达摩院ICCV'25|让AI“聚焦”病灶!ViSD-Boost新框架破解医学图像低信噪比困局
作者|曹维维,阿里巴巴达摩院算法工程师
摘要
视觉语言预训练(VLP)在开放场景多病种辅助诊断方面具有巨大的潜力。然而,将具有低信噪比的医学图像与具有高信噪比的报告对齐存在语义密度差异,易导致视觉对齐偏差。
本文提出ViSD-Boost,通过提高视觉语义密度来促进对齐效果。我们在CT-RATE和Rad-ChestCT两个胸部CT数据集以及MedVL-CT69K腹部CT数据集上进行了广泛的实验,ViSD-Boost实现了多疾病Zero-shot分类能力。此外,我们还证明预训练模型具有迁移学习能力。
论文题目:Boosting vision semantic density with anatomy normality modeling for medical vision-language pre-training
Arxiv链接:https://www.arxiv.org/abs/2508.03742

现存问题及挑战
医学Vision-language pre-training (VLP) 模型能够从报告中学习疾病相关信息,有望显著提升开放场景多病种诊断的能力。然而,医学影像(例如3D CT图像)通常呈现低信噪比的特点,病灶相关区域在整个3D CT中往往仅占极小的比例,而报告则高度浓缩了诊断语义,呈现高信噪比特点。
这种“语义密度差异”导致视觉文本对齐困难,模型难以聚焦病灶、异常等关键区域,限制了AI模型的临床应用价值。如图1所示,我们给出了一个在 CT 图像中诊断膀胱结石的例子。由于视觉语义密度低,VLP模型难以准确聚焦于体积小于整体器官千分之一的小膀胱结石。
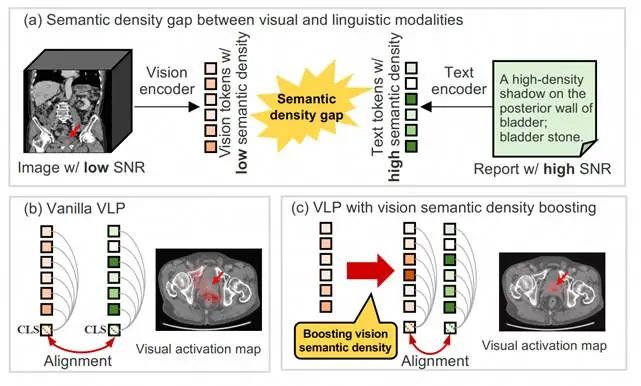
图1. (a) 视觉与语言模态的密度差异。我们展示了一个腹部CT图像及其对应的报告,报告提示膀胱结石;(b) 现有的VLP方法,视觉激活图未能准确定位结石区域,存在视觉对齐偏差;(c) 我们提出通过提升视觉语义密度来促进模型识别疾病相关区域。

方法
1.Anatomy-wise image-report alignment
我们使用
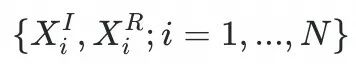
表示成对的图像报告数据集,使用视觉编码器和mask提取解剖级视觉特征
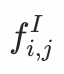
,文本编码器提取解剖级报告特征
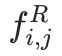
。对于视觉特征,我们构建一个可学习的Query,通过注意力机制来聚合解剖结构所有token信息:

,类似的,文本token聚合为:

