从零开始搭建虚拟情绪疗愈伙伴「沐木」:魔珐星云全栈实战指南
魔珐星云是全球首个面向开发者的具身智能3D数字人开放平台,具备高质量渲染、低延迟交互、高并发支持等六大核心优势。该平台通过云端创建数字人、技术架构设计、SDK加载等步骤,帮助开发者快速构建虚拟形象。以"沐木"虚拟情绪疗愈伙伴为例,展示了如何利用Vue3+TypeScript技术栈实现数字人应用的开发流程,包括SDK动态加载与状态检测等关键技术点。魔珐星云显著降低了数字人开发门槛
文章目录
什么是魔珐星云?
魔珐星云是魔珐科技在2025年10月29日正式发布的全球首个面向开发者的具身智能3D数字人开放平台。它不仅仅是一个数字人制作工具,而是一套完整的具身智能基础设施。魔珐星云的核心定位是"语言驱动身体",让大语言模型能够真正"长出身体",拥有自然的表情、手势和肢体语言。与传统内容生产工具不同,魔珐星云输出的是动作参数而非预渲染视频,这些参数可以实时驱动虚拟世界中的3D数字人,也能驱动物理机器人。
为什么选择魔珐星云进行数字人技术选型?
魔珐星云在数字人技术领域脱颖而出,主要得益于以下六大核心优势:
高质量渲染——数字人要"像人"
传统数字人常见的问题包括嘴型不准确、表情僵硬和动作机械。魔珐的解决方案采用52个面部关键点捕捉,不仅能精细控制嘴部,还能独立驱动眉毛、眼睛和脸颊。微表情系统让数字人能够表现出自然的情感——开心时眼角弯起,难过时眉头皱起。全身骨骼驱动技术则赋予数字人完整的肢体语言能力,而不是仅仅会说话的头部。呼吸动画功能在待机时显示自然的胸腔起伏,彻底消除了"静止感",让数字人看起来真正"活"了。
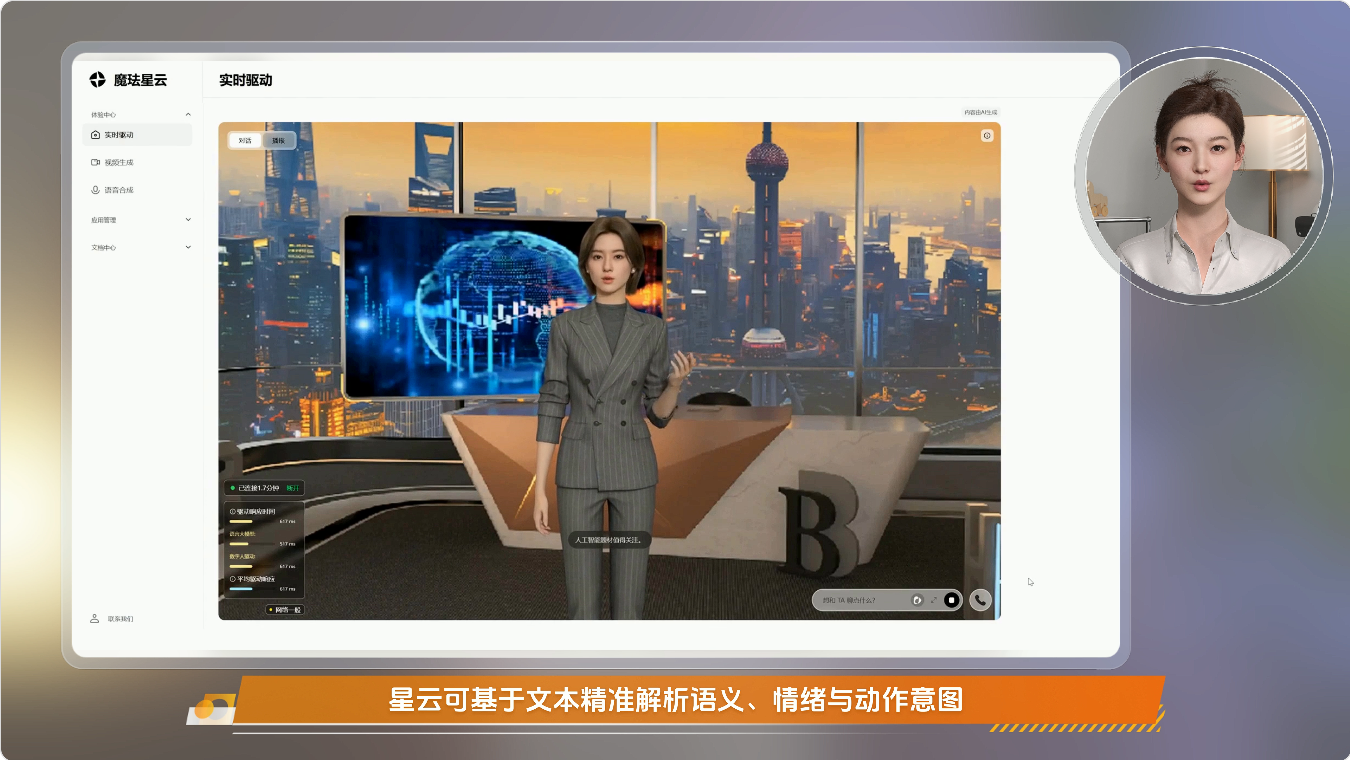
低延迟交互——对话要"跟得上"
这是数字人体验的生命线。根据最新测试数据,魔珐星云将端到端响应延迟压缩到了500毫秒以内(此前宣传的<300ms对部分场景有调整)。与传统方案相比,优化体现在多个环节:ASR语音识别实现流式识别,LLM通过流式输出实现首字响应,文本转语音合成在100毫秒内完成,数字人实时驱动响应时间控制在50毫秒以下。更重要的是,系统完全支持随时打断功能,用户可以在任何时刻改变指令,数字人会立刻停止并响应新的内容,这才是真正的自然对话体验。

高并发支持——轻松应对流量洪峰
采用云原生架构的魔珐星云具备弹性扩容能力,能根据用户数量自动增加或减少资源。系统通过智能负载均衡将请求分配到不同节点,并利用全国多地部署的CDN加速就近接入。这种设计让初创项目无需担心流量突增,实战数据显示系统支持千万级并发能力。
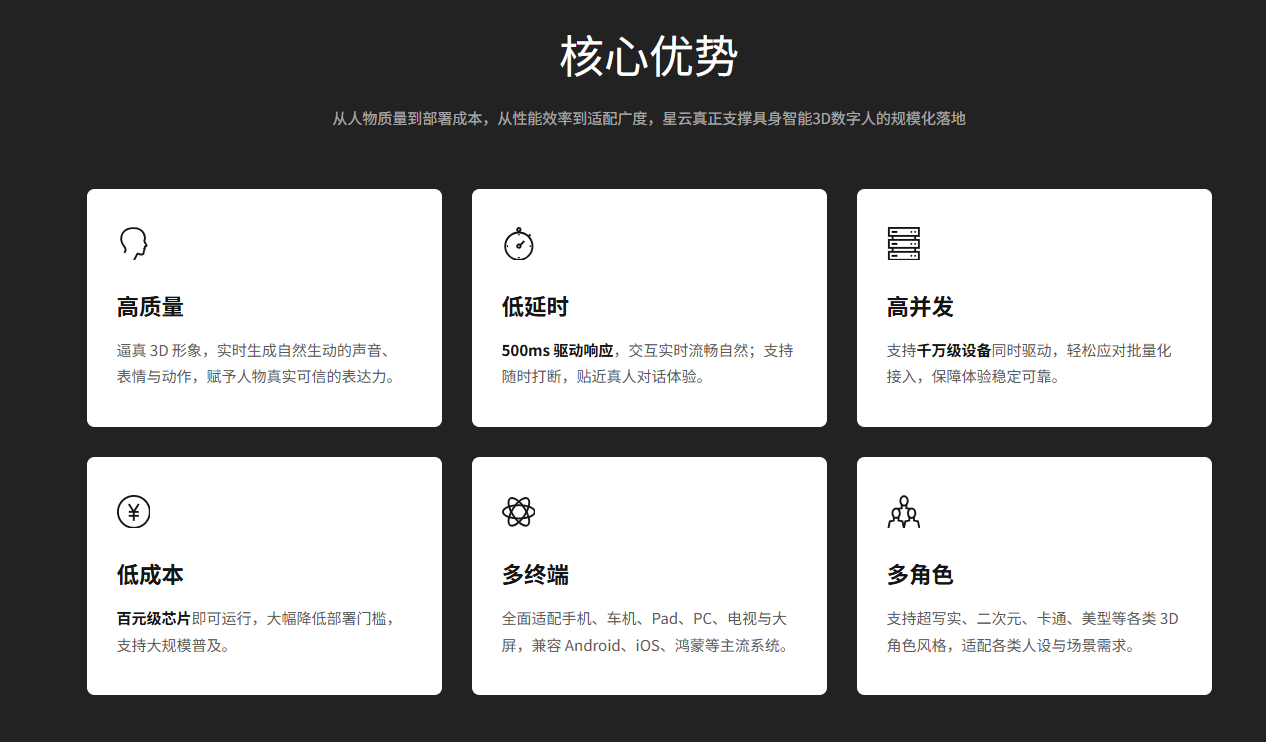
低成本运营——创业公司也用得起
相比传统方案需要5到10万元的3D建模费用、3到5人3个月的开发成本(10到20万人力)以及每月1到3万元的服务器费用,魔珐星云的成本结构完全不同。开发仅需一个前端工程师花一周时间,使用按量计费的模式使小流量项目几乎零成本,云端托管则完全消除了服务器购置成本。对初创项目而言,首月可能仅需投入几百元,真正实现了按需付费。
多终端支持——一次开发,到处运行
魔珐星云提供统一的API接口,支持Web、iOS、Android、Unity和Unreal Engine等多个平台,开发者无需为每个平台单独开发。系统根据设备性能自动调整渲染质量,代码复用率可以超过90%。这意味着在Web上调试完成后,迁移到小程序或App仅需修改少量配置。
信创支持——满足合规需求
