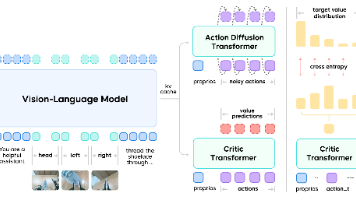
MOVE:一种用于机器人操作空间泛化的简单基于运动的数据采集范式
25年12月来自清华、智源研究院和东南大学的论文“MOVE: A Simple Motion-Based Data Collection Paradigm for Spatial Generalization in Robotic Manipulation”。模仿学习方法在机器人操作领域展现出巨大的潜力,但其实际应用却受到数据匮乏的根本制约。尽管此前已有研究致力于收集大规模数据集,但实现稳健的空间
25年12月来自清华、智源研究院和东南大学的论文“MOVE: A Simple Motion-Based Data Collection Paradigm for Spatial Generalization in Robotic Manipulation”。
模仿学习方法在机器人操作领域展现出巨大的潜力,但其实际应用却受到数据匮乏的根本制约。尽管此前已有研究致力于收集大规模数据集,但实现稳健的空间泛化仍然存在显著差距。有一个关键的局限性:无论轨迹长度如何,通常都是从单一的静态环境空间配置中采集的。这包括固定的物体和目标空间位置以及不变的相机视角,从而极大地限制可用于学习的空间信息多样性。为了解决这一数据效率的关键瓶颈,提出基于运动的变异性增强(MOVE)方法,这是一种简单而有效的数据采集范式,能够从动态演示中获取更丰富的空间信息。核心贡献在于一种增强策略,该策略在每次演示中为环境中所有可移动的物体注入运动。这一过程隐式地在单个轨迹中生成一组密集且多样化的空间配置。
近年来,端到端学习方法在机器人控制领域取得了显著进展,使得机器人能够完成众多复杂的操控任务。以扩散策略[1, 2]和视觉-语言-动作(VLA)模型[3-5]为代表的先进方法,利用大规模数据集实现对不同物体、新任务和多变环境的出色泛化能力[6, 7]。这些进步标志着机器人向通用具身智能迈出重要一步。尽管取得这些成就,但如何泛化物体姿态空间变化仍然是一个关键却常被忽视的挑战[8, 9]。对于实际应用而言,这一局限性尤为突出,因为机器人必须在远比仿真环境受控设置更加多变的非结构化环境中运行。
机器人操作与空间泛化
