利用“软提示”机制,攻克跨机器人模型的泛化难题!清华与上海AI Lab重磅开源X-VLA
利用“软提示”机制,攻克跨机器人模型的泛化难题!清华与上海AI Lab重磅开源X-VLA
为何通用机器人如此难以实现?
在机器人研究领域,一个核心目标是构建一个能够操作各种不同类型机器人(即不同“本体”或“具身”)、并能理解人类指令的通用人工智能体。然而,实现这一目标的主要障碍在于数据异构性。训练数据往往来自具有不同硬件(如不同机械臂、不同摄像头)和数据收集协议的机器人平台。
这种异构性会沿着模型的整个处理流程,从输入到输出,引发严重的分布偏移 和语义错位,从而干扰模型的学习过程,导致其性能不佳。为了解决这一挑战,清华大学智能产业研究院(AIR)与上海人工智能实验室的研究人员提出了名为X-VLA的新模型,它利用软提示(Soft Prompts) 的巧妙技术,为这一难题提供了高效的解决方案。
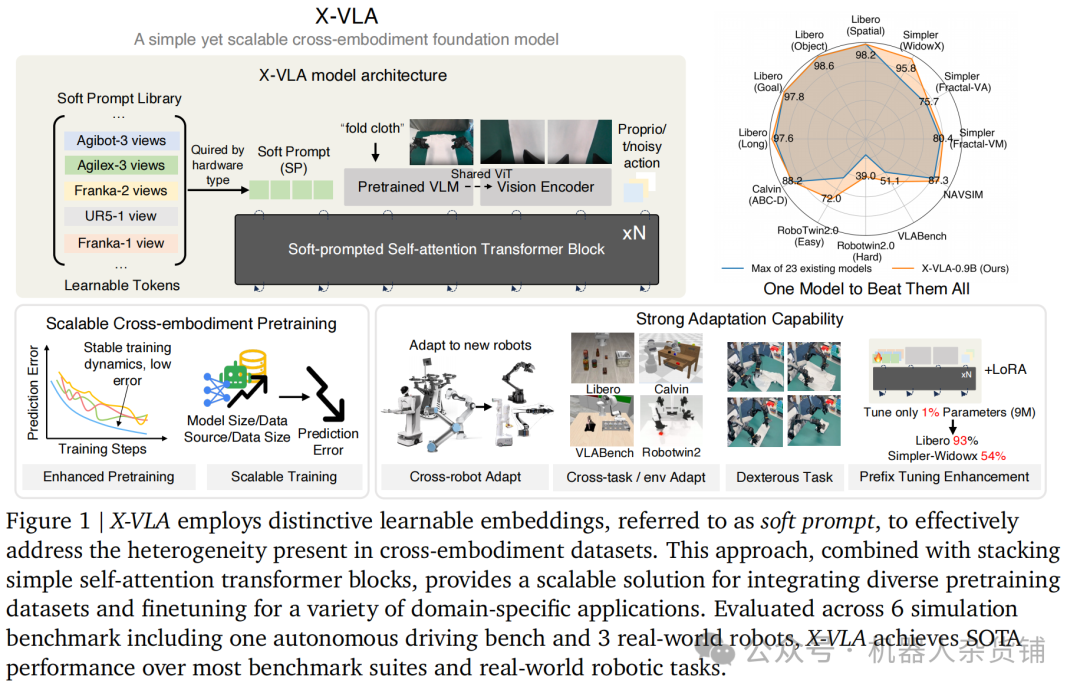
1. 异构性难题:机器人学习的核心瓶颈
机器人数据中的异构性体现在多个维度。这些差异不仅存在于底层的动作信号中,也存在于上层的视觉理解中,是训练通用机器人策略的核心瓶颈。具体来说,异构性的来源包括:
-
