自动驾驶---阿里巴巴之AutoDrive-R²(VLA)大模型
阿里高德地图团队提出AutoDrive-R²VLA大模型,通过思维链与强化学习提升自动驾驶的推理与自反思能力。该模型基于Qwen2.5-VL构建,采用两阶段训练:先在自建nuScenesR²-6K数据集(含6000个带推理步骤的样本)进行监督微调,再结合物理奖励框架优化轨迹生成。在nuScenes和Waymo数据集测试中,模型在轨迹精确度和合理性上超越现有方法,但输出轨迹仍较粗糙,需进一步优化控制
1 前言
熟悉阿里巴巴的朋友应该了解,阿里旗下的自动驾驶团队也有不少,比较知名的是阿里达摩院下的自动驾驶团队,另外还有两个,一个是高德地图下面的团队,还有一个是菜鸟下面的团队。
达摩院下的自动驾驶团队在近几年的变化时间线如下所示:
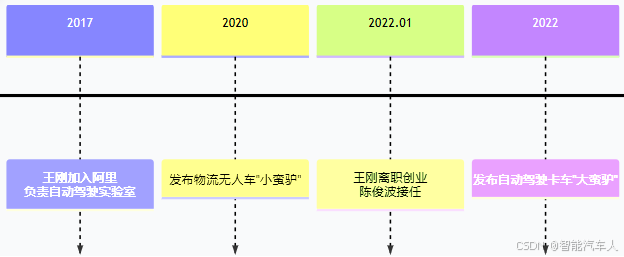
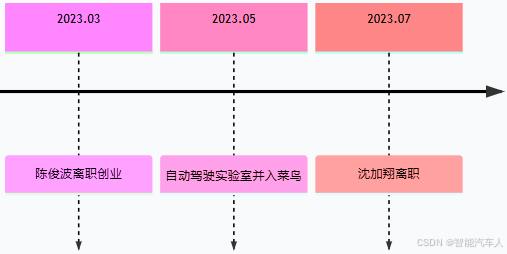
最后,达摩院自动驾驶团队并入菜鸟集团后,其工作重心将紧紧围绕菜鸟的实际物流落地需求展开,例如仓储运输、长途干线和末端配送等。这意味着技术研发将更侧重于解决实际场景中的具体问题,追求技术的商业化应用和盈利能力。
本篇博客,主要介绍阿里高德地图团队的研究成果:AutoDrive-R² VLA大模型。该模型在自动驾驶开环测试结果中体现了不错的能力。
2 AutoDrive-R²
现有自动驾驶 VLA 方法存在轨迹生成框架常产生物理不可行输出等问题,决策过程的可解释性、连贯性以及动作序列的合理性仍未得到充分研究。为解决这些问题,研究团队提出了 AutoDrive-R² 框架。
AutoDrive-R² 是阿里巴巴和昆士兰大学等团队提出的一种新型视觉 - 语言 - 动作(VLA)框架,该框架通过思维链处理与强化学习,同时增强自动驾驶系统的推理与自反思能力。
2.1 模型架构
轨迹规划任务的目标是要求模型基于车辆的历史传感器数据和环境信息,预测其未来运动状态。给定一段车辆历史状态序列 H(包括位置、加速度、速度、转向角等信息)及其摄像头图像 F,模型 M 需输出未来 3 秒内、时间间隔为 0.5 秒的预测鸟瞰图(BEV)轨迹坐标 T,其数学表达式定义为:。
(1)输入
摄像头信息 + 车辆历史状态。
(2)模型
Qwen2.5-VL为基座模型,后续训练得到AutoDrive-R²。
(3)输出
未来一段时间内(3s)的轨迹 + 推理信息。
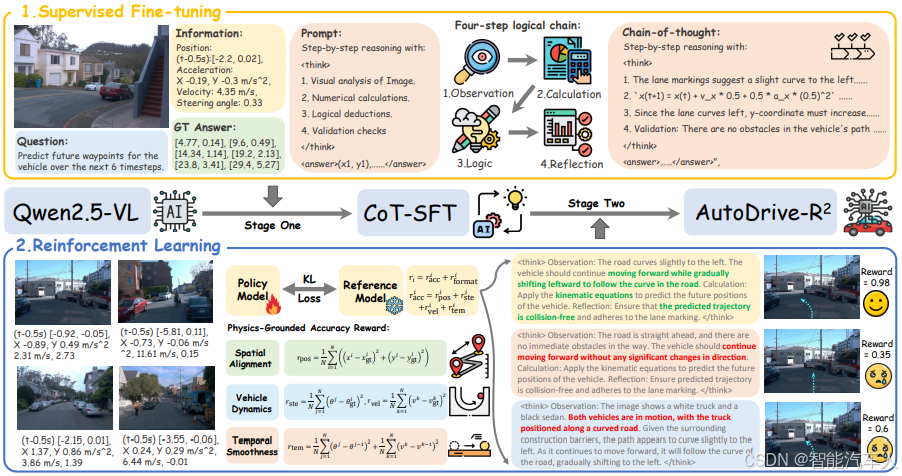
2.2 训练与评估
- 构建全新 CoT 数据集:团队构建了用于监督微调 SFT 的全新 CoT 数据集 nuScenesR²-6K。该数据集包含 6000 个 “图像 - 轨迹” 样本对,每个样本对均包含一张前视图图像和一段时长 3 秒、时间间隔为 0.5 秒的轨迹规划数据。它不仅提供真值轨迹,还包含推理与自反思步骤,确保驾驶行为的正确性与因果合理性,是自动驾驶领域首个同时激发 VLA 模型推理与自反思能力的数据集。
- 采用基于物理的奖励框架:为在强化学习(RL)阶段最大化模型的推理与自反思能力,团队在基于物理的奖励框架内采用组相对策略优化(GRPO)算法。该奖励框架整合了空间对齐、车辆动力学与时间平滑性准则,以确保轨迹规划的可靠性与真实性,使强化学习能够适应不同驾驶场景与车辆动力学特性,同时保证轨迹的物理可行性与行驶舒适性。
