【论文自动阅读】VLA-4D: Embedding 4D Awareness into Vision-Language-Action Models for SpatioTemporally Coher
为解决现有视觉-语言-动作(VLA)模型在机器人操作中“空间不顺畅、时间不连贯”的问题,作者提出了VLA-4D模型。该模型通过将3D空间信息与1D时间信息融合成“4D感知”,一方面优化视觉表示(让模型更精准理解场景的时空变化),另一方面扩展动作表示(给传统空间动作参数增加时间控制,比如每个动作该执行多久);同时还扩展了机器人数据集,增加时间维度的标注用于模型微调,最终让机器人能完成更精细、时空更连
1. 题目、时间(精确到月份)、机构(只写英文简称)、3个关键词(仅英文)
- 题目:VLA-4D: Embedding 4D Awareness into Vision-Language-Action Models for SpatioTemporally Coherent Robotic Manipulation
- 时间:2025年11月
- 机构:NUS(National University of Singapore)、HUST(Huazhong University of Science and Technology)
- 关键词:Vision-Language-Action (VLA)、4D Awareness、Robotic Manipulation
2. 一段话通俗总结干了什么事
为解决现有视觉-语言-动作(VLA)模型在机器人操作中“空间不顺畅、时间不连贯”的问题,作者提出了VLA-4D模型。该模型通过将3D空间信息与1D时间信息融合成“4D感知”,一方面优化视觉表示(让模型更精准理解场景的时空变化),另一方面扩展动作表示(给传统空间动作参数增加时间控制,比如每个动作该执行多久);同时还扩展了机器人数据集,增加时间维度的标注用于模型微调,最终让机器人能完成更精细、时空更连贯的操作(比如抓取物体时不抖动、不停顿)。
3. 本文核心创新点比前人创新在哪里
现有相关模型存在明显局限,而本文创新点针对性突破这些局限:
- 对比2D VLA模型(如OpenVLA):2D模型仅用单图输入,视觉推理粗粒度且时空不连续;本文用视频输入+4D感知(3D+1D),解决了2D-3D坐标 mismatch 和时空断裂问题。
- 对比3D VLA模型(如SpatialVLA):3D模型仅嵌入3D空间信息,虽提升空间精度,但缺乏时间连贯性(易出现操作停顿、抖动);本文在3D基础上增加1D时间嵌入,且通过交叉注意力深度融合,同时优化视觉端的时空感知。
- 对比早期4D相关VLA模型(如4D-VLA):这类模型仅在视觉端融入时空信息,未针对动作端的时间连贯性优化;本文同时在视觉端(4D感知视觉表示)和动作端(时空动作表示,增加时间变量)进行联合优化,还通过多模态对齐让LLM能预测时空一致的动作。
- 数据层面:前人无专门针对VLA时空一致性的数据集,本文扩展LIBERO数据集,增加 temporal action annotations,为模型微调提供关键数据支撑。
4. 本文要解决什么问题
现有Vision-Language-Action(VLA)模型在机器人精细操作中面临的两大核心问题,导致无法实现“时空一致的机器人操纵”:
- 视觉推理粗粒度:部分模型用单张图像输入,无法捕捉时序信息;且2D图像坐标与机器人3D世界坐标不匹配,导致动作精度低(比如抓不准物体)。
- 动作执行缺乏时间连贯性:现有模型仅关注空间动作参数(如移动距离、旋转角度),忽略时间维度控制,导致动作执行时出现“ idle pauses(空闲停顿)”或“ jitter(抖动)”,无法形成流畅、连贯的操作过程。
5. 解决方法/算法的通俗解释,以及整体流程
