达摩院ICCV'25|AnimateAnyMesh实现任意拓扑网格的高效文本驱动动画
作者|吴子杰 阿里巴巴达摩院实习生
摘要
本文提出了一种前馈式的文本驱动通用网格动画生成网络,能够在数秒内根据文本描述生成具有不同拓扑结构和分辨率的高质量网格动画序列。该方法直接在顶点层面建模运动变化,探索了基于顶点运动预测的生成方式。为支持文本到网格动画的训练与评估,本文还构建了一个包含超过400万段动态网格序列的大规模数据集 DyMeshDataset,为4D内容生成的研究提供了新的数据资源。
论文题目:《AnimateAnyMesh: A Feed-Forward 4D Foundation Model for Text-Driven Universal Mesh Animation》
项目主页:https://animateanymesh.github.io/AnimateAnyMesh/
代码仓库:https://github.com/JarrentWu1031/AnimateAnyMesh
论文链接:https://arxiv.org/abs/2506.09982

图1:AnimateAnyMesh驱动示例,其能够非常真实地驱动人物、动物、植物、组合物体等物体

背景
1.1 任务设置
本文聚焦于动态网格动画(Mesh Animation)的生成任务。该任务旨在根据给定的控制信号(如文本),自动生成一段时序连贯、动作自然、细节丰富的3D网格动画。传统的动画制作流程依赖于艺术家繁琐的手动绑定、K帧与雕刻,成本高昂且周期漫长。本方案的目标是开发一个高效的自动化模型,使其能深度理解输入信号的语义,并将其直接转化为高质量的三维动态序列,从而为影视、游戏和元宇宙等领域的内容创作提供技术支持。
1.2 相关方法
传统的mesh animation可以分为两大类:基于骨骼的绑定方案与直接的网格变形方案。
-
骨骼绑定方案 (Skeletal Rigging)通过在模型内部预定义骨架,并与网格的顶点关联,然后控制骨架的关键帧来驱动角色运动。
-
网格变形方案 (Mesh Deformation)则是通过数学算法在保持mesh局部形状的前提下直接或间接地操纵网格的几何形状,代表方法有ARAP[1]等。
前者对于不常见类别及非刚性物体等效果较差,而后者则需要大量的人力调控。近期,也有一些基于SDS[2]的驱动方案(DG4D[3])以及multi-view videos生成方案(Animate3D[4]),但它们均不能直接前馈驱动任意mesh,驱动效果也较为有限。

