RL 训练这样的全身策略面临三个主要挑战
- 首先,与全身跟踪不同,HEAD的目标在空间上是稀疏的,只约束三个点
作者通过构建一个基于 GAN 的强化学习框架来应对第一个挑战,该框架模仿人类示范数据的分布,而不是依赖具体的全身轨迹作为策略输入 - 其次,全身技能要求上半身和下半身能够同时执行不同任务,这需要大量示范样本来覆盖联合动作空间
为解决第二个挑战,作者设计了两个独立的判别器,分别对上半身和下半身给予奖励,从而促进两者之间的可组合性和协调性 - 第三,在真实环境中很难获取精确的根节点位置和速度信息,因此需要一种在没有精确根节点数据情况下依然有效的更鲁棒的策略
为了解决第三个挑战,作者训练的策略不依赖于世界坐标系中的根节点位置或速度;相反,全局信息由导航目标推断,并通过机载摄像头进行估计
1.1.2 相关工作
首先,对于从人类数据中学习
- 随着人形机器人的日益普及,利用人类数据来训练仿人机器人开始受到关注
互联网规模的人类视频为训练提供了海量数据源,使其适合用于预训练隐式视觉表征
3-R3m
4-An unbiased look at datasets for visuo-motorpre-training
5-Open x-embodiment
但由于具身形式和观测方式存在差异,使得这类数据在学习特定技能时效率较低、相关性较弱 - 近期研究表明,高质量且与任务密切相关的人类数据可以有利于机器人训练,用于既包括桌面操作
6-Egomimic
7-Dexcap
8-umi
也包括室内导航
2-Navila
最新工作提出了多种富有创意的数据采集方式,各有侧重
针对便携式设备,如
VR 头显 [9-Arcap]
AR 眼镜 [10-Project aria]
或SLAM 相机[7-Dexcap]
可以捕获多模态的人体数据,包括头部和手部位姿,并且这些数据可以方便地映射到机器人上
————
尽管不同任务通常需要不同形式的人体数据才能实现有效学习,作者主张采用与三点跟踪相接口的模块化系统,以联合实现导航、到达和运动控制
其次,对于人形机器人全身控制
- 近年来,人形机器人硬件的进步使人形机器人在学术研究中变得更加易于使用
为了让人形机器人完成有意义的任务,全身控制器(whole bodycontroller,WBC)在保持人形机器人平衡和协调全身运动方面起到基石作用
传统上,基于最优控制的全身控制器
11-Crocoddyl
12-Optimization-based locomotion planning, estimation, and control design forthe atlas humanoid robot
