GR-RL——首个让机器人系鞋带的VLA:先离线RL训练一个“分布式价值评估器”以做任务进度预测,后数据增强,最后在线RL
前言
随着大家(包括我司具身团队)在不断落地的过程中,越来越发现,在很多精细场景,或高精度场景下,单纯VLA的局限性越来越大
- 故,一方面,像PI这样的公司发布了π*0.6
详见此文《π∗0.6——RL微调流式VLA π0.6:先基于演示数据做离线RL预训练,再在线RL后训练(与环境自主交互,从经验数据中学习,且必要时人工干预)》
————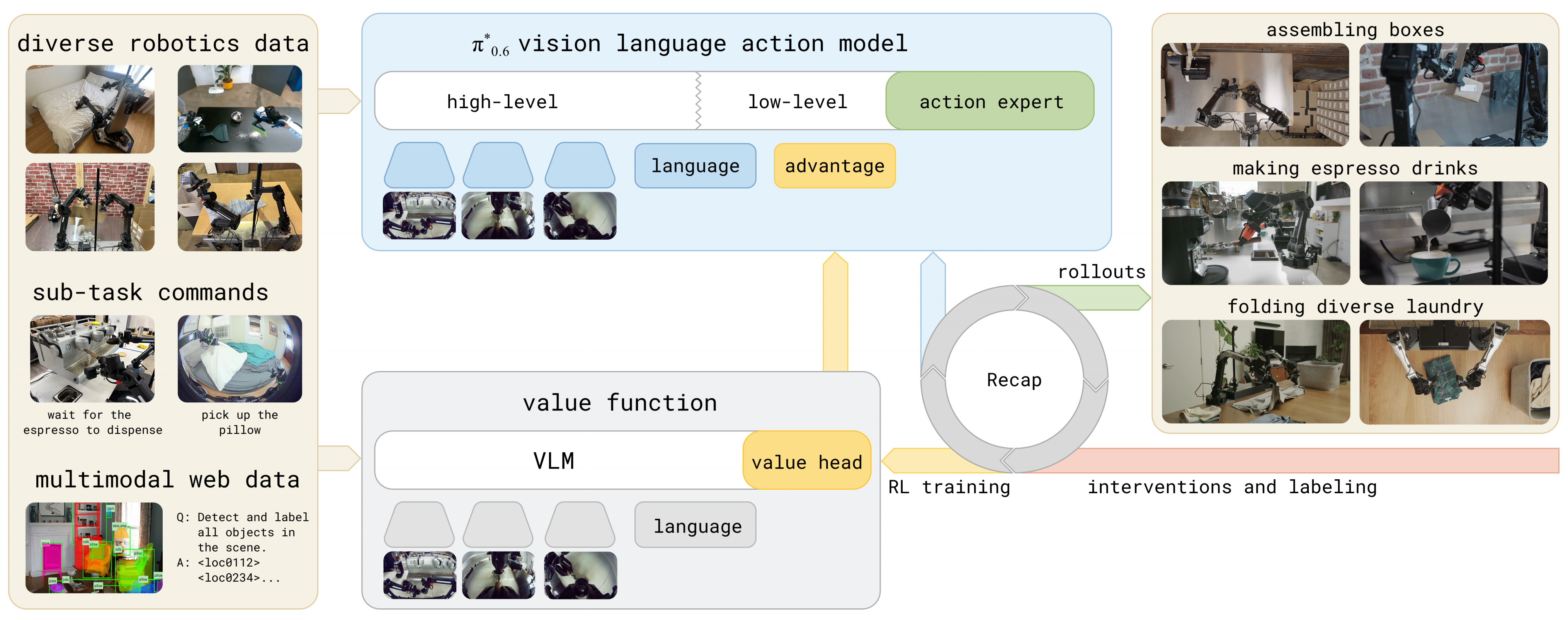
其算是VLA技术发展领域的一个风向标,即VLA与RL的结合是大势所趋 - 另外一方面,也确实越来越多的动作开始结合「vla + rl」了,比如本文要解读的GR-RL
第一部分 GR-RL——面向长时域机器人操作的灵巧与精确
1.1 引言与相关工作
1.1.1 引言
如原论文所述,现有的VLA策略在实际部署中在两个基本方面仍然存在严重不足:
- 精确灵巧性——对可变形物体的毫米级控制仍未得到解决
- 长时域鲁棒性——在多步操作中,误差会逐步累积,当与高精度灵巧操作相结合时问题尤为突出
————
以穿鞋带任务为例:
i) 机器人应具备足够的灵巧性:来操作包括鞋带和鞋在内的可变形物体
ii) 机器人需要实现毫米级的控制精度,将鞋带穿入鞋眼;
iii) 机器人还需要具备长时序操作能力,以应对多样化和不可预见的情境
经典方法通过使用预定义的动作原语和设计好的动作模式进行运动规划来解决系鞋带问题 [38–40]
因此对于未见过的配置的泛化能力、失败后的恢复能力以及其他灵巧操作技能仍然是一个未解决的问题
此,对于行为克隆的简单扩展将导致在系鞋带任务中表现为次优且受限的技能
此前,字节跳动提出了GR-3 [12],这是一种从互联网数据、机器人轨迹和人类示范中训练而成的大规模 VLA 策略。尽管 GR-3 具有很强的泛化能力,但在精度、灵巧性和长时域鲁棒性至关重要的情况下,GR-3 仍会失败
为何如此呢,作者观察到存在两个关键瓶颈:
- 次优的人类演示
- 演示与推理之间的不匹配
在极端精确和灵巧的操作场景下,人类演示者通常会动作放慢、犹豫,从而为策略引入带有噪音的次优演示
然而,为了实现流畅的推理和控制,通常还需要对预测的轨迹进行后处理平滑『如时序集成[63]』、异步递推控制 [8,14,25] 等一系列控制层优化方法
这些系统级优化方法对于基于学习的策略的平滑执行是必需的,但也不可避免地导致模型训练与推理之间出现不匹配
由此,作者提出了GR-RL
- 其对应的论文为:GR-RL: Going Dexterous and Precise for Long-Horizon Robotic Manipulation