本文方案
2.1 研究动机
现有的4D内容生成方法,无论是基于单场景优化的方案还是多视角视频生成方案,在生成效率、时空一致性与可控性上都面临着显著挑战。前者依赖SDS 等技术,通常计算成本高昂且结果不稳定;后者虽然提升了推理速度,但其对渲染视图的依赖而非真实的4D数据,不仅引入了视图间的不一致性,也因繁琐的后处理流程而难以实现实时应用。
鉴于这些局限性,本文设计了一种动态网格变分自编码器DyMeshVAE。通过轨迹分解和拓扑感知注意力机制,DyMeshVAE能够将复杂的动态网格高效地压缩为固定长度的潜空间表征,为后续基于流模型的生成过程提供了高质量的输入。
这一设计不仅保证了动画的高保真度和对任意网格的普适性,也为实现高效、实时的文本到4D动画生成奠定了基础。同时,鉴于目前动态mesh序列数据集的缺失,本文提出了DyMesh数据集,其由超过4M段16/32帧动态mesh序列构成,为4D生成提供了坚实基础。
2.2 DyMeshVAE
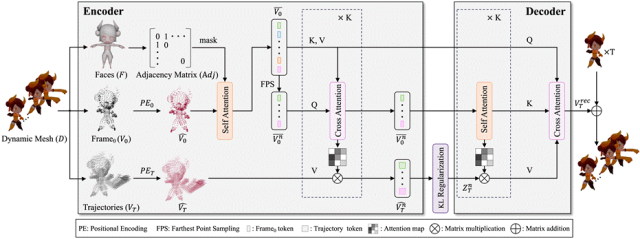
图2:DyMeshVAE架构
DyMeshVAE的架构如上图所示。其设计的核心主要有三点:
a. 动静解耦
b. 拓扑感知邻域Attention
c. 顶点-轨迹JointAttention
a.动静解耦:
DyMeshVAE的输入是动态的Mesh序列
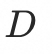
,其由两部分组成:
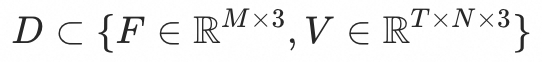
,其中F代表mesh faces,
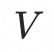
代表动态mesh序列的顶点轨迹,其中N为顶点数目。首先,顶点轨迹
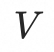
会被解耦为第一帧顶点坐标
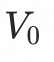
以及相对轨迹
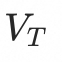
。
这样做的目的有三点:第一,与推理阶段对齐,推理阶段我们只有初始帧的顶点坐标;第二,更好利用动态mesh序列形状和动作解耦的特性,避免两者的模糊;第三,减去第一帧顶点坐标的相对轨迹天然近似0均值的高斯分布,网络更容易学习。
b.拓扑感知邻域Attention:
轨迹粘连是mesh animation任务一个很重要的问题。如图3所示,图中人物初始帧帽檐的顶点和手部顶点距离很近,但是很显然它们属于不同的语义部分,运动相关性应该较低,如果相关性过高则会造成粘连。
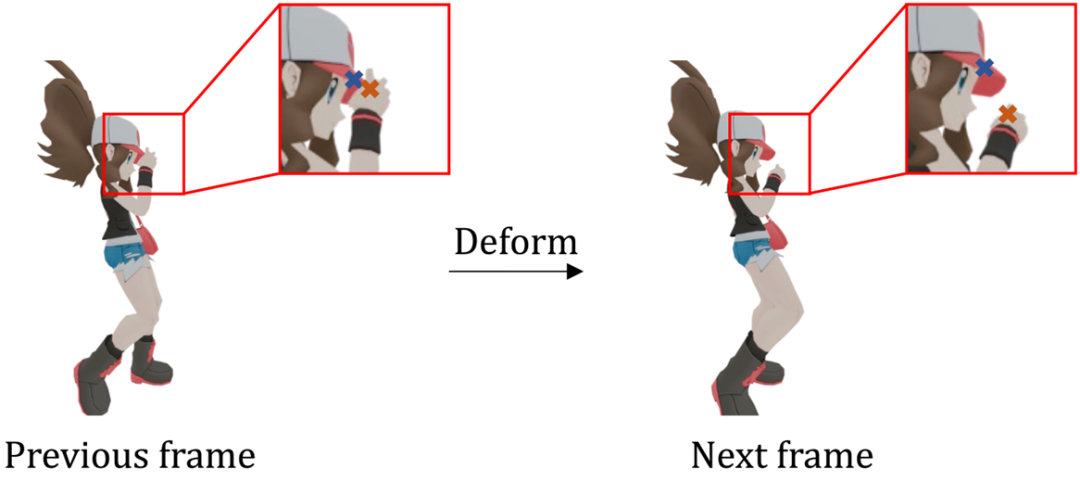
图3:轨迹粘连问题示意图(图中未发生粘连)
如何合理地编码顶点特征,既能够挖掘潜在的运动相关性,又能够避免轨迹粘连,便成为了关键的问题。基于绝大多数物体的局部刚性规律,连接关系更近的顶点天然具有更强的运动相关性。
