CVPR'25 highlight|ASUKA:提升图像修复稳定性,减轻幻觉生成和维持色彩一致性
作者|王艺楷、曹辰捷等(复旦大学,阿里巴巴达摩院)
【CVPR 2025预讲会】系列内容
CVPR 2025预讲会系列文章来源于 DAMO 开发者矩阵与 AI Time 联合举办 CVPR 2025预讲会整理成稿,旨在帮助大家率先了解计算机视觉领域的最新研究方向和成果。
摘要
本文提出的ASUKA(Aligned Stable Inpainting with UnKnown Areas prior)是针对图像修复技术(Image Inpainting)的新方法,旨在解决物体移除任务中的幻觉生成和色彩不一致两大问题。当前的生成模型常在mask区域生成无关对象,且修复后的颜色往往不一致,影响图像质量。通过引入掩码自编码器(Masked AutoEncoder, MAE)修复先验和专门设计的变分自编码器(VAE),ASUKA有效缓解了幻觉生成,同时保持色彩一致性。我们在不同数据集上验证了ASUKA的性能,结果表明其显著优于现有技术。
论文标题:Towards Enhanced Image Inpainting: Mitigating Unwanted Object Insertion and Preserving Color Consistency
论文链接:https://arxiv.org/abs/2312.04831
项目链接:https://yikai-wang.github.io/asuka/

图1. 通过注入MAE特征和VAE改进,所提出的ASUKA能够在高分辨下实现高质量且稳定的物体移除效果。

图像修复的显存问题与挑战
图像修复旨在通过图像生成模型填补mask区域,保持与unmask区域的一致性。传统算法容易导致模糊现象,基于生成对抗网络(GAN)的模型虽然在填充复杂结构时有所突破,但在处理大面积孔洞时仍面临挑战。尽管近期基于扩散模型(diffusion model)的方法,例如Stable Diffusion和FLUX,展现了其强大生成能力,它们仍然存在一些潜在问题:
-
由于diffusion生成模型基于随机噪声(noise)生成目标结果,因此可能导致生成前景存在不合理、随机的元素,影响物体移除的效果。
-
基于latent feature的局部生成模型往往由于隐空间的对齐不足以及VAE的损失产生了难以忽略的色差问题。
尤其是在实际应用中,二者均显著影响了修复图像的质量。因此,迫切需要新方法以提高图像修复技术的可靠性和表现力。为此,本文提出了ASUKA,同时结合了MAE的重构特征先验以及VAE的增强改进来解决两大难题。

