详解genmanip,生成桌面操作仿真数据
论文:GENMANIP: LLM-driven Simulation for Generalizable Instruction-Following Manipulation
1. 介绍
-
机器人仿真平台:对场景、对象和活动类型的多样性以及底层模拟环境的真实性生成演示不足
-
任务和场景生成:
- 基本的域随机化+手动构建程序生成;
- 但GENMANIP采用场景图构建任务场景
-
操纵方法:在模块化操作工作利用GPT-4V/GPT-4o等大型多模态模型
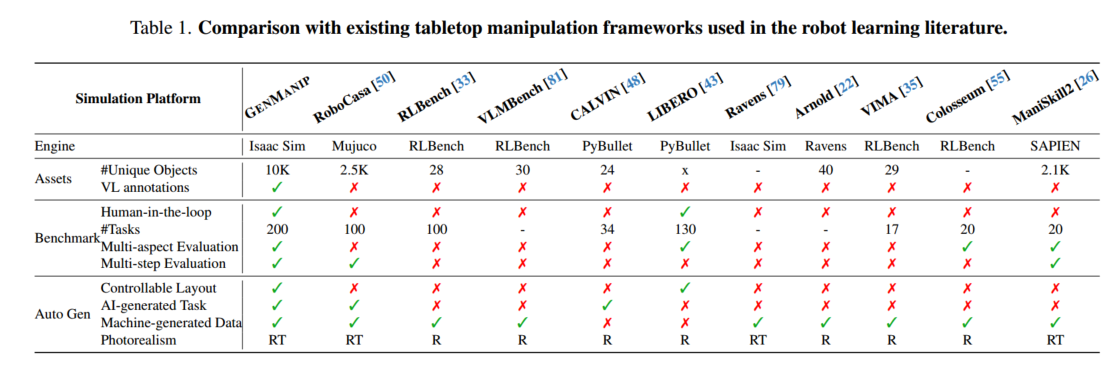
为了解决这些局限性,我们引入了GENMANIP,这是一个现实的大规模桌面仿真平台,专为评估不同场景和指令下的机器人而量身定制。如图1所示,GENMANIP具有丰富的各种3D对象资产集合、面向任务的场景图(ToSG)的标准化范式和LLM驱动的自动任务生成管道。ToSG是任务相关对象的可扩展和结构化表示,在图中将对象级和空间关系编码为节点和边

2. 方法
GENMANIP,这是一个为政策泛化研究量身定制的现实桌面模拟平台。它通过LLM驱动的面向任务的场景图提供了一个自动流水线,使用10K个带注释的3D对象资产合成大规模、多样化的任务
2.1 基本资产收集和基本技能
GENMANIP基于NVIDIA的IsaacSim构建,利用其逼真的渲染和高效的并行数据效率。
带有VL注释的刚性资产。策略泛化需要大规模、多样化和注释丰富的3D对象集。因此通过从Objaverse采购刚性对象以及从GRUtopia和PartNet Mobility采购铰接对象来管理高质量资产,如图1所示。我们的注释管道包括:
- 过滤:我们通过基于标签和标题进行过滤,将Objaverse的资产从660K减少到70K。我们进一步排除了网格面少于1K或缺少正常纹理网格的物体。
- 通过GPT-4V对物体进行VL注释:对于每种资产,我们生成结构化注释,包括对象描述、物理属性(比例、质量)和语义属性(类别、颜色、形状、材料)。
- 居中和调整大小:我们使用GPT-4V将10k资产物体居中并重新缩放到桌面大小,然后进行人工循环校正
铰接资产。我们手动注释100个铰接对象(例如笔记本电脑、垃圾桶、烤箱、微波炉、抽屉),明确指定它们的物理约束。
不同的背景。为了确保环境的多样性,我们整合了100张室内HDRI图像,用不同的背景和照明条件丰富了场景。