魔珐星云专门提供国产化部署方案,支持私有化部署在飞腾、鲲鹏等国产CPU和麒麟、统信等国产操作系统上。平台通过了等保三级和商密认证,让数字人技术不仅服务于互联网应用,也能满足政府、金融和教育等对合规性有严格要求的行业需求。
实战应用:打造虚拟情绪疗愈伙伴「沐木」
现在,让我们进入实操环节。接下来的内容将展示如何利用魔珐星云的完整技术栈,一步步搭建「沐木」这样一个具有情感交互能力的虚拟伙伴,将上述六大优势转化为实际的产品价值。
云端创建数字人
步骤 1:登录魔珐星云官方平台
访问 魔珐星云官网
步骤 2:创建应用
应用配置:
- 应用类型:具身驱动应用
- 应用名称:沐木
- 角色形象:从模板库选一个温柔的年轻女性形象
- 音色:少女音-温柔系
- 表演风格:自然/活泼/治愈
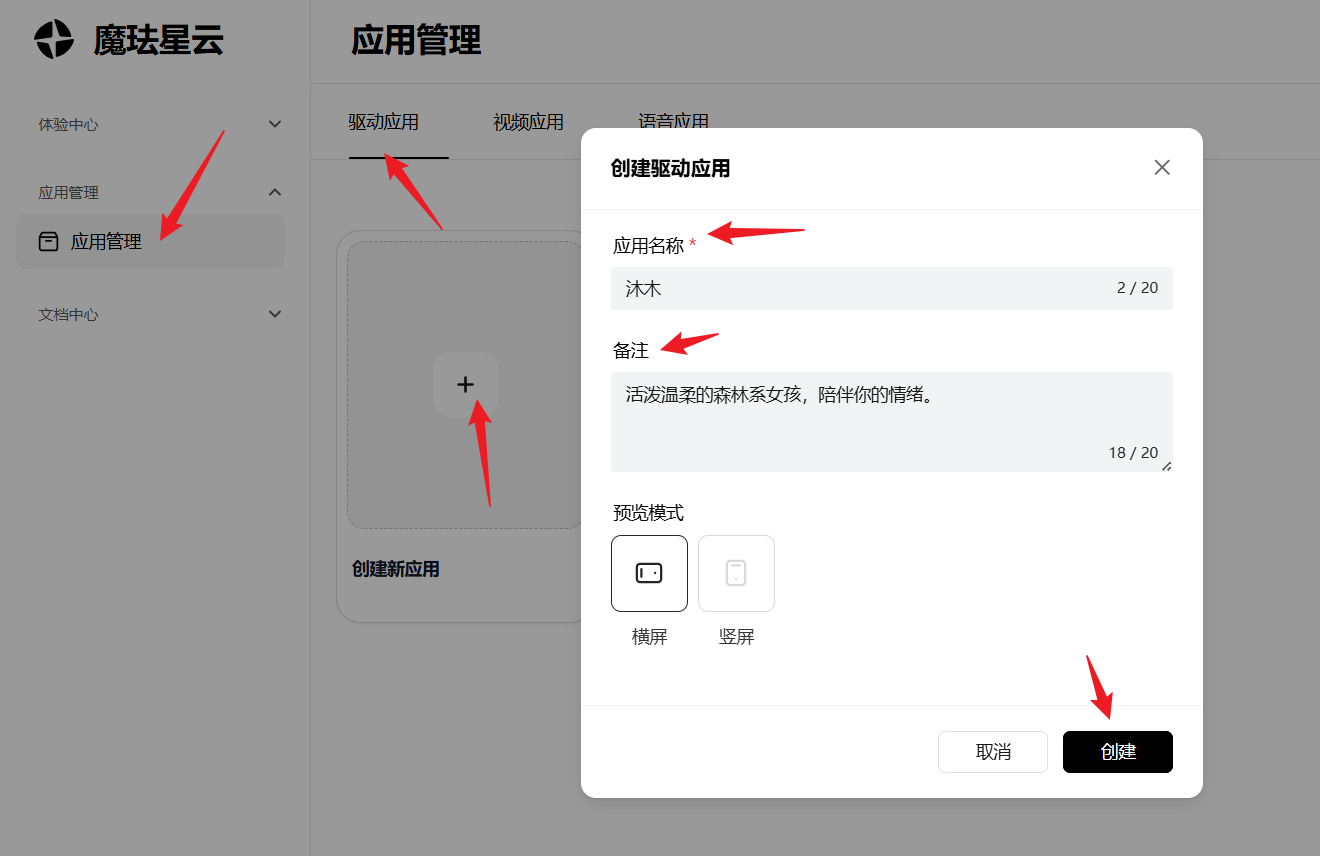
步骤 3:调试预览
在调试中可以设置画面分辨率、帧率、KA 自动触发、驱动指令、开场白,点击发送,即可查看效果。
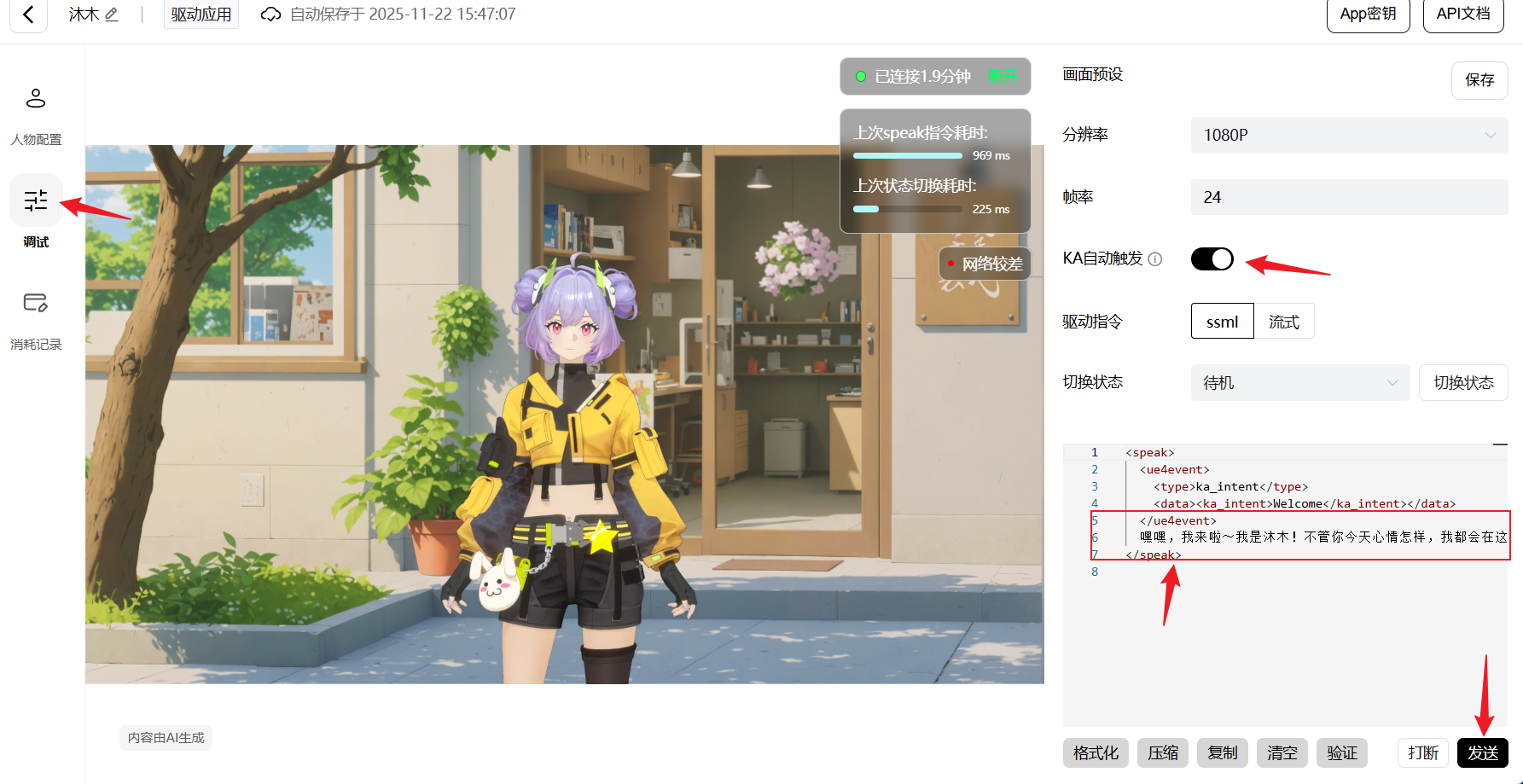
满意后点击保存,系统会生成:
- App ID(应用标识)
- App Secret(密钥)
- Server URL(服务地址)
这三个参数是前端接入的钥匙。到这一步为止,沐木已经在云端创建好了,接下来就是"把她接到你的页面里"。
技术选型与架构设计
技术选型
我选择了 Vue 3 + TypeScript + Vite 的技术栈,原因很简单:
- Vue 3:组合式 API 适合管理复杂状态
- TypeScript:提供类型安全
- Vite:开发体验丝滑
架构分层设计
src/
├── main.ts # 应用入口,SDK初始化
├── components/ # UI组件层
│ ├── AvatarRender.vue # 虚拟人渲染容器
│ └── ConfigPanel.vue # 配置面板
├── services/ # 业务逻辑层
│ ├── avatar.ts # 虚拟人连接与控制
│ └── llm.ts # LLM交互
├── composables/ # 组合式功能
│ └── useAsr.ts # 语音识别hooks
├── stores/ # 应用状态
│ └── app.ts # 集中式状态管理
├── utils/ # 工具函数
│ ├── sdk-loader.ts # SDK动态加载
│ └── index.ts # 通用工具
├── lib/ # 第三方库封装
│ └── asr.ts # ASR签名生成
├── constants/ # 配置常量
├── types/ # 类型定义
└── style.css # 全局样式
应用启动与 SDK 加载
入口初始化流程
应用启动时面临的第一个挑战是加载三个异构 SDK:CryptoJS(用于腾讯云签名)、WebAudioSpeechRecognizer(语音识别)、XmovAvatar(虚拟人渲染)。这些 SDK 来自不同厂商,加载方式和初始化流程各不相同。
// src/main.ts
import { createApp } from 'vue'
import App from './App.vue'
import { initSDKs, checkSDKStatus } from './utils/sdk-loader'
async function initApp() {
console.log('应用初始化开始...')