方法总览
ASUKA通过两个核心组件对图像修复进行改进:上下文的稳定性对齐和色彩一致性对齐。
1. 上下文的稳定性对齐
传统的回归损失以及表征学习MAE虽然能够得到稳定的修复结果,但是重建的pixel由于回归损失趋于平均,造成模糊的结果。而以diffusion model为代表的方法,例如SD以优化分布为核心,不明确使用pair对的重构损失,结果清晰质量高。然而,其生成结果从随机噪声出发,生成结果不稳定存在随机性。这在需要稳定生成的物体移除环境下表现不佳,ASUKA结合了两类方法的优势,兼顾了高质量生成和稳定的物体移除。
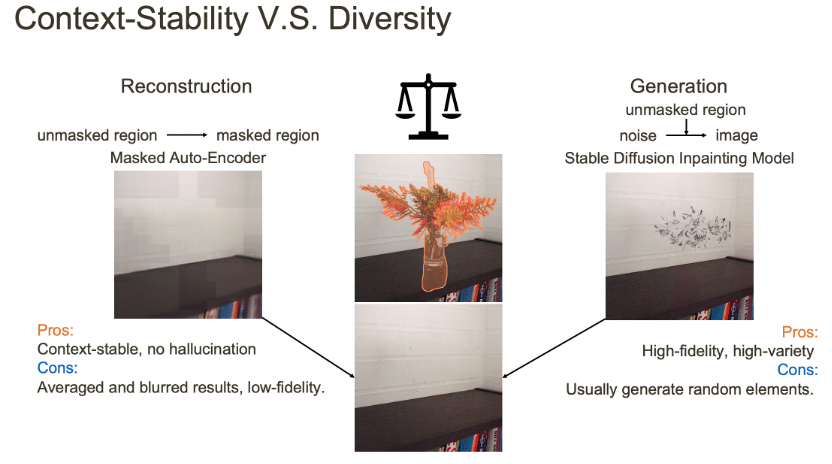
图2. 生成稳定性 vs 多样性。传统的回归损失和MAE预训练受限于稳定、模糊的生成结果,而diffusion模型质量虽高,却存在幻觉问题。我们的方法结合了两者各自的优势。
ASUKA的架构非常简洁,以latent diffusion架构为基础。同时输入图片会被resize并且mask后输入到MAE,取出对应的MAE特征以一个alignment模块注入到U-net中。除了Alignment模块其余模型都是固定的。
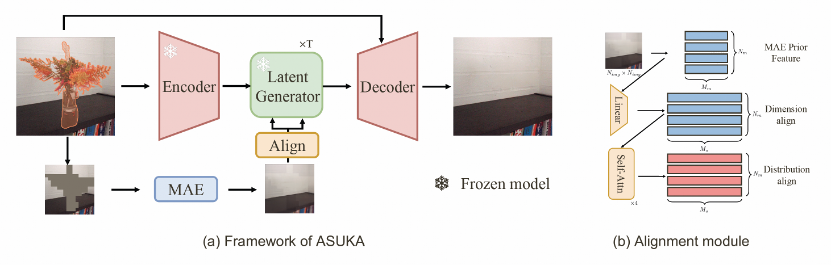
图3. (a) ASUKA模型架构图。(b) alignment模块的构造细节。首先从MAE的最后一层特征取出了对应的token feature。我们首先使用一层MLP对特征进行维度对齐,随后通过4层self-attention进行特征分布的学习。
2. 色彩一致性对齐

图4. 图像修复中的色差问题说明。
我们将图像修复中出现的色彩不一致问题归类为两大原因,分别是:
1)VAE信息损失,2)diffusion信息损失。
为了验证VAE的信息损失,首先进行了如下图的验证实验,并证实:VAE天然存在一定低频色彩偏差。为此,我们提出了利用色彩数据增强(color jittor)来微调VAE的decoder部分。
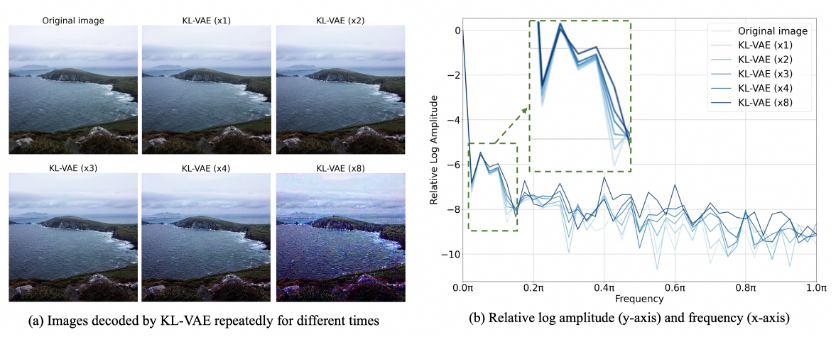
图5. (a) 反复VAE编解码多次后,色彩偏差的问题会逐渐加剧。(b) 经过VAE编解码后,输出空间的低频信息有一定的退化。
此外,我们发现基于diffusion U-Net输出的隐空间特征天然存在一定色差偏移。因此,在微调VAE的时候,显式地模拟了diffusion的色差。整体VAE的训练框架如下图所示。
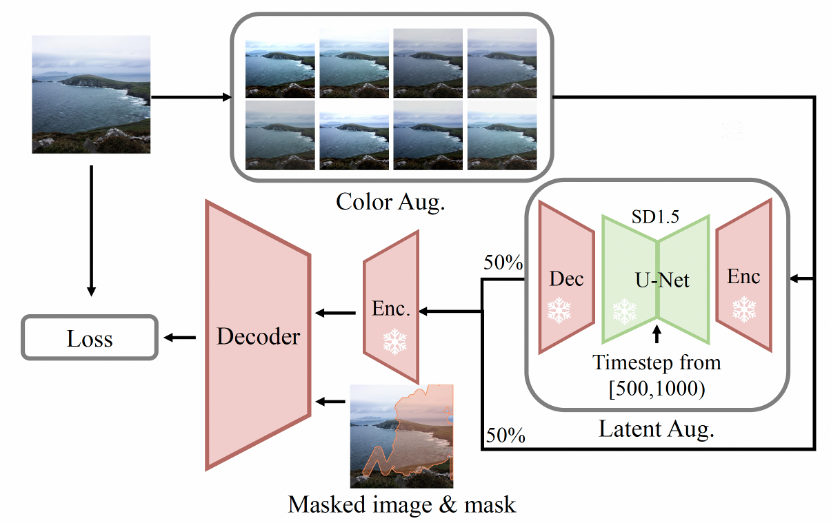
图6. 以局部和谐化的目标来增强VAE的decoder微调。输入图片会随机经过色彩增强和隐空间增强以增加训练难度。


