7天掌握LeRobot:机器人学习新利器
本文是「7 天上手 LeRobot」系列的第 1 篇,主要回答三个问题:
1)LeRobot 从哪来?
2)它在机器人学习生态里的地位和作用是什么?
3)它的整体框架长什么样?
一、LeRobot 是什么?
如果对 Hugging Face 有了解,会知道它靠 Transformers 库把 NLP 的模型和预训练权重做成了“标准件”;而 LeRobot 可以理解成 Hugging Face 想在机器人领域做的一次类似尝试。
官方的定义大致可以概括为:
LeRobot 是 Hugging Face 开源的机器人学习库,提供 模型、数据集、仿真环境和端到端训练/部署工具,目标是让现实世界的机器人学习更易用、更可复现。
它有几个关键词值得标出来:
-
PyTorch 生态:底层以 PyTorch 为主,你可以把它当成“面向机器人场景的强化学习 + 模仿学习工具箱”。
-
专注真实世界机器人:不仅仅是玩玩仿真,还强调能跑在真实硬件上(例如 SO-101 这类开源机械臂)。
-
数据、模型、环境全部上 Hub:数据集、模型、仿真环境都通过 Hugging Face Hub 分发和版本管理,天然适合分享和复现。
-
从数据采集到训练、推理的一整条流水线:不仅给你模型,还包括遥操作(teleoperation)、录数据、训练脚本、部署脚本等。
LeRobot 在 Hugging Face 官方的 机器人课程(Robotics Course) 中被作为主力工具贯穿使用,从“传统机器人学”讲到“基于数据和大模型的机器人学习”,都是围绕 LeRobot 展开的。
二、LeRobot 的由来:从“缺统一方案”到“端到端库”
1. 机器人学习的痛点
在 LeRobot 之前,机器人学习一般长这样:
-
数据集格式五花八门:HDF5、npy、自定义 JSON/CSV……
-
仿真环境分散:OpenAI Gym、Isaac Lab、自研 env,各玩各的。
-
模型实现分散在一堆论文仓库,参数、训练细节不统一。
-
真机控制又是另一堆驱动、SDK、ROS/ROS2 节点。
结果就是:你花在“接线+写 glue code”上的时间,远大于花在“设计算法和调参”上的时间。
Hugging Face 在 2024 年左右正式推出 LeRobot,希望做一件类似当年 Transformers 在 NLP 里做的事:
把“模型 + 数据集 + 环境 + 训练代码”打包成一个标准化的生态,降低机器人学习的进入门槛。
2. 时间线和几个关键版本
从公开资料里可以看到的大致演进:
-
2024 年:LeRobot 正式对外发布,被称为「面向现实世界的第一个开源机器人学习库之一」,主打统一格式的机器人数据集 + 模仿学习/RL 模型实现。
-
2024–2025 年:
-
发布了 LeRobotDataset 数据格式,配套的 HF 博客详细讲了如何用视频编码把机器人数据做得既小又好用。
-
开始接入各种真实机器人(比如 SO-100 / SO-101)、仿真平台(Isaac、LIBERO、MetaWorld 等)。
-
-
2025 年 v0.4.0:这是一个比较大的里程碑版本,引入:
-
LeRobotDataset v3.0:为 OXE、DROID 这类几百 GB 甚至 TB 级别数据集设计的分块 + 流式格式。
-
新一代 VLA(视觉-语言-动作)模型,比如 π0.5、GR00T N1.5 等。
-
新的插件系统,简化硬件对接;增加对 LIBERO、MetaWorld 等仿真套件的支持。
-
官方推出完整的 机器人学习课程 和长篇 Tutorial(《Robot Learning: A Tutorial》),都以 LeRobot 为实战库。
-
可以看到,LeRobot 不是“一个单独的仓库”,而是在逐渐变成 机器人学习生态:从硬件到仿真,从数据集到模型,从课程到社区。
三、LeRobot 在生态中的地位和作用
1. 和传统工具的对比
如果你之前接触过 RL 或机器人,可能用过:
-
