如何使用 AutoRAG 构建 RAG 应用?
RAG 通过为模型生成的答案提供可靠的引用来源,从而提高准确性。RAG 的应用场景包括聊天机器人、知识助手、分析解决方案以及企业级问答系统。
检索增强生成(Retrieval-Augmented Generation,简称 RAG)的核心由两个主要部分组成:检索器(Retriever)和生成器(Generator)。
RAG 有助于克服大语言模型(LLM)的局限性、减少幻觉,并提供基于信任源的专家级回答。随着人们对 RAG 的兴趣日益浓厚,对能够简化探索、测试和优化不同 RAG 策略的工具需求也随之增加。AutoRAG 就是为此目的而生的最新解决方案之一,它能自动化大部分开发流程,让你能够自由实验各种配置、评估流水线(Pipeline),并精准定位最适合你使用场景的方案。

RAG 通过为模型生成的答案提供可靠的引用来源,从而提高准确性。RAG 的应用场景包括聊天机器人、知识助手、分析解决方案以及企业级问答系统。
RAG 的核心组件
有几个关键的构建块决定了 RAG 的成功及其提供准确信息的能力:
- 检索器(Retriever): RAG 的第一步是使用检索器对文档进行索引,然后检索器会在索引中搜索相关的文档分块(Chunks)。
- 嵌入模型(Embedding Model): 索引可以基于文档分块的相似性,通过相似性搜索(Similarity Search)、**向量嵌入(Vector Embedding)或混合检索(Hybrid Retrieval)**等多种方法建立。
- 生成器 (LLM): 生成器必须依赖准确的上下文才能产出可靠的响应。因此,必须利用最佳版本的上下文来保证生成的准确性。
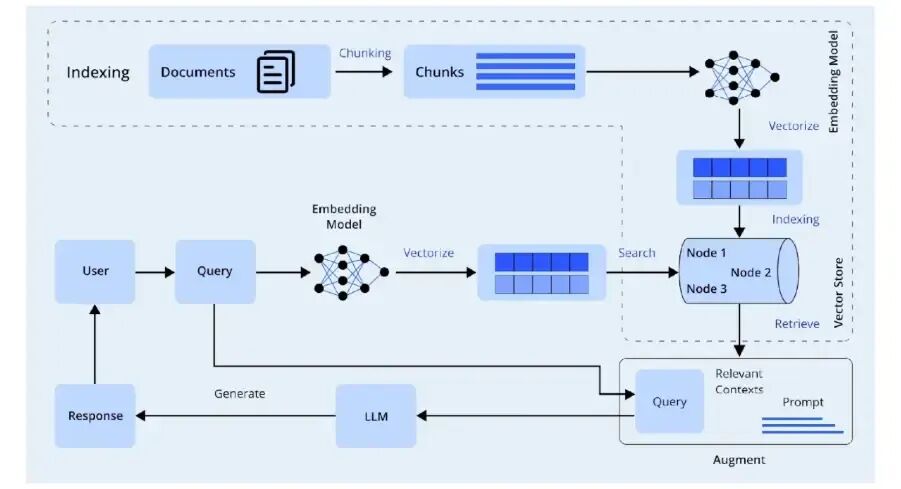
什么是 AutoRAG?
AutoRAG 是一个允许你快速创建、评估和优化多个 RAG 流水线的框架。它帮助开发人员在无需编写自定义评估脚本的情况下,快速测试多种设计方案。当团队想要比较不同的检索方法、嵌入模型、分块策略或生成模型时,就会使用 AutoRAG。
借助 AutoRAG,开发人员可以快速迭代多种不同的 RAG 配置,因为它会自动运行测试并提供检索准确性的评估,找出生成流水线的最佳配置。当你需要系统性评估或想要测试大量流水线配置时,应当使用 AutoRAG。
AutoRAG 解决什么问题?