// 关键步骤1:初始化所有SDK
const sdkLoaded = await initSDKs()
if (sdkLoaded) {
console.log('✓ SDK加载成功')
checkSDKStatus()
} else {
console.error('✗ SDK加载失败,应用可能无法正常工作')
}
// 关键步骤2:挂载Vue应用
const app = createApp(App)
app.mount('#app')
}
initApp().catch(error => {
console.error('应用初始化异常:', error)
})
这里的初始化采用先 SDK 后应用的策略,确保在 Vue 应用挂载时,所有全局 SDK 已经就绪。
SDK 动态加载与轮询检测
SDK 加载的核心挑战是处理异步加载的不确定性。因为 SDK 来自 CDN,网络状况可能导致加载延迟或失败。我们采用了"加载 + 轮询 + 超时"的组合方案:
// src/utils/sdk-loader.ts
export function checkSDKStatus() {
const status = {
cryptoJS: !!window.CryptoJSTest,
speechRecognizer: !!window.WebAudioSpeechRecognizer,
xmovAvatar: !!window.XmovAvatar
}
console.log('SDK加载状态检查:', status)
return status
}
export function waitForSDK(
sdkName: keyof ReturnType<typeof checkSDKStatus>,
timeout = 10000
): Promise<boolean> {
return new Promise((resolve) => {
const startTime = Date.now()
const check = () => {
const status = checkSDKStatus()
// 检查到SDK已加载
if (status[sdkName]) {
resolve(true)
return
}
// 检查超时
if (Date.now() - startTime > timeout) {
console.error(`${sdkName} SDK加载超时(${timeout}ms)`)
resolve(false)
return
}
// 继续轮询
setTimeout(check, 100)
}
check()
})
}
export function loadSDK(src: string): Promise<void> {
return new Promise((resolve, reject) => {
// 避免重复加载
const existingScript = document.querySelector(`script[src="${src}"]`)
if (existingScript) {
resolve()
return
}
const script = document.createElement('script')
script.src = src
script.onload = () => {
console.log(`✓ ${src} 加载成功`)
resolve()
}
script.onerror = () => {
console.error(`✗ ${src} 加载失败`)
reject(new Error(`Failed to load script: ${src}`))
}
document.head.appendChild(script)
})
}
关键点分析:
- 轮询策略:每 100ms 检查一次 SDK 是否挂载到 window 上,相比回调方式更稳定
- 超时保护:设置 10 秒超时,防止长时间等待
- 错误降级:SDK 加载失败时不中断应用,而是记录日志并继续运行(某些功能会不可用)
第三方 SDK 的兼容性处理
腾讯云 ASR SDK 期望 CryptoJS 挂载在 window.CryptoJS,但某些 CDN 场景可能会有命名冲突。我们采用了命名映射的方案,避免了全局命名空间污染,同时保证了腾讯云 ASR SDK 能找到加密库。
export async function initSDKs() {
try {
// 并行加载三个SDK
await Promise.all([
loadSDK('/cryptojs.js').catch(() => {
console.warn('本地cryptojs.js加载失败,尝试CDN')
return loadSDK(
'https://cdnjs.cloudflare.com/ajax/libs/crypto-js/4.1.1/crypto-js.min.js'
)
}),
loadSDK('/speechrecognizer.js'),
loadSDK(
'https://media.xingyun3d.com/xingyun3d/general/litesdk/xmovAvatar.0.1.0-alpha.63.js'
)
])
// 等待所有SDK初始化完成
await Promise.all([
waitForSDK('cryptoJS'),
waitForSDK('speechRecognizer'),
waitForSDK('xmovAvatar')
])
console.log('✓ 所有SDK加载完成')
return true
} catch (error) {
console.error('SDK加载失败:', error)
return false
} finally {
// 兼容性处理:将CryptoJS映射为CryptoJSTest
if (!window.CryptoJSTest && window.CryptoJS) {
window.CryptoJSTest = window.CryptoJS
console.log('✓ CryptoJS兼容性映射完成')
}
}
}
虚拟人连接与渲染
运行效果
运行 pnpm install 安装依赖。
然后 pnpm run dev 启动开发服务器。
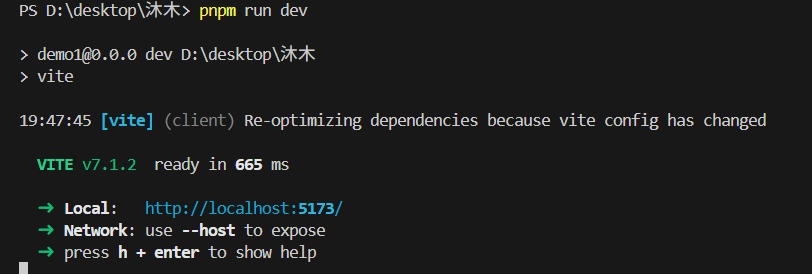
访问 http://localhost:5173/ 就能看到一个基础的数字人页面。
接入魔珐 SDK
这是最核心的一步,也是最简单的一步。
在项目里引入魔珐的 SDK 文件,然后初始化:
- 指定渲染容器(页面上的哪个区域显示数字人)
- 填入 App ID 和 App Secret
- 调用连接方法
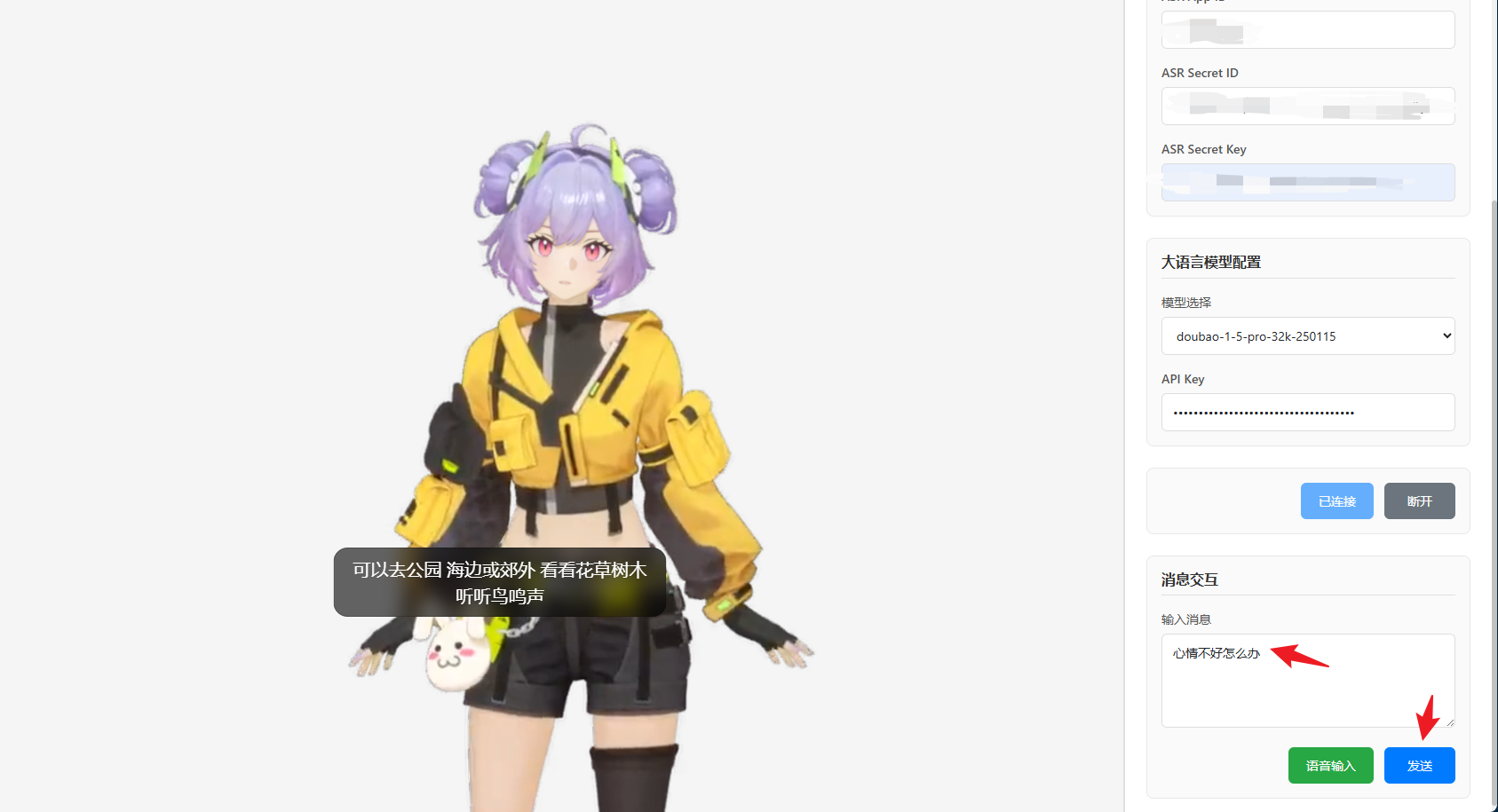
连接成功后,沐木就出现在页面上了,还会自动播放开场白:“嘿嘿,我来啦~”。此时你已经拥有了一个能说话、能做表情、能动的数字人。

容器管理与生命周期
虚拟人渲染前,需要在 DOM 中预留容器。XmovAvatar SDK 会在该容器内创建 Canvas 元素并渲染数字人。关键是容器 ID 的生成和跟踪。通过时间戳 + 随机字符串组合,确保容器 ID 全局唯一,同时便于调试。
// src/services/avatar.ts
let containerId: string = ''
function generateContainerId(): string {
const id = `avatar-${Date.now()}-${Math.random().toString(36).substr(2, 9)}`
containerId = id
return id
}
export function getContainerId(): string {
return containerId
}
连接流程详解
虚拟人连接是应用中最复杂的异步操作。它涉及 SDK 初始化、网络通信、资源下载、渲染启动等多个阶段:
// src/services/avatar.ts
async connect(config: AvatarConfig, callbacks: AvatarCallbacks): Promise<any> {
const { appId, appSecret } = config
const { onSubtitleOn, onSubtitleOff, onStateChange } = callbacks
// 第一步:构造网关URL
// 网关地址包含了服务端场景配置,决定了数字人是否有背景、是否有特定动作等
const url = new URL(SDK_CONFIG.GATEWAY_URL)
url.searchParams.append('data_source', SDK_CONFIG.DATA_SOURCE)
url.searchParams.append('custom_id', SDK_CONFIG.CUSTOM_ID)
// 第二步:创建Promise,用于追踪连接状态
let resolve: (value: boolean) => void
let reject: (reason?: any) => void
const connectPromise = new Promise<boolean>((res, rej) => {
resolve = res
reject = rej
})
// 第三步:配置SDK选项
// 这些选项是XmovAvatar SDK的核心配置
const constructorOptions = {
// 渲染容器
containerId: `#${this.containerId}`,
// 认证信息
appId,
appSecret,
enableDebugger: false,
