GaussGym 论文学习
论文链接: https://arxiv.org/pdf/2510.15352代码链接:https://github.com/escontra/gauss_gym本文提出了一种用于机器人仿真的创新方法,将 3D Gaussian Splatting 集成到了主流的向量化物理模拟器中,作为其内置的渲染器。这种方法实现了极高的速度(在消费级GPU上每秒超过10万次模拟步长)和高视觉保真度(即画面非常逼真
论文链接: https://arxiv.org/pdf/2510.15352
代码链接:https://github.com/escontra/gauss_gym
Introduction
本文提出了一种用于机器人仿真的创新方法,将 3D Gaussian Splatting 集成到了主流的向量化物理模拟器中,作为其内置的渲染器。这种方法实现了极高的速度(在消费级GPU上每秒超过10万次模拟步长)和高视觉保真度(即画面非常逼真)的结合。证明了该方法在 “仿真到现实” 机器人应用中的有效性,即将在模拟环境中训练的策略转移到真实世界中。它不仅支持基于深度信息的感知,还能利用丰富的视觉语义信息(如需要避开的区域),提升机器人的导航和决策能力。它能轻松地将多种来源的数据快速转换为逼真的训练场景,如 iPhone 扫描的 3D 环境、大规模场景数据集(GrandTour)和生成式视频模型输出的视频。本工作在快速模拟(高通量模拟)和高保真感知(逼真视觉)之间架起了桥梁,推动了可扩展和可泛化的机器人学习技术的发展。
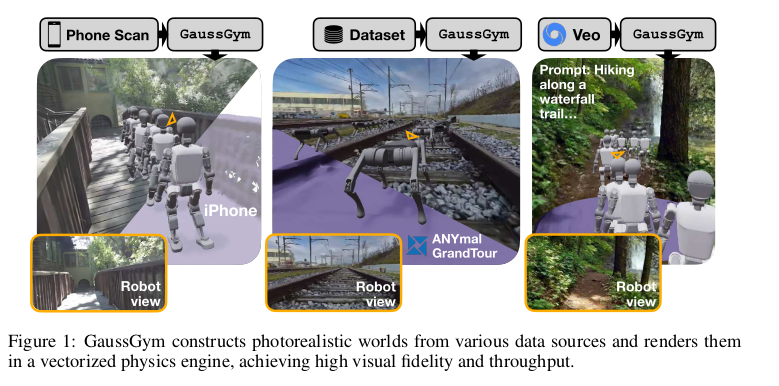
移动机器人要想在非结构化的真实世界(即不是工厂流水线那样规则的环境,而是像家庭、街道这样复杂多变的环境)中行动,它们必须能够精确地感知周围环境。文章设想了一个具体的机器人任务:在环境中移动到指定目标位置。在这个过程中,机器人需要完成两个关键动作:导航并避开障碍物、与人造物体进行交互。许多障碍物和环境提供的功能是无法通过激光雷达来识别的。在真实世界中(比如街道、办公室),一个移动机器人要完成送货、巡检等任务,不能只知道自己离某个物体有多远(避障)。它还必须能“看懂”场景,而这就需要依赖摄像头提供的视觉信息。因为像人行道、水坑、红绿灯、按钮这类对导航和交互至关重要的信息,它们的本质是视觉化的(表现为特定的图案、纹理、颜色),其他传感器无法有效识别。没有视觉感知,机器人就无法理解这些信息,从而无法在复杂环境中做出智能决策。
目前主流的腿式机器人 locomotion 研究采用的范式是 sim-to-real 强化学习,在利用现实环境的视觉特性方面存在巨大挑战,这限制了机器人的能力。这个方法会在虚拟环境中训练一个控制策略,然后希望这个策略能直接应用到真实机器人上,无需额外调整,即可实现鲁棒的移动能力。现有的仿真器在模拟物理(重力、摩擦力、关节运动)方面已经足够精确,能够成功地将策略转移到真实场景。问题出在视觉信息的处理上。仿真器要么渲染画面太慢(严重影响训练效率),要么画面不够逼真(与真实世界差距大)。