- 其对应的作者为:Yunfei Li, Xiao Ma, Jiafeng Xu, Yu Cui, Zhongren Cui, Zhigang Han, Liqun Huang, Tao Kong, Yuxiao Liu, Hao Niu, Wanli Peng, Jingchao Qiao, Zeyu Ren, Haixin Shi, Zhi Su, Jiawen Tian, Yuyang Xiao, Shenyu Zhang, Liwei Zheng, Hang Li, Yonghui Wu
具体而言,其用于长时段的灵巧与精细操作『该流程包括:1)利用学习到的任务进度进行离线过滤行为克隆;2)简单而有效的动作增强;3)在线强化学习』

GR-RL采用了多阶段强化学习增强的训练流程用于筛选、增强并强化:次优及不匹配的人类演示数据
- 首先,作者并非直接对完整的人类演示数据集进行行为克隆,而是通过过滤后的轨迹初始化基础GR-RL VLA策略
具体上,作者利用离线RL[17],对成功和失败的轨迹共同训练一个评价器模型
即在每个回合结束时给予稀疏奖励,这样预测的价值自然反映任务的进展程度
且进一步利用这一价值结果仅保留对任务正向推进有贡献的状态转换,将其余数据剔除
which we further use to filter only transitions that contribute positively to the progress anddiscard the rest
并采用分布式评价器,观察到在离线稀疏奖励场景下,该方法可以显著提升鲁棒性
We adopt distributional critics and observe that they give much more robust performance under offline sparse reward scenarios. - 接下来,在离线预训练检查点的基础上,作者进行在线强化学习,以进一步探索和修正基础策略中的失败模式
具体而言,作者通过学习将去噪过程引导到高回报区域来实现这一目标[58]
In particular, we achieve this by learning to steer the denoising process towards high-return regions [58-Steering your diffusion policy with latent space reinforcement learning] - 最后,作者提出了一种简单有效的增强机器人动作的方法,即通过镜像机器人动作和观测,并配以翻转后的文本描述
这一方案显著提升了他们策略的整体成功率与泛化能力
1.1.2 相关工作