gatewayServer: url.toString(),
// 事件回调
onWidgetEvent: (event: any) => {
console.log('【SDK事件】', event.type, event)
// 字幕事件:数字人说话时触发
if (event.type === 'subtitle_on') {
onSubtitleOn(event.text)
} else if (event.type === 'subtitle_off') {
onSubtitleOff()
}
},
// 状态变化回调
// 例如:'idle' -> 'speaking' -> 'thinking' -> 'idle'
onStateChange,
// 错误回调
onMessage: async (error: any) => {
const state = await getPromiseState(connectPromise)
const plainError = new Error(error.message)
// 只在连接未完成时才抛错
if (state === 'pending') {
reject(plainError)
}
}
}
// 第四步:实例化SDK
const avatar = new window.XmovAvatar(constructorOptions)
// 第五步:等待SDK初始化
// 初始化涉及下载资源文件(模型、动作、音频等),可能需要几秒
// 为了避免promise race condition,我们设置一个合理的初始化超时
await new Promise(resolve => {
setTimeout(resolve, APP_CONFIG.AVATAR_INIT_TIMEOUT)
})
// 第六步:调用init方法,开始下载资源
await avatar.init({
onDownloadProgress: (progress: number) => {
console.log(`资源下载进度: ${progress}%`)
// 资源下载完成,连接可以建立
if (progress >= 100) {
resolve(true)
}
},
onClose: () => {
onStateChange('')
console.log('【连接关闭】SDK连接已断开')
}
})
// 第七步:等待连接完成
// 使用allSettled而不是all,因为我们要设置超时
const [result] = await Promise.allSettled([
connectPromise,
new Promise(resolve => setTimeout(resolve, 1000))
])
// 连接失败时抛错
if (result.status === 'rejected') {
console.error('【连接失败】', result.reason)
throw result.reason
}
// 第八步:视频自动播放处理
// Chrome等浏览器默认禁止自动播放,需要用户交互触发
try {
const containerSelector = `#${this.containerId}`
const videoEl = document.querySelector(
`${containerSelector} video`
) as HTMLVideoElement | null
if (videoEl) {
videoEl.muted = true
await videoEl.play().catch(() => {})
// 如果播放失败,绑定点击事件作为后备方案
if (videoEl.paused) {
const container = document.querySelector(containerSelector)
container?.addEventListener(
'click',
() => {
videoEl.play().catch(() => {})
},
{ once: true }
)
}
}
} catch {}
return avatar
}
连接流程中的关键点:
- Promise 追踪:通过
connectPromise追踪连接状态,避免多次回调冲突 - 资源下载:数字人的模型、动作库、音色等资源都需要下载,进度回调让我们能实时展示加载状态
- 自动播放处理:现代浏览器限制了无声视频的自动播放,我们通过
muted属性和点击事件来绕过这个限制 - 错误隔离:在连接完成后发生的错误不会中断应用,而只是记录日志
渲染容器与 UI 叠加
虚拟人渲染容器和 UI 元素的关系如下:
<!-- src/components/AvatarRender.vue -->
<template>
<div class="avatar-container">
<!-- 虚拟人Canvas容器,由SDK自动创建Canvas -->
<div :id="containerId" class="avatar-render-area"></div>
<!-- 字幕UI,覆盖在虚拟人上方 -->
<div class="avatar-subtitle" v-if="appState.ui.subTitleText">
{{ appState.ui.subTitleText }}
</div>
<!-- 连接中的遮罩层 -->
<div v-if="!appState.avatar.connected" class="avatar-mask">
<div class="mask-content">
<div class="spinner"></div>
<p>正在连接虚拟人...</p>
</div>
</div>
</div>
</template>
<script setup lang="ts">
import { inject, computed } from 'vue'
import { avatarService } from '../services/avatar'
import type { AppState } from '../types'
const appState = inject<AppState>('appState')!
const containerId = computed(() => avatarService.getContainerId())
</script>
<style scoped>
.avatar-container {
position: relative;
width: 100%;
height: 600px;
background: linear-gradient(135deg, #667eea 0%, #764ba2 100%);
border-radius: 12px;
overflow: hidden;
}
.avatar-render-area {
width: 100%;
height: 100%;
}
/* 字幕UI绝对定位,显示虚拟人的语音内容 */
.avatar-subtitle {
position: absolute;
bottom: 30px;
left: 50%;
transform: translateX(-50%);
background: rgba(0, 0, 0, 0.7);
color: white;
padding: 12px 24px;
border-radius: 24px;
max-width: 80%;
text-align: center;
font-size: 14px;
line-height: 1.5;
z-index: 10;
}
/* 连接中的遮罩层 */
.avatar-mask {
position: absolute;
inset: 0;
display: flex;
align-items: center;
justify-content: center;
background: rgba(0, 0, 0, 0.5);
z-index: 100;
}
.mask-content {
text-align: center;
color: white;
}
.spinner {
width: 40px;
height: 40px;
border: 4px solid rgba(255, 255, 255, 0.3);
border-top-color: white;
border-radius: 50%;
animation: spin 1s linear infinite;
margin: 0 auto 16px;
}
@keyframes spin {
to { transform: rotate(360deg); }
}
</style>
虚拟人的渲染采用了分层设计:底层是 Canvas 元素,中层是字幕气泡,上层是连接状态遮罩。这样的设计既能展示虚拟人的实时动画,又能清晰显示交互反馈。
接入语音识别(ASR)
腾讯云 ASR 的工作原理
要让沐木"听懂"用户说的话,需要集成语音识别服务。我选择了腾讯云 ASR。
腾讯云 WebAudioSpeechRecognizer 是一个浏览器语音识别 SDK,它的核心特点是流式识别——边说边转写,而不是等用户说完再识别。这对于实时对话应用至关重要。
工作流程如下:
用户说话 → 浏览器捕获音频 → 实时上传到腾讯云
↓
腾讯云处理音频流 → 边处理边返回识别结果 → 浏览器展示中间结果
↓
用户停止说话 → 腾讯云返回最终结果
在腾讯云控制台创建 ASR 应用
访问腾讯云控制台创建 ASR 应用,获取密钥,然后在项目里集成 WebSocket 实时识别:
- 用户点击"语音输入"按钮
- 浏览器请求麦克风权限
- 开始录音,实时传输音频流给 ASR
- ASR 边听边转写,文字实时显示在输入框