近年来,机器人操作取得显著进展,视觉-语言-动作(VLA)模型和扩散模型所代表的策略使机器人能够基于视觉输入执行各种任务。VLA模型基于视觉-语言模型,利用大型预训练Transformer模型将视觉和语言输入映射到机器人动作[3-5, 12-14]。扩散策略[1]及其扩展[2, 15-18]利用扩散模型拟合多模态动作分布的能力,并通过动作分块增强长时程规划和效率,在直接从人类演示中学习复杂灵巧的技能方面取得显著成功。
尽管取得这些进展,但实现空间泛化仍然是机器人领域一项核心且长期的挑战。许多先前的研究试图通过注入空间信息(例如三维点云或边框)来改进视觉表示,从而解决这个问题[11, 19–21]。然而,机器人策略的性能仍然严重依赖于训练数据集的规模和多样性[6, 22],尤其当测试场景与训练分布不同时,性能会显著下降。由于这种依赖性,该领域正从纯粹的模型中心转向数据中心[23, 24]。为此,研究人员致力于解决收集大规模真实世界机器人数据资源密集且耗时的挑战。
机器人数据采集
受LLM和VLM数据规模化成功经验的启发,研究人员也开始探索操作任务的数据规模化。大规模数据集的开发对近期的进展至关重要,例如DROID(7.6万条轨迹)[24]、BridgeData V2(约6万条轨迹)[25]和Open X-Embodiment数据集(约100万条轨迹)[26]。尽管社区做出巨大努力,但可用的机器人数据量仍然远低于视觉语言数据,这限制当前方法实现稳健泛化的能力[27]。为了应对这一挑战,近期的研究探索更高效的数据采集方法,其方向包括大规模物理仿真和3D场景重建。基于仿真的方法在高保真仿真环境中收集大量数据,以弥合仿真与现实之间的差距[28-31]。基于三维重建的方法可以根据真实轨迹生成合成轨迹[10, 32]。除了这些方法之外,研究人员还在探索高效的真实世界数据采集策略。ADC[33]在数据采集过程中会周期性地重置物体的位置。然而,ADC仅包含轨迹上的几个离散点。
基于运动的变异性增强(MOVE)
问题的根源在于静态数据采集方法从连续状态空间中采样空间配置的效率低下。如图左侧重点展示静态数据采集的局限性。用从9个空间位置均匀采集的数据训练一个扩散策略,并在整个目标空间中评估该策略。正如预期的那样,该策略仅在训练集内的位置附近有效,但在其余空间的大部分测试点上均失败,导致成功率仅为29.5%。随着任务空间空间维度的增加,这个问题变得尤为严重。例如,不同的相机视角、可调节的桌子高度以及随机的目标物体放置都会使空间环境更加复杂且组合丰富。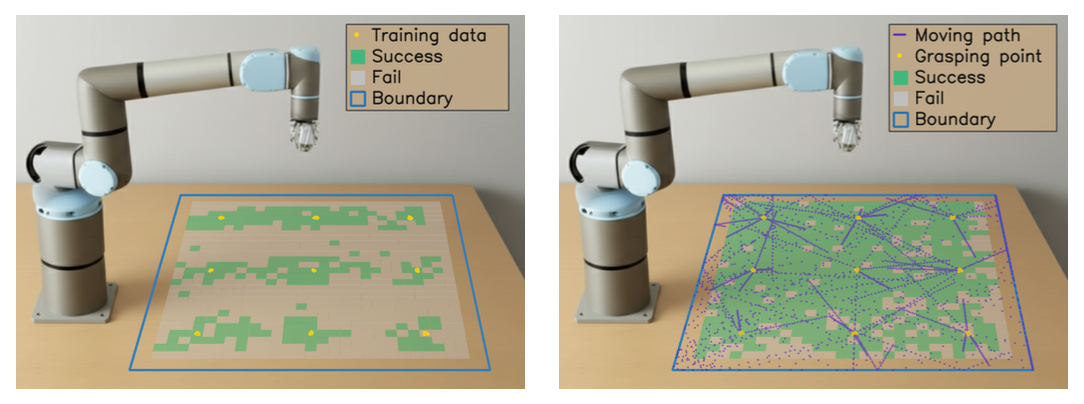