13-A compliant hybrid zero dynamicscontroller for stable, efficient and fast bipedal walking on mabel
在给定需要跟踪的详细运动学轨迹的前提下,使人形机器人能够行走、跳跃,并在具有挑战性的地形中移动
然而,这类高质量的运动学轨迹难以获取,并且高度依赖于具体机器人的运动学结构 - 近年来,基于RL的全身控制器在直接从人体数据中学习方面表现出令人瞩目的效果
14-Deepmimic
15-Perpetual humanoid control for real-time simulatedavatars
16-Humanplus
17-H2O
18-Exbody2
其中,大多数 WBC 被设计为跟踪人体关节位置[14,15,16,17],这就需要将人体全身姿态作为输入 - 为利用更稀疏、且更易通过虚拟现实(virtual reality,VR)设备捕获的输入
19-Omnih2o
20-Hover
21-Questsim
构建了跟踪人体头部和手部位置的 WBC,而这些位置可以通过现成的 VR 头显精确获得
另一种方案是类似[22-Mobile-television] 使用 VR 头显和脚踏板分别控制上半身和下半身
HEAD采用与[20-Hover,19-Omnih2o]类似的头部和手腕跟踪作为 WBC 的接口,因为这种方式允许在任务空间中直接迁移人体数据
与之前的方法相比,HEAD的 WBC 还会跟踪头部和手腕的朝向,从而支持更为多样的操作技能,例如扭转手腕
最后,对于导航
- 以往在视觉导航领域的大量研究,大多将机器人视为在二维平面上运行的质点
在长期导航中,已有工作采用了多种不同的探索策略
从局部方法
23-robot exploration and mapping strategy based on a semantichierarchy of spatial representation
24-Information based adaptive robotic exploration
全局方法
25-Minerva
26-A frontier-based approach for autonomous exploration
27-A comparative evaluation of explorationstrategies and heuristics to improve them
到端到端学习以目标为导向的策略
28-Gated-attention architectures for task-oriented language grounding
29-Human-level control through deep rein-forcement learning