OpenAI Gym / Gymnasium:统一环境接口,但不管数据和真实机器人。
-
Isaac Sim / Isaac Lab:GPU 加速仿真很强,但偏底层,需要自己搭建学习部分。
-
各类 RL 库(Stable-Baselines3、RLlib 等):专注算法本身,对现实世界机器人支持有限。
LeRobot 的定位有点像:
把“Gym + RL 库 + 数据集格式 + 真机控制”的功能合在一个统一的、以 Hugging Face Hub 为中心的框架里。
具体来说,它在生态里做了几件“补位”的事情:
-
标准化机器人数据集格式(LeRobotDataset v3.0)
-
支持 多模态(状态、图像、多机位视频),用视频编码 + Parquet 元数据的方式把容量压缩到原始的十几分之一甚至更少。
-
显式支持 多百万条 episode + 流式读取,对大规模开放数据集(OXE、DROID)非常友好。
-
-
模型和策略的“模型库化”
-
不只是 ACT 这种模仿学习策略,还有以 视觉-语言-动作(VLA) 为代表的通用机器人策略,如 π0、π0.5、GR00T N1.5 等。
-
-
EnvHub:社区驱动的仿真环境中心
-
可以把自己的仿真环境上传到 Hub,然后用一行代码加载:
from lerobot.envs.factory import make_env env = make_env("lerobot/cartpole-env", trust_remote_code=True) -
这样做的好处是:环境和数据集、模型一样被版本化和分享,可以快速复现实验。
-
-
和真实机器人硬件强绑定
-
官方重点支持 SO-100 / SO-101 等开源机械臂,并提供从组装、标定、遥操作、录制数据、训练、推理的一整套教程。
-
通过像 LeIsaac、phosphobot 这样的配套项目,打通 真机 ↔ 仿真 ↔ 数据集 ↔ 大模型 的闭环。
-
总结一句:
LeRobot 把原来散落在各处的“机器人学习基础设施”尽量统一到一个可复用的框架里,既方便研究,也方便工程落地。
四、LeRobot 的整体框架:一图看清
为了后面几天好展开,我们先用一个“逻辑架构图”来认认门:
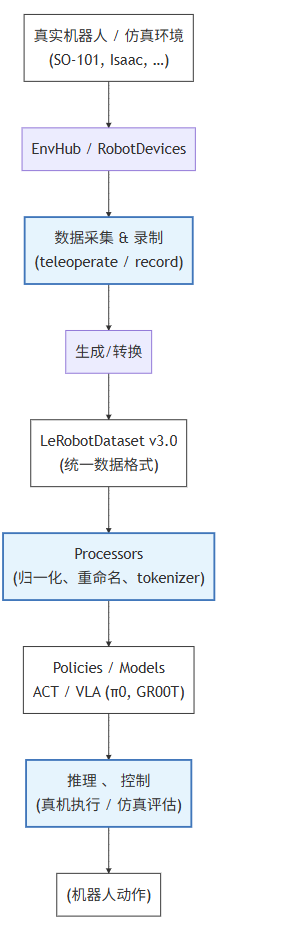
简单拆一下模块:
-
环境与硬件层
-
真机:SO-101、Koch 等机械臂,通过
robot_devices接入。 -
仿真:通过 EnvHub 加载各种环境,包括基于 IsaacLab 的 LeIsaac 场景。
-
-
数据采集层
-
遥操作(teleoperation):人用 Leader 臂、手柄、VR 等控制机器人。
-
录制(record):把机器人状态、动作、相机图像等保存成 LeRobotDataset 格式,为后续训练做准备。
-
-
数据集层:LeRobotDataset v3.0
-
统一的 时间序列 + 多模态 数据结构,可直接被 PyTorch DataLoader 使用。
-
支持大规模、多 episode 的流式训练。
-
-
Processor 层
-
负责把“原始数据字典”转成“模型需要的张量结构”,包括归一化、裁剪、重命名字段、tokenization 等。
-
-
策略 / 模型层
-
各种基于模仿学习、强化学习或 VLA 的策略,比如 ACT、π0、π0.5、GR00T N1.5 等,可直接在 Hub 上获取或微调。
-
-
训练 & 推理流水线
-
官方提供了训练、评估、推理脚本和命令行工具,能在多 GPU 上训练,也能跑在 Jetson 等边缘设备上执行策略。
-
这一整套结构的直接结果是:
可以从“没有机器人,只有一台电脑”,一路学到“用真实机械臂做遥操作、录制数据、训练策略、再让机器人自己完成任务”。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 22
22 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)