首先,对于通用机器人基础策略
- 构建通用机器人基础操作策略一直是机器人研究与应用领域面临的长期挑战
[4,6–10,25,27,31,32,49,54,56] - 近期,构建VLA模型的进展推动了通过增加动作模态,将基于大规模网页数据预训练的VLMs适配于机器人动作的研究
[8,15,25,27,29,36,46,48,56,59]
其核心思想是利用由人类远程操作员收集的大规模真实机器人轨迹,以实现对潜在新颖场景和任务的泛化
GR-RL 基于 GR-3 [12] 先前的成功经验,GR-3 是一种通过网页级数据与人类演示共同训练的通用策略。GR-RL 进一步通过筛选高质量数据、扩增动作以及在线真实世界RL,对 GR-3 进行改进,从而使其能够执行长时序的灵巧且精确的操作
其次,现实世界强化学习
纯模仿学习的一个核心局限性在于其易受累积误差影响,并且无法超越演示的表现
- 为了解决这些问题,大量研究探索了在线数据采集和现实世界RL,以提升操控的稳健性,超越有监督训练的范畴
[2, 26, 28, 30, 42-44, 52, 53]
在VLA 背景下,一些最新的工作旨在通过仿真中的on-policy RL 进行策略改进
[13, 34, 37, 50, 62]
然而,将它们的成功转移到现实世界场景仍然很困难,因为现实世界中的交互样本效率低且噪声较大 - 另一类工作通过学习世界模型并与所学习的世界模型进行on-policy RL 交互
18 −22, 45, 61, 65
世界模型缓解了真实机器人交互的问题,但由于视觉预测不准确又引入了新的问题
GR-RL 遵循了[42, 43, 52] 的方法,专注于现实世界的off-policy RL。这使得能够高效利用过往轨迹并提升样本效率。将现实世界中噪声较大的奖励视为一个分布,作者展示了分布式评论者相较于标准基于回归的评论者模型能显著提升稳健性
- 具体而言,在GR-RL工作的同时,π∗0.6 提出了一个用于高精度操控的现实世界RL 流程[24]
与π∗0.6 类似,作者都采用了学习任务进展的分布式评论者『Similar to π∗0.6, we both adopt distributional critics that learn the progress of the task』 - 然而,GR-RL并没有进行advantage-conditioned 去噪,而是直接进行滤波行为克隆,并同样观察到了明显的性能提升
鉴于更强的离线基础策略,这有助于在在线探索过程中缩小搜索空间。作者希望GR-RL 能为社区揭示从通用策略构建高能力专用智能体的某些见解,并推动可部署机器人学研究的边界
1.1.3 GR-RL模型的结构
GR-RL采用一种混合Transformer架构,由VLA模型和多任务评价器
