E0:离散扩散新框架,大幅提升 VLA 模型泛化与操控精度
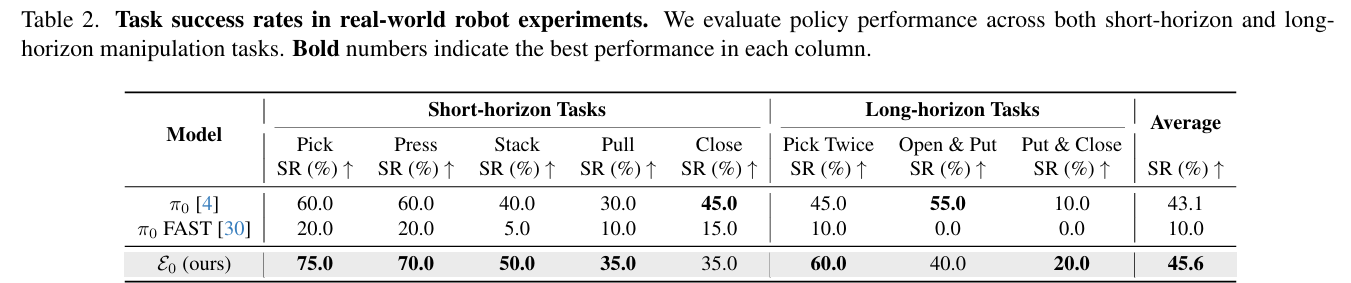
平均成功率45.6%,显著高于π₀(43.1%)和π₀ FAST(10.0%)(table2)。即使在训练数据中未见过的物体位置配置下(如交换红绿方块位置),仍能准确完成堆叠任务(figure5)。以RT1、RT-2、OpenVLA为代表,通过token预测生成动作,与预训练backbone架构亲和,但动作分辨率受限于固定分箱数,细粒度控制能力不足。的架构以PaliGemma开源VLM为backb
一、 研究背景
机器人在开放环境中的操作需要模型具备三大核心能力:复杂视觉场景感知、自然语言指令理解、精准可靠的动作生成。视觉-语言-动作(VLA)模型作为统一框架,通过大规模多模态预训练,旨在实现跨任务、场景和物体类别的泛化,但现有方案仍面临关键瓶颈:
- 泛化能力不足:难以适配多样的任务指令、环境配置和相机视角;
- 动作控制粗糙:生成的动作往往不够精细,在插装、抓取特定图案物体等细粒度操作中易失败;
- 建模范式矛盾:离散建模(自回归、掩码式离散扩散)受限于动作词汇量,连续扩散建模与预训练backbone的符号结构语义错位,且与真实机器人的量化控制特性不匹配。