(1)训练阶段
基于 nuScenesR²-6K 数据集对 Qwen2.5-VL-7B 模型进行监督微调(SFT),以建立基础感知能力。
训练过程包含两个阶段。在第一阶段,为实现 “冷启动”(cold start,指模型从初始状态开始学习的过程),我们构建了高质量数据集 nuScenesR2-6K。该数据集通过包含 “自我反思”(self-reflection,用于验证环节)的四步逻辑链,在输入信息与输出轨迹之间搭建 “认知桥梁”(cognitive bridges,即建立两者间的关联逻辑)。在第二阶段,我们采用基于物理的强化学习框架,该框架整合了空间对齐、车辆动力学及时间平滑性准则,以确保生成的轨迹具备物理可行性与安全性。
步骤如下:
采用两阶段训练流程,具体如下:
第一阶段引入了一个创新的思维链(CoT,Chain-of-Thought)数据集,名为 nuScenesR²-6K,用于有监督微调(SFT,Supervised Fine-Tuning)。该数据集通过包含 “自我反思”(self-reflection)的四步逻辑链,生成具有价值的思维链数据 —— 即数据生成过程中包含明确的推理逻辑,而非单纯的输入输出对应关系。
第二阶段在 GRPO 算法(一种强化学习优化算法)的框架下,提出了一种新颖的 “基于物理的奖励机制”(physics-grounded reward framework)。该机制整合了空间对齐、车辆动力学及时间平滑性三大核心准则,最终实现可靠的轨迹规划。
(2)评估阶段
在 nuScenes 和 Waymo 两个数据集上进行测试。nuScenes 数据集包含 1000 个城市驾驶场景,配备 6 个同步摄像头视角以支持规划任务;Waymo 数据集包含 4021 个驾驶片段,涵盖 8 个摄像头视角和自车轨迹数据。实验结果表明,AutoDrive-R² 实现了最先进的性能,在多个指标上超越了现有领先方法。
2.3 测试结果
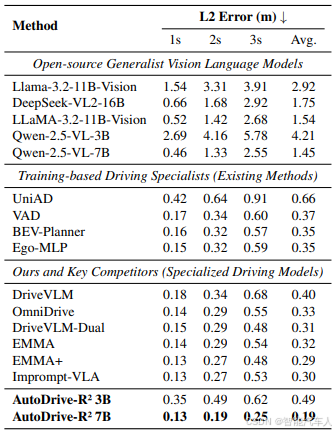

可以看到,最终训练出的模型得到的轨迹比原始的Qwen2.5-VL要精确很多,同时也变得更加合理了,但是这种轨迹有一个缺点就是无法直接给到控制模块,比较粗糙。
3 总结
阿里高德地图团队提出AutoDrive-R² VLA大模型,通过思维链与强化学习提升自动驾驶的推理与自反思能力。该模型基于Qwen2.5-VL构建,采用两阶段训练:先在自建nuScenesR²-6K数据集(含6000个带推理步骤的样本)进行监督微调,再结合物理奖励框架优化轨迹生成。
在nuScenes和Waymo数据集测试中,模型在轨迹精确度和合理性上超越现有方法,但输出轨迹仍较粗糙,需进一步优化控制接口。研究聚焦解决自动驾驶决策可解释性与动作连贯性问题。
参考文献:《AutoDrive-R²: Incentivizing Reasoning and Self-Reflection Capacity for VLA Model in Autonomous Driving》

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)