原始技能。对于拾取和放置任务,我们手动应用原始技能,如拾取和放置。我们定义了关键姿势:pre-grasp, post-grasp, move, pre-{place} 和post-{place},其中抓取和放置姿势是根据物体高度确定的。
2.2 任务和场景布局生成
为了从大规模带注释的资产中自动合成各种任务场景,我们以适合LLM操作的结构化但直观的格式表示每个场景。
传统的表示法,如PDDL,明确地定义了世界状态、初始条件、行动和目标。然而,它们的严格语法,涉及详细的动作前提和状态转换,对于LLM来说很麻烦。
为了简化中间表示,我们引入了面向任务的场景图(ToSG),这是一种结构化但自然的格式,专为涉及空间和关系推理的机器人操作场景而设计。ToSG由以下组件组成:
-
任务指令:旨在澄清和消除设计场景图歧义的文本指令。
-
场景图:节点表示对象内部状态(例如,打开、关闭),表示为:
(object,status)
边定义了对象间的关系,具体如下:
( object,relation, anchor object)
可能的关系包括left, right, front, behind, near, on, in,所有这些都与相机视角有关。 -
目标条件:定义为条件项列表,每个条件包括成对(目标对象状态)或三元组(目标关系)
goal: - - obj1_uid: - '0' obj2_uid: - '1' position: - top
LLM驱动的ToSG生成。
- 随机抽一个种子物体
- 选择种子任务类型:短期推理(空间、外观和常识)和长期任务
- 根据种子对象 + 种子任务类型,从带注释的资产集合中检索相关对象
- 用 GPT-4 生成一个「任务场景描述」以及对象标签列表
- 自然语言场景 → 结构化的 ToSG
2.3 模块化操作系统
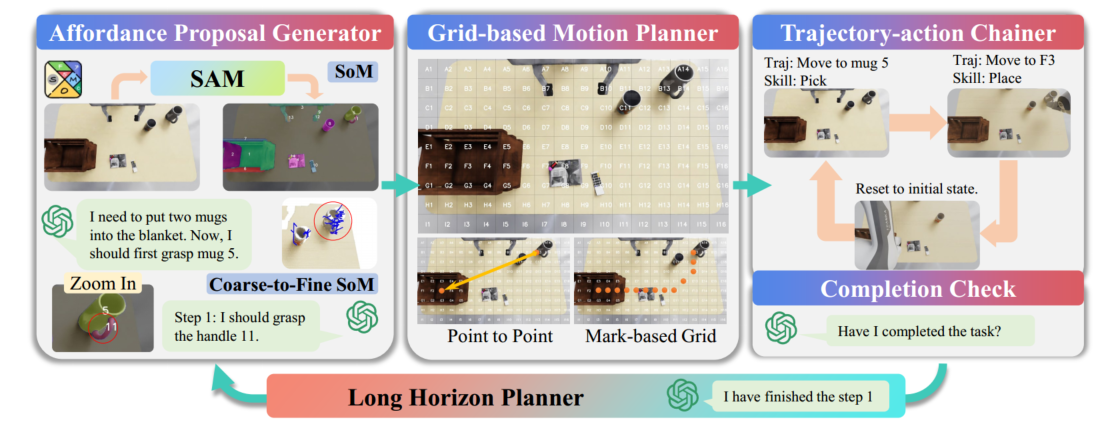
最近的模块化方法利用大语言模型或基础模型中的基于标记的视觉提示,在实际任务中实现了强大的泛化能力。我们将这些策略抽象为一个统一的模块化系统,如图4所示,该框架包括四个模块:an affordance proposal 生成器、基于网格的运动规划器、轨迹动作链和长视野规划器
affordance proposal 生成器
整体理解:找到“抓哪里”(物体 & 可抓部位 & 抓取姿态)。
关键步骤:
-
SAM2 分割: RGB 图输入到 SAM2 ,生成对应的就是「物体 mask + 编号」
-
SoM( Set-of-Mark prompting) 选目标物:相机RGB图、掩码分割图 +任务指令输入到VLM模型,选出“哪一个物体”(杯子 5)(粗粒度的目标)
Set-of-mark prompting unleashes extraordinary visual grounding in gpt-4v,2023
SoM技术:采用交互式分割模型(例如 SAM)将图像划分为不同粒度级别的区域,并在这些区域上添加一组标记(mark),例如字母数字、掩码(mask)、框(box),使用添加标记的图像作为输入,模型推理更加细致、准确
https://zhuanlan.zhihu.com/p/662860990 -
Coarse-to-Fine SoM 选可抓部位:把放大后的RGB局部图 +掩码分割图 + 任务指令喂给 VLM,生成细粒度的目标(例如杯柄还是杯身)
-
AnyGrasp 生成并过滤抓取姿态:在全图 RGB-D 上生成所有候选抓取姿态,并用 mask 过滤,只保留该部分的抓取姿态,并选择最合适的抓取点。
GenManip 的 Pick-and-Place 轨迹生成策略如下: 计算抓取位姿(grasp pose)与放置位姿(place pose)。 基于抓取/放置位姿沿夹爪朝向推导出四个辅助位姿:pre_grasp、post_grasp、pre_place、post_place。 在这些位姿之间进行插值,得到连续的轨迹(motion)。
基于网格的运动规划器
整体理解:在网格上“画一条路”,并转成 3D 轨迹点(带高度和末端姿态)
- 把桌面图像离散成 9×16 网格;
- 用上一步 SoM 的结果,确定目标物体所在格子;
- 通过路径规划以获取一系列waypoint。
- Point-to-Point:输入任务指令、对象名称、抓取点(在图像中标记)输入到 VLM,获取放置位置单元标签
- Grid-based Path Planning:输入任务指令、对象名称、抓取点(在图像中标记)输入到 VLM,输出每次移动都应包括网格单元编号、桌子上方的高度(0.1至0.5米)和夹爪的方向
- 使用MPlib(实际采用curobo,效果更好)进行运动规划,生成一系列轨迹点
轨迹动作链