如表所示,成功率随着空间维度的增加呈指数级下降,揭示了当前方法在真实世界环境中泛化能力的不足。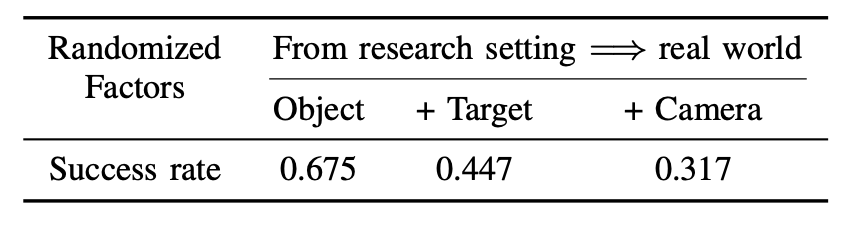
为了解决这个问题,对静态数据采集范式本身提出挑战。在这种范式中,完整的专家轨迹(通常跨越数百个时间步)是在固定的空间配置(例如固定的物体位置、目标位置和相机视角)下捕捉任务的。空间稀疏性导致的结果是,如果策略需要以新的姿态抓取物体,则必须为该特定位置收集全新的演示[10, 11],这对于现实世界的部署是不切实际的。
本文提出一种基于运动的数据采集框架MOVE,旨在提高每条轨迹的空间信息密度,从而增强机器人操作的空间泛化能力。鉴于传统数据采集方法的局限性,目标是赋予单条轨迹来自多个空间配置的空间位置信息。具体而言,在采集专家演示数据时,关键物体(例如拾取物体、目标物体和摄像头)会被有意地连续移动。如图所示展示MOVE相对于静态方法的空间覆盖范围。在相同的数据集规模下,MOVE在训练过程中会将策略暴露于单条轨迹内连续移动的物体流中。虽然该策略可能无法直接学习抓取运动路径上每个位置的物体,但它仍然可以隐式地获取相应空间配置的信息。如上图右侧所示,使用MOVE数据训练的策略能够抓取运动路径上的物体。这种范式有效地将强大而灵活的数据增强形式直接嵌入到每个轨迹中,从而提高样本效率和空间泛化能力。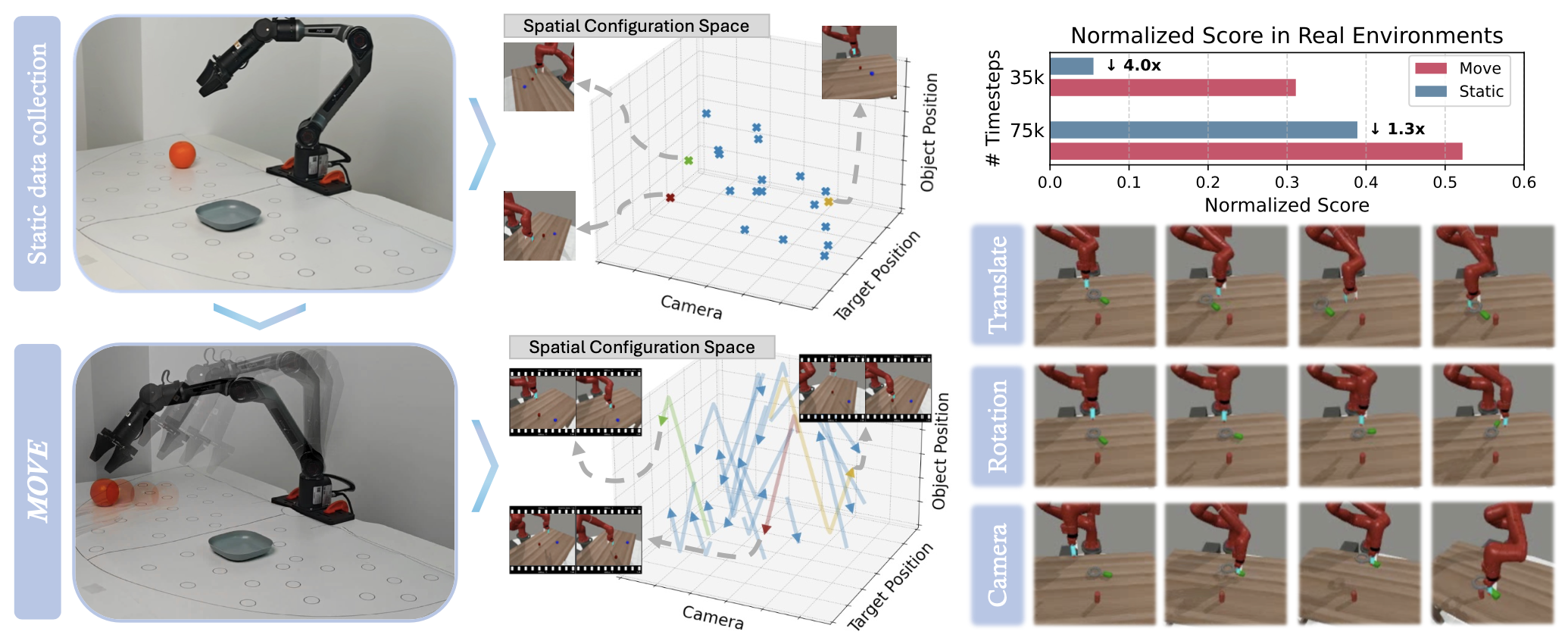
空间泛化挑战
在机器人学习中,策略训练的泛化能力高度依赖于大型且多样化的数据集,但在机器人领域获取足够的数据却异常困难。随着任务空间维度的增加,这一挑战愈发突出,因为每个标准演示通常只包含一个空间配置实例,导致高维环境中严重的空间稀疏性。在元世界拾取放置任务上验证这一现象,并将结果列于上表。
具体而言,逐步随机化关键空间因素,构建三种空间泛化难度递增的设置。在设置 1 中,仅随机初始化物体在桌面上 30 cm × 30 cm 区域内的位置,而目标位置和相机视角保持不变。尽管训练和测试使用相同的采样范围,但由于采样位置的差异,仍然需要进行泛化。在设置 2 中,除了随机化物体的位置外,目标位置也在 20 cm × 10 cm × 25 cm 的空间范围内随机化。设置 3 通过随机化相机姿态进一步增加了难度,视角范围从 0 到 π 弧度,从而从受控设置过渡到更真实的场景。在相同的 2 万个时间步的训练预算下,成功率从设置 1 的 67.5% 急剧下降到设置 3 的 31.7%。这种指数级下降凸显标准静态数据采集范式无法充分覆盖具有多维变化的真实环境中的空间配置空间。