由于视觉仿真效果不佳,大多数需要感知的移动框架都放弃使用摄像头,转而依赖更简单、但信息量更少的激光雷达或深度相机。这些传感器只能提供物体的几何距离和形状信息。这就限制了机器人利用语义信息,无法理解环境的含义,它只知道“前方10米处有一个障碍物”,但不知道这个障碍物是一滩水、一片草地还是一个脆弱的纸箱。不同的语义需要不同的应对策略(绕开水洼、小心走过草地、避开纸箱)。同时也限制了可模拟的任务范围,许多高级任务严重依赖视觉语义,如“走到那扇开着的门那里”。
本文提出了 GaussGym,一个开元的仿真框架,它利用最新的图形技术(3D高斯溅射),能够将各种现实世界或AI生成的视频数字化,创建一个既模拟物理又提供照片级真实感画面的虚拟环境。其最终目的是让机器人能直接从RGB摄像头画面(而不仅仅是激光雷达)中学习行走和导航策略。它构建于 3D 重建和可微分渲染基础上,将多种不同来源的输入数据导入仿真环境中。系数可以处理多种数据来源,包括智能手机扫描、现有的 3D 数据集、手持设备拍摄的视频、生成式视频模型生成的视频。GaussGym 的性能卓越,在单张RTX 4090消费级GPU上,可以同时模拟4096个机器人,每个机器人的画面分辨率达到 640 × 480 640\times 480 640×480。
为了验证 GaussGym 在训练“视觉-运动”策略方面的有效性。具体就是为双足(人形)和四足(如狗型)机器人训练了移动和导航策略。尽管GaussGym速度更快、画面更逼真,但“直接从RGB像素学习”依然很难。因为策略网络必须从二维图像中自行推断出三维几何信息(比如地面的高度、障碍物的形状),而不能像传统方法那样直接使用现成的高度图或深度图。于是作者引入了一个辅助的重建损失函数。 在仿真训练时,系统拥有场景的精确三维模型(ground truth meshes)。他们要求策略网络在学习控制机器人的同时,额外学习重建出它所“看到”的场景的几何结构。这个“附加任务”像一个老师,引导网络更关注场景的几何特征,从而显著提高了学习的速度和最终的性能。作者将在GaussGym 中仅通过视觉训练出的策略,不经过任何在真实机器人上的额外调整,直接部署到真实的机器人上进行楼梯攀爬测试,并取得了初步成功。这是向填补视觉仿真与现实差距所迈出的第一步。GaussGym 降低了对高逼真度仿真技术的使用门槛,为未来关于视觉移动和导航的研究提供了坚实的基础。
本文主要贡献如下:
- GaussGym:一个快速开源的仿真模拟器,包含了 2500 个场景,从人工扫描、开放数据集和生成视频模型提供了多样化的场景重建。
- 分享了一些关于解决视觉 sim-to-real gap 的发现,将几何重建作为辅助任务能显著提升爬楼梯的表现。
- 通过一个“到达目标点”的任务证明:基于RGB像素训练出的导航策略,具备语义推理能力。它能成功避开一些“不受欢迎的区域”,而这些区域对于只使用深度信息的策略来说是完全“不可见”的。
Related Works
Sim-to-real RL for Locomotion