把 Grid-based Planner 输出的“末端轨迹”与高层脚本技能(pick/place 等)配对,形成 “Traj + Skill” 的可执行子任务单元
长视野规划器
- 根据指令、历史与当前状态来决定下一步该调用哪个子任务(Traj+Skill),在每一步后做完成检查;
- 如果没完成,就触发重新从 Affordance 模块开始规划,从而在很长的任务序列中维持进度、并能从失败中恢复。
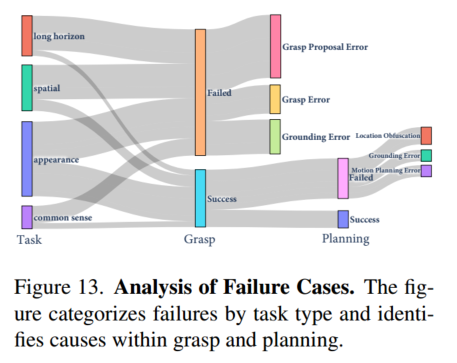
附录中提到的错误分析
任务分为四种类型:空间、外观、常识和长时程。
抓取故障分为三个子类别:(1)grounding错误,由场景对象模型(SoM)生成的不正确掩码引起;(2) Grasp Proposal Error,Context-to-Frame (CtoF) SoM或AnyGrasp识别的姿势无法执行抓取;以及(3) Grasp Error,因碰撞或其他操作问题引起
同样,规划失败分为:(1)Grounding Error,由于选择了不正确的锚对象 (anchor object);(2)Location Obfuscation,涉及对放置规范的混淆(例如,区分“on”和“near”);以及(3)Motion Planning Error,无法执行计划路线。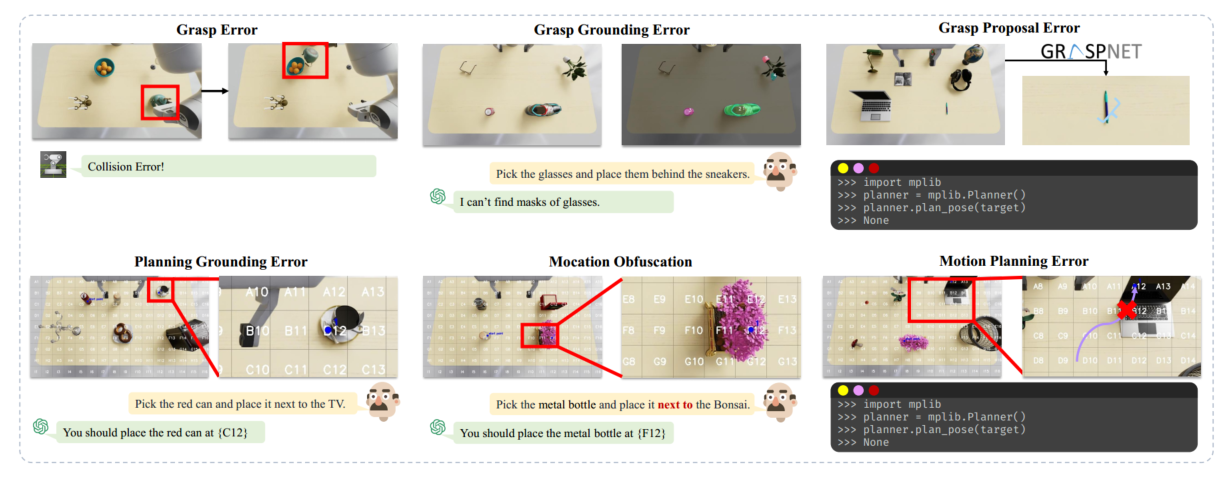
3. GENMANIP特点:
- 基于桌面操作环境生成仿真数据
- 目前只支持pick&place操作
4. 应用
InternVLA-M1: A Spatially Guided Vision-Language-Action Framework for Generalist Robot Policy
论文中提到了InternVLA-M1模型用作机器人控制,在 GenManip和Isac Sim的基础上构建一个高度可扩展、灵活且完全自动化的模拟流程,生成InternVLA-M1数据集
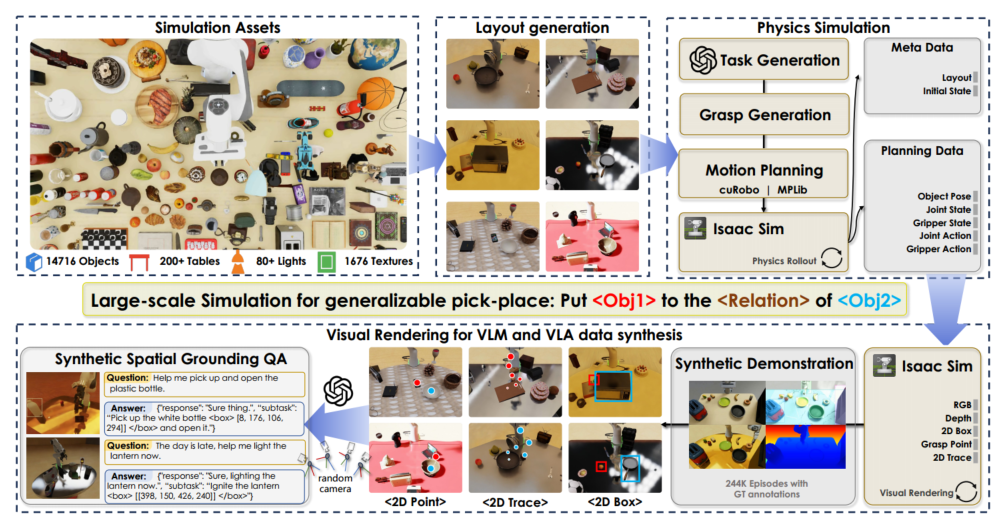
- 用于通用拾取和放置的自动任务合成
- 用于空间grounding的VLM数据和VLA数据的合成

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 21
21 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)