达摩院CVPR’25|最高 91% 的视觉标记裁剪率!优化视觉语言模型推理的创新方法
作者|赵望博 阿里巴巴达摩院实习生
【CVPR 2025预讲会】系列内容
CVPR 2025预讲会系列文章来源于 DAMO 开发者矩阵与 AI Time 联合举办 CVPR 2025预讲会整理成稿,旨在帮助大家率先了解计算机视觉领域的最新研究方向和成果。
摘要
视觉语言模型(VLMs)在多模态任务中表现出色,但大型VLM在处理大量视觉token时面临效率挑战。为加速推理,我们提出Small VLM Guidance for accelerating Large VLMs (SGL)。
首先,我们通过观察发现,小型VLM的全局注意力图与大型VLM高度相似,使用小型VLM的全局注意力图指导大模型进行视觉标记裁剪,可以充分保留关键信息,用于引导视觉token剪枝既能显著减少计算量,又能保持高性能。此外,我们还引入了早退机制,仅在必要时调用大模型,进一步优化准确性与计算成本的平衡。在11个基准测试中,SGL方法实现了最高91%的视觉标记裁剪率,同时保持了竞争性的性能表现。
代码仓库:https://github.com/NUS-HPC-AI-Lab/SGL

论文背景与研究动机
随着计算机视觉(CV)和自然语言处理(NLP)的快速发展,视觉语言模型(Vision-Language Models, VLMs)在多模态任务中展现了显著的性能提升。然而,随着模型规模的增大,大型VLMs在推理阶段面临着巨大的计算开销,特别是由于视觉token的处理带来了显著的效率瓶颈。
为了缓解这一问题,近年来的研究提出了多种视觉token压缩方法,例如token合并和剪枝。然而,现有方法通常使用局部信息,例如基于单层注意力图进行token重要性评估的方法(如FastV),在低token保留比例时难以维持模型性能。但同时我们发现,如果使用全局信息,例如全层聚合的注意力图能够更准确地识别重要的视觉token,但需要完整的推理过程,无法实现加速推理的目的。
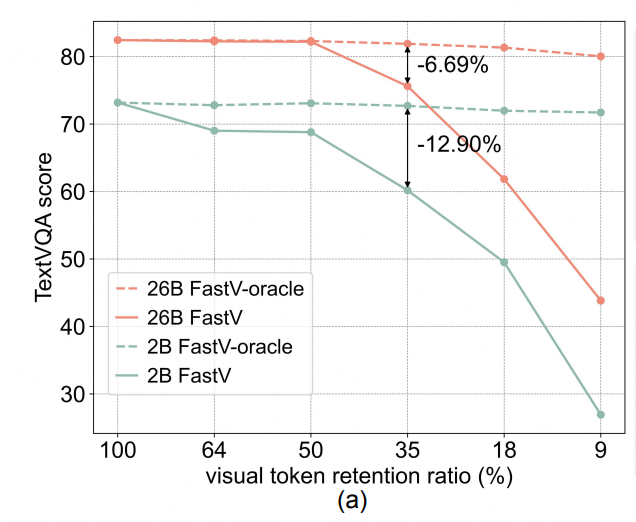
但在本研究中,我们发现小型VLM的全局注意力图与大型VLM的全局注意力图具有高度相似性,这为利用小模型指导大模型优化提供了可能。