现有方法可分为两类(见figure1):
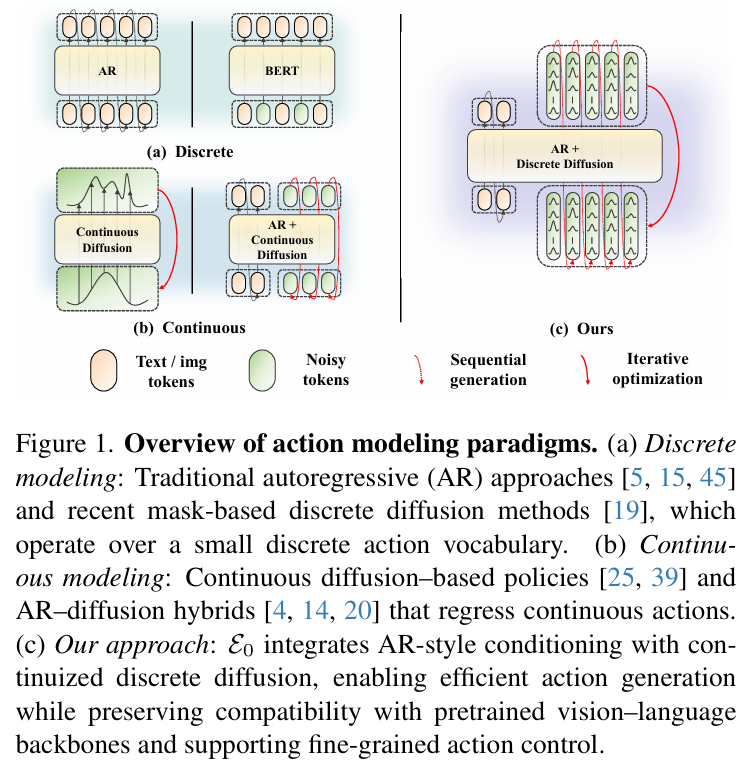
- 离散建模:依赖语言分词器的固定词汇表,动作分辨率有限,掩码式方法存在分布失配问题;
- 连续建模:在欧氏空间操作,与VLM/VLA的符号结构语义脱节,且忽略机器人硬件(控制频率、编码器分辨率)带来的信号量化特性。
二、 核心创新点
针对上述问题,提出 E 0 \mathcal{E}_0 E0框架,核心创新集中在三点:
- 连续化离散扩散范式:将动作生成建模为对量化动作token的迭代去噪,直接对独热动作向量添加高斯噪声,遵循Tweedie公式保持前向-反向一致性,避免掩码式方法的分布失配;
- 灵活细粒度动作表示:支持任意数量的离散分箱(最高可达2048及以上),突破自回归模型256分箱的限制,在不牺牲推理速度的前提下提升动作分辨率;
- 球面视角扰动增强:通过模拟相机在观测球面上的运动生成扭曲图像,结合相对球面嵌入,无需额外数据即可提升模型对相机视角变化的鲁棒性。
三、 主要技术方案
整体架构与建模逻辑
E 0 \mathcal{E}_0 E0的架构以PaliGemma开源VLM为backbone,新增3亿参数的动作专家网络(见figure2(a)),核心逻辑是将连续动作离散化后,通过扩散模型实现迭代优化,同时保留与预训练视觉语言模型的兼容性。
