达摩院 CVPR'25 |告别人工标注,无监督同行评审如何精准评估多模态大语言模型?
作者|张祺珲,阿里巴巴达摩院实习生
【CVPR 2025预讲会】系列内容
CVPR 2025预讲会系列文章来源于 DAMO 开发者矩阵与 AI Time 联合举办 CVPR 2025预讲会整理成稿,旨在帮助大家率先了解计算机视觉领域的最新研究方向和成果。
摘要
多模态大语言模型(Multimodal Large Language Models, MLLMs)在视觉问答(Visual Question Answering, VQA)领域取得突破性进展的同时,也引发了学界对模型客观评估方法的新一轮探索。
现有评估机制受限于人工设计图文问答对所需的巨量标注成本,这种固有缺陷严重制约了评估规模和覆盖范围的扩展。尽管基于MLLMs自动评判的评估方案试图通过模型间互评降低人力消耗,但又往往引入新的评估偏差。
针对这些挑战,我们提出了一种创新的无监督评估框架——无监督同行评审多模态大语言模型评估体系(Unsupervised Peer review MLLMs Evaluation framework, UPME)。该框架仅需原始图像数据作为输入,通过引导模型自主生成问题并开展跨模型的同行评审式答案评估,有效突破传统评估方法对人工标注的依赖瓶颈。进一步地,我们构建了融合视觉-语言评分系统,从三个维度构建评估标准:(i) 回答正确性;(ii) 视觉理解与推理能力;(iii) 图文匹配相关性。实验表明,UPME在MMstar数据集上与人工评估的皮尔逊相关系数达到0.944,在ScienceQA数据集上达到0.814,验证了该框架与人类设计的问答基准及内在评估偏好的高度一致性。
论文链接:https://arxiv.org/abs/2503.14941

引言
如果我们想要对若干个多模态大预言模型进行评估和排名,当下有三种主流的方法,第一种是专门设计一个benchmark,但是这种方法有可能面对数据泄露或污染、人工打标时间长的问题;第二种是利用模型作为评估器来评估其他模型,但是这种方法会引入模型的冗长偏好、自我偏好等偏见;第三种是构建一个众包平台,利用人类反馈进行排名得分,但这种方法成本高,还面临冷启动问题。
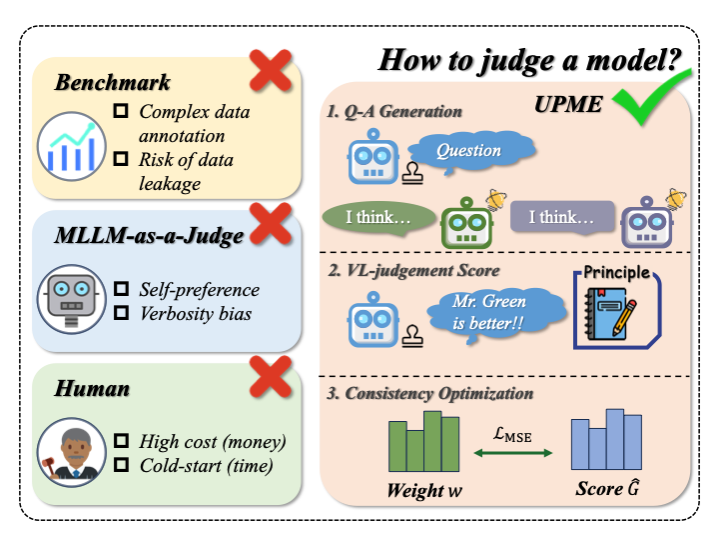
基于以上三种方法的限制,我们提出了一种无监督的同行评审机制,赋予每个模型一个可学习的参数
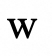
代表模型的评估置信度;然后根据模型的回答和获得的评价,计算每个模型的得分
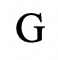
代表模型的能力分数;之后最大化
和
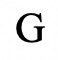
之间的一致性。
这篇论文的主要贡献:首次探索无监督的MLLMs评估,并提出一种基于一致性假设的约束优化方法以及视觉-语言评分系统,同时在两个数据集上验证了方法的有效性。
国内外的相关研究也是分为刚刚提到的三个维度。Benchmark有ScienceQA、MMStar、RealworldQA等评估方法;人类评估有LMSYS、Ziems等方法;模型的自动化评估也有MLLM-as-a-Judge、PRD、PRE等方法。

方法
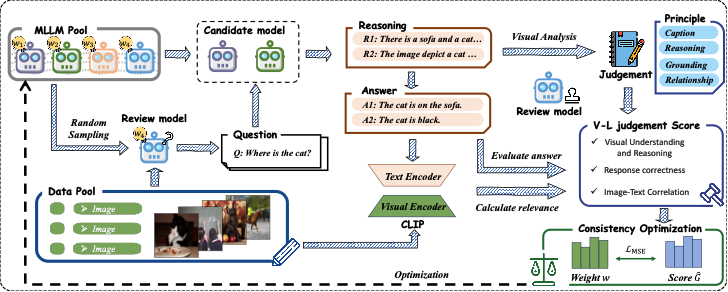
首先是问题的定义,同行评审的目的是为了让MLLMs得到的评估结果与人类偏好高度一致,即让
和
![]()
的相似性尽可能的高。在每次审查迭代中,会从模型池中随机选择两个不同的候选模型进行比较,同时选择另一个模型作为审查员,审查员为每幅图像生成一个问题,然后提示候选模型分别提供回答,并计算得分。