机器人本体: 不同的机械臂动力学特性和控制接口。
-
硬件配置: 不同的摄像头设置、视觉域和任务分布。
-
数据本身: 不同的动作空间和数据收集策略。
以往的大多数方法主要通过为不同机器人分配独立的动作解码头(Action Decoder Heads) 来处理这一问题。然而,这是一种不完整的解决方案,更像一个“后期补丁”。它仅仅在模型的最终输出阶段解决了动作空间的异构性,却完全忽略了更根本的早期阶段问题——模型的核心推理过程未能感知到不同机器人输入的差异(例如,如何解读不同摄像头视角下的信息)。而软提示机制恰恰解决了这一早期阶段的难题。
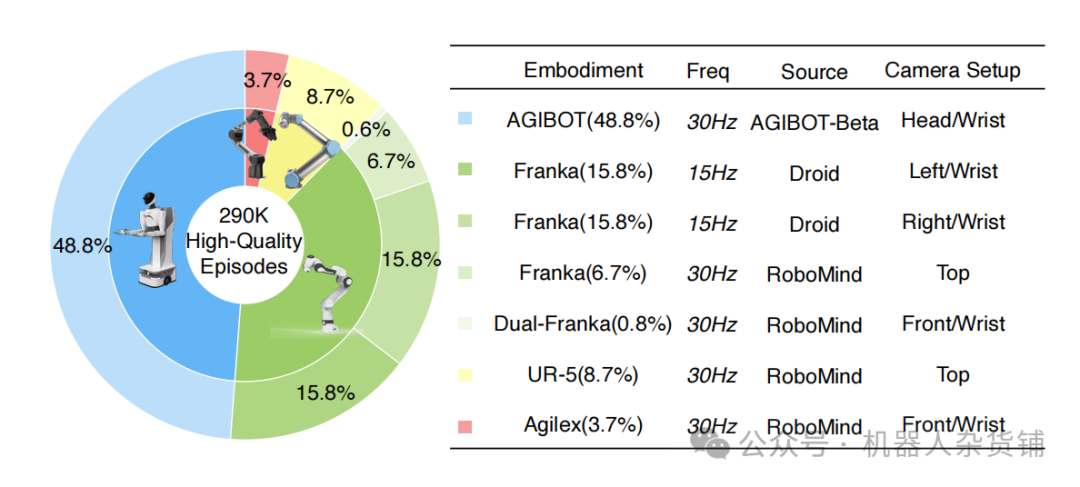
2. 解决方案:以“软提示”为核心的X-VLA模型
X-VLA模型的核心是其创新的软提示(Soft Prompt)机制。这一机制可以被形象地理解为给每个机器人的数据集分配一张独特的、可学习的“身份证”。从本质上讲,这些提示充当了可学习的、特定于领域的条件变量,用于引导共享的Transformer主干网络,使其能够根据数据来源动态调整自身行为。
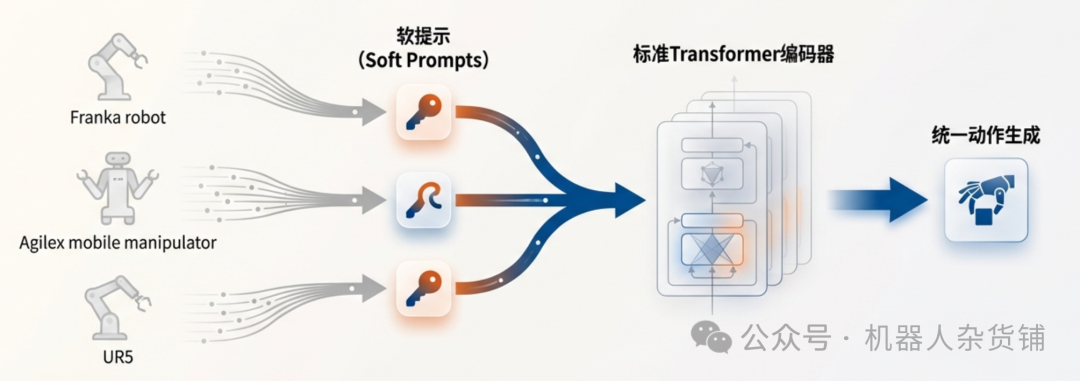