概述。为了增强模型对复杂环境的泛化能力并提高其对不可预见空间位置的鲁棒性,探索一种简单而有效的数据采集方法,称为基于运动的变异性增强(MOVE),该方法利用动态轨迹提供更丰富的空间定位信号。如上图所示,为了增加空间配置的覆盖范围,在收集训练数据时引入受控运动学运动(包括平移、旋转和相机运动)作为数据增强策略。收集完成后,应用扩散策略来训练策略模型。
空间配置增强
物体平移:为了确保对整个工作空间的空间覆盖,MOVE 模拟拾取物体和目标物体的多条线性运动轨迹,并通过在边界处引入线性平移和反弹来建模。物体在时间 t 的位置 p_i(t) 由其初始位置 p_i(0)、恒定速度矢量 v_i 和运动方向 d_i 决定,其中 v_max 为最大可能速度,速度 v_i 从 Beta 分布 B(α_p, β_p) 中采样。利用 Beta 分布的特性将采样速度限制在区间 [0, v_max] 内,并确保速度接近 0 的概率高于 v_max。具体来说,在整个仿真实验中设置所有 α = 2 和 β = 5。这种分布不仅有助于模型学习空间泛化,还有助于学习鲁棒的抓取策略。
物体旋转:为了提高空间泛化能力,使其能够处理各种物体方向,引入恒定角速度旋转。为简化起见,模拟绕垂直 z 轴的一维旋转。与上述类似,物体的方向 θ_i(t) 基于其初始方向 θ_i(0) 和一个恒定角速度 ω_i 演化。
这种增强对于不对称物体(例如带把手的杯子)尤其有效。相反,它不适用于完全旋转对称的物体。
相机运动:为了模拟非静态视角,虚拟相机沿相对于场景中心的约束圆柱路径运动。相机位置的更新方式与物体平移类似,其速度从 Beta 分布中采样。
组合增强策略:并非同时应用所有运动,而是采用分阶段策略,该策略针对任务的语义阶段量身定制。例如,在“合盒子”任务中,将每条轨迹分解为拾取阶段(t_0 → t_1)和放置阶段(t_1 → t_2)。
• 拾取阶段(t_0 → t_1):仅对拾取目标(盒子盖)应用平移和旋转,同时引入相机运动。这迫使策略学习如何在适应不断变化的视角的同时接近并抓取移动目标。
• 放置阶段(t_1 → t_2):仅对目标对象(盒子主体)应用线性平移,并继续动态相机运动。这挑战策略将对象放置到移动的目标位置。
该策略将 MOVE 扩展到单维空间之外,增加跨多个空间维度的空间信息丰富度。