本文提出的视觉-语言评分系统主要从三个维度进行评估:
-
回答正确性:主要标准是候选模型对评审模型所提问题的回答是否正确;
-
视觉理解与推理评估:该模型在视觉内容方面的解释和分析能力。
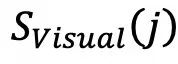
是通过函数
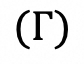
计算得出的,该函数评估了四个维度的响应:Captioning、Reasoning、Grounding和 Objecting relationship;
-
图像文本匹配度:为了获取图像内容和模型文本响应之间的对齐方式

将上述分数计算后进入动态权重优化阶段,主要是希望最大化每个模型的权重和得分之间的一致性。也就是说,计算得分时会考虑给他打分的模型本身的能力,同时利用这个分数去优化模型自身的权重,用于下一轮的评估。
此外,也尝试引入了一个方法来解决常见评分遇到的分数膨胀问题——Elo机制,来访时某个模型不断击败较弱的对手来快速积累分数。
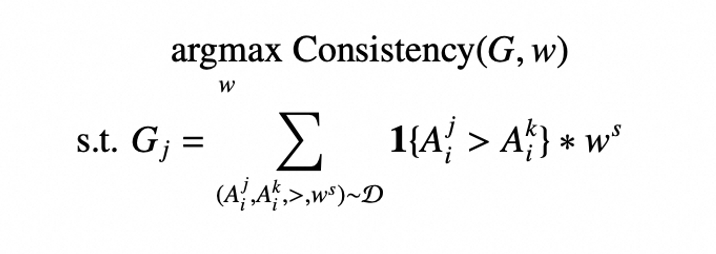

实验
我们选择了上文提到的两个数据集,ScienceQA和MMStar,这两个数据集可以同时检验模型的思维推理能力和纯视觉能力。同时,也选择了五个闭源模型和一个开源模型作为候选模型。
采用了三种常用的指标:皮尔森相关系数、斯皮尔曼相关系数和排列熵。所有实验都使用了不同的随机种子运行四次,并记录平均结果。
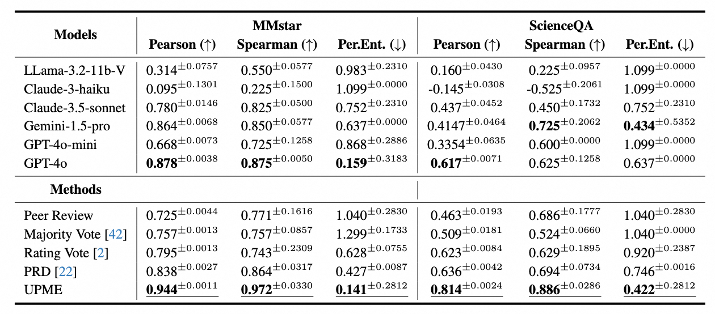
实验结果表明,最初的同行评审方法得出的结果低于 GPT-4o,这表明较弱模型的偏差影响了同行评审方法。在 MMstar 数据集上,UPME 方法达到了 0.944 的Pearson和 0.972 的Spearman ,这表明它与人类注释高度相似,并验证了我们在视觉质量保证理解和一致性评估方面的优化效果。
虽然在ScienceQA上的性能没有那么高,但像ScienceQA这样的传统数据集可能并不完全符合当前MLLMs的评估需求,因为它们可能缺乏视觉依赖性或足够的区分度。但方法也实现了更高的Pearson和Spearman,证明了其稳健性和卓越性能。
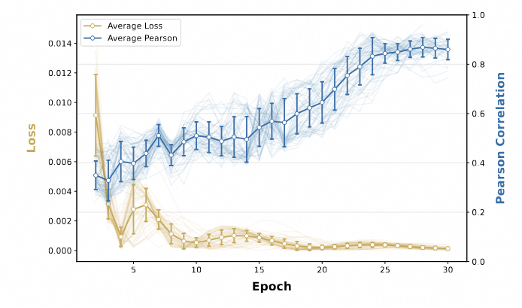
此外,如上图所示,在64个不同的初始设置中,损失持续减少,皮尔森相似度指标随时间推移而增加,这证明了
和
的收敛性。在当前的实验设置下,该框架能在 30 个epoch(约3~4个小时)内可靠收敛。
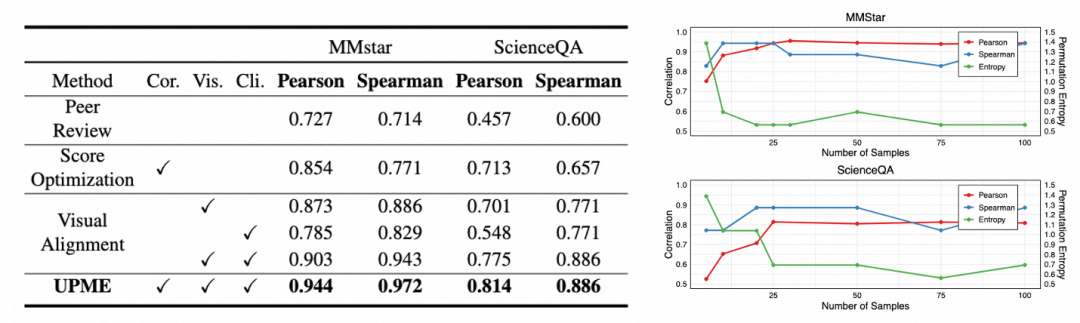
此外,也有消融实验逐步评估不同组件对模型的影响。可以看到评分优化的组件和视觉对齐的组件分别能够提升整体的效果。同时,也探索了样本大小对结果的影响,做了额外的收敛实验,证明模型在25个图像时已经可以收敛。