- 用户松开按钮,完整文本发送给后台
关键点:要用 WebSocket 流式识别,不要用录完再上传的方式,后者延迟太高。
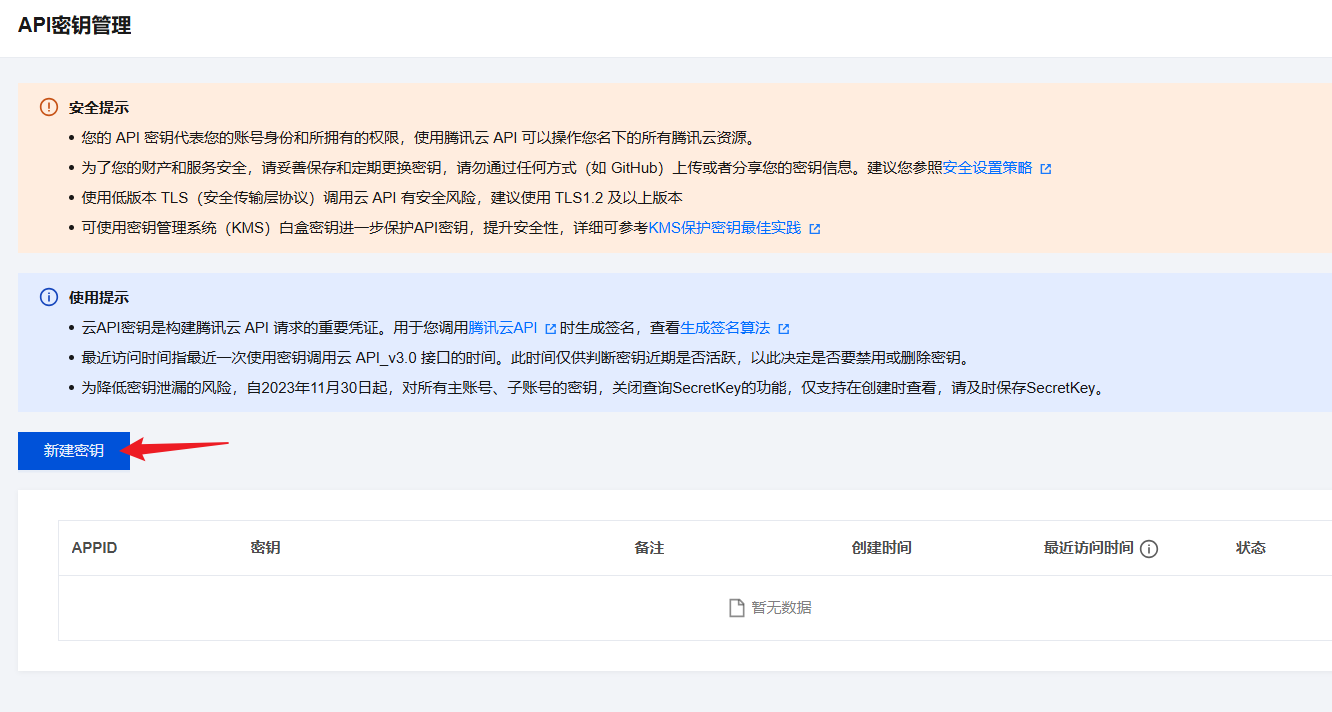
点击新建密钥,获取 ASR App ID、ASR Secret ID、ASR Secret Key。
ASR 的组合式封装
我们将 ASR 的初始化、事件监听、生命周期管理封装成一个 Vue composable,这样任何组件都能轻松使用:
// src/composables/useAsr.ts
import { ref } from 'vue'
import type { AsrConfig, AsrCallbacks } from '../types'
import { ASR_CONFIG } from '../constants'
import { signCallback } from '../lib/asr'
export function useAsr(config: AsrConfig) {
const asrText = ref('') // 当前识别的文本
const isListening = ref(false) // 是否正在监听
let webAudioSpeechRecognizer: any = null
// 根据配置构建ASR参数
const buildAsrConfig = (vadSilenceTime?: number) => ({
// 签名回调:腾讯云要求请求签名,用于权限验证
signCallback: signCallback.bind(null, config.secretKey),
// 认证信息
appid: config.appId,
secretid: config.secretId,
secretkey: config.secretKey,
// 识别引擎配置
engine_model_type: ASR_CONFIG.ENGINE_MODEL_TYPE, // 16k通用版本
voice_format: ASR_CONFIG.VOICE_FORMAT, // PCM格式
// 文本过滤配置
filter_dirty: ASR_CONFIG.FILTER_DIRTY, // 过滤脏话
filter_modal: ASR_CONFIG.FILTER_MODAL, // 过滤语气词
filter_punc: ASR_CONFIG.FILTER_PUNC, // 过滤标点符号
convert_num_mode: ASR_CONFIG.CONVERT_NUM_MODE, // 数字转写
word_info: ASR_CONFIG.WORD_INFO, // 词信息输出
// VAD(Voice Activity Detection)配置
// VAD用于检测语音活动,自动判断用户是否说完
needvad: ASR_CONFIG.NEEDVAD,
vad_silence_time: vadSilenceTime || config.vadSilenceTime || 300 // 300ms无声则认为说完
})
// 开始识别
const start = (callbacks: AsrCallbacks, vadSilenceTime?: number) => {
if (isListening.value) {
console.warn('语音识别已在进行中')
return
}
// 检查SDK是否加载
if (!window.WebAudioSpeechRecognizer) {
console.error('WebAudioSpeechRecognizer 未加载')
callbacks.onError('WebAudioSpeechRecognizer 未加载')
return
}
// 检查配置完整性
if (!config.appId || !config.secretId || !config.secretKey) {
console.error('ASR配置不完整')
callbacks.onError('ASR配置不完整,请检查App ID、Secret ID和Secret Key')
return
}
const asrConfig = buildAsrConfig(vadSilenceTime)
console.log('【ASR配置】', asrConfig)
try {
// 创建识别器实例
webAudioSpeechRecognizer = new window.WebAudioSpeechRecognizer(asrConfig)
// 绑定事件监听
setupEventListeners(callbacks)
// 开始录音并识别
webAudioSpeechRecognizer.start()
isListening.value = true
console.log('【ASR】开始语音识别')
} catch (error) {
console.error('创建WebAudioSpeechRecognizer失败:', error)
callbacks.onError(error)
}
}
// 停止识别
const stop = () => {
if (webAudioSpeechRecognizer) {
webAudioSpeechRecognizer.stop()
webAudioSpeechRecognizer = null
}
isListening.value = false
console.log('【ASR】停止语音识别')
}
// 事件监听器设置
const setupEventListeners = (callbacks: AsrCallbacks) => {
// 识别开始事件
webAudioSpeechRecognizer.OnRecognitionStart = (res: any) => {
console.log('【ASR事件】识别开始:', res)
}
// 句子开始事件(VAD检测到语音)
webAudioSpeechRecognizer.OnSentenceBegin = (res: any) => {
console.log('【ASR事件】句子开始:', res)
asrText.value = '' // 清空之前的识别结果
}
// 识别结果变化事件(实时返回中间结果)
webAudioSpeechRecognizer.OnRecognitionResultChange = (res: any) => {
const currentText = res.result?.voice_text_str
if (currentText) {
asrText.value = currentText
console.log('【ASR事件】识别中:', currentText)
}
}
// 句子结束事件(VAD检测到用户停止说话)
webAudioSpeechRecognizer.OnSentenceEnd = (res: any) => {
const resultText = res.result?.voice_text_str
console.log('【ASR事件】句子结束:', resultText)
if (resultText) {
asrText.value = resultText
// 将识别结果传回给调用者
callbacks.onFinished(resultText)
}
}
// 识别完成事件
webAudioSpeechRecognizer.OnRecognitionComplete = (res: any) => {
console.log('【ASR事件】识别完成:', res)
isListening.value = false
}
// 错误事件
webAudioSpeechRecognizer.OnError = (res: any) => {
console.error('【ASR错误】', res)
callbacks.onError(res)
isListening.value = false
}
}
return {
asrText,
isListening,
start,
stop
}
}
腾讯云签名的生成
腾讯云 API 要求使用 HMAC-SHA1 算法对请求进行签名,以验证请求的合法性。这需要用到 CryptoJS 库。HMAC-SHA1 是一种基于密钥的哈希算法。腾讯云会在服务端使用相同的密钥验证签名,确保请求来自合法的应用。
// src/lib/asr.ts
/**
* 将CryptoJS的WordArray转换为Uint8Array
* CryptoJS内部使用WordArray格式存储数据,需要转换为浏览器原生的Uint8Array
*/
function toUint8Array(wordArray: any) {
const words = wordArray.words // 32位整数数组
const sigBytes = wordArray.sigBytes // 有效字节数
const u8 = new Uint8Array(sigBytes)
for (let i = 0; i < sigBytes; i++) {
// 每个32位整数包含4个字节,按大端序提取
u8[i] = (words[i >>> 2] >>> (24 - (i % 4) * 8)) & 0xff
}
return u8
}
/**
* 将Uint8Array转换为字符串
* 用于后续Base64编码
*/
function Uint8ArrayToString(fileData: Uint8Array) {
let dataString = ''
for (let i = 0; i < fileData.length; i++) {