解决方法通俗解释
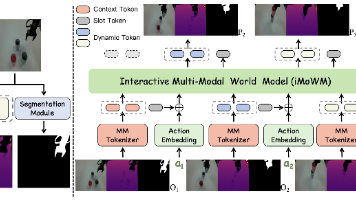
- 4D感知视觉表示:把“3D空间位置”(比如物体在机器人坐标系中的X/Y/Z坐标)和“1D时间”(比如操作的第几帧、执行时长)打包成“4D嵌入信息”,再用“交叉注意力”技术把这些4D信息融合到原本的视觉特征里——相当于让模型既能“看见”物体在哪,又能“记住”物体的时间变化,理解操作的动态过程。
- 时空动作表示:在传统机器人动作参数(如“移动多少距离(Δx)”“旋转多少角度(Δθ)”“夹爪开合(Grip)”)基础上,加一个“时间参数(Δt)”(比如这个动作要执行0.5秒还是1秒),让动作不仅知道“去哪”,还知道“花多久完成”,避免停顿或急促抖动。
- 多模态对齐:把4D视觉特征、机器人自身状态(如关节角度)都转换成和语言模型(LLM)兼容的“token”,再和文本指令(如“拿起黑色碗放到盘子上”)的token对齐,让LLM能综合所有信息,输出时空一致的动作。
整体流程
- 输入:机器人的手腕视角+第三方视角视频、文本任务指令、机器人本体状态(如夹爪位置)。
- 视觉处理:用视觉编码器提视频特征,用几何编码器(VGGT)提3D位置,结合时间信息生成4D嵌入,通过交叉注意力融合成4D感知视觉特征。
- 动作表示构建:将传统空间动作参数+新增的时间参数,形成时空动作表示。
- 多模态对齐:把4D视觉特征、本体状态都投影到LLM的语言嵌入空间,和文本指令token整合。
- 动作预测:LLM加动作头,根据整合的多模态信息,输出机器人的时空动作参数(Δx、Δθ、Grip、Δt)。
- 模型训练:用扩展的LIBERO数据集微调,分两阶段(先对齐4D视觉-语言,再优化动作预测),用L1损失计算预测动作与真实动作的差距,优化模型。
6. 基于了前人的哪些方法
- Vision-Language Models(VLMs):如Flamingo、Qwen2.5-VL-7B等,借鉴其多模态对齐思路,将视觉与语言信息融合到LLM中,为VLA模型提供基础框架。
- 3D VLA模型:如TraceVLA、SpatialVLA,借鉴其“将3D位置嵌入视觉特征以提升空间精度”的思路,解决2D-3D坐标 mismatch 问题。
- 4D时空信息融入方法:如Llava-4D、4D-VLA,借鉴其“将时间信息与空间信息结合以增强时空推理”的理念,但本文进一步扩展到动作端。
- 机器人数据集使用:基于LIBERO数据集(用于机器人终身学习的模拟数据集),本文在其基础上扩展时间标注,解决数据缺乏时空信息的问题。
- 交叉注意力融合技术:借鉴Transformer中的交叉注意力机制(如CrossViT),实现4D嵌入与视觉特征的高效融合。
- LLM动作预测框架:借鉴OpenVLA、Octo等VLA模型“用LLM输出动作token”的思路,本文进一步扩展为时空动作预测。
7. 实验设置、数据、评估方式是什么样的
实验设置
- 模型初始化:VLM backbone用预训练的Qwen2.5-VL-7B,几何编码器用预训练的VGGT;交叉注意力模块为Transformer-based架构。
- 硬件:8台RTX 6000 Ada GPU。
- 训练参数:分两阶段训练——阶段1(4D视觉-语言对齐):学习率1e-4,批大小16;阶段2(机器人任务微调):学习率5e-5,批大小24;优化器用AdamW,损失函数为动作参数的L1-norm损失。
- 对比模型:2D VLA(OpenVLA、Octo、CogACT)、3D VLA(TraceVLA、SpatialVLA)、4D VLA(4D-VLA)。
数据
- 数据集:扩展的LIBERO数据集(原数据集用于机器人终身学习,含4个任务类型:Spatial、Object、Goal、Long)。