在选择软提示之前,研究人员曾评估过其他几种方案。例如,“语言提示”依赖于人工编写的机器人描述,这种方式不仅繁琐,而且在面对新配置时适应性很差。另一种“HPT式输入投影”方法,则试图将不同来源的输入映射到统一的特征空间,但这容易破坏预训练VLM模型中宝贵的先验知识,导致训练过程不稳定。相比之下,软提示机制巧妙地结合了这些方法的优点,既能提供领域特定的引导,又无需人工编写模板,更不会干扰模型预训练好的知识,从而实现了稳定高效的训练。
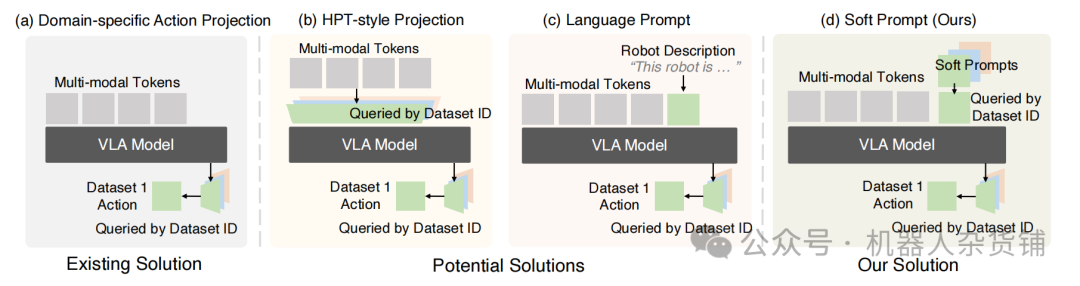
基于这一原理构建的X-VLA模型,采用了一种“简洁的、基于流匹配(Flow-Matching) 的VLA架构”。至关重要的是,该模型避免了任何复杂的、定制化的架构修改。通过将处理异构性的任务完全交给软提示,其核心架构可以保持简单,完全由标准的Transformer 构成,这正是其兼具简单性 和可扩展性 的关键。
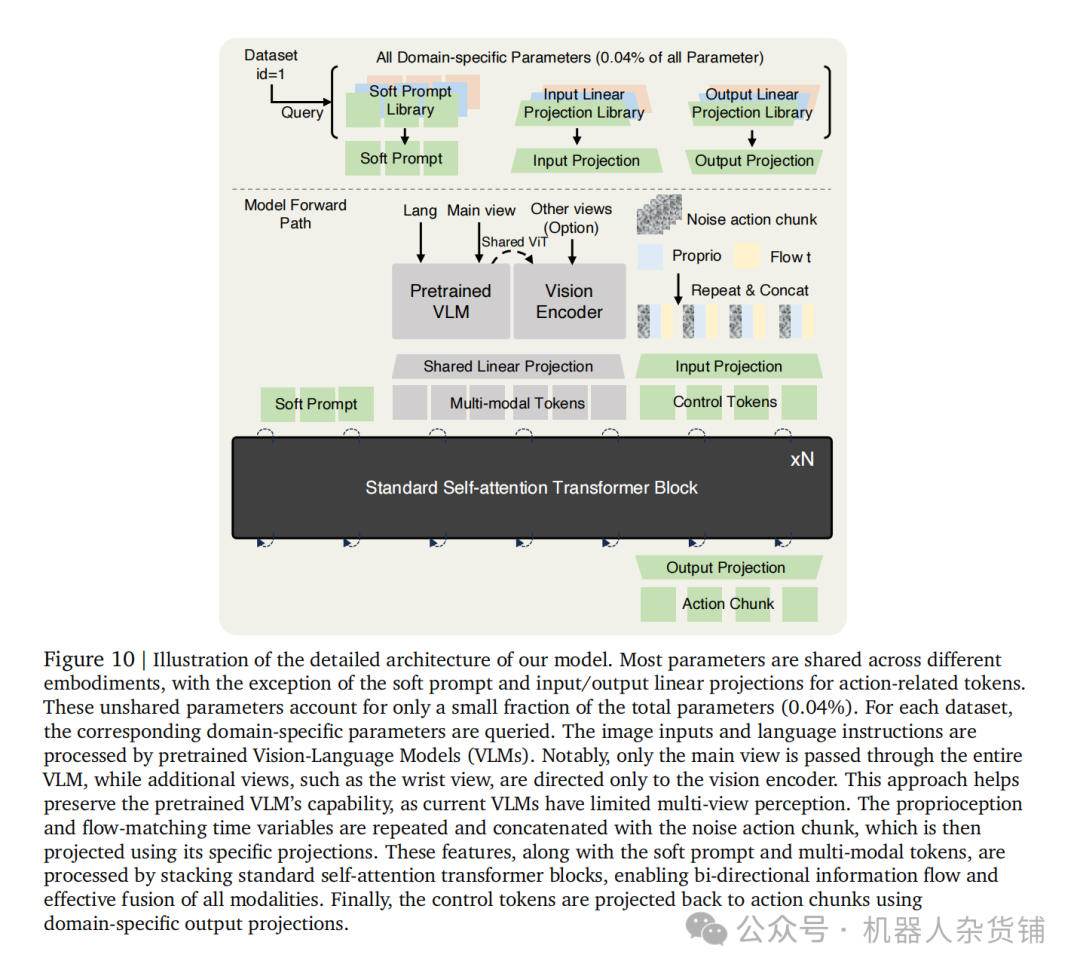
X-VLA的训练和应用分为两个阶段:
-
第一阶段:预训练 (Pretraining): 模型在包含多种机器人数据的大规模异构数据集上进行预训练,学习一个强大但潜藏的本体无关通用策略。
-