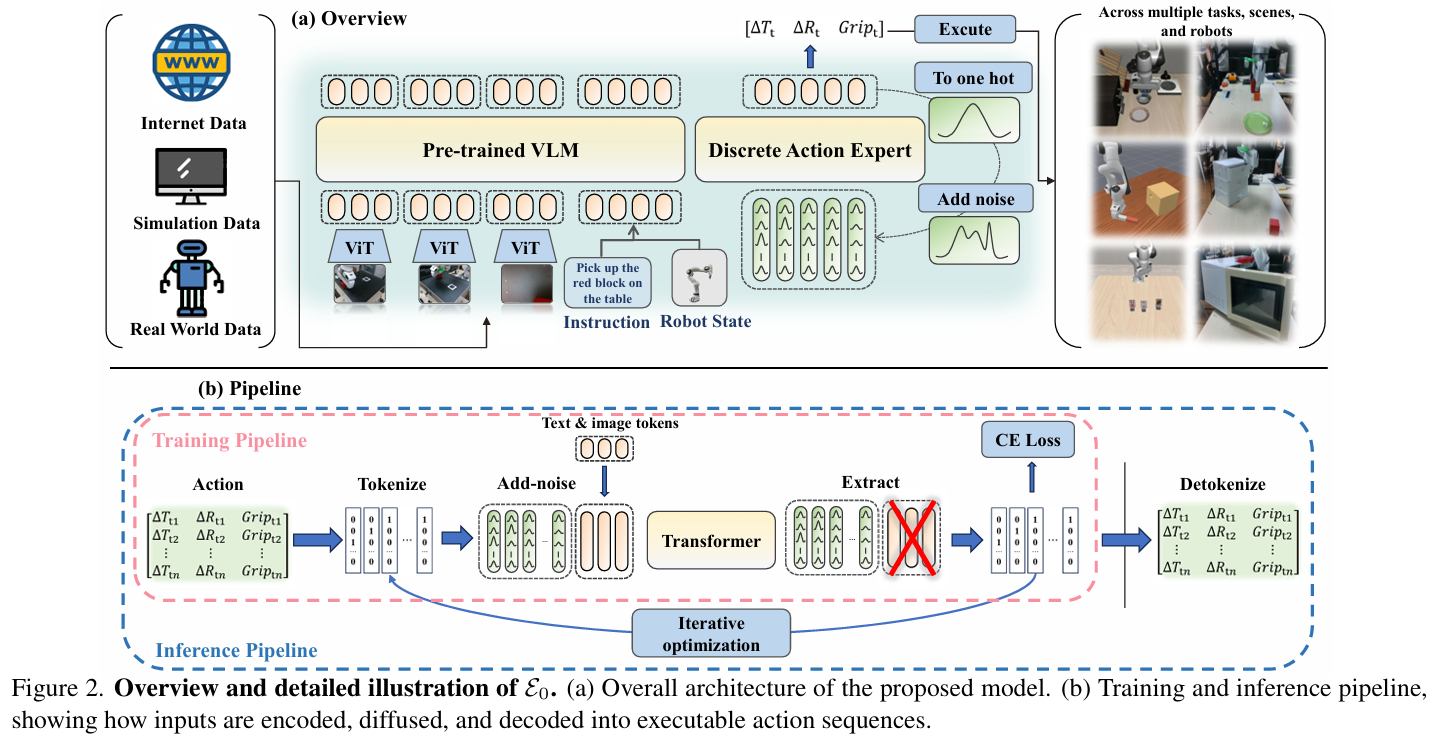
动作表示采用分位数离散化策略,过滤异常值以保证机器人推理的稳定性:
- 单步动作维度: D a = 7 D_a=7 Da=7(3平移+3旋转+1夹爪)或 D a = 8 D_a=8 Da=8(7关节角+1夹爪,适配Franka机械臂);
- 动作块设计:将H个未来时间步的动作组合为动作块,总长度 L a = H × D a L_a=H×D_a La=H×Da,实验中设 H = 50 H=50 H=50以平衡时序一致性与响应性。
训练与推理流程
训练流程(figure2(b))
- 多模态观测编码:将RGB图像、语言指令、机器人本体感受态(关节角)编码到同一嵌入空间;
- 动作离散化:通过1%-N%分位数将连续动作转换为独热向量表示的离散token;
- 高斯加噪:采样时间步 τ ∈ [ 0 , 1 ] \tau \in [0,1] τ∈[0,1](服从Beta分布,偏向高噪声区域),对独热向量添加噪声:
A ~ t τ = ( 1 − α ) ⋅ one-hot ( A ~ t ) + α ⋅ ε \tilde{A}_{t}^{\tau} = (1 - \alpha) \cdot \text{one-hot}(\tilde{A}_{t}) + \alpha \cdot \varepsilon A~tτ=(1−α)⋅one-hot(A~t)+α⋅ε
其中 ε ∼ N ( 0 , I ) \varepsilon \sim \mathcal{N}(0, I) ε∼N(0,I), α = 0.1 \alpha=0.1 α=0.1为平滑因子,用于稳定训练;
- 损失函数:最小化预测token与真实token的交叉熵损失,保证时序一致性。
推理流程
- 初始化噪声动作序列,编码观测生成键值缓存(跨注意力复用);
- 多步迭代去噪:每轮接收当前噪声动作序列与固定观测缓存,预测动作token的分类分布,解码为独热向量后重新加噪进入下一轮;
- 确定性解离散化:N轮迭代后,将最终离散token映射为连续动作,形成可执行的动作块。
球面视角泛化机制
为解决相机视角偏移导致的性能下降问题:
- 球面扭曲:将图像像素反投影到固定深度的3D点,施加偏航角 Δ θ \Delta\theta Δθ和俯仰角 Δ ϕ \Delta\phi Δϕ旋转后重新投影,模拟相机动态视角;