仿真为训练强化学习移动和导航策略,提供了一个具有规模性和经济性的方法,在训练时无需昂贵的硬件数据采集和危险的真实世界探索,也能获取到有用的信息。一个理想的仿真器应包括以下几个特性:高通路、准确的物理属性、逼真的渲染。
仿真技术从CPU上的刚体动力学仿真发展到GPU加速的大规模并行仿真,极大地促进了机器人强化学习的发展。CPU刚体动力学仿真器(如MuJoCo, PyBullet)首次证明了“仿真到现实”转移是可行的,即可以在仿真中训练策略并应用到真实机器人上。但是,他们是基于 CPU 的,计算速度很慢,难以进行大规模并行训练。而 GPU 加速仿真器(如Isaac Gym)利用GPU并行计算,速度极快。这使得研究人员可以使用消费级硬件同时训练成千上万个机器人,极大地普及了强化学习训练,推动了腿式机器人和导航技术的快速发展。
尽管最新的仿真框架已经支持硬件加速的并行渲染,但真正在现实世界中成功部署的机器人移动策略,其感知输入仍然局限于:
- 几何信息:深度图、高程图
- 本体感觉信息:如关节角度、身体姿态。
仿真器生成的画面不够逼真,导致在仿真中学到的视觉策略无法适应真实世界。此外, 仿真环境中缺少足够多样且逼真的3D场景模型。逼真渲染通常很慢,无法满足强化学习所需的海量数据模拟速度。隐式学习的场景表示如 3DGS 能够同时解决上述的保真度和速度问题——既能提供高质量的视觉输出,又能实现极高的渲染速度。
场景生成
使用手工设计的规则或算法程序化地生成地形(如随机的台阶、斜坡),能非常有效地创建复杂的几何地形,训练出非常鲁棒的机器人运动行为。但是,它只能定义几何形状,无法指定场景有意义的视觉外观。生成的世界看起来像抽象的几何体,没有真实的纹理和材质。实现真实的视觉输入需要从现有的高质量资产库中导入已经建好的、带纹理的3D模型来组合场景。如 ReplicaCAD, AI2-THOR 等平台提供了室内场景的精细模型,可以获得较高质量的模型,但创建和搜集这些资产的成本高昂,灵活性有限。有研究尝试从视频中重建场景用于训练,但他们放弃了重新渲染RGB图像(即只使用几何信息,而不利用逼真的视觉外观进行训练)。这说明了在保持高保真度的同时实现高效渲染的难度。另一方面,使用专业的3D扫描设备捕获真实场景,然后导入仿真框架,能获得最真实的环境数据,但过程繁琐、昂贵,难以大规模应用。上述大多数方法依赖的基于纹理网格的渲染管道,往往导致较低的视觉保真度。
本方法基于 NeRF2Real 而来,它通过 NeRF 来捕获场景,提升视觉保真度,然后通过网格提取、人工后处理来训练移动策略。但是,计算成本很高,因为光线追踪速度慢,无法在GPU上对成千上万个环境进行并行模拟。Zhu 等人构建了多个场景的 3DGS,训练了一个视觉高层级导航策略。在机器人控制领域的一些工作使用了 3DGS 创建关节式场景或训练模型来进行物体的参数估计,预测物体的 URDF。 这些工作证明了3DGS在机器人学的价值,但GaussGym的焦点是整合3DGS到物理仿真中,直接训练从像素到动作的端到端运动控制策略,并实现前所未有的模拟速度。LucidSim 主要有两个贡献:
- 用ControlNet从深度图和语义掩码生成视觉数据(一种数据增强方法)。
- 提出了一个“真实到仿真”的框架,使用3DGS,但需要通过 Polycam 生成的网格来手动对齐坐标系。
前沿生成式视频模型能根据文本提示生成逼真、多视角一致的视频,为大规模3D资产和环境创建提供了革命性的可能性。但是生成(推理)速度极慢,无法直接作为仿真器使用。GaussGym的设计正好可以接纳这些模型生成的视频作为输入,将其转化为可交互的仿真环境,从而 bridging the gap(架起桥梁)。
Radiance Fields in Robotics
NeRF 是一种用于从照片进行高质量3D场景重建的先进技术,它产生的视觉质量非常高,近年来在各个方面(如质量、规模、速度、动态场景)都有飞速发展。最初用于高质量抓取,后来因其能嵌入高维特征(如语言信息),也被用于语言引导的机器人操作。但是 NeRF 的训练和渲染速度非常慢。 这是阻碍其被广泛应用于机器人仿真的根本原因。3DGS 是NeRF的一种改进和替代方案,它不再使用复杂的神经网络来表示场景,而是用一组具有方向的3D高斯椭球的集合来表示。这种表示方法可以通过现代GPU硬件进行快速的可微分光栅化,渲染速度极快。许多研究已经成功地将NeRF的高级特性(如高维特征场)迁移到3DGS上,用于语言引导抓取、长期操作以及视觉模仿等任务。
辐射场(如NeRF, 3DGS)技术已被证明在多个方面有巨大潜力,比如可微的碰撞表征用于导航;作为视觉模拟器,用于从RGB像素学习无人机飞行或自动驾驶;作为场景表征,通过视角增强来训练运动“功能可供性”模型。GaussGym从这些成果中汲取了灵感,并将高保真环境视觉模拟与来自IsaacSim的接触物理模拟结合起来,专门用于实现机器人运动。它是一个完整的“视觉-物理”仿真系统。与 GassuGym 最相关的工作是LucidSim,它也是一个集成了“溅射”技术的仿真器,用于评估运动策略。GaussGym虽然也采用了类似的“真实到仿真”思路,但它在三个方面实现了超越:
- 极高的可扩展性: GaussGym的框架设计使其能够轻松扩展到数千个扫描场景。而LucidSim可能只针对少量特定测试场景。
- 与大规模并行物理的深度集成: GaussGym与IsaacGym等物理引擎紧密集成,支持同时模拟数千个机器人,这对于高效的强化学习训练至关重要。
- 为未来研究打造的灵活框架: GaussGym被设计成一个灵活、开源的基础框架,旨在供整个研究社区使用和扩展,而不仅仅是为了展示某个特定成果。
GaussGym
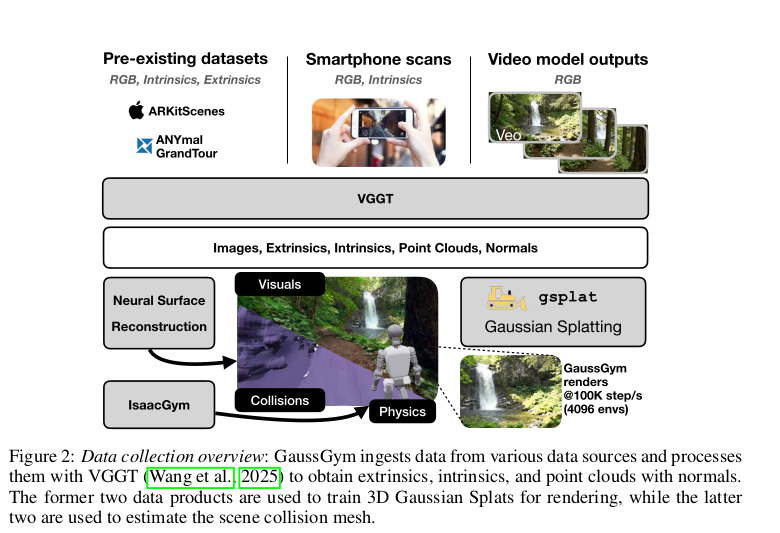
上图展示了 GaussGym 的流程。数据可以是带有位姿信息的数据集、智能手机扫描数据、视频生成模型生成的 RGB 序列。所有的输入都用 VGGT 做了标准化,估计相机内参、外参、密集点云和法线。为了创建仿真环境,GaussGym同时采用两种方法从原始数据生成3D资产。
路径一:用于生成网格,这些中间表征然后被送入一个神经表面重建模块,生成网格,网格是物理引擎进行碰撞检测的基础,需要明确的表面来计算物体之间是否接触。