30-Nomad: Goal masked diffusion policies fornavigation and exploration
并通过在平面图上的路径点或语义地标上进行规划,以在大空间环境中实现稳健的性能
短期导航同样依赖这种二维抽象,但更侧重于符合社会规范且具有响应性的行为——包括动态避障和人机交互
31-Sacson: Scalable autonomous control for socialnavigation
32-Human-robot proxemics: physical and psychological distancing inhuman-robot interaction
33-Corechallenges of social robot navigation: A survey - 与HEAD的工作最接近的是基于人形平台的 NaVila 『详见此文《NaVILA——可语音交互的用于四足和人形导航与避障的VLA模型:在VLM的导航规划下,执行基于视觉的运动策略(LiDAR点云构建高度图)》』
它将长时域的二维路径点导航应用于双足机器人,但将感知与运动分离,并忽略了全身触达
————
相比之下,HEAD的方法通过全身控制直接研究短期三维导航,并致力于减轻人类与类人机器人之间在具身上的差异
1.2 HEAD的完整方法论
给定机器人在初始 RGB 图像上选定的一个点,HEAD 使得人形机器人能够用手在真实三维物理世界中到达该点
HEAD 是一个模块化系统,由用于导航和触达的高层策略和用于全身控制的低层策略组成(见图2)
HEAD 由一个包含导航和到达两个模块的高层策略,以及一个协调全身运动的低层策略组成
- 高层策略以较低频率提供手眼跟踪目标
基于学习的导航模块从混合训练数据集中学习,将RGB 自我视角感知映射为相机目标轨迹
基于模型的到达模块生成手眼目标位姿- 而全身控制器则以较高频率跟踪这些手眼目标
低层全身控制器使用基于模仿的强化学习,在一组人体动作捕捉数据上进行训练
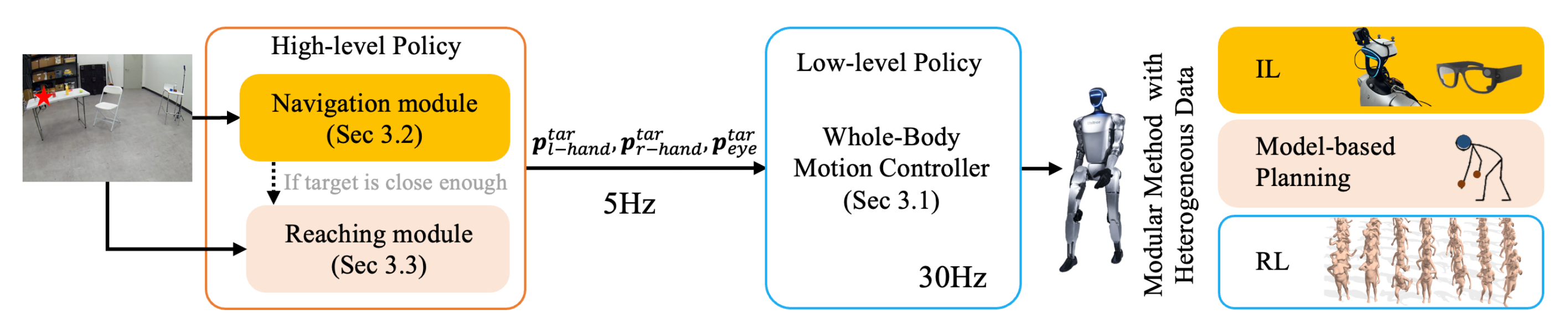
其核心思想是:导航与触达这两项任务都可以通过对同一个低层全身策略下达指令来完成,该策略负责跟踪头部和双手的 6D 位姿
1.2.1 全身控制器
在高层策略给定目标手-眼位置和姿态的情况下,低层全身控制器通过 PD 伺服器来控制人形机器人
- 为使人形机器人在跟踪任意目标的同时表现得更接近人类,作者在RL框架下,采用类似 GAN 的方法[34-A gan-like approach for physics-based imitation learning and in-teractive character control],从非结构化运动数据中进行动作模仿,并结合面向目标的位置和姿态跟踪控制