dataString += String.fromCharCode(fileData[i])
}
return dataString
}
/**
* 生成腾讯云ASR请求签名
* @param secretKey 密钥
* @param signStr 待签名字符串
* @returns Base64编码的签名
*/
export function signCallback(secretKey: string, signStr: string) {
if (!window.CryptoJSTest) {
console.error('CryptoJS 未加载')
throw new Error('CryptoJS 未加载')
}
try {
// 使用HMAC-SHA1算法生成签名
const hash = window.CryptoJSTest.HmacSHA1(signStr, secretKey)
// 转换为字节数组
const bytes = Uint8ArrayToString(toUint8Array(hash))
// Base64编码
return window.btoa(bytes)
} catch (error) {
console.error('签名生成失败:', error)
throw error
}
}
组件中的 ASR 集成
在配置面板中,我们实际调用 ASR 的 start 方法:
// src/components/ConfigPanel.vue
import { useAsr } from '../composables/useAsr'
const asrConfig = computed(() => ({
provider: 'tx' as const,
appId: appState.asr.appId,
secretId: appState.asr.secretId,
secretKey: appState.asr.secretKey
}))
function handleVoiceInput() {
// 如果正在监听,则停止
if (appState.asr.isListening) {
stopAsr()
appStore.stopVoiceInput()
return
}
// 检查ASR配置
const { appId, secretId, secretKey } = appState.asr
if (!appId || !secretId || !secretKey) {
alert('请先配置ASR信息')
return
}
// 创建ASR实例并开始识别
const { start: startAsrWithConfig } = useAsr(asrConfig.value)
appStore.startVoiceInput({
onFinished: (text: string) => {
appState.ui.text = text // 将识别结果填入输入框
appStore.stopVoiceInput()
},
onError: (error: any) => {
console.error('语音识别错误:', error)
appStore.stopVoiceInput()
}
})
startAsrWithConfig({
onFinished: (text: string) => {
appState.ui.text = text
appStore.stopVoiceInput()
},
onError: (error: any) => {
console.error('语音识别错误:', error)
appStore.stopVoiceInput()
}
})
}
接入大语言模型(LLM)
火山引擎豆包配置
数字人的"大脑"来自大语言模型。我用的是火山引擎方舟平台的豆包模型。
访问火山引擎方舟平台,登录后,点击 API 接入。
创建 API Key 后,点击 开通模型。
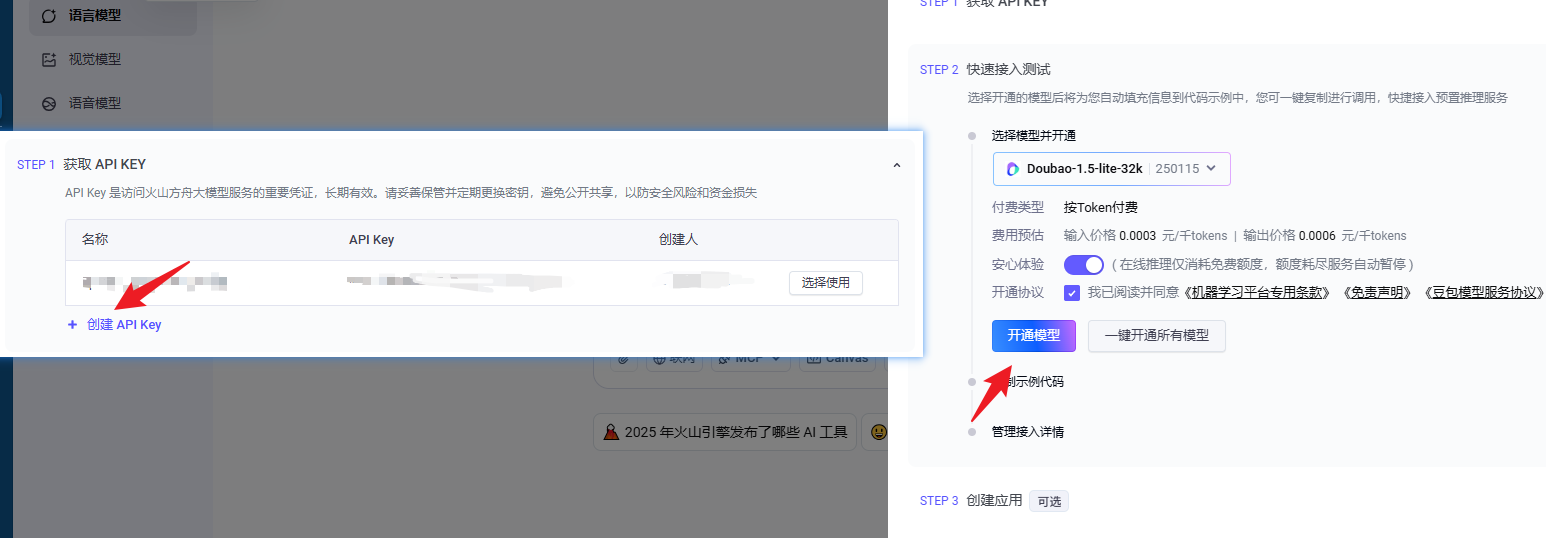
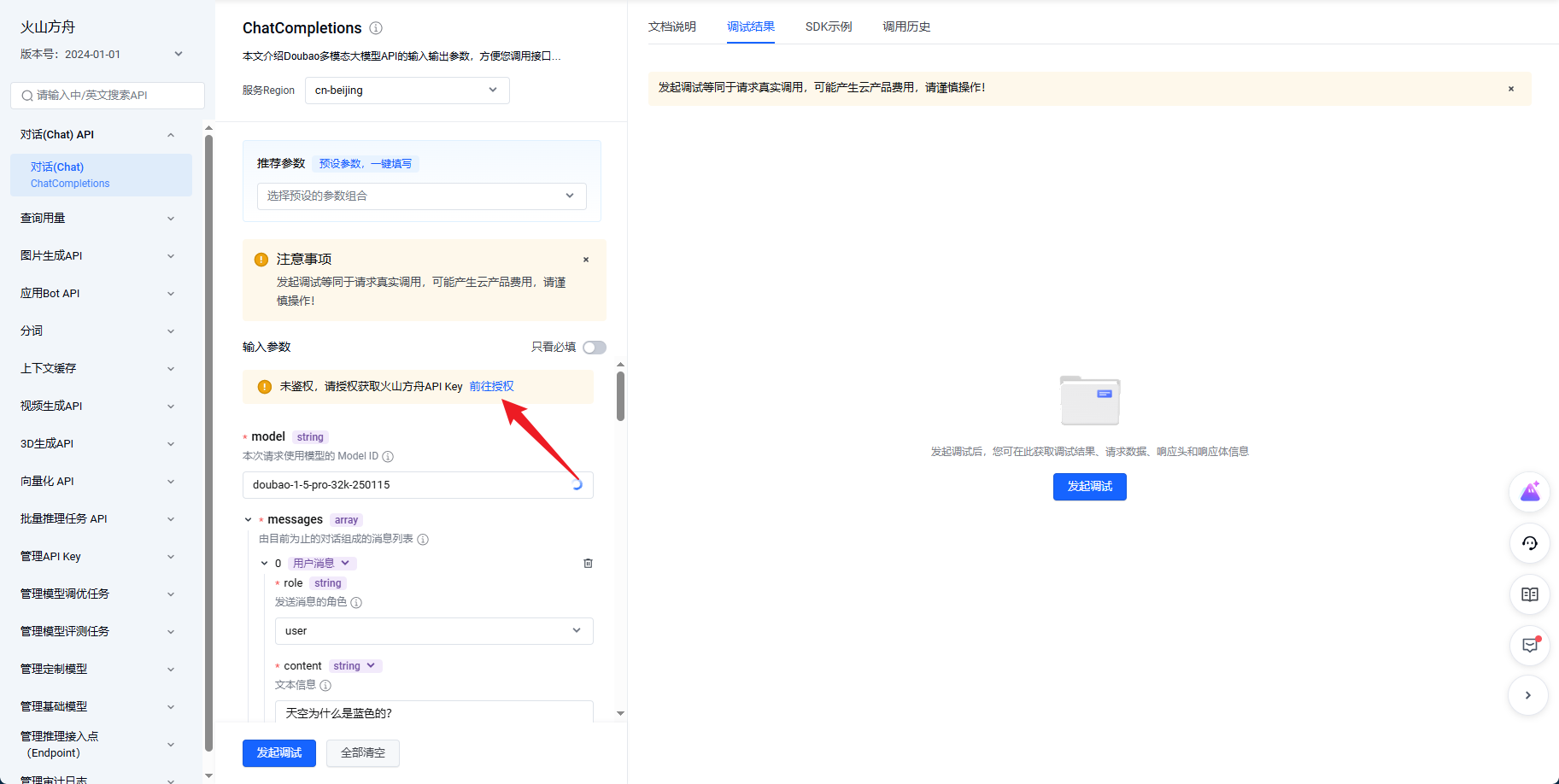
访问 API Key测试网站,查看是否成功开通,点击授权刚创建的 API Key。
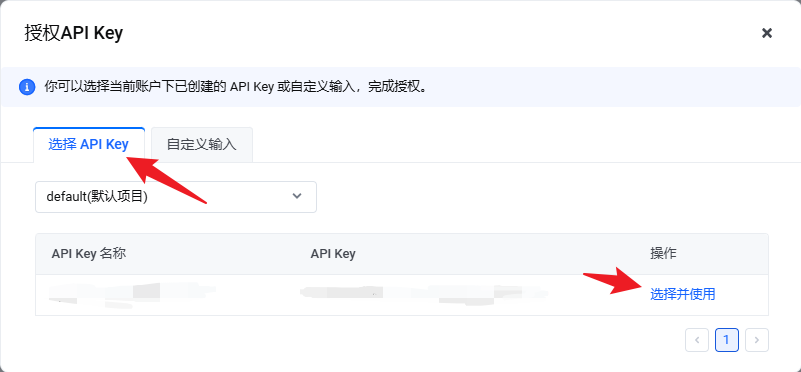
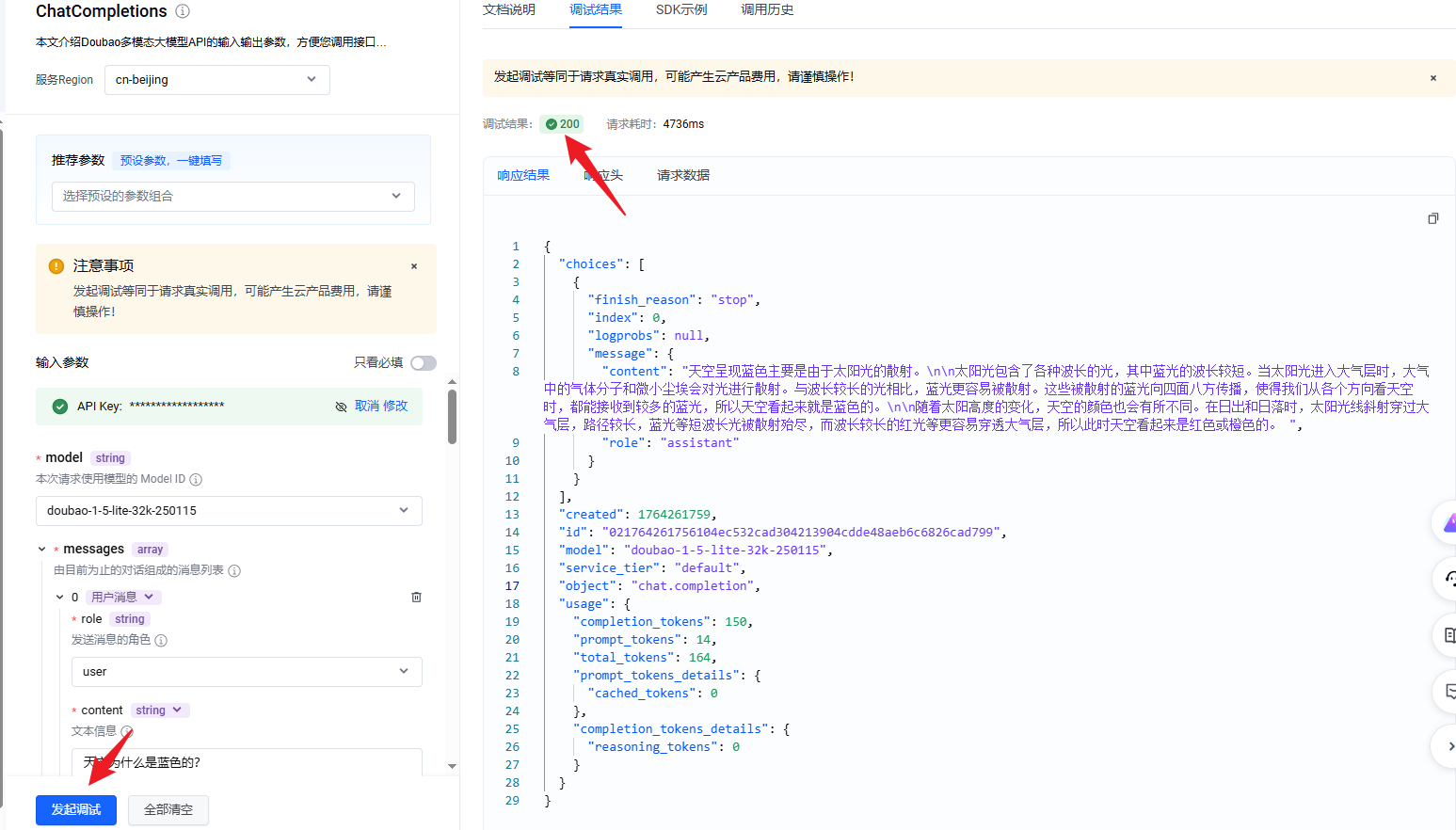
点击发起调试,调试结果为 200 则连接成功。
LLM 服务的设计
虚拟人的"大脑"来自大语言模型。我们选择了 OpenAI 兼容接口,这样既能使用 OpenAI 的 GPT 系列,也能使用火山引擎豆包等兼容实现。相比传统的一次性 API,流式 API 能逐字返回结果。这让我们能在 LLM 还在思考时就开始播放虚拟人的语音,大幅降低了用户感知的延迟。
// src/services/llm.ts
import type { LLMConfig } from '../types'
import { LLM_CONFIG } from '../constants'
class LLMService {
private client: any = null
/**
* 惰性创建OpenAI客户端
* 只在第一次调用LLM方法时才创建,避免不必要的初始化
*/
private getClient(config: LLMConfig) {
if (!this.client) {
const { OpenAI } = window
if (!OpenAI) {
throw new Error('OpenAI SDK未加载')
}
this.client = new OpenAI({
apiKey: config.apiKey,
// 豆包方舟默认接入点
baseURL: 'https://ark.cn-beijing.volces.com/api/v3',
dangerouslyAllowBrowser: true
})
}
return this.client
}
/**
* 发送单次消息并获取完整回复
* 适用于简单的问答场景
*/
async sendMessage(config: LLMConfig, userMessage: string): Promise<string> {
try {
const client = this.getClient(config)
const response = await client.chat.completions.create({
model: config.model,
messages: [
{
role: 'system',
content: LLM_CONFIG.SYSTEM_PROMPT
},
{
role: 'user',
content: userMessage
}
],
temperature: 0.7,
top_p: 0.95,
max_tokens: 1000
})
return response.choices[0].message.content
} catch (error) {
console.error('LLM请求失败:', error)
throw error
}
}
/**
* 发送消息并获取流式回复
* 返回异步迭代器,可以逐块获取响应
* 这对于实时对话和显示实时动画至关重要
*/
async sendMessageWithStream(
config: LLMConfig,
userMessage: string
): Promise<AsyncIterable<string>> {
try {
const client = this.getClient(config)
const stream = await client.chat.completions.create({
model: config.model,
messages: [
{
role: 'system',
content: LLM_CONFIG.SYSTEM_PROMPT
},
{
role: 'user',
content: userMessage
}
],
temperature: 0.7,
top_p: 0.95,
max_tokens: 1000,
stream: true // 启用流式模式
})
// 将SDK的流转换为自定义的异步迭代器
return (async function* () {
for await (const chunk of stream) {
const content = chunk.choices[0]?.delta?.content || ''
if (content) {
yield content
}
}
})()
} catch (error) {
console.error('LLM流式请求失败:', error)
throw error
}
}
}
export const llmService = new LLMService()
打通完整链路
分句算法的设计
虚拟人播报文本时需要分句,否则会一次性播放很长的文本,显得生硬。分句算法需要遵循以下原则:
// src/stores/app.ts - 分句算法
const MIN_SPLIT_LENGTH = 2 // 最少2个字符才分句
const MAX_SPLIT_LENGTH = 20 // 最多20个字符
function splitSentence(text: string): string[] {
if (!text) return []
const chinesePunctuations = new Set(['、', ',', ':', ';', '。', '?', '!', '…', '\n'])
const englishPunctuations = new Set([',', ':', ';', '.', '?', '!'])