路径二:用于生成高斯泼溅,直接用 VGGT 点云来初始化高斯泼溅,3D高斯溅射技术本身训练速度极快,能迅速优化出高质量外观。
上述两条路径生成的资产(用于物理的网格 和用于渲染的高斯表示)会被自动地对齐于全局坐标系内。这确保了机器人“看到”的画面(由高斯渲染产生)和它“身体”感受到的物理碰撞(由网格计算得出)在空间上是完全一致、同步的。这是实现逼真仿真的基石。在仿真时,高斯泼溅会被作为“即插即用”的组件使用,提供逼真的视觉信息,并且可以进行大规模并行渲染。物理引擎则负责计算重力、摩擦力、运动和碰撞处理。并且,这两者保持完全同步。这种巧妙的设计使得 GaussGym 能够将多样的真实世界和合成数据整合起来,既利用了 3DGS 的速度优势,也能支持大规模大规模机器人学习。

数据采集和处理
GaussGym 的设计非常灵活,可以从多种数据源获取数据。包括带有位姿的数据集(如 ARKitScenes 和 GrandTour)、带有内参标定的智能手机采集的图像,甚至是不带有位姿的视频生成模型生成的 RGB 序列。
所有数据(无论是手机扫描、视频还是数据集)在处理前都被转换到一个统一的重力对齐坐标系中。这是实现自动化流程的基础,确保不同来源的数据都能以一致的方式被处理。使用 VGGT 来提取相机的内参、外参、密集的场景表征(包括点云、法线)。然后,流程分为两支,分别生成物理和视觉所需的资产:
- 用于物理碰撞的网格: 使用神经核表面重建(NKSR) 技术从VGGT的输出生成高质量的网格。这个网格将用于物理引擎的碰撞检测。
- 用于视觉渲染的高斯溅射: 直接使用VGGT产生的点云来初始化3D高斯。这种方法极大地提高了几何保真度(因为点云直接来自真实数据,几何准确),并加速了收敛。
通过上述自动化流程,GaussGym确保了渲染画面(来自3D高斯)的几何形状与物理碰撞体(来自网格)的几何形状在空间上精确匹配。这是实现可靠物理仿真的关键。机器人“看到”的物体轮廓和它“撞到”的物体轮廓必须一致。GaussGym相对于最相关的已有工作LucidSim 有三大改进:
- 数据兼容性更广: LucidSim仅限于处理智能手机扫描数据;而GaussGym可以处理各种来源的数据。
- 自动化程度更高: LucidSim需要手动将网格和3DGS模型进行对齐注册;而GaussGym实现了全自动对齐,这是实现大规模扩展的关键。
- 性能更强: LucidSim不提供向量化渲染(即无法同时并行渲染成千上万个环境);而GaussGym的设计原生支持向量化渲染,从而实现了前所未有的模拟速度。
3DGS as a Drop-in Renderer
在场景创建完成后,GaussGym 使用 3D高斯溅射技术重建好的3D高斯进行光栅化。简单说,就是把3D的高斯椭球转换成2D的屏幕像素图像。与传统图形技术相比,这种技术能以极小的开销实现照片级逼真的画面。它不是一个个环境顺序渲染,而是同时渲染成千上万个环境。天生就适合在GPU上进行大规模并行处理,从而确保了极高的渲染效率和训练速度。作者使用 PyTorch 的多线程内核对所有环境中的高斯进行批量渲染,确保了 GPU 的高效利用率和支持分布式训练。
