探索全局路径规划算法与 DWA 算法融合实现动态避障
各种全局路径规划算法与DWA算法的融合实现动态避障在机器人运动规划领域,如何让机器人在复杂且动态变化的环境中安全、高效地到达目标点,一直是研究的热点。其中,全局路径规划算法为机器人规划出从起点到终点的大致路线,而动态窗口法(DWA)则专注于在局部环境中实时避开动态障碍物。将这两者巧妙融合,能显著提升机器人在动态环境下的避障能力。
各种全局路径规划算法与DWA算法的融合实现动态避障
在机器人运动规划领域,如何让机器人在复杂且动态变化的环境中安全、高效地到达目标点,一直是研究的热点。其中,全局路径规划算法为机器人规划出从起点到终点的大致路线,而动态窗口法(DWA)则专注于在局部环境中实时避开动态障碍物。将这两者巧妙融合,能显著提升机器人在动态环境下的避障能力。
全局路径规划算法
全局路径规划算法旨在从宏观层面为机器人找出一条从起始位置到目标位置的可行路径。常见的算法如 A*算法、Dijkstra 算法等。
以 A*算法为例,它通过维护一个优先队列,结合启发函数来评估每个节点到目标点的代价。代码实现大致如下:
import heapq
def heuristic(a, b):
return abs(a[0] - b[0]) + abs(a[1] - b[1])
def astar(graph, start, goal):
open_set = []
heapq.heappush(open_set, (0, start))
came_from = {}
g_score = {node: float('inf') for node in graph.keys()}
g_score[start] = 0
f_score = {node: float('inf') for node in graph.keys()}
f_score[start] = heuristic(start, goal)
while open_set:
_, current = heapq.heappop(open_set)
if current == goal:
path = []
while current in came_from:
path.append(current)
current = came_from[current]
path.append(start)
path.reverse()
return path
for neighbor in graph[current]:
tentative_g_score = g_score[current] + graph[current][neighbor]
if tentative_g_score < g_score[neighbor]:
came_from[neighbor] = current
g_score[neighbor] = tentative_g_score
f_score[neighbor] = tentative_g_score + heuristic(neighbor, goal)
if neighbor not in [i[1] for i in open_set]:
heapq.heappush(open_set, (f_score[neighbor], neighbor))
return NoneA*算法代码分析
heuristic函数是启发函数,这里采用曼哈顿距离来估计节点到目标点的代价。曼哈顿距离简单计算横纵坐标差值的绝对值之和,能快速给出一个粗略的代价估计。astar函数主体,openset是优先队列,使用heapq模块实现,确保每次取出的节点是当前代价最小的。camefrom记录路径,gscore记录从起点到每个节点的实际代价,fscore是综合实际代价和启发式代价的总代价。- 在主循环中,从优先队列取出当前代价最小的节点,如果是目标节点则回溯路径并返回。对当前节点的邻居节点进行评估,更新它们的
gscore和fscore,如果邻居节点不在open_set中则加入。
动态窗口法(DWA)
DWA 算法主要考虑机器人的运动学约束和局部环境信息,实时生成安全的运动轨迹。它在一个动态窗口内搜索最优的速度和角速度组合。
以下是简化的 DWA 算法 Python 代码框架:
import numpy as np
def dwa_control(robot_state, goal, obstacles, v_max, w_max, dt):
# 动态窗口生成
v_min = 0
w_min = -w_max
v_window = np.linspace(v_min, v_max, num=10)
w_window = np.linspace(w_min, w_max, num=10)
best_score = -np.inf
best_v = 0
best_w = 0
for v in v_window:
for w in w_window:
predicted_state = predict_state(robot_state, v, w, dt)
score = evaluate_score(predicted_state, goal, obstacles)
if score > best_score:
best_score = score
best_v = v
best_w = w
return best_v, best_w
def predict_state(state, v, w, dt):
x, y, theta = state
new_x = x + v * np.cos(theta) * dt
new_y = y + v * np.sin(theta) * dt
new_theta = theta + w * dt
return np.array([new_x, new_y, new_theta])
def evaluate_score(state, goal, obstacles):
# 这里简单以到目标点距离和到障碍物距离作为评估指标
dist_to_goal = np.linalg.norm(state[:2] - goal[:2])
min_dist_to_obstacle = np.inf
for obstacle in obstacles:
dist = np.linalg.norm(state[:2] - obstacle[:2])
if dist < min_dist_to_obstacle:
min_dist_to_obstacle = dist
score = -dist_to_goal + min_dist_to_obstacle
return scoreDWA 算法代码分析
dwa_control函数中,首先定义了速度和角速度的动态窗口范围,通过np.linspace生成一系列候选速度和角速度值。- 嵌套循环遍历所有候选组合,调用
predict_state函数预测机器人在该速度和角速度下经过时间dt后的状态。 evaluate_score函数评估预测状态的优劣,这里简单地以到目标点的距离和到最近障碍物的距离作为评估指标,距离目标点越近且距离障碍物越远得分越高。- 最终返回得分最高的速度和角速度组合。
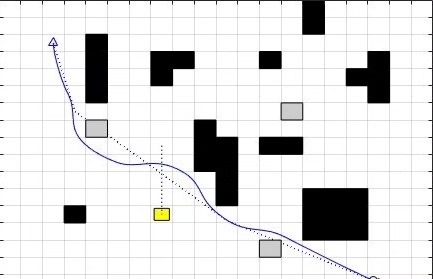
两者融合实现动态避障
将全局路径规划算法(如 A)与 DWA 融合时,首先利用 A算法规划出一条全局路径。然后,DWA 算法以全局路径上的点作为局部目标,在动态环境中实时调整机器人的速度和方向,避开障碍物。
以下是融合实现的简化代码框架:
# 假设已经有前面定义的 astar, dwa_control 等函数
def global_local_planning(graph, start, goal, obstacles, v_max, w_max, dt):
global_path = astar(graph, start, goal)
if not global_path:
return None
robot_state = np.array(start)
local_goal_index = 0
while local_goal_index < len(global_path):
local_goal = global_path[local_goal_index]
v, w = dwa_control(robot_state, local_goal, obstacles, v_max, w_max, dt)
robot_state = predict_state(robot_state, v, w, dt)
# 检查是否到达局部目标点附近
if np.linalg.norm(robot_state[:2] - local_goal[:2]) < 0.5:
local_goal_index += 1
return robot_state融合代码分析
globallocalplanning函数先调用astar规划全局路径,如果规划失败则返回None。- 初始化机器人状态为起点,设定局部目标点索引。在循环中,将全局路径上的点依次作为局部目标,调用
dwa_control函数获取速度和角速度,更新机器人状态。 - 通过判断机器人与局部目标点的距离,决定是否切换到下一个局部目标点,直到遍历完全局路径。
通过这种全局路径规划算法与 DWA 算法的融合,机器人能够在复杂动态环境中,既拥有宏观的路径指导,又能实时避开突然出现的障碍物,实现更加智能、高效的移动。这为机器人在实际应用场景,如智能仓储、服务机器人等领域,提供了更可靠的运动规划方案。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 25
25 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)