图7. 微调后的VAE能够显著改善图像修复中的色差问题。

实验结果
和先前的方法一样,我们在places2数据集上进行了验证。此外,为了能够更进一步检验算法的能力,还从大量室内外开源数据中构建了一个没有前景的场景图片验证集MISATO(Matterport3D, Flickr-Landscape, MegaDepth, COCO2014)。在多个数据集上的实验验证表明,ASUKA显著减轻了对象幻觉并提高了色彩一致性,较先前的图像修复方法有明显优势。

图8. 定性图像修复比较。所提的ASUKA能够取得稳定的物体移除效果。
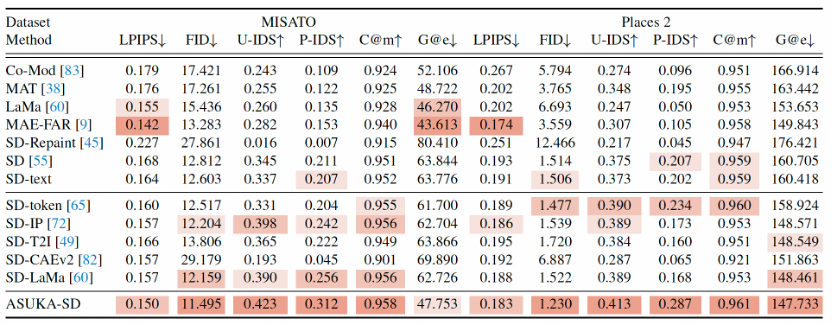
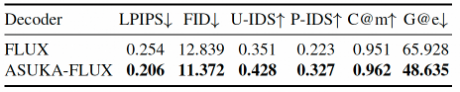
表1. 定量图像修复实验。所提算法能够基于SD和FLUX取得显著提升。

总结
本文所提出了ASUKA通过解决上下文的稳定性对齐和色彩一致性对齐两大问题,提升了图像修复的效果。然而,和所有基于self-attention的算法一样,该方法在面对密集物体场景的移除时也可能会失效,如下图所示。虽然调整MAE的注入信息可以解决问题,但是探索一种更加泛化的密集场景物体移除的方案会是一个有趣的研究方向。

图9. 展示了一个有趣的探索。我们发现所有基于self-attention的模型在处理稠密物体的移除时效果都很差。这里包括SD,FLUX,MAE这些有self-attention的模块。他们都会关注到临近的物体,并补全出类似的物体。我们的方法基于原本的MAE也会失败,但是把MAE的输入修改为一张纯白的图片,就可以有效移除了。这也说明了MAE alignment的有效性。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 0
0 0
0- 0



 已为社区贡献120条内容
已为社区贡献120条内容

所有评论(0)