组成,总参数量为50亿『如下图所示,GR-RL采用了一种Mixture-of-Transformer, 即MoT架构。它通过流匹配目标(flow-matching objective)共同训练机器人视觉-语言-动作轨迹,以及通过分布式强化学习(distributional reinforcementlearning)进行时序差分(Temporal-Difference, TD)误差的训练』
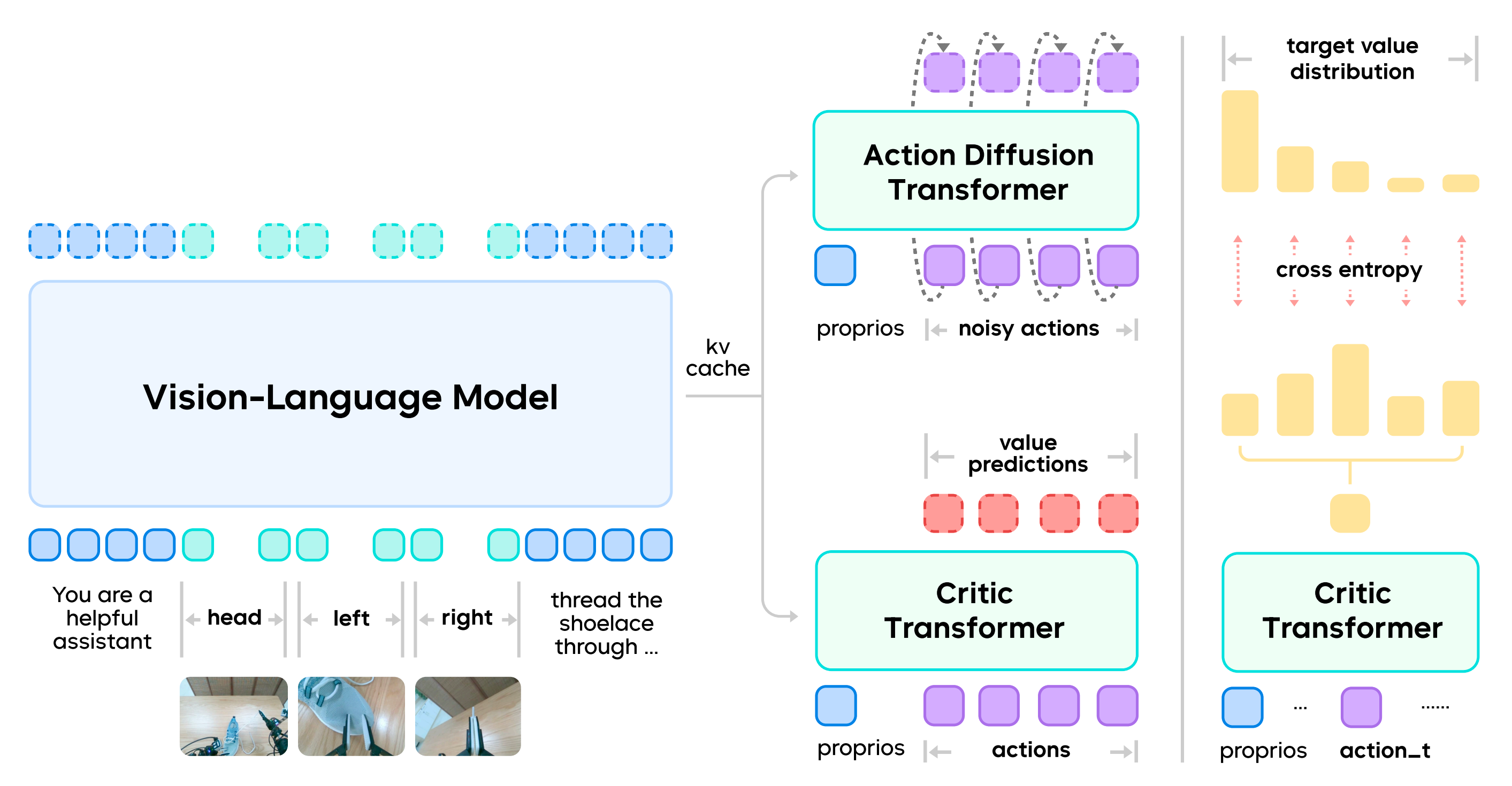
- 对于策略:
通过生成一个长度为
的动作片段
,在给定输入语言指令
、观测
和机器人状态
的条件下,控制具有移动底盘的双臂机器人,即
遵循GR-3 [12] 的架构设计,GR-RL 采用Qwen2.5-VL-3B-Instruct [3] 作为VLM骨干,并通过动作『扩散transformer (DiT)』预测由流匹配目标[8, 33, 35] 训练得到的动作片段
具体来说,作者遵循GR-3 的方法,仅使用VLM 后半部分层的KV 缓存以实现快速推理 - 评论者:与策略
是一个对每个动作进行评估的因果Transformer
具体来说,作者遵循Q-chunking [30-Reinforcement learning with action chunking,51]
————
详见此文《Q-chunking——带有动作分块的强化学习:基于人类演示,进行一定的连贯探索(且可做到无偏的n步价值回溯)》
————
并为每个动作块预测一个
值块,同时采用分布式强化学习
5-distributional perspective on reinforcement learning
16-Stop regressing: Training value functions via classificationfor scalable deep r
23-Rainbow: Combining improvements in deep reinforcement learning
51-Coarse-to-fine q-network with action sequence for data-efficient robot learning
区别于无界回归方式的策略评估,分布式评论者将值视为具有上下界的离散分布『Different from unbounded regression-based policy evaluation,distributional critics treat values as a discrete distribution with upper and lower bounds』
即这种方式自然而然地捕捉了真实世界轨迹中的不确定性