模仿人类操作中的手-眼位姿,特别是眼的位姿,这个HEAD是我目前所知的第一个工作了 - 不同于两阶段的蒸馏方法[35-Humanoid policy˜ human policy,19-Omnih2o],HEAD的方法以端到端方式训练低层控制策略,以便部署到真实世界
第一,作者特地整理了人体运动数据集
- 作者发现,动作重定向的质量会显著影响策略性能
故作者通过将来自 AMASS [36] 和 OMOMO [37] 数据集的人体动作捕捉数据重新定向到 G1 机器人,整理了一个 5 小时的数据集 - 该重定向是通过类似于[17-H2O] 的关键点匹配实现的
所收集的运动总体上涵盖了操作与运动两个领域的代表性行为。数据集将在论文被接收后开源
第二,部署的观测空间
为了支持在真实环境中的部署,观测空间必须限制为机器人机载传感器可获取的信息
- 作者的观测向量由机器人局部坐标系中两个连续时间步的机器人连杆位姿
和局部的关节速度
构成
- 它不包含任何未来信息,也不依赖世界坐标系中的任何特权数据,例如根部位置和线速度,这些在仿真之外很难获取
作者发现,去除对特权信息的依赖,其效果优于任何依赖重建或预测替代量的其他方法
第三,运动模仿
作者将全身运动解耦为上半身和下半身两组,并同时使用两个判别器来进行模仿学习
- 通过这种方式,策略可以学习来自上下半身部位姿态的组合,而不再受限于动作数据集中提供的固定全身姿态
- 类 GAN 的强化学习方法使得策略能够从动作数据集中的任意片段进行动作模仿,而无需事先生成或获取完整的模仿轨迹,同时还可以完成跟踪任务
第四,稀疏目标跟踪
- 为了避免在全局空间中引入目标信息,作者通过相对变换来表示跟踪目标,作为策略网络的输入
其中表示相对变换算子,”tar” 表示目标姿态
- 为了执行跟踪
在训练过程中,作者在每个时间步执行动作之后,基于定义以目标为导向的奖励
第五,针对sim2real的考虑
除了目标跟踪的任务奖励之外,作者另外定义了一个正则化项,以辅助实现从仿真到现实的迁移
- 为进一步提升鲁棒性,作者在训练过程中对动力学参数和传感器噪声进行大范围的域随机化
- 且采用文献 [38-Composite motion learning with task control] 中提出的多目标学习框架来进行策略训练,同时利用判别器给出的奖励来优化两个模仿目标,并通过人工定义的奖励函数来优化目标导向的目标函数。实现细节请参见补充材料
1.2.2 导航模块
给定一个能够跟踪三个点的低层次全身控制器,HEAD的导航模块将机器人引导至一个目标,该目标被指定为机器人初始观测到的RGB 图像中的一个2D 点