与人类偏好的对齐
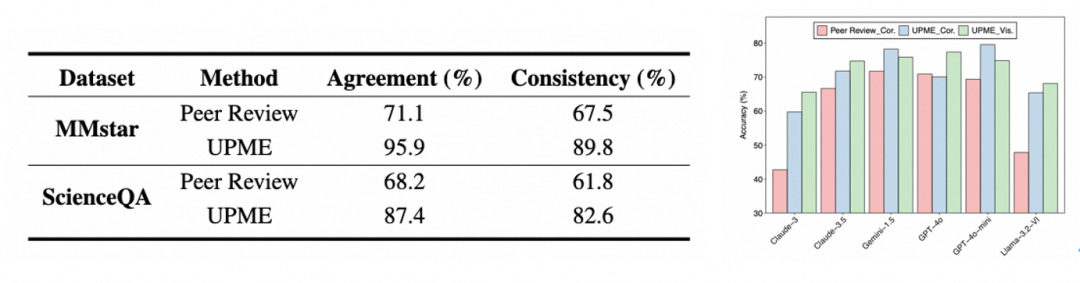
为了验证方法在没有人工标注的情况下是否能与人类偏好一致,基线方法的人类一致性和模型一致性均较低,这表明在无权重优化和无监督设定下的Peer Review机制难以实现人类偏好的对齐。
UPME能够显著提高评估结果的准确性和与人类偏好的对齐程度。在不依赖人工标注的情况下,通过对多模态理解关键指标的捕捉,实现了与人类打标高度一致的效果。
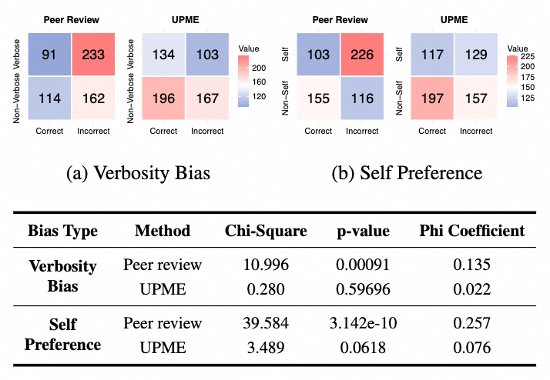
这个实验是为了验证方法对缓解冗长偏好、自我偏好的问题。原始的Peer Review方法的p < 0.05,表明在评估中对冗长回答的偏好具有显著性;相比之下,UPME框架的p > 0.05,说明其对选择冗长回答并无显著偏好。
此外,卡方分布和Phi系数也显著降低,进一步表明冗长文本与正确选择之间的相关性显著减弱。因此,UPME方法有效减轻了多模态模型对冗长文本的偏好,提升了在无监督设定下的评估多样性和对人类偏好的对齐度。自我偏好偏差也是类似,得到了显著缓解。
之后我们选择了三个案例来说明方法是如何有效解决传统 MLLMs-as-a-judge中的核心问题,分别是“评估模型自身能力的不足”、“模型的冗长偏好”和“模型的自我偏好”。

总结
本研究提出了一种基于无监督同行评审的框架 UPME,有效减少了传统人工设计的问答基准中的标注工作量。我们的视觉语言评分系统强调以视觉为导向的判断,解决了“多模态大语言模型作为评判者”的评估方法中固有的冗长性和自我偏好偏差等问题。进一步的实验验证,评估结果与人类偏好实现了更高的一致性,提供了一种有前景且可靠的方法。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 0
0 0
0- 0



 已为社区贡献120条内容
已为社区贡献120条内容

所有评论(0)