第二阶段:领域自适应 (Domain Adaptation): 当需要将模型适配到一个新的机器人时,只需为新机器人引入并优化一组新的软提示,同时保持预训练好的模型主干网络冻结。这一过程能够高效地解锁和特化模型潜藏的通用能力,使其在新任务上快速生效。
3. 性能验证:X-VLA的实证表现
实验结果充分证明了X-VLA模型的有效性和优越性。
3.1. 跨基准测试的SOTA性能
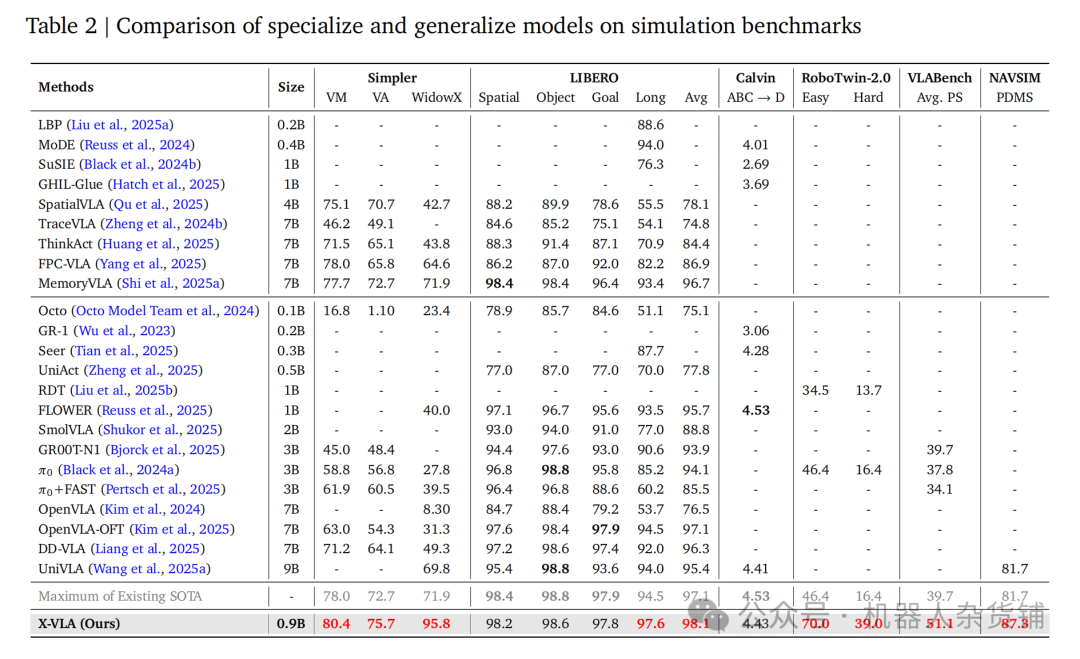
X-VLA模型(特别是其0.9B参数版本X-VLA-0.9B)在一系列广泛的基准测试中均取得了当前最佳性能。它不仅在多个单项测试中超越了先前最佳纪录,更在极具挑战性的LIBERO基准测试套件中,凭借四个子任务的平均分创造了新的SOTA,展现了其卓越且全面的泛化能力。
3.2. 惊人的参数效率
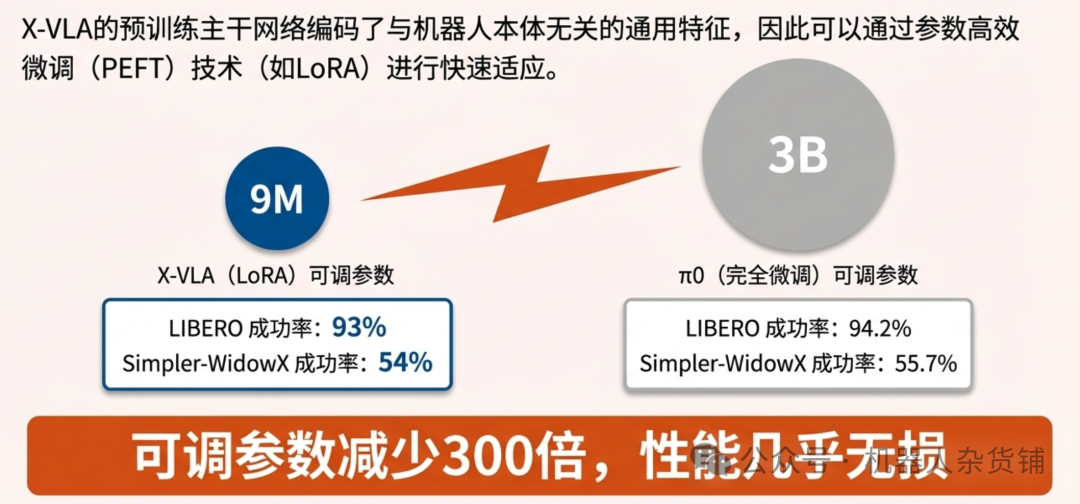
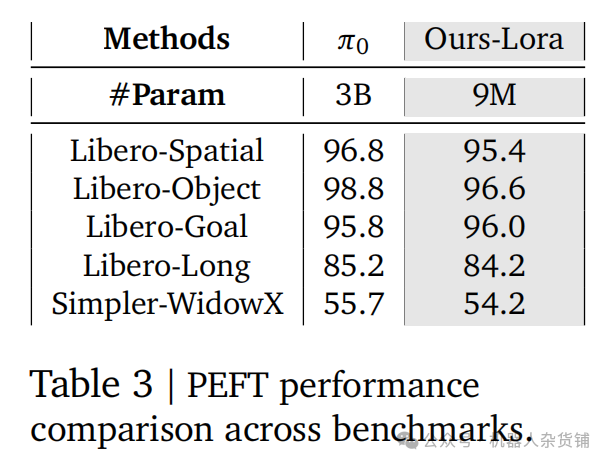
X-VLA在参数高效微调(Parameter-Efficient Finetuning, PEFT) 方面表现出色。PEFT旨在用最少的参数调整来实现模型的适配。