在推理过程中,导航模型从导航相机获取当前RGB 图像以及由点跟踪器[39-Co-tracker3: Simpler and better point tracking by pseudo-labelling real videos] 提供的已跟踪2D 目标,并预测未来眼睛在位置和朝向上的轨迹(见下图图3 右)
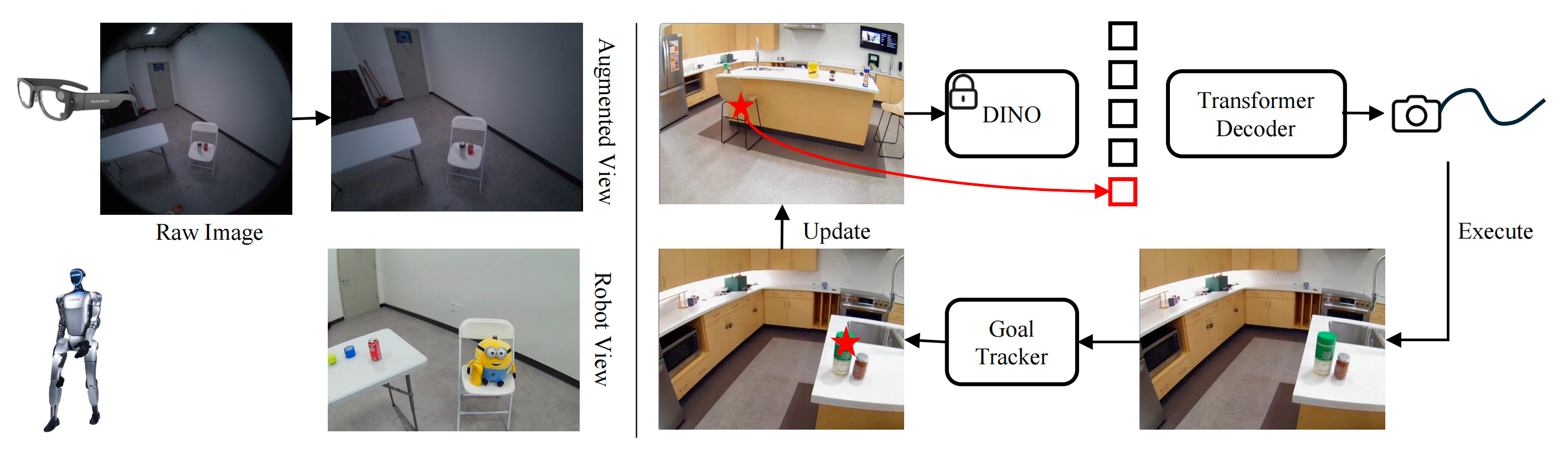
- 导航训练数据(左):作者对从 Aria Glasses 采集的图像进行增强(去畸变和单应变换),使其看起来更像机器人的视角
- 导航模块概览(右):在推理过程中,给定一幅图像和一个以二维点形式表示的目标,提取 DINO 特征,附加目标坐标,并将它们输入 transformer 解码器,以预测未来的眼睛(摄像头)轨迹
低层全身控制器执行该预测并获得新的观测。随后,利用现成的点跟踪器在新的图像中跟踪该目标
具体来说,作者提取输入图像 的DINO 特征,并向目标
添加位置嵌入。然后将它们输入到一个transformer 解码器中,以输出未来的相机轨迹
,该轨迹相对于前一帧表示为变换
- 收集人类数据
作者提出了一种自动化方法,利用Aria 眼镜来收集以目标为条件的人类训练数据,这些数据以图像、未来相机轨迹和二维目标的元组形式表示
眼镜为所有采集到的数据提供精确的相机位姿、静态点云和视线估计
—————
作者通过在未来视线向量方向上,在静态点云中找到最近的点,并通过当前的相机位姿将其投影到图像平面上,来近似当前目标 - 领域偏移
然而,仅在有限的人类数据上训练得到的导航模型在两个需要解决的潜在领域偏移方面表现不佳
此外,作者还通过控制机器人执行导航任务,并使用动捕mocap系统记录其头部位姿,从而收集少量机器人数据,并使用人类数据和机器人数据共同训练导航模块
1.2.3 到达模块
当导航模块在房间尺度上驱动机器人朝目标物体前进时,触达(reaching)模块负责最后的接近以触碰该物体。作者为触达使用第二个向下朝向的 RGB-D 相机,其视场(FoV)更窄并进行了放大
高层策略在从导航切换到触达时,低层策略持续运行,以确保平滑过渡
- 首先,对于导航-触达过渡
当目标物体进入俯视RGB-D 相机的视野并处于可触达范围内时,导航策略将控制权移交给触达模块
通过对应关系匹配 [41-Loftr: Detector-free local feature matching with transformers],将目标从原始坐标系转换到 RGB-D 帧中 - 其次,对于到达目标
到达模块将目标近似为一个三维手部位置,并计算目标手部朝向以及头部的6D位姿,以用于低层策略