let count = 0 // 字符计数
let firstValidPunctAfterMin = -1 // 第一个有效标点位置
let forceBreakIndex = -1 // 强制分句位置
let i = 0
const n = text.length
while (i < n && count < MAX_SPLIT_LENGTH) {
const char = text[i]
// 中文字符或数字,计数+1
if ((char >= '\u4e00' && char <= '\u9fff') || (char >= '0' && char <= '9')) {
count++
if (count === MAX_SPLIT_LENGTH) {
forceBreakIndex = i + 1
}
i++
}
// 英文单词
else if ((char >= 'a' && char <= 'z') || (char >= 'A' && char <= 'Z')) {
i++
// 跳过整个单词
while (
i < n &&
((text[i] >= 'a' && text[i] <= 'z') || (text[i] >= 'A' && text[i] <= 'Z'))
) {
i++
}
count++
if (count === MAX_SPLIT_LENGTH) {
forceBreakIndex = i
}
}
// 标点符号
else {
// 中文标点
if (chinesePunctuations.has(char)) {
// 在达到最小长度后记录第一个标点位置
if (count >= MIN_SPLIT_LENGTH && firstValidPunctAfterMin === -1) {
firstValidPunctAfterMin = i
}
i++
}
// 英文标点(需要后跟空格才视为句尾)
else if (englishPunctuations.has(char)) {
if (i + 1 >= n || text[i + 1] === ' ') {
if (count >= MIN_SPLIT_LENGTH && firstValidPunctAfterMin === -1) {
firstValidPunctAfterMin = i
}
}
i++
} else {
i++
}
}
}
// 决定分句位置
let splitIndex = -1
if (firstValidPunctAfterMin !== -1) {
// 优先在标点位置分句
splitIndex = firstValidPunctAfterMin + 1
} else if (forceBreakIndex !== -1) {
// 字符超长时强制分句
splitIndex = forceBreakIndex
}
// 分句
if (splitIndex > 0 && splitIndex < text.length) {
return [text.substring(0, splitIndex), text.substring(splitIndex)]
}
return [text]
}
算法的核心逻辑:
- 优先级 1:在中文标点处分句(满足最小长度的前提下)
- 优先级 2:在英文标点处分句(标点后需有空格)
- 优先级 3:超过最大长度时,在字符/单词边界强制分句
这样既能保证句子的完整性,又能避免单次播放过长的文本。
SSML 文本生成
SSML(Speech Synthesis Markup Language)是用于控制语音合成的标记语言。我们通过 SSML 可以控制虚拟人的语速、音调、音量等:
// src/utils/index.ts
export function generateSSML(
text: string,
pitch?: number,
speed?: number,
volume?: number
): string {
// 组装SSML属性
let attributes = ''
if (pitch !== undefined) {
attributes += ` pitch="${pitch}%"`
}
if (speed !== undefined) {
attributes += ` rate="${speed}%"`
}
if (volume !== undefined) {
attributes += ` volume="${volume}%"`
}
return `<speak>${text}<prosody${attributes}>${text}</prosody></speak>`
}
完整的消息处理流程
最后,我们将 ASR、LLM、虚拟人播报串联起来,形成完整的对话流程:
// src/stores/app.ts
export class AppStore {
/**
* 发送消息并让虚拟人播报
* 这是应用的核心业务流程
*/
async sendMessage(): Promise<string | undefined> {
const { llm, ui, avatar } = appState
// 1. 参数校验
if (!validateConfig(llm, ['apiKey']) || !ui.text || !avatar.instance) {
return
}
try {
// 2. 等待虚拟人准备好
await this.waitForAvatarReady()
// 3. 调用LLM获取流式回复
const stream = await llmService.sendMessageWithStream(
{
provider: 'openai',
model: llm.model,
apiKey: llm.apiKey
},
ui.text
)
if (!stream) return
// 4. 缓冲区和播报控制
let buffer = '' // 累积文本缓冲区
let isFirstChunk = true // 是否第一句
for await (const chunk of stream) {
buffer += chunk
console.log('【LLM输出】', chunk)
// 5. 尝试分句
const arr = splitSentence(buffer)
// 分句成功,第一句可以播报
if (arr.length > 1) {
const ssml = generateSSML(arr[0] || '')
console.log('【播报】', arr[0])
// 使用SDK的speak方法播报
// 参数解释:
// - ssml: 待播报的SSML文本
// - true/false: 是否立即开始播报(打断之前的语音)
// - false: 是否最后一句
if (isFirstChunk) {
avatar.instance.speak(ssml, true, false)
isFirstChunk = false
} else {
avatar.instance.speak(ssml, false, false)
}
// 6. 保存剩余文本到缓冲区
buffer = arr[1] || ''
}
}
// 7. 处理剩余的文本
if (buffer.length > 0) {
const ssml = generateSSML(buffer)
if (isFirstChunk) {
avatar.instance.speak(ssml, true, false)
} else {
avatar.instance.speak(ssml, false, false)
}
}
// 8. 发送结束信号
const finalSsml = generateSSML('')
avatar.instance.speak(finalSsml, false, true)
return buffer
} catch (error) {
console.error('发送消息失败:', error)
throw error
}
}
/**
* 等待虚拟人准备好
* 如果虚拟人正在说话,则打断并等待