- 数据扩展:在不改变原空间动作参数的基础上,手动筛选动作片段,根据采样频率将步骤数转换为“时间标注(Δt)”,最终含40个子任务、15万组“视觉-语言-动作”样本。
- 输入模态:多视角视频(手腕视角+第三方视角)、文本指令、机器人本体状态、3D位置信息、时间戳。
评估方式
- 评估任务:LIBERO的4个任务类型(Spatial:空间推理;Object:物体理解;Goal:任务目标;Long:长程规划),分“微调评估”和“零样本评估”。
- 评估指标:核心指标为“任务成功率(Succ. rate,越高越好)”和“任务完成时间(Time,越短越好)”,结果均报告均值±标准差。
- 消融实验:验证视觉端的3D嵌入、1D时间嵌入、交叉注意力融合的有效性;验证动作端时间参数的有效性;验证输入模态(图像vs视频、4D cues、本体状态)的影响;验证训练策略(单阶段vs两阶段)的影响。
8. 客观评价本文的价值
理论价值
- 填补空白:提出“视觉-动作联合4D感知”的VLA框架,解决了前人仅优化视觉端或仅优化动作端的局限,为VLA模型的“时空一致性”研究提供了新范式。
- 方法创新:将4D嵌入与交叉注意力结合,实现视觉特征的时空精细化;在动作表示中引入时间变量,量化动作的时间维度,为机器人时空动作规划提供了可复用的设计思路。
应用价值
- 提升机器人性能:在LIBERO数据集上,VLA-4D的平均成功率达97.4%(远超2D VLA的76.5%、3D VLA的78.1%、4D-VLA的88.6%),完成时间缩短至5.8秒,显著提升机器人操作的精度与效率,可应用于家庭服务机器人、工业装配机器人等场景。
- 数据支撑:扩展的LIBERO数据集(含时间标注)为后续VLA时空一致性研究提供了关键数据,降低了领域研究门槛。
局限与未来方向
- 局限:在“未知真实环境”中性能可能下降(如机械磨损、校准偏差导致动作误差),缺乏真实物理机器人的验证(当前基于模拟环境)。
- 未来潜力:文中提出的“结合强化学习在线修正动作误差”的方向,若实现可进一步提升模型在真实场景的鲁棒性,拓展应用边界。
9. 列出和本文相关性最高的3个文献
-
OpenVLA [5](Moo Jin Kim et al., 2024):核心原因是2D VLA模型的代表性 baseline,本文在实验中多次对比其性能(如微调任务中OpenVLA平均成功率76.5%,VLA-4D达97.4%),凸显本文对2D VLA时空不连续问题的解决价值;同时,本文的VLA基础框架也借鉴了OpenVLA“LLM+动作头”的设计思路。
-
SpatialVLA [13](Delin Qu et al., 2025):核心原因是3D VLA模型的代表性 baseline,本文借鉴其“3D位置嵌入视觉特征以提升空间精度”的思路,同时通过实验对比(SpatialVLA平均成功率78.1%,VLA-4D达97.4%),证明加入时间维度后对“时空一致性”的提升,凸显本文在3D VLA基础上的创新。
-
4D-VLA [16](Jiahui Zhang et al., 2025):核心原因是最接近本文的“4D相关VLA模型”,本文指出其仅在视觉端融入时空信息、未优化动作端的局限,通过实验对比(4D-VLA平均成功率88.6%,VLA-4D达97.4%),证明“视觉-动作联合4D优化”的必要性,是本文创新点的直接对比对象。# 1. 题目、时间(精确到月份)、机构(只写英文简称)、3个关键词(仅英文)
- 题目:VLA-4D: Embedding 4D Awareness into Vision-Language-Action Models for SpatioTemporally Coherent Robotic Manipulation
- 时间:2025年11月
