什么是强化学习-Reinforcement Learning(RL)
学习者(比如那只狗,或者你的AI模型)。智能体所处的场景(比如房间)。智能体能做的事情(跑、跳、坐)。环境给出的反馈分数(+1分,-10分)。除非你的问题是一个需要连续决策的问题(如机器人控制、物流调度),且你拥有一个高保真的模拟环境,否则不要使用强化学习。它会把简单的问题复杂化,且大概率训练不出来。
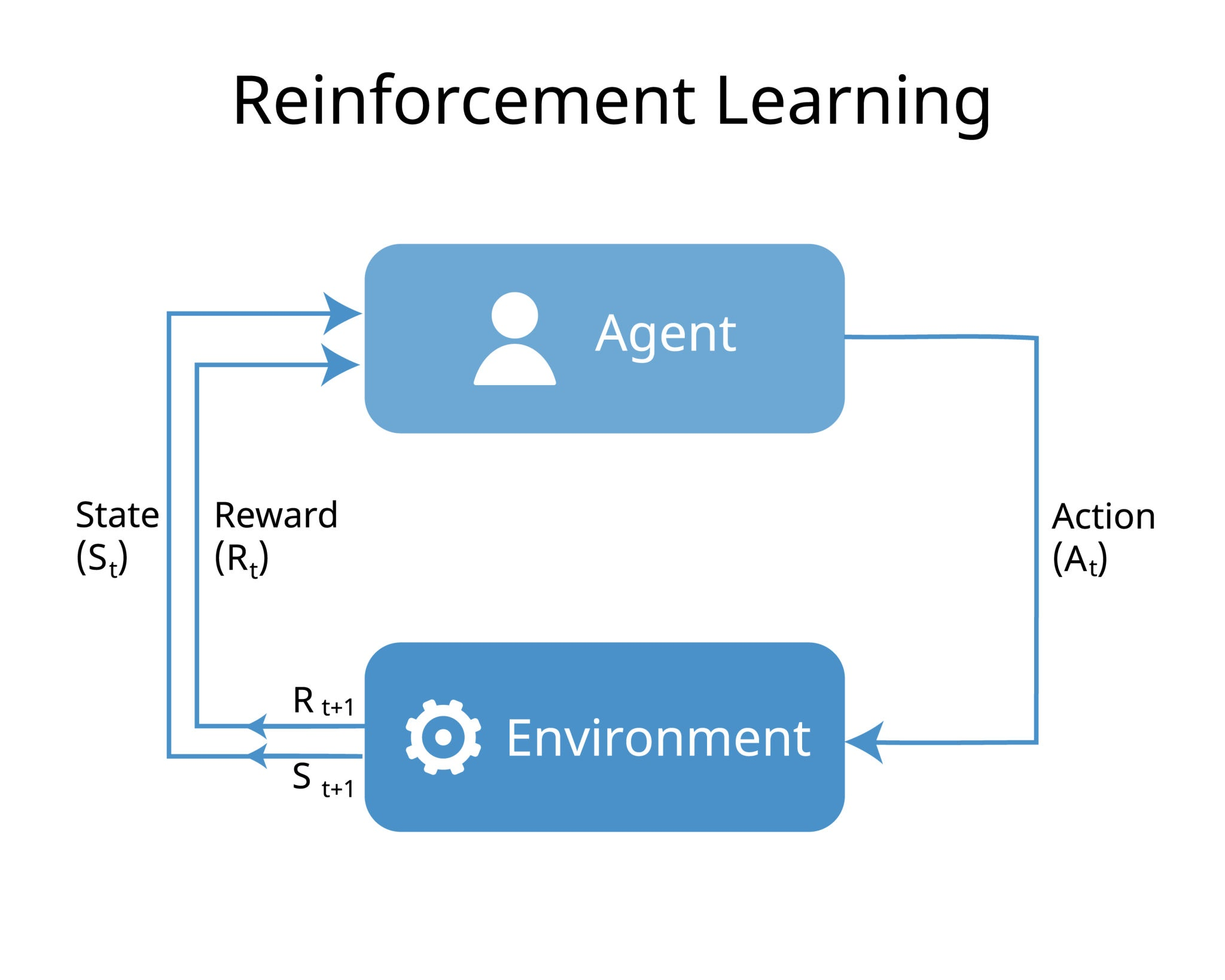
一、技术上的四个要素:
-
智能体 (Agent): 学习者(比如那只狗,或者你的AI模型)。
-
环境 (Environment): 智能体所处的场景(比如房间)。
-
动作 (Action): 智能体能做的事情(跑、跳、坐)。
-
奖励 (Reward): 环境给出的反馈分数(+1分,-10分)。

除非你的问题是一个需要连续决策的问题(如机器人控制、物流调度),且你拥有一个高保真的模拟环境,否则不要使用强化学习。它会把简单的问题复杂化,且大概率训练不出来。
给了一个实例:
二 、具体应用案例
(1)DeepMind AI 控制谷歌数据中心冷却系统
这个案例完美展示了强化学习如何处理“复杂系统控制”,而不仅仅是玩游戏。
-
背景痛点: 谷歌的数据中心(Data Centers)里有成千上万台服务器,它们产生巨大的热量。为了不让服务器烧坏,必须用工业级的空调和冷却系统降温。这非常耗电,冷却系统的能耗占了总能耗的很大一部分。
-
挑战: 这是一个极其复杂的物理系统。天气变化、服务器负载波动、管道水流速度、风扇转速……变量成千上万,传统的工程师写死的规则(比如“温度超过30度就开大风扇”)根本做不到最优。
-
-
强化学习的解决方案: DeepMind 开发了一个强化学习智能体(Agent)。
-
状态 (State): 智能体每5分钟读取一次数据中心的“快照”,包括几千个传感器的数据(温度、压力、流量、外部天气等)。
-
动作 (Action): 智能体可以调节数据中心里的各种“旋钮”,比如把某个冷水机组的水温调高0.5度,或者把某个风泵的转速调低一点。
-
奖励 (Reward): 目标很简单——PUE(能源使用效率)越低,奖励越高。同时有一个硬性约束:千万不能让服务器过热宕机(如果温度越界,给予巨额惩罚)。
-
-
训练过程(关键点): 他们没有直接让AI在真实的数据中心里乱试(万一关掉空调导致服务器烧毁损失就大了)。他们利用历史数据构建了一个高精度的虚拟模拟器。AI先在这个模拟器里尝试了几百万种不同的开关组合,学会了其中的规律。
-
最终效果: 当这个AI系统真正接管谷歌数据中心后,它成功将冷却系统的能源消耗减少了 40%。这是人类工程师优化了十几年都没能达到的水平。
这个案例给你的启示: 如果你想用强化学习,你不需要通过大量真实失败来收集数据,但你通常需要一个能反映真实物理规律的仿真环境(模拟器)。
三、思考
那么问题来了,DeepMind 怎么开发了这么一个强化学习智能体(Agent),基础是什么,需要那些原始素材?