在稀疏奖励设置下,分布式评论者比非分布式评论者表现出更强的鲁棒性
通过将上界设为1、下界设为0,训练得到的评论者能够自然地反映任务的进展,如图3 所示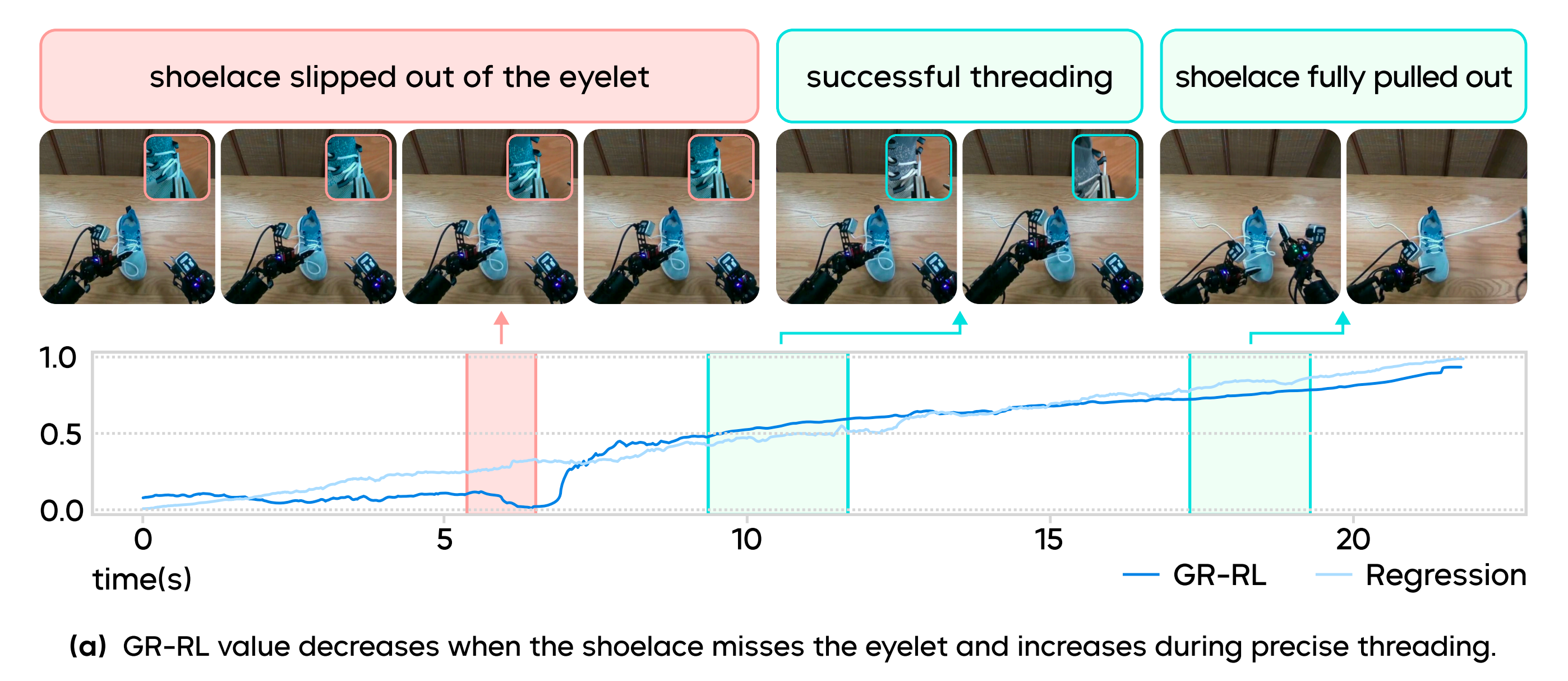
1.2 GR-RL的完整训练方法
由于人类示范存在次优和噪声,比如
- 在长时间跨度的高精度灵巧操作任务中,人类演示者往往会犹豫、出错,并以不一致的行为试图完成任务
- 此外,推理阶段的优化策略,如全身递归视野控制和时间集成方法 [14,63],进一步加剧了训练与部署之间的不匹配,从而增强了次优示范带来的负面影响
对此,作者引入了一种RL增强的训练流程,以实现基于人类示范的灵巧且精确的机器人操作,即
- 为防止策略在监督学习过程中记忆次优行为,利用离线RL学习任务进展模型,并用其过滤有害数据
To prevent the policy from memorizing suboptimal behaviors duringsupervised learning, we learn a task progress model using offline RL and use it to filter out detrimental data - 随后,根据双手操作的对称性,对示范数据进行增强,以提升离线策略的鲁棒性
- 最后,实施在线RL,使模型能够在闭环环境中通过试错学习,这有效缓解了训练与部署之间的偏差,并显著提升了整体性能
1.2.1 离线RL:基于学习任务进度评估器(分布式critics)的数据过滤
对于如系鞋带等对可变形物体进行高精度操作的任务,收集完美的演示数据极其困难。即使是有经验的远程操作者收集的轨迹也包含次优片段:错误的尝试、犹豫等
- 故直接模仿所有数据会不必要地将多模态噪声动作引入训练,导致策略表现次优
- 然而,标注这些次优片段并非易事,并且可能引入更多主观和噪声的人为先验
因此,为识别并过滤掉次优动作,作者提出利用离线强化学习学习一个任务进度模型。具体来说,采用TD3+BC [17-A minimalist approach to offline reinforcement learning]算法对critic进行训练『To identify and filter out suboptimal actions, we propose to learn a task progress model using offline RL.Specifically, we train the critic using TD3+BC [17]』
且采用如下稀疏奖励定义:
其中是一个指示函数,用于判断轨迹
是否成功,
表示轨迹的长度,
表示折扣因子