由于被跟踪的目标只指定了手部位置,作者使用 Mink [42-Mink: Python inverse kinematics based on MuJoC] 求解逆运动学 (IK),以推断缺失的头部姿态和手部朝向
为了保证高层动作之间的平滑过渡并使机器人的姿态看起来自然,作者从当前的机器人状态初始化IK 优化,并添加一个目标项,以鼓励质心位置和骨盆朝向的变化尽可能小
1.3 实验
接下来,逐一介绍
- 硬件配置
- 以及作者在不同环境下使用新颖物体对整个手眼协同投递系统进行评估
- 分别分析各个模块——全身控制器的设计选择
- 以及用于训练导航模块的各类数据要素各自的贡献
1.3.1 硬件配置
作者基于一台 Unitree G1 仿人机器人搭建所提出的系统,如图 5 所示

- 用于导航时,作者使用一款广角 USB 摄像头,其水平视场角为 90°(HFOV)、垂直视场角为 67.5°(VFOV)
- 用于到达模块,作者使用 G1 内置的 RealSense D435 RGB-D 相机
在部署过程中,所有模块均运行在一台配备 RTX 4090 GPU 和 i9-14900K CPU 的 PC 上,机器人通过以太网连接进行控制 - 最终作者在两个房间中开展实验:一个实验室(训练房间)和一个厨房(部署房间)
仅在实验室房间中采集与机器人相关的训练数据。这样做是为了模拟一种部署场景:在该场景下,没有可用的硬件来记录机器人的真实训练数据
在每个房间中,作者摆放若干件家具(例如,书架、椅子、桌子、凳子),以构造多样化的布局
所有测试时使用的布局和物体在训练阶段均是未见过的
1.3.2 不同场景下的全身触及动作
作者在每个房间中针对三种不同的布局对HEAD方法进行评估
对于每种布局,机器人被要求到达4 个放置在不同位置和不同高度的物体,如图Fig. 5.c 所示
详细的实验结果如表Tab 1 所示
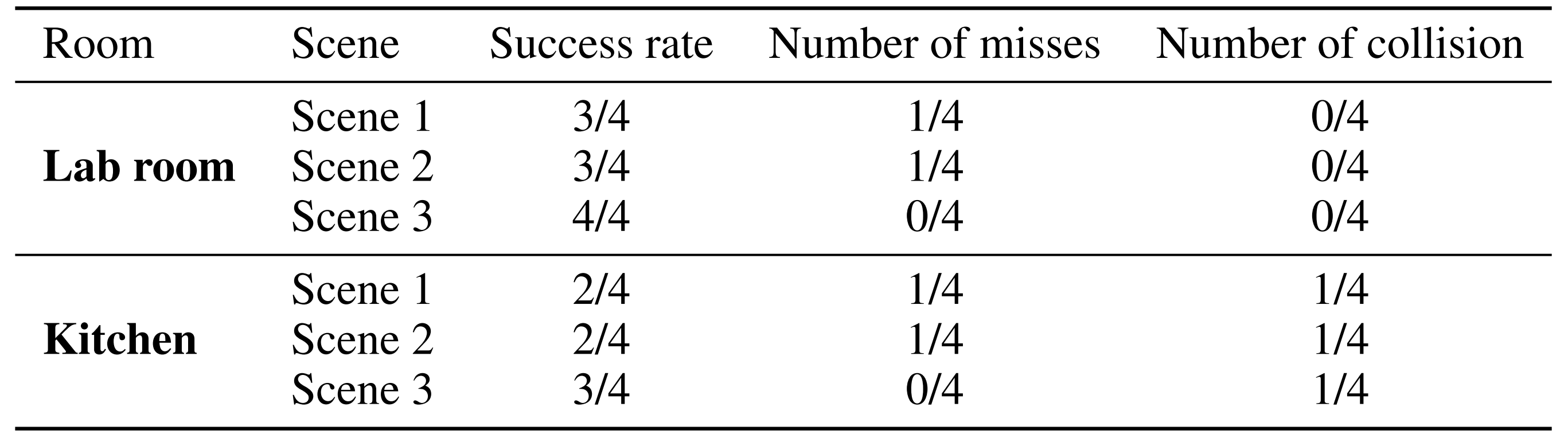
总体而言,HEAD方法在不同环境中达到了71 % 的成功率。实验室房间中的成功率比厨房高25 %,而厨房拥有更狭窄的走廊和更多的反光表面,这对目标追踪器、导航Transformer 和转换模块提出了挑战
对于失败的情况,机器人运动产生的运动模糊可能导致追踪器丢失目标或追踪到错误的目标,从而干扰导航模块
此外,人类在采集数据时往往移动得更快、路径也更加激进,而这对于机器人来说可能不可行,并可能导致碰撞
1.3.3 全身控制器的性能
作者在Isaac Gym 中训练HEAD的全身控制器,并在两个仿真环境中报告其性能:Isaac Gym [43] 和MuJoCo [44]