- 机构:NUS(National University of Singapore)、HUST(Huazhong University of Science and Technology)
- 关键词:Vision-Language-Action (VLA)、4D Awareness、Robotic Manipulation
2. 一段话通俗总结干了什么事
现有视觉-语言-动作(VLA)模型让机器人干活时,要么空间上抓不准、要么时间上不连贯(比如停顿、抖动)。作者提出VLA-4D模型,把3D空间位置和1D时间融合成“4D感知”:视觉上,用交叉注意力把4D信息融入视频特征,让模型既懂物体在哪又懂时序变化;动作上,给传统动作参数(如移动距离、夹爪开合)加时间控制(如动作执行多久),让操作更顺畅;还扩展了数据集,给动作加时间标注。最终让机器人能完成时空一致的精细操作,比如平稳拿起碗放到盘子上。
3. 本文核心创新点比前人创新在哪里
前人模型存在明显短板,本文创新点针对性突破:
- 对比2D VLA(如OpenVLA):2D模型用单图输入,时空不连续、2D-3D坐标不匹配;本文用视频+4D感知(3D+1D),解决坐标 mismatch 和时序缺失问题,让视觉推理更精细。
- 对比3D VLA(如SpatialVLA):3D模型仅优化空间精度,缺时间连贯性(易抖动);本文在3D基础上加时间嵌入,且用交叉注意力深度融合,同时保障空间顺畅与时间连贯。
- 对比早期4D相关VLA(如4D-VLA):这类模型仅优化视觉端时空感知,未改进动作端;本文同时优化“视觉4D表示”和“动作时空表示”(加时间参数),还对齐多模态到LLM,实现端到端时空动作预测。
- 数据层面:前人无时空标注的VLA数据集,本文扩展LIBERO数据集加时间标注,为模型训练提供关键支撑。
4. 本文要解决什么问题
现有VLA模型无法实现“时空一致的机器人精细操作”,核心是两大问题:
- 视觉推理粗粒度:单图输入缺时序信息,2D图像坐标与机器人3D世界坐标不匹配,导致动作精度低(如抓不准物体)。
- 动作执行缺时间连贯性:仅关注空间参数(移动、旋转),忽略时间控制,导致操作时出现停顿、抖动,无法形成流畅过程。
5. 解决方法/算法的通俗解释,以及整体流程
解决方法通俗解释
- 4D感知视觉表示:把“物体3D位置”(如X/Y/Z坐标)和“时间”(如操作第几秒)打包成“4D信息包”,用“交叉注意力”技术融入视频特征——让模型既能“看见”位置,又能“记住”时序变化。
- 时空动作表示:在传统动作参数(移动Δx、旋转Δθ、夹爪Grip)基础上,加“时间参数Δt”(如这个动作执行0.5秒),让动作不仅知道“去哪”,还知道“花多久”,避免停顿。
- 多模态对齐:把4D视觉特征、机器人自身状态(如关节角度)转换成语言模型(LLM)能懂的“token”,和文本指令(如“拿碗放盘”)对齐,让LLM综合信息输出连贯动作。
整体流程
- 输入:机器人的手腕+第三方视角视频、文本指令、机器人本体状态(如夹爪位置)。
- 视觉处理:提视频特征和3D位置,结合时间生成4D嵌入,用交叉注意力融合成4D视觉特征。
- 动作构建:在空间动作参数中加时间参数,形成时空动作表示。
- 多模态对齐:将4D视觉特征、本体状态投影到LLM语言空间,与文本token整合。
- 动作预测:LLM加动作头,输出时空动作参数(Δx、Δθ、Grip、Δt)。
- 训练:用扩展的LIBERO数据集分两阶段微调(先对齐视觉-语言,再优化动作),用L1损失修正预测误差。
6. 基于了前人的哪些方法
- VLMs多模态框架:借鉴Flamingo、Qwen2.5-VL-7B等模型“视觉-语言对齐到LLM”的思路,为VLA模型提供基础架构。
- 3D VLA空间嵌入:借鉴TraceVLA、SpatialVLA“将3D位置嵌入视觉特征以提升空间精度”的方法,解决2D-3D坐标 mismatch。