*/
private async waitForAvatarReady(): Promise<void> {
if (avatarState.value === 'speak') {
console.log('【控制】虚拟人正在说话,发送打断信号')
appState.avatar.instance.think()
await delay(APP_CONFIG.SPEAK_INTERRUPT_DELAY)
}
}
/**
* 启动语音输入
*/
startVoiceInput(callbacks: {
onFinished: (text: string) => void
onError: (error: any) => void
}): void {
appState.asr.isListening = true
console.log('【语音输入】已启动')
}
/**
* 停止语音输入
*/
stopVoiceInput(): void {
appState.asr.isListening = false
console.log('【语音输入】已停止')
}
}
export const appStore = new AppStore()
根据回复内容触发对应的表情动作
整个流程跑通后,你会发现:从用户说话到沐木回应,整个过程行云流水,没有明显的等待感。
最后把所有模块串起来:
用户文字输入/语音输入
→ ASR 转文字
→ 发送给 LLM
→ LLM 生成回复
→ 用 SSML 包装(控制语速、音调)
→ 发送给魔珐 SDK
→ 沐木开口说话
同时根据回复内容触发对应的表情动作:
- 如果回复里有"开心"、“哈哈”,触发开心表情
- 如果有"抱抱"、“没关系”,触发安慰动作
- 默认是温柔的倾听表情
这就是魔珐星云的魔力——技术细节被 SDK 优雅地封装了,开发者只需要关心业务逻辑和用户体验。

常量与配置管理
为了便于后续扩展和调整,我们将所有硬编码的值集中在常量文件中:
// src/constants/index.ts
// 应用级常量
export const APP_CONFIG = {
AVATAR_CONTAINER_PREFIX: 'avatar-',
AVATAR_INIT_TIMEOUT: 3000,
SPEAK_INTERRUPT_DELAY: 500
}
// LLM配置
export const LLM_CONFIG = {
DEFAULT_MODEL: 'doubao-pro-32k',
SYSTEM_PROMPT: `你是沐木,一个温柔、富有同情心的虚拟情绪疗愈伙伴。你的目标是:
1. 认真倾听用户的情感诉求
2. 给予温暖和理解
3. 提供建设性的建议
4. 用温柔、自然的语言交流
回复应该简洁(200字以内),避免生硬和冗长的建议。`,
SUPPORTED_MODELS: [
'doubao-pro-32k',
'gpt-4o',
'gpt-4-turbo',
'gpt-3.5-turbo'
]
}
// ASR配置
export const ASR_CONFIG = {
ENGINE_MODEL_TYPE: '16k_zh',
VOICE_FORMAT: 'wav',
FILTER_DIRTY: 1,
FILTER_MODAL: 0,
FILTER_PUNC: 0,
CONVERT_NUM_MODE: 1,
WORD_INFO: 0,
NEEDVAD: 1
}
// SDK网关配置(需要根据实际账号填写)
export const SDK_CONFIG = {
GATEWAY_URL: 'https://your-gateway-url.com',
DATA_SOURCE: 'scene_template_0001',
CUSTOM_ID: 'your_custom_id'
}
遇到的坑与解决方案
坑 1:浏览器禁止自动播放
现象:数字人出现了,但没有声音。
原因:Chrome 等浏览器默认禁止网页自动播放音频(防止广告骚扰)。
解决:在用户第一次点击页面时,触发音频上下文恢复。或者在连接前加个"点击开始"的引导页。
坑 2:背景显示不出来
现象:数字人渲染正常,但背景是黑色。
排查步骤:
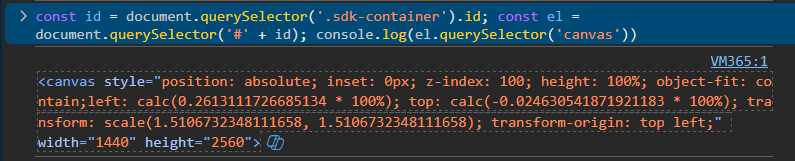
1. 打开 DevTools 查看 Network,确认背景资源是否加载
const id = document.querySelector('.sdk-container').id;
const el = document.querySelector('#' + id);
console.log(el.querySelector('canvas'))
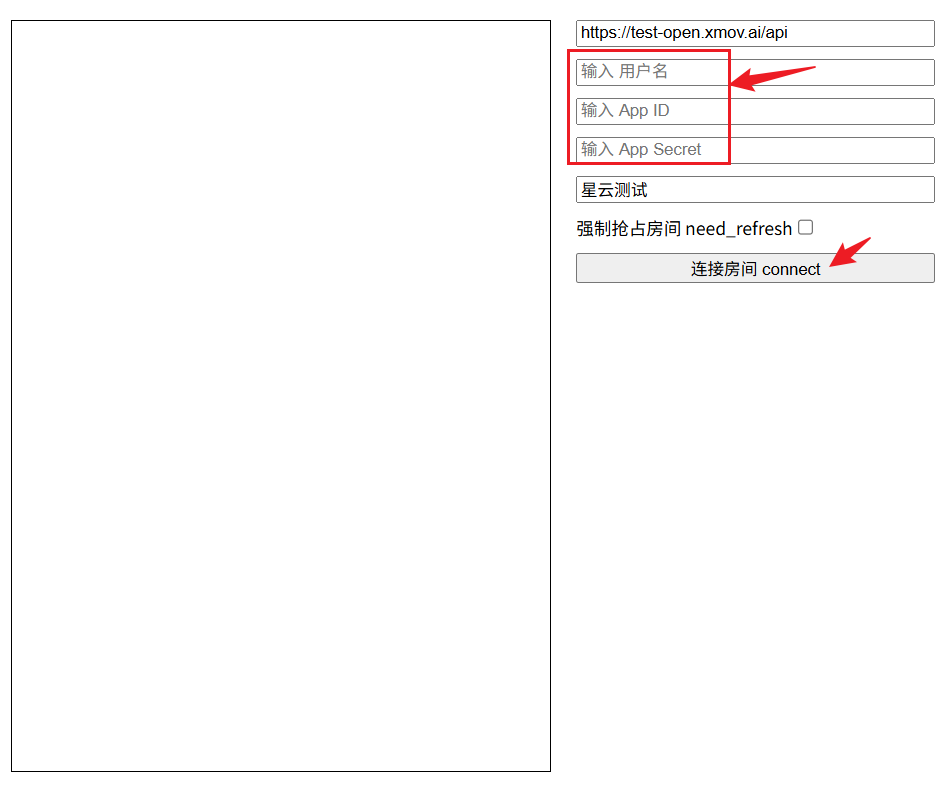
2. 用官方测试页验证账号是否开通了背景权限
打开你仓库内的 TTSA 测试页 src/stores/sdk-test.html(直接在资源管理器里双击打开即可)。在页面右侧填写:
server_url(你的服务地址)username/app_id/app_secrettag(场景标签)
点击"连接房间 connect"。若该 tag 场景具备背景,测试页会显示带背景的画面。这一步用于确认账号与场景能力。
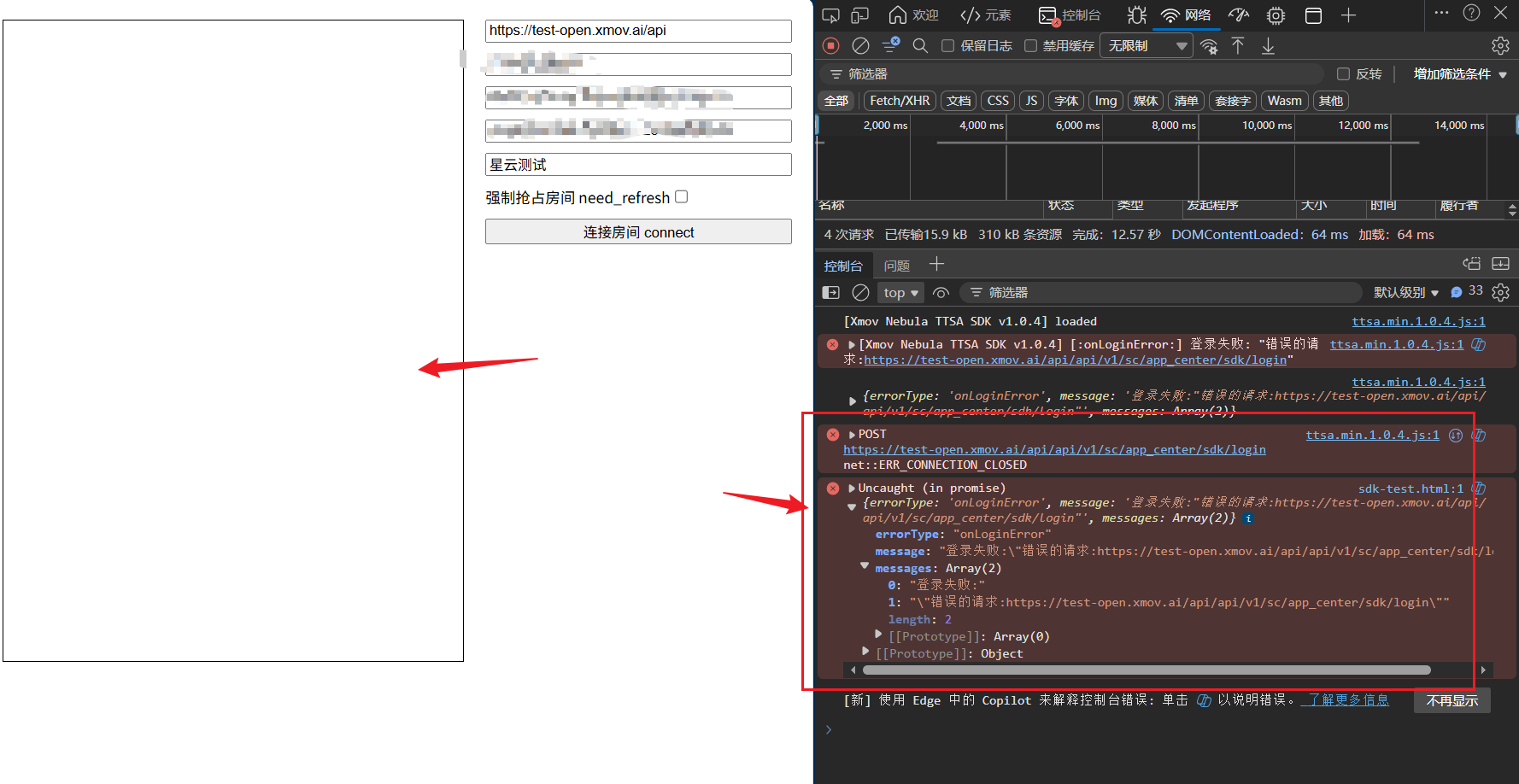
3. 检查场景配置的 dataSource 是否指向正确的场景
- 如果测试页能显示背景:说明你的账号具备背景能力。接下来需要确认"主应用的网关参数与场景配置"一致,即当前
data_source/custom_id指向的流是否就是你在 Demo 页用到的有背景的场景。通常需要服务侧把data_source/custom_id映射到带背景的房间/模板。 - 如果测试页也没有背景或 Network 显示失败:需要确认你的账号是否启用了背景资源和对应场景(
tag),或修正网络/跨域问题。只有服务端返回包含背景的流,客户端 canvas 才能渲染背景。
运行与构建
开发环境
# 安装依赖
pnpm install
# 启动开发服务器
pnpm run dev
# 访问本地应用
# http://localhost:5173/
生产构建
# 类型检查 + 打包
pnpm run build
# 预览生产构建结果
pnpm run preview
核心实现要点总结
| 模块 | 关键技术 | 核心文件 |
|---|---|---|
| SDK加载 | 动态Script注入 + 轮询检测 | sdk-loader.ts |
| 虚拟人渲染 | Canvas + XmovAvatar SDK | avatar.ts, AvatarRender.vue |
| 语音识别 | WebSocket流式ASR + 签名 | useAsr.ts, asr.ts |
| LLM交互 | OpenAI兼容API + 流式输出 | llm.ts |
| 业务编排 | 分句算法 + SSML包装 | app.ts |
| 状态管理 | Pinia + Vue 3 Reactivity | app.ts |
写在最后
从第一行代码到沐木真正"活"起来,我最大的感受是:具身智能时代已经到来,而魔珐星云正在让它变得触手可及。
这就是技术进步的意义——把曾经的"黑科技"变成人人可用的工具,让更多创新成为可能。如果你也想做一个有温度的数字人产品,不妨试试魔珐星云。它不只是一个 SDK,更是通往下一代交互的入场券。
快点击官方网站进行体验吧:https://xingyun3d.com/?utm_campaign=daily&utm_source=jixinghuiKoc11
此代码已上传至gitee仓库:https://gitee.com/yanyanhy/mumu
💡 技术的终极意义,是让世界变得更温暖。
当大模型有了身体,AI 就不再是冷冰冰的工具,而是能陪伴、能理解、能共情的伙伴。


DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 24
24 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)