- 相对球面嵌入:定义3D偏移向量 δ = ( d , θ , ϕ ) \delta=(d, \theta, \phi) δ=(d,θ,ϕ)(径向、水平、垂直位移),通过可学习投影函数融入图像token,显式建模相机相对位移。
四、 相关工作
自回归VLA模型
以RT1、RT-2、OpenVLA为代表,通过token预测生成动作,与预训练backbone架构亲和,但动作分辨率受限于固定分箱数,细粒度控制能力不足。 E 0 \mathcal{E}_0 E0保留其上下文对齐优势,同时突破分箱数限制。
扩散基VLA模型
Diffusion Policy、RDT、π₀等采用连续扩散生成动作轨迹,表达能力强但语义对齐弱。 E 0 \mathcal{E}_0 E0将扩散建模迁移到离散空间,兼顾扩散的精细优化与符号结构的语义兼容性。
离散扩散
现有方法多基于掩码建模(如BERT-like掩码),存在分布失配问题。 E 0 \mathcal{E}_0 E0直接对独热向量加噪,通过自回归式反馈机制实现渐进式优化,无需额外架构复杂度即可达到竞争性能。
五、 实验验证
仿真实验
在三大基准(LIBERO、VLABench、ManiSkill)的14个环境中, E 0 \mathcal{E}_0 E0均达到SOTA性能,平均超过基线10.7%:
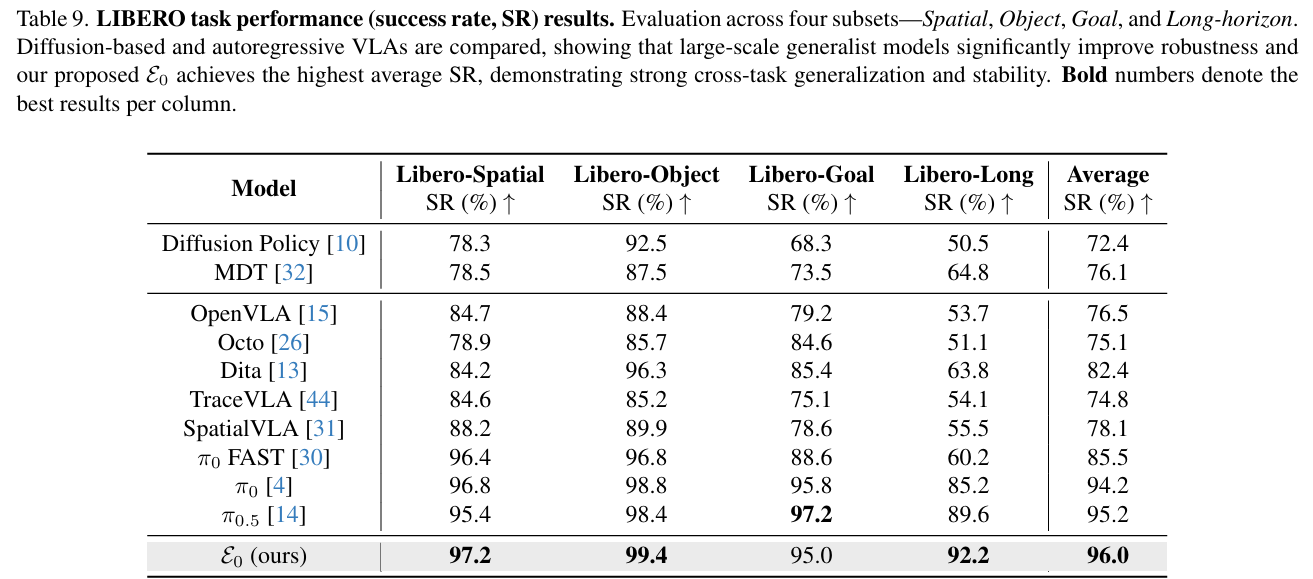
- LIBERO:平均成功率96%,在复杂场景中展现更精准的抓取与指令执行能力(table9);
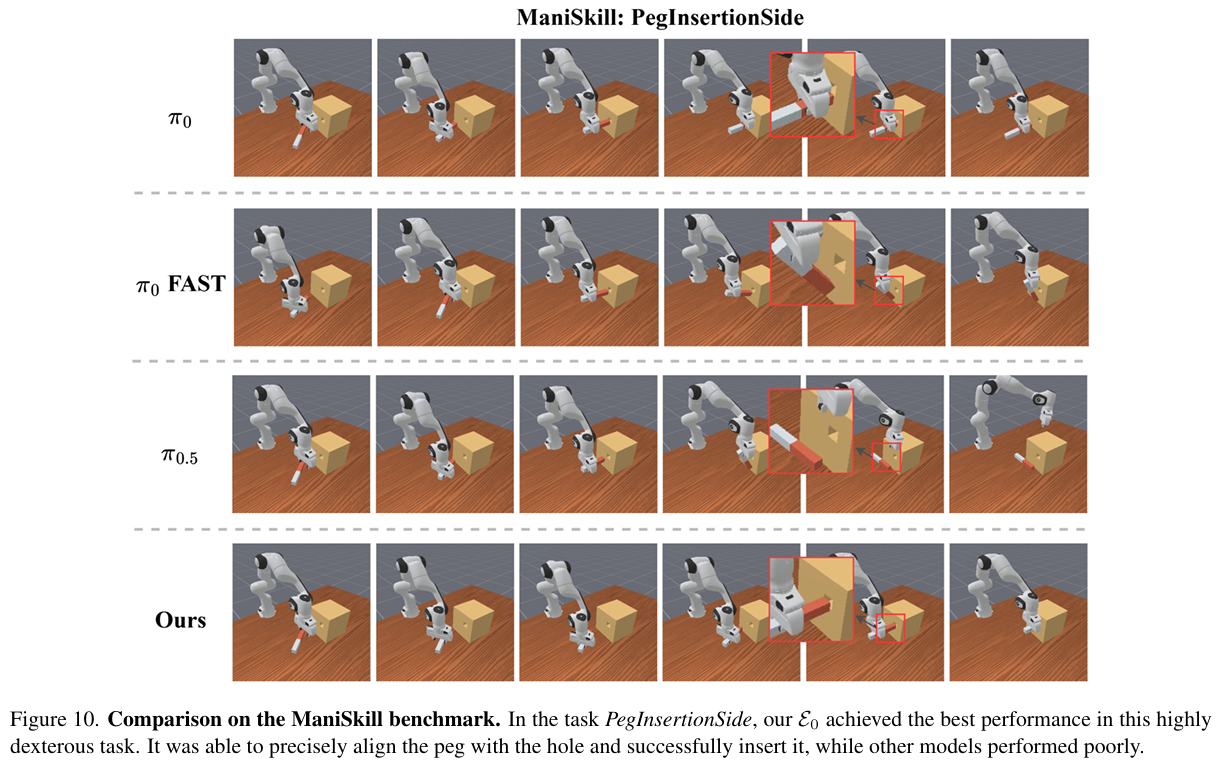
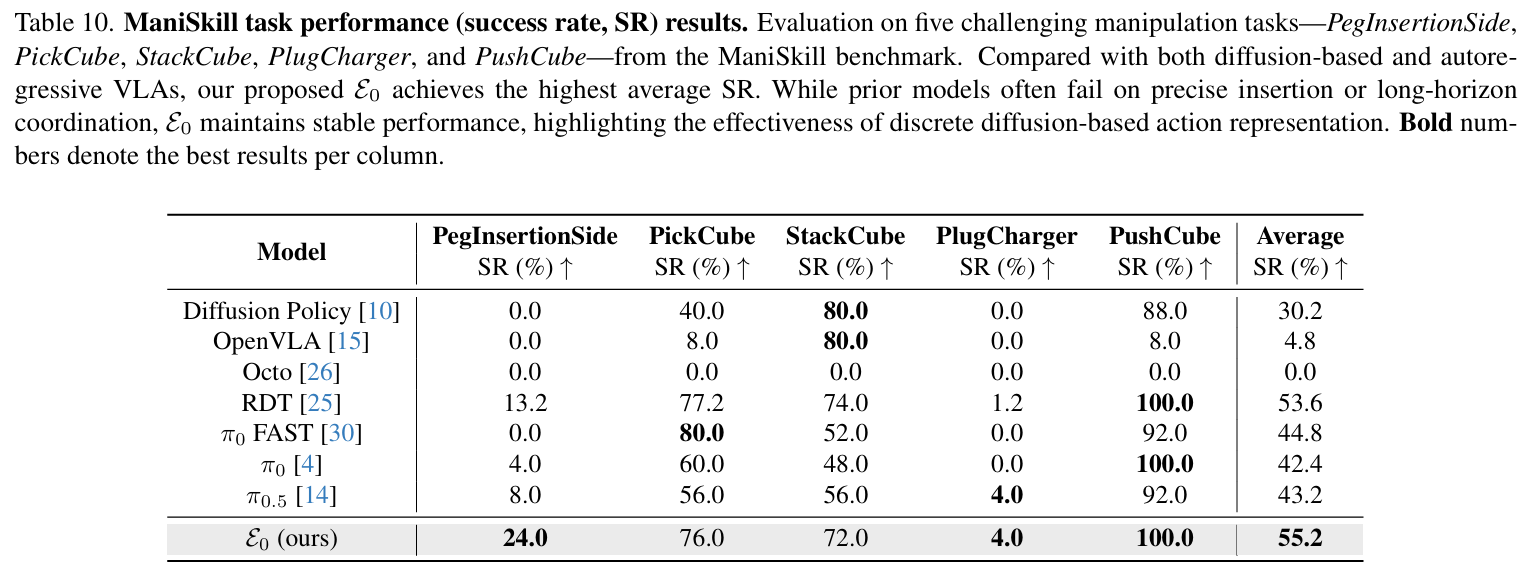
- ManiSkill:在插装、充电插头插入等高精度任务中表现最优,平均成功率55.2%,显著优于π₀、RDT等基线(figure10、table10);
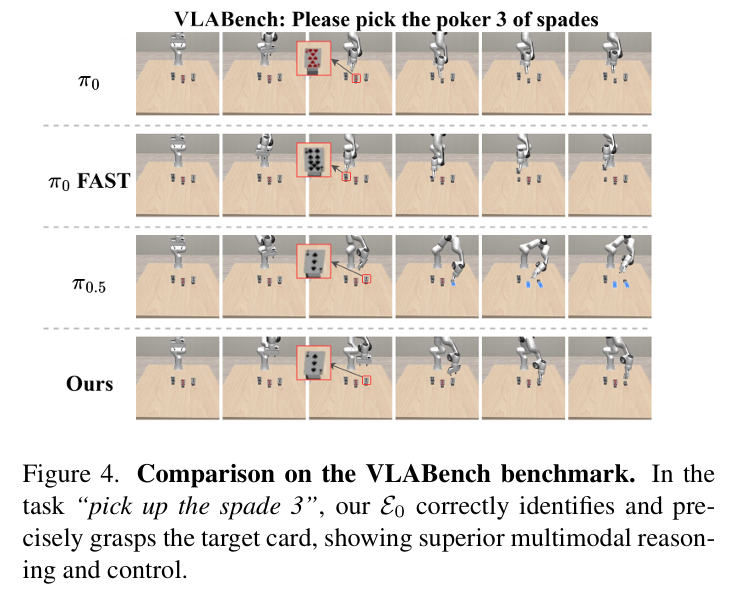
- VLABench:成功区分特定图案扑克牌、麻将牌及绘画风格,解决连续动作模型的语义推理短板(figure4、figure7)。
真实世界实验
基于Franka Research 3机械臂,在8类任务(短时序:拾取、按键、堆叠等;长时序:连续拾取、抽屉操作+放置等)中, E 0 \mathcal{E}_0 E0平均成功率45.6%,显著高于π₀(43.1%)和π₀ FAST(10.0%)(table2)。即使在训练数据中未见过的物体位置配置下(如交换红绿方块位置),仍能准确完成堆叠任务(figure5)。