基于上述发现,我们提出了Small VLM Guidance for accelerating Large VLMs (SGL)。具体地,我们首先设计了一种基于小型VLM全局注意力图的视觉token剪枝方法(Small VLM-Guided Pruning, SGP),无需额外训练即可在大型VLM中高效剪枝。
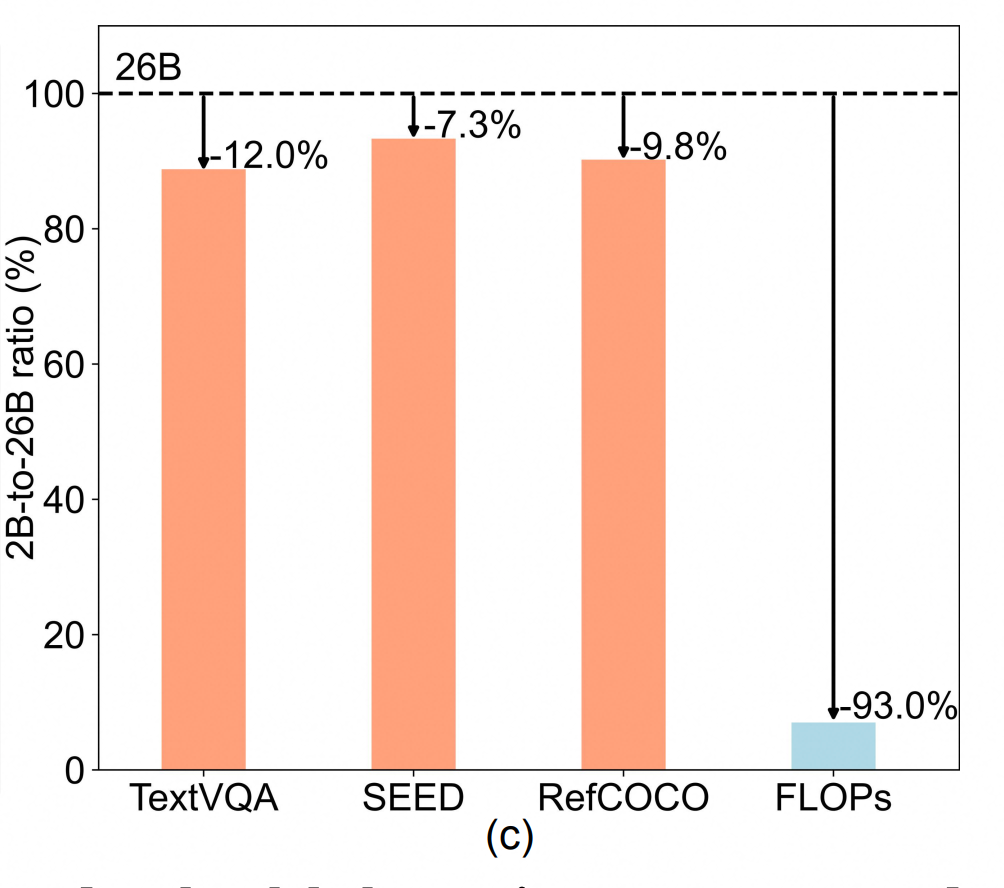
另外,我们还发现大小VLM的在各个数据集上的性能差距相比于计算量差距更加微小,这说明在很多情况下小VLM依然可以胜任预测任务,这启发我们设计了一种早退出机制(Small VLM Early Exiting, SEE),可以在小VLM对回答置信度较高时可以避免激活大VLM,进一步优化推理效率。

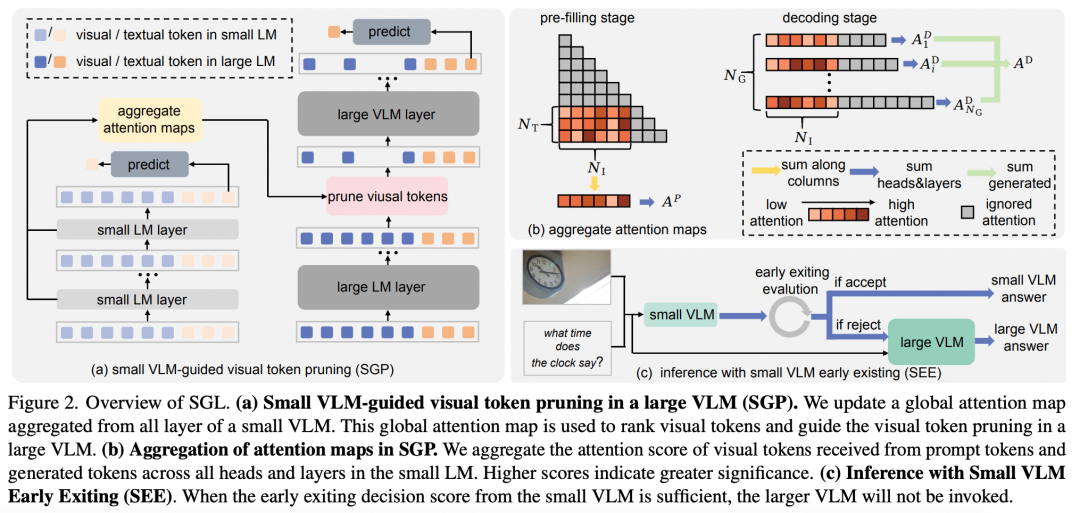
技术方法
该论文的技术方法包括两个核心组件:Small VLM-Guided Pruning (SGP) 和 Small VLM Early Exiting (SEE)。
-
Small VLM-Guided Pruning (SGP)
SGP的核心思想是利用小型VLM的全局注意力图,来指导大型VLM的视觉token剪枝,主要分为两步:
-
全局注意力图的生成,小型VLM通过其所有层的注意力图聚合,生成一个全局注意力图,用于评估每个视觉token的重要性。在预填充阶段(pre-filling stage),从每一层的注意力头中提取视觉token与文本token的交互权重。在解码阶段(decoding stage),聚合生成token与视觉token的交互权重。
-
最终将预填充阶段和解码阶段的注意力信息相加,形成完整的全局注意力图。全局注意力图中的重要性评分用于对视觉token排序,并根据保留比例(如5%、9%等)剪除不重要的token。
2. Small VLM Early Exiting (SEE) SEE的目标是通过早退出机制减少大型VLM的调用次数, 主要分为三步:
-
置信度评估:小型VLM在生成预测结果后,计算其预测的置信度分数(如基于生成序列概率的长度归一化得分)。
-
一致性检测:在小型VLM生成结果的基础上,对剪枝后的视觉token进行推理,计算结果的一致性分数。
-
退出决策:将置信度分数和一致性分数结合起来,当综合得分超过设定阈值时,直接使用小型VLM的预测结果,否则调用大型VLM进行完整推理。