为了最大化效率,并缩小仿真与现实的差距,GaussGym 采用了两种策略:
- 渲染与控制的频率解耦: 不以极高的控制频率进行渲染,而是以更接近真实摄像头的帧率渲染,从而大幅提升速度,并保持了高保真度。机器人控制器和物理引擎的更新频率非常高(可能高达几百甚至上千赫兹),以确保运动的稳定和精确。而真实世界摄像头的帧率相对较低(通常为30或60帧/秒)。如果为了匹配控制频率而每步物理仿真都渲染一帧图像,会产生大量视觉上完全重复的帧,造成巨大的、不必要的计算浪费。
- 模拟运动模糊: 通过一种新颖的方法生成逼真的运动模糊效果,这能提高策略在真实世界中应对快速运动时的鲁棒性。真实摄像头在曝光时间内,如果与场景有相对运动,就会产生运动模糊。传统的仿真器通常生成“绝对清晰”的图像,这与真实摄像头拍摄的画面有差异,构成了“仿真到现实”差距的一部分。GaussGym 根据摄像机的运动速度和方向,沿着运动路径渲染一小簇偏移的图像,然后使用 AlphaBlend 将这些图像以一定的透明度叠加融合成一张最终图像。这种方法能产生非常真实的运动模糊伪影。
这样做能提高视觉保真度,画面更接近真实摄像机所拍;并增强转移的鲁棒性,策略在训练时就已经见识并学会了处理模糊的图像,因此当被转移到真实世界、面对因机器人快速运动或震动产生的模糊画面时,会更加鲁棒。此外,特别有益于剧烈运动场景,在爬楼梯(会产生突然的颠簸)或高速运动时,运动模糊效果尤为明显,因此这个优化对这些任务至关重要。
效果
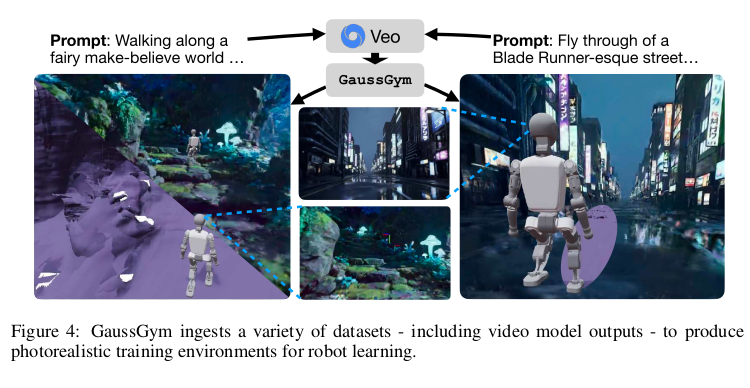

Visual Locomotion and Navigation
为了评估GaussGym中照片级真实感渲染的价值,研究者选择了“视觉楼梯攀爬”和“复杂地形下的视觉导航”作为测试任务。在方法上,他们刻意选择了一种更具挑战性但更纯粹的端到端单阶段训练方法,而不是更简单但间接的“师生蒸馏”法,以直接证明从像素到动作的端到端学习的有效性。
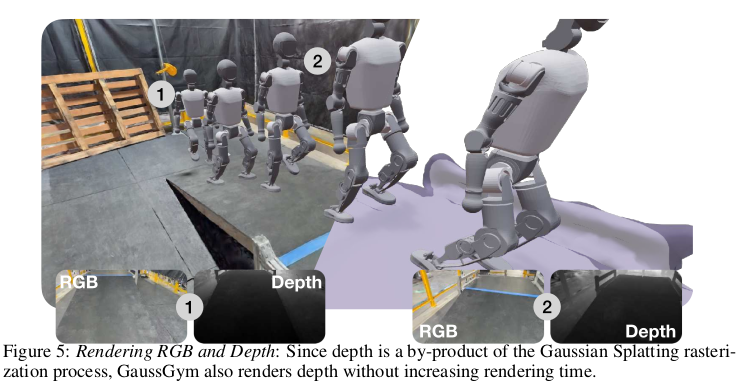
Neural Architecture
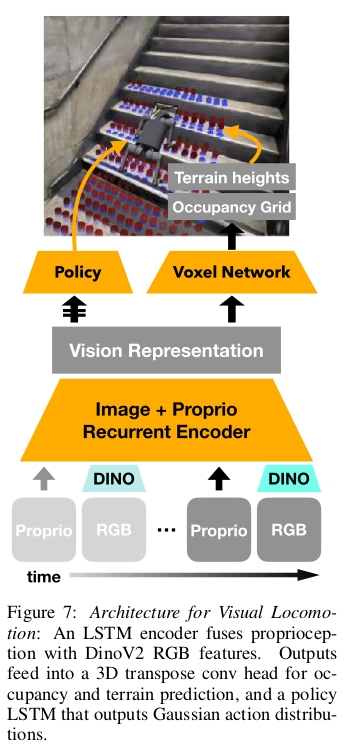
本框架的核心组件是一个循环编码器。它的作用是融合视觉信息和本体感觉信息,并理解其随时间的变化趋势。它采用LSTM而非Transformer架构,是出于在真实机器人上实现快速推理速度的实际考虑。输入包含了两种不同传感器的信息流。视觉流来自于摄像头的 RGB 图像。本体感觉流则来自机器人身体的传感器数据,如关节角度、电机扭矩、身体朝向等。