- 4D时空融入理念:借鉴Llava-4D、4D-VLA“时空信息结合增强推理”的想法,但扩展到动作端。
- 机器人数据集基础:基于LIBERO数据集(用于机器人终身学习),扩展其时间标注解决数据缺失问题。
- 交叉注意力融合:借鉴CrossViT等模型的交叉注意力技术,实现4D嵌入与视觉特征的高效融合。
- LLM动作预测:借鉴OpenVLA、Octo“LLM+动作头输出动作”的框架,扩展为时空动作预测。
7. 实验设置、数据、评估方式是什么样的
实验设置
- 模型初始化:VLM用预训练Qwen2.5-VL-7B,几何编码器用预训练VGGT,交叉注意力为Transformer架构。
- 硬件:8台RTX 6000 Ada GPU。
- 训练参数:分两阶段——阶段1(视觉-语言对齐):学习率1e-4,批大小16;阶段2(动作微调):学习率5e-5,批大小24;优化器AdamW,损失为L1-norm。
- 对比模型:2D VLA(OpenVLA、Octo、CogACT)、3D VLA(TraceVLA、SpatialVLA)、4D VLA(4D-VLA)。
数据
- 数据集:扩展的LIBERO数据集(原含4类任务:Spatial、Object、Goal、Long)。
- 数据扩展:手动筛选动作片段,按采样频率将步骤数转为“时间标注Δt”,最终含40个子任务、15万组“视觉-语言-动作”样本。
- 输入模态:多视角视频、文本指令、机器人本体状态、3D位置、时间戳。
评估方式
- 评估任务:LIBERO的4类任务,分“微调评估”和“零样本评估”(测未见过的任务泛化性)。
- 核心指标:任务成功率(越高越好)、任务完成时间(越短越好),结果报均值±标准差。
- 消融实验:验证3D嵌入、时间嵌入、交叉注意力、动作时间参数、输入模态、训练策略的有效性。
8. 客观评价本文的价值
理论价值
- 填补空白:提出“视觉-动作联合4D感知”框架,解决前人仅优化单一端的局限,为VLA时空一致性研究提供新范式。
- 方法创新:4D嵌入+交叉注意力的视觉优化、动作加时间参数的设计,可复用于其他机器人时空规划任务。
应用价值
- 提升机器人性能:在LIBERO上平均成功率97.4%(远超2D VLA的76.5%、3D VLA的78.1%),完成时间5.8秒,可应用于家庭服务、工业装配机器人。
- 数据支撑:扩展的LIBERO数据集(含时间标注)降低领域研究门槛,为后续工作提供数据基础。
局限与潜力
- 局限:仅在模拟环境验证,真实场景(如机械磨损)中可能误差增大。
- 潜力:文中提出的“强化学习在线修正误差”方向,若实现可提升真实场景鲁棒性,拓展应用边界。
9. 列出和本文相关性最高的3个文献
- OpenVLA [5](Moo Jin Kim et al., 2024):2D VLA代表性 baseline,本文多次对比其性能(如成功率76.5% vs 97.4%),凸显时空不连续问题的解决价值;同时借鉴其“LLM+动作头”的基础框架。
- SpatialVLA [13](Delin Qu et al., 2025):3D VLA代表性 baseline,本文借鉴其3D位置嵌入思路,且通过对比(成功率78.1% vs 97.4%)证明时间维度的必要性。
- 4D-VLA [16](Jiahui Zhang et al., 2025):最接近的4D VLA模型,本文指出其仅优化视觉端的局限,通过对比(成功率88.6% vs 97.4%)验证“视觉-动作联合优化”的优势,是创新点的直接对比对象。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 6
6 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)