训练
为了学习机器人的控制策略,采用扩散策略[1]框架。为了训练,采用前面说的增强方法,使用收集的动态数据集。具体来说,采用去噪扩散隐式模型(DDIM)调度器来实现确定性和高效的采样过程。噪声较小的样本x_t−1由时间步t的噪声样本x_t计算得出。
实验旨在全面评估 MOVE 的有效性,并将其与传统的静态范式进行比较。在仿真环境和真实环境中均进行实验。
a) 任务和环境:在仿真环境中,利用 Meta-World 基准测试集 [34],该测试集包含一系列机器人操作任务,包括抓取、推动和放置。对于每个仿真环境,通过修改仿真器代码,在较大范围内随机初始化物体、目标和摄像头。由于代码修改耗时较长,从三个难度级别中各选取一定数量的环境作为代表性示例。
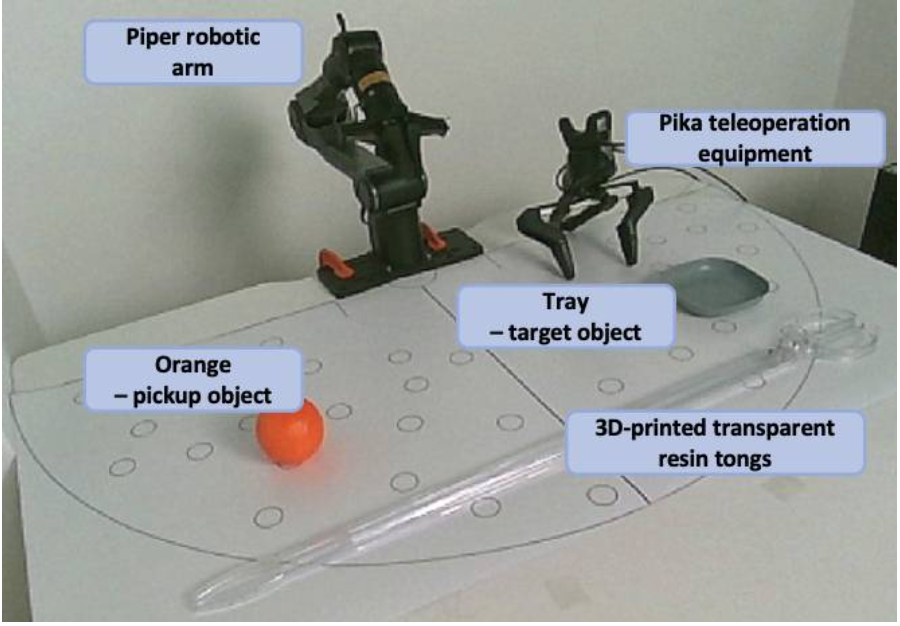
对于真实环境验证,使用一个典型的抓取和放置任务。Agilex PIPER 机械臂的任务是从可变的初始位置抓取一个橙子,并将其放置在塑料托盘上。操作工作空间配置为半圆形,覆盖面积为 0.5×π×60 cm×60 cm ≈ 5655 cm²,涵盖末端执行器可到达空间的大部分区域。训练数据集通过随机抽取 20 对位置构建,每对位置分别指定一个橙色物体的位置和一个平板的位置。
b) 基线:为了展示方法的优势,将 MOVE 与传统的静态数据采集范式进行比较。此外,还将其与 ADC 方法 [33] 进行比较,该方法在单次数据采集轨迹中周期性地将物体位置重置为一个新的随机位置,以鼓励策略多样性。所有方法均采用相同的训练和评估协议。
c) 专家数据采集:在仿真中,专家演示是使用 Meta-World 提供的脚本策略生成的。在现实世界中,通过使用 Pika 夹爪远程操作机械臂来采集人类演示。一个关键的考虑因素是,在动态条件下收集的轨迹通常比静态条件下的轨迹更长。为了确保数据效率的公平比较,将数据集的大小定义为环境交互步骤的总数,而不是轨迹的数量。
如图所示是使用 RealSense 摄像头拍摄的真实实验装置概览。在桌面上随机选取若干点对作为橙子和托盘的放置位置,这些数据用作训练数据。物体的移动是通过 3D 打印的透明树脂夹实现的。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 31
31 0
0- 0



 已为社区贡献102条内容
已为社区贡献102条内容

所有评论(0)