实验设计与结果分析
论文在多个基准任务上验证了SGL方法的有效性,包括视觉问答(VQA)、视觉定位(Visual Grounding)和综合多模态理解任务。以下为实验的关键结果:
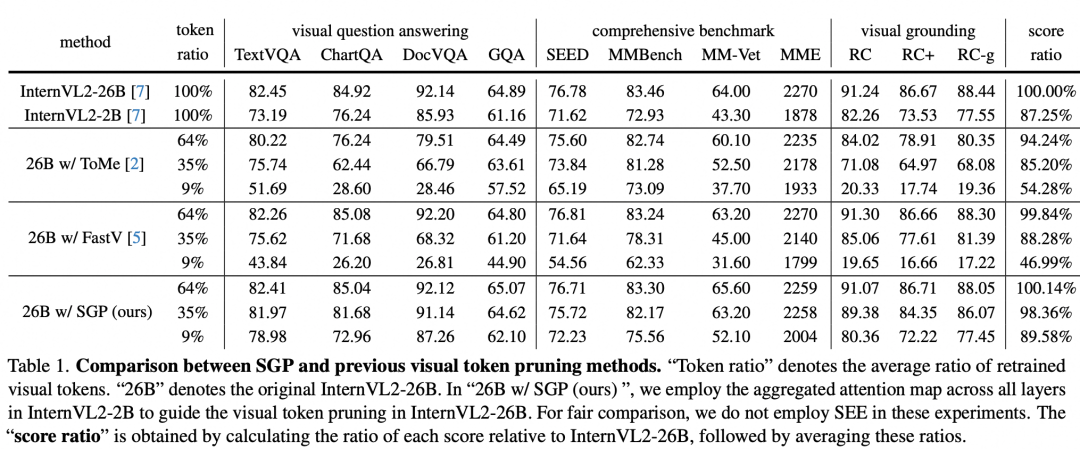
与现有方法比较视觉token剪枝性能:与FastV和ToMe等方法相比,SGP在低token保留比例(如9%)下显著优于其他方法。例如,在TextVQA任务中,SGP在仅保留9%的视觉token时,依然能够保持89%的原始性能,而FastV和ToMe的性能则大幅下降。
效率提升:通过结合SEE机制,SGL方法在多个任务中实现了更高的推理效率。例如,在RefCOCO任务中,与仅使用SGP相比,结合SEE后推理时间显著减少。
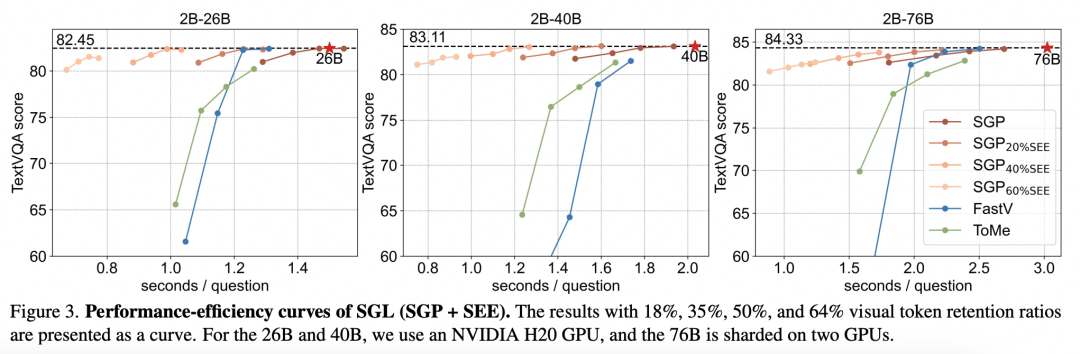
论文通过可视化结果进一步验证了SGL方法的有效性:SGP能够在不同保留比例下优先保留与问题相关的重要视觉token,从而保证模型的预测准确性。即使小型VLM的预测结果错误,其全局注意力图依然能够准确识别目标区域,帮助大型VLM进行更精确的推理。
与FastV对比时发现,FastV在低保留比例下难以保留关键视觉token,而SGP则能够在极端剪枝情况下(如9%保留比例)依然保持较高的性能。


结论
本论文通过系统研究发现,小型VLM的全局注意力图能够高效指导大型VLM的视觉token剪枝,并提出了结合剪枝与早退出机制的SGL方法。实验结果表明,SGL在保持性能的同时显著降低了推理成本,展现了其在多模态任务中的广泛适用性。
未来,我们可以在该论文的基础上尝试以下探索方向:
-
生成任务的扩展:未来可以探索SGL方法在结合理解与生成能力的多模态模型中的应用。
-
更小规模模型的探索:论文发现1B规模的小型VLM在某些任务中表现优于2B模型,这表明进一步减小小模型规模具有潜力。
-
动态剪枝策略:结合任务上下文信息动态调整剪枝比例,进一步提升模型的适应性和效率。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 0
0 0
0- 0



 已为社区贡献120条内容
已为社区贡献120条内容

所有评论(0)