在每个时间步,原始RGB图像(像素数巨大,信息冗余)不会被直接送入网络。而是先通过一个强大的预训练视觉模型 DinoV2,将其转换为一个高度浓缩的、包含丰富语义信息的数学向量(称为嵌入)。这就像是把一张复杂的图片总结成一段包含关键信息的描述。将上一步得到的视觉嵌入和当前的本体感觉测量值拼接在一起,形成一个组合特征向量。将这个组合特征向量输入到一个LSTM 中。LSTM 具有“记忆”功能。它不仅能处理当前时刻的输入,还能保留之前时刻的信息。这使得策略能够理解时序动态。LSTM最终产生一个紧凑的潜在表示。这个表示综合了历史的视觉语义和本体感觉信息,是对当前环境状态和机器人自身状态的高度概括。Transformer 是当前许多AI领域的首选模型,性能强大。但作者选择了LSTM,原因很务实:需要快速推理速度。
在生成融合了视觉和本体感觉的潜在表示之后,网络分为两个并行的“头”来执行不同任务:
- 体素预测头: 负责从潜在表示中重建出场景的3D几何结构(体素占用和地形高度)。这是一个辅助任务,旨在迫使网络学习对几何的深刻理解。将来自共享编码器的 latent 表示展开为一个粗糙的 3D 网格,通过3D转置卷积层逐步上采样这个网格,最终输出一个密集的体素预测,包括了占用和地形高度。为了完成这个任务,共享的潜在表示必须捕获场景的几何信息。这为网络提供了一个强大的、基于几何的归纳偏差,引导它去关注对移动至关重要的几何特征(如台阶边缘、地面凹凸),而不是无关的纹理细节。这被称为辅助重建损失。
- 策略头: 这是主线任务,它负责输出机器人的动作(关节位置偏移量),最终目的是输出控制机器人运动的动作。将来自共享编码器的 latent 表示用另一个 LSTM 处理这个表示及其自身的隐藏状态,以生成与时间序列密切相关的动作。输出一个高斯分布的参数,策略学习的是动作的概率分布,而不是一个确定的动作。这为探索和不确定性提供了空间。智能体从这个分布中采样得到一个具体的关节位置偏移量。
这种设计利用辅助任务来监督和提升网络内部表征的质量,从而间接但极大地改善主任务的性能。
Visual Locomotion Results
研究者选择“爬楼梯”这个任务作为测试案例。虽然这个任务可以靠几何信息(如深度相机)甚至不靠视觉(“盲爬”)解决,但它能很好地展示其纯视觉策略学到的智能行为。实验证明,基于 Unitree A1 和纯视觉训练出的策略能精确地落脚并适应步态,并且能够不经过任何调整,直接从仿真迁移到真实机器人上成功爬楼梯。在GaussGym仿真中,使用RGB图像训练的策略(在Unitree A1机器人上)学会了:
- 精确的脚部放置: 能够准确地将脚踩在台阶上,而不是踢到或踩空。
- 自适应的步态: 能够调整自己的步伐以避免与楼梯竖板 发生碰撞。
- 鲁棒的速度跟踪: 能够在不同地形上稳定地按照指令速度行进。
这些行为表明,策略并非死记硬背,而是真正理解了场景的3D几何结构以及如何与之安全交互。

Visual Navigation Results
视觉导航任务包括稀疏的目标跟踪任务,智能体需要绕过障碍物,到达远处的路径点。作者设计了一个障碍场,其中设置了一个惩罚区域——地板上的一块黄色斑块。在训练期间,如果智能体进入这个区域,会收到一个负奖励信号。作者设计了两种策略,一个是 RGB 策略,一个是深度图策略。
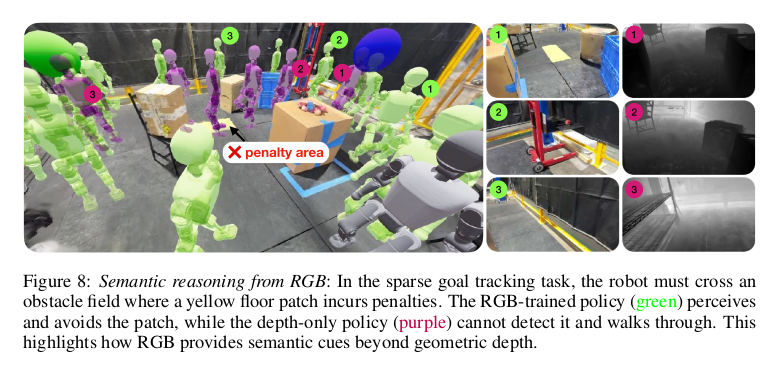