- 由于策略是在Isaac Gym 中训练的,表2 左侧报告的性能突出了训练过程中设计选择的影响
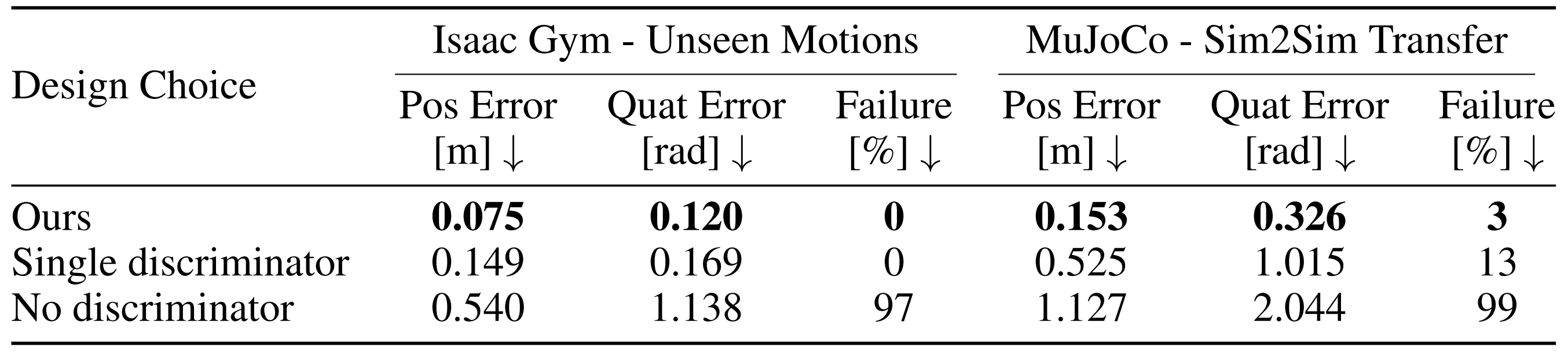
- 此外,在表2 右侧中,在MuJoCo 中进行的仿真到仿真的评估进一步量化了当模拟的接触模型更接近真实世界时[45] 各个策略的鲁棒性
且作者观察到,利用生成对抗网络GAN来引导RL的探索,可以大幅提升样本效率。与使用一个对整体全身运动进行联合评判的单一判别器相比,作者发现,通过来自两个判别器的分别奖励,将上半身与下半身运动解耦更加有效
- 其原因很可能在于,独立的判别器可以在训练过程中避免策略将彼此无关的运动纠缠在一起,从而获得更低的跟踪误差
例如,在大多数行走片段中,人们会自然摆臂,而双臂操作通常发生在下蹲姿态下。使用单个全身判别器训练得到的策略,往往会记住摆臂模式,因此在行走时需要搬运箱子时就难以处理 - 相反,HEAD的设置将手臂操作从平衡控制中解耦,使得全身控制器在三点跟踪条件下能够产生更加多样的运动
在未见过的任务中,HEAD的策略始终优于使用单一全身判别器的变体
1.3.4 导航模块的性能
作者使用 Aria Glasses 在每个房间收集 200 段人类视频片段(H-Lab/H-Kit)
对于机器人数据(R),使用动捕系统分别在
- 实验室收集 38 段机器人轨迹片段
在实验室机器人数据中,24 段用于训练,14 段用于测试 - 在厨房收集 20段
所有厨房中的机器人片段均用于测试
每段片段时长约为 4 秒(人类)或 30 秒(机器人)
这样做是为了模拟一种部署场景,即没有可用设备来记录机器人的真实值训练数据。人类目标是通过眼动轨迹进行近似(上文1.2.2节导航模块,对应于原论文第 3.2 节),而机器人的目标则由人工标注并进行跟踪
作者还包含了分布外的 ADT 数据集 (O)[40],其中包含 400 分钟的 Aria 眼镜拍摄的视频,记录了用户执行清洁、烹饪等任务的过程
- 度量指标
在实验室房间和厨房这两个环境中报告开放环预测性能。对于每个测试视频,我们在每一个时间步预测一个长度为 10 步的轨迹,并在展开这些预测后,将其与真实轨迹进行比较,计算平均误差
如果最终误差在 0.6米以内,则认为该预测是成功的,这大致对应于人形机器人有效操作范围 - 用于导航的人机数据融合方案
如表 3 中 Lab Room 列所示,仅使用域内的人类数据(H-Lab)进行训练,相比使用域内的机器人数据(R-Lab)训练,会导致较低的成功率,这很可能是因为模型没有学到人类与机器人在具身形态上的差异
采用域内机器人数据(R-Lab)并结合人类数据『无论是来自分布外环境的数据(O),还是来自同一域内环境的人类数据(H-Lab)』进行训练,可以进一步提升性能