AutoRAG 解决了许多令 RAG 开发耗时费力的挑战:
- 流水线探索: 它支持在不编写手动代码的情况下,对各种相似性度量、分块大小、嵌入模型和检索器进行实验。
- 评估: AutoRAG 包含检索准确度、引文正确性和回答质量等评估指标,让评估 RAG 流水线的有效性变得简单。
- 优化: AutoRAG 能够识别出最有效的配置,使团队能够根据其数据和用例做出最佳决策。
在开始使用 AutoRAG 开发应用之前,你需要配置合适的开发环境。这意味着你需要安装 Python、相关依赖库、准备数据,并获取 LLM 或嵌入模型提供商的凭证。
Python 环境设置
你必须拥有定义良好的 Python 环境(建议 3.10 或更高版本)。
# 创建虚拟环境python3 -m venv autorag-venv# 激活虚拟环境source autorag-venv/bin/activate # Linux/macOS# windows 使用: autorag-venv\Scripts\activate# 升级 pippython -m pip install --upgrade pip
核心依赖安装
安装 AutoRAG 所需的软件包:
pip install AutoRAG pandas langchain sentence-transformers faiss-cpu
autorag: 核心框架pandas: 数据处理sentence-transformers: 嵌入模型支持faiss-cpu: 向量数据库后端langchain: 用于 LLM 集成
导出 API 密钥
export OPENAI_API_KEY="sk-..."
如果你使用其他提供商,请以类似方式设置其环境变量。
使用 AutoRAG 构建 RAG 应用
构建过程主要分为三个步骤:
- 索引与嵌入: 将信息分块转换为嵌入并存储在向量数据库中。
- 检索与流水线实验: 创建 QA 评估集,运行 AutoRAG 实验以确定最佳流水线。
- 部署: 使用生成的最佳流水线响应用户查询。
1. 数据摄取与预处理
首先,加载原始 PDF 文档并解析:
import jsonimport osfrom pathlib import Pathimport PyPDF2def parse_pdf(pdf_path="data/raw_docs/attention.pdf", out_path="data/parsed.jsonl"): os.makedirs("data", exist_ok=True) with open(pdf_path, "rb") as f, open(out_path, "w", encoding="utf-8") as fout: reader = PyPDF2.PdfReader(f) for i, page in enumerate(reader.pages): text = page.extract_text() or"" fout.write(json.dumps({ "doc_id": "attention.pdf", "page": i + 1, "content": text, "source": "attention.pdf", "title": "Attention Is All You Need" }) + "\n") print("解析 PDF 完成 → data/parsed.jsonl")parse_pdf()
接下来,对文档进行分块(Chunking):
import jsondef chunk_text(text, chunk_size=600, overlap=60): words = text.split() i = 0 chunks = [] while i < len(words): chunk = words[i:i + chunk_size] chunks.append(" ".join(chunk)) if i + chunk_size >= len(words): break i += chunk_size - overlap return chunksdef create_corpus(parsed="data/parsed.jsonl", out="data/corpus.jsonl"): with open(parsed, "r") as fin, open(out, "w") as fout: for line in fin: row = json.loads(line) chs = chunk_text(row["content"]) for idx, c in enumerate(chs): fout.write(json.dumps({ "id": f"{row['doc_id']}_p{row['page']}_c{idx}", "doc_id": row["doc_id"], "page": row["page"], "chunk_id": idx, "content": c, "source": row["source"], "title": row["title"] }) + "\n") print("创建语料库完成 → data/corpus.jsonl")create_corpus()
对元数据进行规范化处理:
import jsondef normalize_metadata(path="data/corpus.jsonl"): rows = [] with open(path) as fin: for line in fin: obj = json.loads(line) obj.setdefault("source", "attention.pdf") obj.setdefault("title", "Attention Is All You Need") rows.append(obj) with open(path, "w") as fout: for r in rows: fout.write(json.dumps(r) + "\n") print("元数据规范化完成。")normalize_metadata()
2. 索引、嵌入与存储设置
构建 FAISS 向量索引:
import jsonimport numpy as npimport faissfrom sentence_transformers import SentenceTransformerimport osdef build_faiss_index(corpus="data/corpus.jsonl", index_dir="data/faiss_index"): os.makedirs(index_dir, exist_ok=True) texts, ids = [], [] with open(corpus) as f: for line in f: row = json.loads(line) texts.append(row["content"]) ids.append(row["id"]) model = SentenceTransformer("all-MiniLM-L6-v2") embeddings = model.encode(texts, convert_to_numpy=True) faiss.normalize_L2(embeddings) index = faiss.IndexFlatIP(embeddings.shape[1]) index.add(embeddings) faiss.write_index(index, f"{index_dir}/index.faiss") json.dump(ids, open(f"{index_dir}/ids.json", "w")) print("FAISS 索引已存储在", index_dir)build_faiss_index()
3. 使用 AutoRAG 进行流水线实验
创建一个问答(QA)评估数据集:
import pandas as pdfrom autorag.data.qa.schema import Raw, Corpusfrom autorag.data.qa.sample import random_single_hopfrom autorag.data.qa.query.llama_gen_query import factoid_query_genfrom autorag.data.qa.generation_gt.llama_index_gen_gt import make_basic_gen_gtfrom llama_index.llms.openai import OpenAIdef create_qa(): # 注意:确保此处已有 parquet 格式的数据 raw_df = pd.read_parquet("data/parsed.parquet") corpus_df = pd.read_parquet("data/corpus.parquet") raw_inst = Raw(raw_df) corpus_inst = Corpus(corpus_df, raw_inst) llm = OpenAI() sampled = corpus_inst.sample(random_single_hop, n=140) sampled = sampled.make_retrieval_gt_contents() sampled = sampled.batch_apply(factoid_query_gen, llm=llm) sampled = sampled.batch_apply(make_basic_gen_gt, llm=llm) sampled.to_parquet("data/qa.parquet", index=False) print("创建 data/qa.parquet 完成")create_qa()
配置 default_rag_config.yaml 文件:
node_lines:-node_line_name:retrieve_node_linenodes:-node_type:semantic_retrieval top_k:3 modules: -module_type:vectordb vectordb:faiss_local index_dir:data/faiss_index embedding_module:sentence_transformers/all-MiniLM-L6-v2-node_line_name:post_retrieve_node_linenodes:-node_type:prompt_maker modules: -module_type:fstring prompt:| Use the passages to answer the question. Question: {query} Passages: {retrieved_contents} Answer:-node_type:generator modules: -module_type:openai_llm llm:gpt-4o-mini batch:8
运行评估器:
from autorag.evaluator import Evaluator evaluator = Evaluator( qa_data_path="data/qa.parquet", corpus_data_path="data/corpus.parquet" ) evaluator.start_trial("configs/default_rag_config.yaml")
你就可以输入查询,例如:“What is multi-head attention in the Transformer model?”系统将根据评估结果给出最佳答案。
构建稳健的 RAG 应用需要仔细规划。以下是一些建议:
- 嵌入与原文关联: 始终将嵌入向量与原始文本分块(或引用)关联存储,不要仅依赖嵌入向量。
- 合理分块: 确保分块在边界处保留语义完整性。建议使用统一的 Token 计数(如 300 到 512 个 token)并保持重叠(Overlap,如 50 个 token)。
- 缓存嵌入: 在处理重复查询或大量内容时,缓存相同的嵌入结果以节省成本和时间。
- 监控质量: 使用 AutoRAG 提供的 F1 分数、召回率(Recall)等标准指标持续监控检索和生成性能。
- 密钥安全: 严禁将 API 密钥硬编码在应用中。请使用环境变量或安全保险箱(Vault)。
RAG 应用的设计涉及从数据处理到检索技术的多个组件。AutoRAG 使开发人员能够自动化实验阶段和评估过程,从而简化 RAG 应用的创建。通过 AutoRAG,开发人员可以快速实验各种流水线设计,并基于结论性数据发布卓越的 RAG 应用。
利用 AutoRAG 的优化能力和既定的最佳实践,团队能够以更少的手动配置时间,创造出最高质量的 AI 体验。
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:
- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 13
13 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)