1. 原始素材:你需要给它“喂”什么?
利用了谷歌数据中心原本就有的成千上万个传感器。
每 5分钟 采集一次数据,主要包括以下几类:
-
温度数据: 服务器进风口温度、出风口温度、冷水进水温度、回水温度等。
-
压力与流量: 冷却水管的压力、流速、空气流速。
-
设备状态: 冷水机组(Chillers)的运行功率、冷却塔(Cooling Towers)的风扇转速、水泵的转速。
-
外部环境: 数据中心外的天气(主要是湿球温度,影响冷却塔效率)、室外湿度。
-
IT 负载: 服务器当前有多忙(计算任务越重,发热越大)。
-
数以亿计的时间序列数据点。
关键点: 如果没有这庞大的历史数据来构建“世界观”,强化学习就无法启动。
2. 基础架构:它是怎么“思考”的?(The Brain)
使用的是 深度神经网络 (Deep Neural Networks) 来作为强化学习的大脑。
模型 A:系统模拟器(System Models)—— 这是“世界观”
这是最关键的一步,也是你朋友可能误解的地方。DeepMind 没有一开始就让 AI 去控制真实的空调。
-
做法: 他们利用那几年的历史数据,训练了一组深度神经网络来模拟数据中心的物理反应。
-
功能: 这个模型能预测未来。比如输入:“当前温度25度,如果把水温调低1度,1小时后能耗会变成多少?温度会变成多少?”
-
精度: 这个预测模型的精度达到了 99.6%。你可以把它理解为一个高精度的数字孪生(Digital Twin)。
模型 B:策略网络(Policy Network)—— 这是“指挥官”
这才是真正的强化学习智能体。
-
输入: 当前的所有传感器读数。
-
输出: 一组具体的动作(Actions)。例如:
-
动作1: 将3号冷水机组的目标温度设定为 8.5°C。
-
动作2: 将2号冷却塔的风扇转速增加 10%。
-
-
架构: 通常是 Actor-Critic 结构的变体(专门处理连续动作空间)。
3. 开发与训练流程:它是怎么“学会”的?
有了素材和基础,DeepMind 按照以下步骤“炼制”了这个 AI:
第一步:离线训练(在模拟器里练兵)
智能体(模型B)在模拟器(模型A)里疯狂试错。
智能体尝试把温度调高,发现能耗降低了(奖励+1),但紧接着服务器过热报警了(奖励-1000)。
智能体记住了:“省电虽好,但不能烧坏机器”。
它在虚拟环境中跑了相当于现实世界几十年的时长,摸索出了在各种天气和负载下的最优解。
第二步:设定奖励函数(制定KPI) 这是人类工程师的核心工作。告诉 AI 什么是“好”。
DeepMind 的奖励函数公式大致逻辑是:
奖励=−(能源消耗)−(违反安全约束的惩罚) 目标是让奖励最大化(即能耗最小化)。
一旦预测到温度可能超过安全线,惩罚值会是无穷大,迫使 AI 绝对避免这种情况。
第三步:部署与安全护栏(Sim-to-Real)
当 AI 在模拟器里表现完美后,DeepMind 把它接到了真实的控制系统上。但为了安全,他们加了多重保险:
置信度检查: 如果 AI 遇到的情况(比如台风天)在历史数据里从未出现过,AI 会自动交出控制权,退回到传统的人工规则。
平滑过渡: AI 的指令不会突变(比如突然把风扇从 0% 开到 100%),而是平滑调整。
双向验证: AI 发出指令后,会有一个简单的传统控制器进行校验,确认这个指令在安全范围内。
从上面看,个人能力进行强化学习的门槛还是挺高的,因为首先你很难获取庞大的数据量的,除非是背靠大企业或者国家部门,才可以获取巨大连的数据,但是给了 一个启示,经济调控是不是可以使用强化训练的模型来支持工作, 财政部的工作会不会变得更加简单和有依赖。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)