基于上述结论,本文利用初始mesh的faces信息得到顶点的连接矩阵
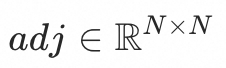
,并使用该连接矩阵作为attention mask来通过self-attention layer聚合每个顶点的邻域信息,称之为拓扑感知邻域Attention。这样既增强了相隔跳数较近顶点特征的相似性,又由于邻域信息的引入,使得图3示例中欧式距离较近但测地线距离较远的顶点被编码成的特征差异加大,从而解决轨迹粘连的问题。
c. 顶点-轨迹JointAttention:
本文任务为静态mesh驱动,在测试阶段只有第一帧的mesh,而没有运动轨迹的gt;经过拓扑感知邻域Attention增强后的顶点特征能够很好表达初始帧顶点的距离/相邻关系,更相似的增强顶点特征往往有更强的运动相关性,本文设计了一种顶点-轨迹的JointAttention机制。
其核心操作在于:通过对增强后的顶点特征计算Cross-Attention/Self-Attention,得到Attention map后同步映射对应的相对轨迹特征,来得到处理后的顶点-轨迹特征。如图2所示,除了第一层拓扑感知邻域Attention以及最后一层Cross-Attention,DyMeshVAE中的其他attention layer均为上述顶点-轨迹JointAttention结构。这样尽可能地将物体局部运动的相似性先验编码进了轨迹特征,降低了网络学习的困难程度,从而获得了更好的重建效果。
2.3 Text-to-Trajectory Retified Flow Model
在DyMeshVAE将变长动态mesh序列压缩成固定数量token后,本文基于MMDiT[5]架构设计了一个轨迹生成模型,并使用基于Rectified flow的策略进行训练/推理,得到最终的文生轨迹模型。
需要注意的是,该轨迹生成模型的监督有两个信号:文本信号和第一帧的特征信号,其中文本信号被编码成了独立的token,而第一帧的特征则与对应的相对轨迹特征一一对应。如图5所示,第一帧的特征与加噪后的相对轨迹特征在channel维度拼接后,再与文本特征在sequence维度拼接作为网络的输入。
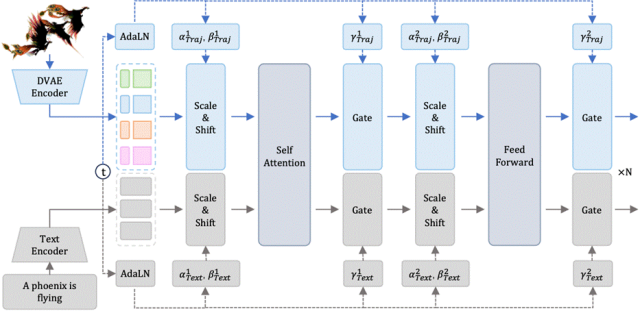
图4:Text-to-Trajectory Retified Flow Model架构
2.4 DyMesh数据集
本文提出了大规模高质量动态mesh序列数据集DyMesh数据集,为高质量4D生成提供了基础。DyMesh数据集的数据来源主要有三个:Objaverse1.0[6],AMASS[7],DT4D[8]。
本文利用bpy将上述数据集中的数据转化为顶点轨迹并保存成相同格式,随后经过:切片、居中归一化、动作幅度筛选、渲染正面视频、打标(Qwen-VL-2.5)来得到最终的数据,并通过最大顶点数目以及帧数划分为子集,得到的DyMesh数据集如下:


实验结果
3.1 与其他方法对比

图5:定性比较
本文与三种方法进行了对比:DG4D, L4GM[9], Animate3D,其中,DG4D为单场景优化方法、L4GM为视频到4D重建方法、Animate3D则是先前馈生成四个正交视角的视频,再单场景优化每组视频对初始mesh的驱动结果。由图6中可以看到:我们的方法在生成结果的时空一致性、局部形状保持、以及语义一致性上都明显超越了对比的方法。并且由于我们的方法完全前馈生成,在效率上也大大超过了对比的方法:
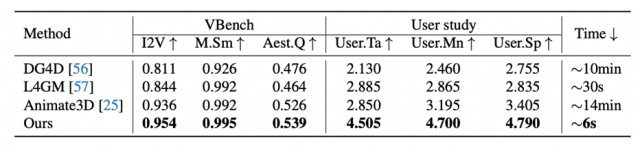
上述表格中的测试均在单张Nvidia A800 GPU上得到,其中I2V, M.Sm, Aest.Q分别为VBench[10]中的I2V Sub- ject Similarity, Motion Smoothness, Aesthetic Quality指标。
3.2 消融实验

图6:拓扑感知邻域Attention消融实验
由图6可以看到,未引入连接矩阵
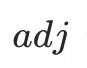
聚合邻域信息时,图中人物的左手和腰部在运动过程中出现了粘连问题,腰部部分顶点随着手部运动了一段距离。引入邻域信息后,手/腰部的顶点的运动被很好地解耦,体现出了所提出的拓扑感知邻域Attention对解决粘连问题的有效性。

图7:轨迹特征PE(positional encoding)消融实验
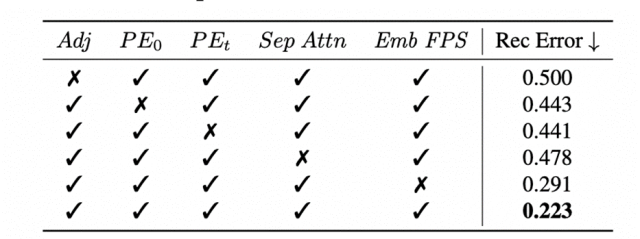
如图7所示,加入轨迹特征PE后,原本的局部抖动被很好缓解,重建出的轨迹也更加平滑,贴近gt。另外,本文还针对:顶点轨迹PE、顶点-轨迹JointAttention、特征FPS做了相应消融实验,以上消融实验的定量结果如下:
参考文献
-
Olga Sorkine and Marc Alexa. As-rigid-as-possible surface modeling. In Symposium on Geometry processing, pages 109–116. Citeseer, 2007.
-
Ben Poole, Ajay Jain, Jonathan T Barron, and Ben Milden- hall. Dreamfusion: Text-to-3d using 2d diffusion. arXiv preprint arXiv:2209.14988, 2022.
-
JiaweiRen,LiangPan,JiaxiangTang,ChiZhang,AngCao, Gang Zeng, and Ziwei Liu. Dreamgaussian4d: Genera- tive 4d gaussian splatting. arXiv preprint arXiv:2312.17142, 2023.
-
Yanqin Jiang, Chaohui Yu, Chenjie Cao, Fan Wang, Weim- ing Hu, and Jin Gao. Animate3d: Animating any 3d model with multi-view video diffusion. arXiv preprint arXiv:2407.11398, 2024.
-
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Mu ̈ller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling recti- fied flow transformers for high-resolution image synthesis. In Forty-first international conference on machine learning, 2024.
-
Matt Deitke, Dustin Schwenk, Jordi Salvador, Luca Weihs, Oscar Michel, Eli VanderBilt, Ludwig Schmidt, Kiana Ehsani, Aniruddha Kembhavi, and Ali Farhadi. Objaverse: A universe of annotated 3d objects. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13142–13153, 2023.
-
NaureenMahmood,NimaGhorbani,NikolausF.Troje,Ger- ard Pons-Moll, and Michael J. Black. AMASS: Archive of motion capture as surface shapes. In International Conference on Computer Vision, pages 5442–5451, 2019.
-
Yang Li, Hikari Takehara, Takafumi Taketomi, Bo Zheng, and Matthias Nießner. 4dcomplete: Non-rigid motion es- timation beyond the observable surface. In Proceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 12706–12716, 2021.
-
Jiawei Ren, Cheng Xie, Ashkan Mirzaei, Karsten Kreis, Zi- wei Liu, Antonio Torralba, Sanja Fidler, Seung Wook Kim, Huan Ling, et al. L4gm: Large 4d gaussian reconstruction model. Advances in Neural Information Processing Systems, 37:56828–56858, 2025.
-
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, et al. Vbench: Comprehensive bench- mark suite for video generative models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21807–21818, 2024.

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 0
0 0
0- 0



 已为社区贡献120条内容
已为社区贡献120条内容

所有评论(0)