实验证明,仅微调其 1% 的参数(9M),X-VLA-0.9B的性能便能与完全微调的30亿参数模型 π₀ 相媲美。
3.3. 真实世界中的灵巧操作与未来潜力
在真实世界中,X-VLA同样表现出色。在叠衣服的操作任务中,X-VLA展现了其预训练阶段学到的强大能力。正是得益于其强大的、本体无关的通用特征,模型仅使用1200个演示数据进行微调,就实现了极高的成功率和处理效率,其表现不仅可与那些使用远超此规模数据集训练的闭源模型相提并论,也优于在相同数据上从零开始训练的其他模型。
此外,X-VLA展现出很高的拓展性。实验表明,随着模型规模、数据多样性和数据量的增加,模型的预测误差持续下降,且该趋势没有出现饱和迹象,这表明其未来仍有巨大的提升潜力。
结论:迈向通用机器人模型的关键一步
X-VLA模型及其核心的软提示机制,针对机器人领域长期存在的关键瓶颈-数据异构性问题,提供了一个简单、可扩展且高效的方案。它在多个基准测试中取得了SOTA性能,在模型适配中展现了卓越的参数效率,并在真实世界的复杂任务中证明了其灵巧操作能力。
关注“机器人杂货铺”来获取更多内容吧!


DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)