- 由于大多数收集到的轨迹都以成功结束,作者在每个示范中标注重试关键帧,并在事后生成更多失败的轨迹[1]
- 假设在一个成功轨迹
中,帧
被标注为重试关键帧
作者可以在原有成功轨迹的基础上,扩充出条失败轨迹
通过对成功和失败数据进行时序差分学习『时序差分的介绍详见此文《RL极简入门》的2.2节』,评论器 可以作为一个鲁棒的任务进度评估器,且在得到「任务进度模型」后,作者对
进行评估,并将其类别分布的均值作为数据集中所有转移的进度
预测进展的一个例子如图3 所示
- 可以观察到,当远程操作员犯错误时,进展会突然下降
作者将时间步t 处的一个样本定义为次优,如果在序列
中存在大于某一阈值
的数值下降,并且将所有次优样本从用于策略学习的数据集中剔除
- 然后,可以仅通过使用经过筛选的高质量数据集进行行为克隆来训练πθ
1.2.2 模仿学习:通过左右手的数据互换,做数据增强
在离线训练阶段,作者采用了一种简单但高效的形态对称增强范式,进一步提升了策略性能。该增强范式利用了双臂任务设置中的形态对称性
- 对于图像观测数据,作者将所有图像进行水平翻转,并交换左手腕与右手腕的图像
所有本体感知状态和动作数据都根据世界坐标系的镜像对称进行转换,随后再变换回各自的本地手腕坐标系 - 同时,也相应地翻转语言指令中的空间描述,例如,将“左边的孔”改为“右边的孔”
经验表明,对称性数据增强能够有效提升策略的表现
1.2.3 在线(RL)调整:以实现策略部署的一致性
在部署分块策略时
- 通常会采用系统级后处理方法以确保机器人运动的平滑性,例如时间集成和收缩域控制[14,63]
- 然而,这些优化技巧导致了训练与部署之间的不匹配:策略在训练中接收到的是原始动作,而实际部署时执行的却是经过优化的动作
在灵巧且精确的操作场景下,这种不匹配不容忽视
为了适应这种差异,作者发现通过封闭环的在线交互,使模型在执行对齐动作的过程中主动探索和自我改进至关重要
在长时序、高精度操作任务中进行在线强化学习仍然具有挑战性,尤其是在探索方面。由于该任务要求完成毫米级精度,仅对手腕位姿或关节位置添加噪声几乎难以取得成功
作者转而在潜在空间中进行结构化探索,并引导训练好的流策略[58]
- 具体而言,作者在共享的VLM 骨干网络后添加一个噪声预测器
,用于预测动作DiT 的初始噪声
噪声预测器
为了避免生成超出离线训练分布的任意噪声动作,当其输出偏离原始正态分布超过某一阈值β 时,作者对噪声预测器进行惩罚
其目标函数为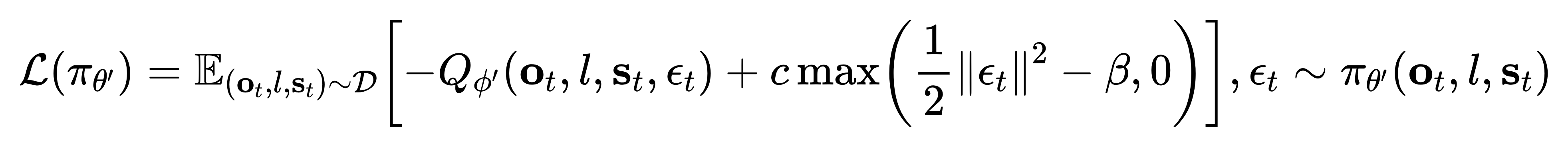
- 按照[58],作者还在噪声空间蒸馏一个Q 函数
,以避免在策略优化过程中反向传播通过流模型
————
在原始动作空间中的评论家