其中,来自同一环境的人类数据(H-Lab)相较于分布外数据(O)具有适度更大的帮助
总之,通过结合目前所有可用的数据,获得了最佳性能 - 在新场景中部署
正如表 3 中 Kitchen 列所示,虽然仅使用机器人数据进行训练在实验室房间中表现尚可,但无法泛化到新的(部署)房间。单独收集额外的域内人类数据(+H-Kit)就能帮助机器人在新场景中表现更好
————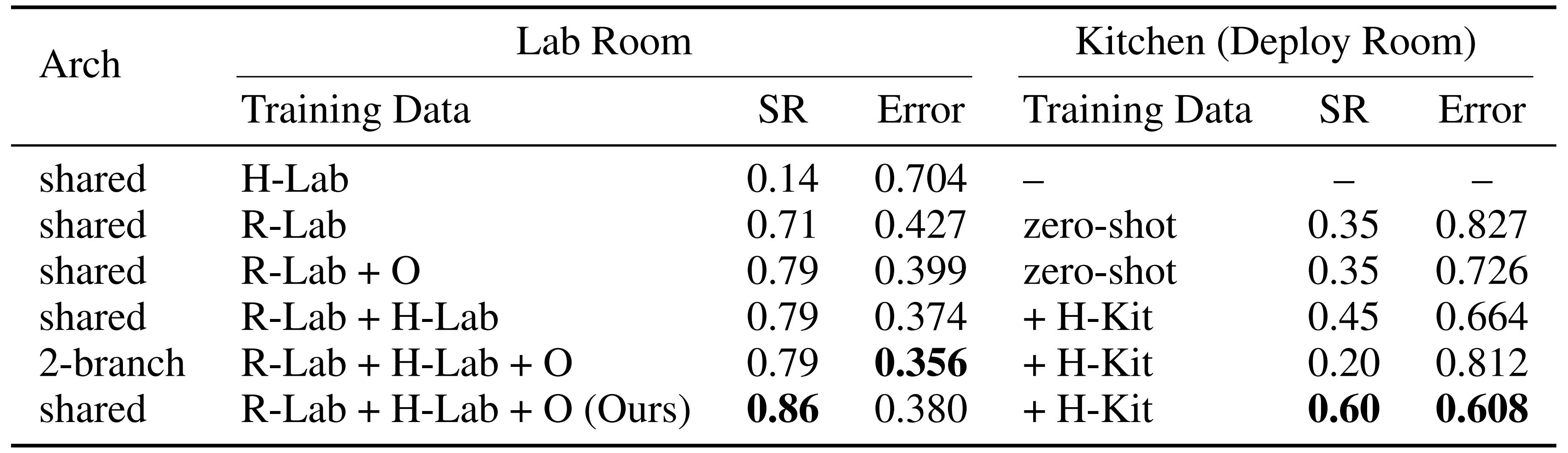
需要注意的是,尽管引入 ADT (O) 并未显著提升在实验室房间内的性能,但却在部署房间中大幅提高了成功率,而该房间中没有任何机器人训练数据
这凸显了利用多样的无标注人类数据来提升跨场景泛化能力的重要性 - 共享解码分支可以提升导航泛化能力
与操作任务中的常见做法[6-Egomimic,35-Humanoid policy˜ human policy]相反,作者发现:在人类与机器人数据之间共享同一个解码分支,能够提升导航任务中的场景泛化能力
故作者推测,这是因为在人类与机器人之间,短期导航中的具身差异小于操作任务中的具身差异,从而使得共享表征更加有效
1.4 结论与局限性
1.4.1 结论
- 总之,HEAD,是一种用于人形机器人导航与到达的自主手眼递送系统。该方法在具有障碍物的两个不同环境中,对放置在不同位置的各类物体进行到达操作时,达到了71% 的成功率
- 未来的扩展工作可以是构建一个通用抓取框架,使其能够抓取放置在不同位置的不同物体
进一步地,学习更加细粒度的全身导航能力,使机器人能够感知并避免身体各部位与环境发生碰撞,也是让类人机器人在真实环境中发挥作用的一个有趣方向
1.4.2 局限性
尽管HEAD可以在存在障碍物的环境中工作,但它只采集人的头部姿态并将其作为机器人控制接口,而没有考虑身体的其他部分
- 对于到达被严重遮挡的目标,人类会利用全身协调来避免碰撞,例如在面对狭窄缝隙时侧身通过,或跨过较低的障碍物
但HEAD方法会导致机器人在面对复杂环境时采取更加保守的策略,不能充分发挥其灵活性 - 此外,将头部和手腕姿态用作仿人机器人控制接口,在控制下半身时存在内在的歧义,可能会使仿人机器人产生犹豫
例如,当 three-point 向前移动时,仿人机器人很难判断其高层意图是要前屈还是向前行走
————
从自我视角设备中可估计到的更多信息(例如足部位姿)可能有助于在采取动作时减少这种犹豫
// 待更

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 20
20 0
0- 0



 已为社区贡献77条内容
已为社区贡献77条内容

所有评论(0)