- RGB策略成功地避开了黄色斑块,对于RGB策略来说,它从图像中“看到”了黄色的颜色和特定的纹理。通过训练,它将这些视觉特征与“惩罚”(负奖励)联系了起来,从而理解了“这是一个应该避开的地方”的语义。
- 而仅深度策略未能避开,直接穿过了该区域,它所“看到”的惩罚区域只是一片平坦的、可通行的地面。在几何上,这里没有障碍物,因此它认为这是最优路径。
为了科学地证明 GaussGym 框架中各个设计选择的有效性,作者在四种模拟场景(平坦地面、陡坡、低矮楼梯、高楼梯)上进行了一次大规模的消融实验。实验结果表明:
- 体素网格回归和预训练的DINO编码器都是提升性能的关键组件,移除任何一个都会导致性能下降。
- 使用大量场景进行训练比只使用少量场景效果要好得多,这凸显了 GaussGym 能够无缝整合多场景进行训练的基础设施的价值。
Limitations
尽管GaussGym取得了成功,但视觉 sim-to-real 的迁移仍然是一个巨大且未完全解决的挑战。作者系统地阐述了当前框架的多个局限性,包括:在真实硬件上部署的额外挑战、对视觉语义(如社交规范)的奖励函数定义问题、物理参数的单一性、依赖的生成式模型的内在缺陷,以及无法处理动态场景和复杂物理(如流体、可变形物体)等。这些都为未来研究指明了方向。
仿真到现实的差距依然存在
在仿真时,基于视觉的策略学习了如何避开高代价区域,能准确地落脚在正确的位置。但是策略尚未在训练中未见过的新楼梯上进行评估,其泛化能力需要进一步检验。尽管实现了零样本转移,但作者观察到在真实世界中,策略的精确度有所下降(如脚部放置不如仿真中精准)。
真实世界部署的故有难题
- 物理延迟:真实机器人存在图像传输、计算等延迟,而仿真中是即时的。
- 依赖自我中心视角:机器人的视角是局部的、动态的,这比仿真中可能使用的全局视角更具挑战性。
- 与传统几何方法比较:基于高程图和高速状态估计的传统方法在这些“低级”控制问题上更稳定,这反衬出纯视觉方法的难度。
高阶语义推理的自动化问题
对于需要理解“社交规范”的任务(如走人行道),GaussGym目前缺乏自动生成相应成本或奖励函数的机制。现在仍需手工设计。未来可以利用基础语言模型来自动定义这些高级语义的奖励函数。
物理-视觉关联的缺失
当前环境中的资产使用统一的物理参数(如摩擦系数)。因此,无法模拟“看起来是冰面,踩上去就很滑”或“看起来是泥潭,踩上去会下陷”这种视觉外观与物理特性之间的关联。这限制了策略应对复杂地形的能力。
依赖的生成式模型的内在缺陷
- 不一致性: 如Veo等模型生成的内容可能不一致,需要反复调整提示词。
- 控制力有限: 仅通过文本控制生成视角的能力有限。
- 未来方向: 集成更先进、可控的世界模型(如Genie 3)是明确的改进路径。
仿真能力的边界
- 动态场景: 目前无法处理包含移动物体(如行人、车辆)的动态环境。
- 复杂物理: 无法模拟流体、沙子、布料等非刚体物理效果,这受限于底层物理引擎IsaacGym的能力。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)