噪声空间中评论家的在线训练目标如下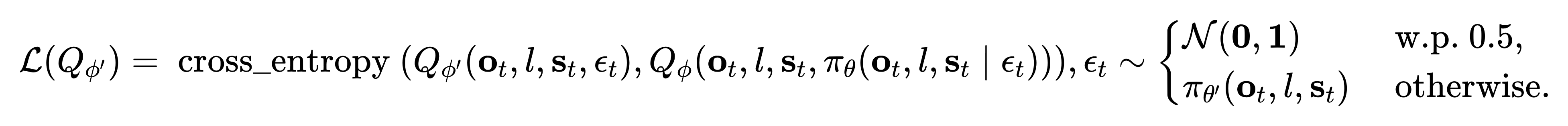
不同于原始实现[58],为了在蒸馏时确保对噪声空间的良好覆盖,作者以0.5 的概率(概率为0.5)从原始正态分布中采样输入噪声,其余情况下从噪声预测器中采样
且为了实现高效的离线到在线自适应,作者维护了一个离策略缓冲区和一个在策略缓冲区,并从这两个缓冲区中平均采样批次『For sample-efficient offline to online adaptation, we maintain an off-policy buffer and an on-policy buffer, and sample batches from them evenly』
- 在训练开始之前,作者通过离线训练的检查点进行在线rollout,预热离策略缓冲区,这与 Warm-start RL [64] 类似
详见此文《WSRL——热启动的RL如何20分钟内控制机器人:先离线RL预训练,之后离线策略热身(模拟离线数据保留),最后丢弃离线数据做在线RL微调》
————
且作者有意不将遥操作轨迹混入缓冲区,以避免策略在不匹配的动力学环境下训练 - 在策略缓冲区仅存储由最近两个检查点生成的轨迹,过时数据则被转移到离策略缓冲区
// 待更
1.3 局限性与结论
1.3.1 局限性
尽管 GR-RL 在长时序高精度的灵巧操作任务中表现出色,但仍然存在明显的局限性
- 当前流程中的一个主要问题是行为漂移现象。在稀疏且噪声较大的奖励条件下,策略行为在在线强化学习过程可能会变得不稳定
————
这可能是由于轻量级噪声预测器的能力有限,或者是在庞大的潜在动作空间中信任分配问题较为棘手 - 此外,将改进后的策略蒸馏至基础VLA,有望获得既强大又具通用性的操作策略
1.3.2 结论
GR-RL,作为一种面向机器人学习的框架,用于构建具备专长的VLA策略,以实现长时序的灵巧和精确操作
GR-RL的关键洞见在于:数据采集与策略推理之间的不匹配需要在线对齐
- GR-RL通过将从稀疏奖励中学习到的评价值视为任务进展预测,从而学习一个基于强化学习的评价器,并利用该评价器筛选高质量的转换,以训练一个稳健的基础策略
- 在此过程中,作者还引入了一种简单且有效的形态对称性增强方法,以提升整体性能
- 最后,作者进行了在线强化学习,使推理过程的行为与训练信号对齐
作者宣称,据他们所知,GR-RL是首个能够基于学习的方法实现系鞋带的策略。他们希望GR-RL能够成为实现现实世界专能机器人策略的一小步
// 待更

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 17
17 0
0- 0



 已为社区贡献51条内容
已为社区贡献51条内容

所有评论(0)