消融实验
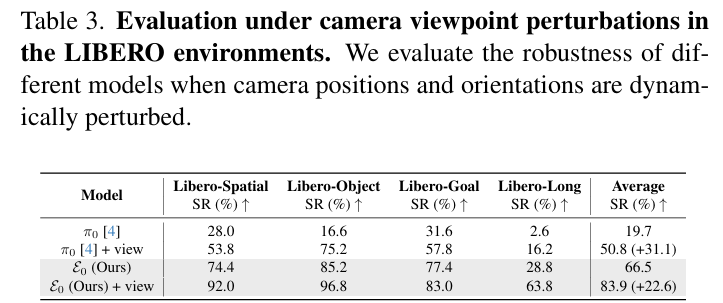
- 球面视角增强:使 E 0 \mathcal{E}_0 E0在相机扰动下的平均成功率从66.5%提升至83.9%,有效缓解视角过拟合(table3);
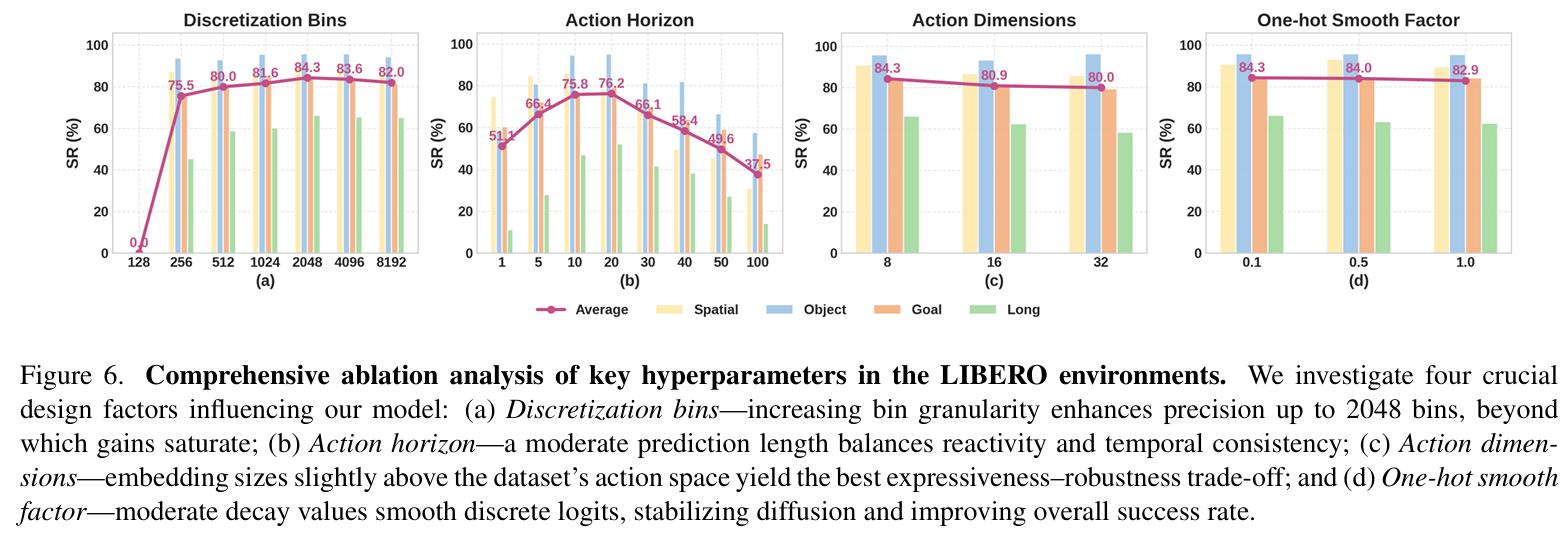
- 分箱数:2048分箱为性能拐点,进一步增加分箱数会引入优化噪声(figure6(a));
- 动作块长度:10-20步平衡响应性与时序一致性,过长会导致累积误差(figure6(b))。
六、 局限与未来方向
6.1 现存局限
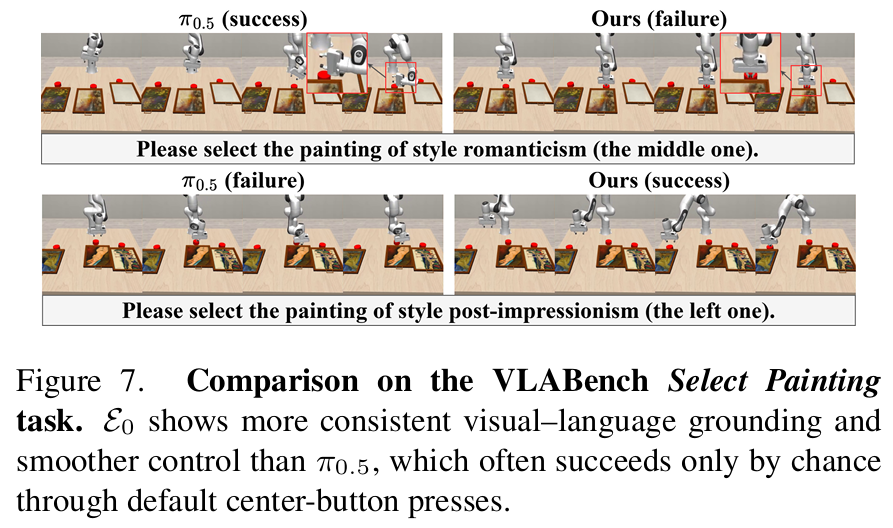
- 特定任务语义对齐不足:在VLABench的Select Painting任务中表现较弱,部分失败源于基准标注逻辑问题而非模型缺陷;
- 复杂协调任务瓶颈:双臂协同、长时程时序依赖任务(如递麦克风、堆叠三个碗)性能不及单臂任务,混合任务训练可能稀释特定技能;
- 机械交互建模不足:对开关旋转、笔记本开合等需要精细力矩控制的任务,仍存在操作精度短板。
6.2 未来方向
- 优化视觉-语言接地:针对艺术风格识别等语义密集型任务,增强跨模态对齐能力;
- 模块化任务适配:设计自适应任务采样策略,避免混合训练中的技能稀释;
- 融合机械动力学:引入物理模型先验,提升对铰接物体、力矩依赖型任务的控制精度。
参考
[1]E0:EnhancingGeneralizationandFine-GrainedControlinVLAModels viaContinuizedDiscreteDiffusion
具身求职内推来啦
国内最大的具身智能全栈学习社区来啦!
推荐阅读
从零部署π0,π0.5!好用,高性价比!面向具身科研领域打造的轻量级机械臂
工业级真机教程+VLA算法实战(pi0/pi0.5/GR00T/世界模型等)
具身智能算法与落地平台来啦!国内首个面向科研及工业的全栈具身智能机械臂
VLA/VLA+触觉/VLA+RL/具身世界模型等!具身大脑+小脑算法与实战全栈路线来啦~
MuJoCo具身智能实战:从零基础到强化学习与Sim2Real
Diffusion Policy在具身智能领域是怎么应用的?为什么如此重要?
1v1 科研论文辅导来啦!

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 8
8 0
0- 0



 已为社区贡献106条内容
已为社区贡献106条内容

所有评论(0)