。因此,Anatomy-wise image-report alignment的优化目标可以公式化为:
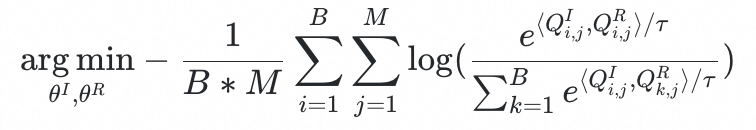
其中,
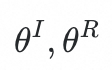
是视觉和文本编码器的参数,B是batch size,M是解剖结构数量,
![]()
是温度。
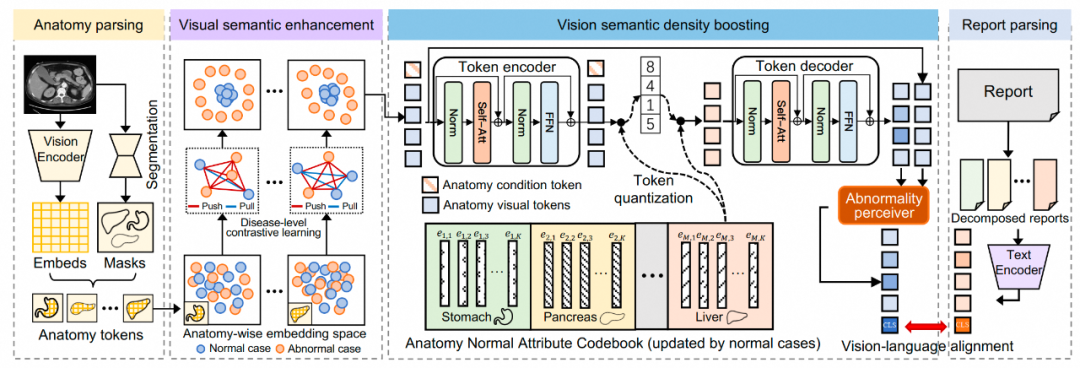
图2. 提出的ViSD-Boost框架。Anatomy parsing: 根据解剖结构mask提取vision tokens;Visual semantic enhancement: 使用疾病级视觉对比学习增强正常/健康和异常样本的语义区分性;Vision semantic density boosting: 使用VQ-VAE建模健康解剖结构分布来放大异常视觉线索;Report parsing: 使用LLM将完整CT报告解析为解剖结构级别报告。
2.Visual semantic enhancement
我们提出疾病级视觉对比学习来增强样本的视觉语义。传统的视觉对比学习方法是实例级别,样本实例之间互相推远,但此类方法不足以获取疾病级别的语义。
受到异常检测的启发,我们将健康样本作为语义相同的一类,而异常样本视为互不相同的个体,在语义空间中将健康样本聚集在一起,增加异常样本与其他样本的区分性。我们使用LLM从报告中识别每个解剖结构正常/异常的标签,表示为
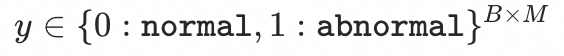
,因此疾病级视觉对比学习的loss可公式化为:
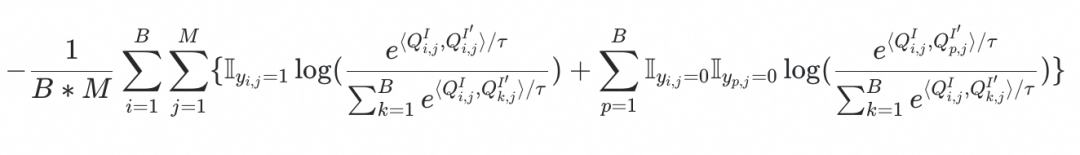
3.Vision semantic density boosting
3.1 Anatomical normality modeling
在visual semantic enhancement之后,视觉编码器具有了区分正常和异常解剖结构的能力,但是其捕捉诊断相关关键语义的能力仍然不足。因此,我们提出了一种健康解剖结构建模的方法,使用VQ-VAE建模健康解剖的属性分布。
我们的方法与传统VQ-VAE有两个方面的差异:
(1)Multi-distribution learning:CT图像包括几十种解剖结构,我们引入了一个condition token使用一套编解码器来提示VQ-VAE完成不同解剖结构的重建任务;
(2)Modeling in latent space:我们在latent space训练VQ-VAE,而不是在图像域,这不仅提升了计算效率,还降低了健康解剖属性编码的难度。此外,为了更有效的聚合解剖结构的所有token信息,我们专门设计了基于transformer的token encoder
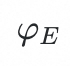
和token decoder
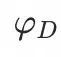
。Embedding重建的过程可以用以下公式表示:
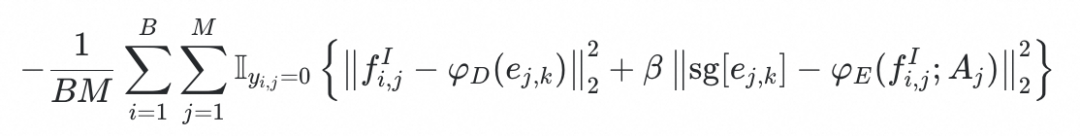
其中,
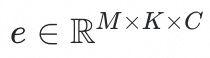
为codebook,包含M*K个向量。
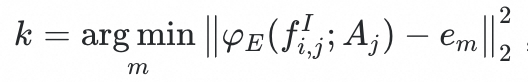
;

是anatomy condition token,
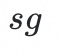
表示截断梯度操作。
3.2Abnormality semantic perception
使用VQ-VAE 对原始embedding
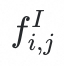
进行重建得到embedding
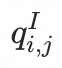
,需要注意的是,
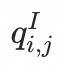
不存在任何异常语义。因此,有必要设计一个差异感知模块,该模块以重建的正常embedding作为参考,检测原始embedding中的差异,从而指示潜在的异常成分。该模块提取并放大这些异常信号,以提升视觉embedding的语义密度。我们设计了一个简单而高效的感知模块,将
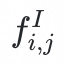
和
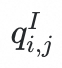
拼接作为多层感知器(MLP)网络的输入。我们使用 MLP 的输出替换原始embedding
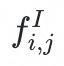
,记为正在上传…重新上传取消
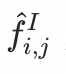
,并根据公式1进行视觉语言预训练。

实验结果
-
在胸部CT(CT-RATE, Rad-ChestCT)场景与腹部CT(MedVL-CT69K)场景的三个数据集上,ViSD-Boost达到了业内领先的诊断表现,其中腹部CT场景覆盖15个器官54类疾病,平均AUC高达84.9%(表1),显著优于现有主流VLP模型。
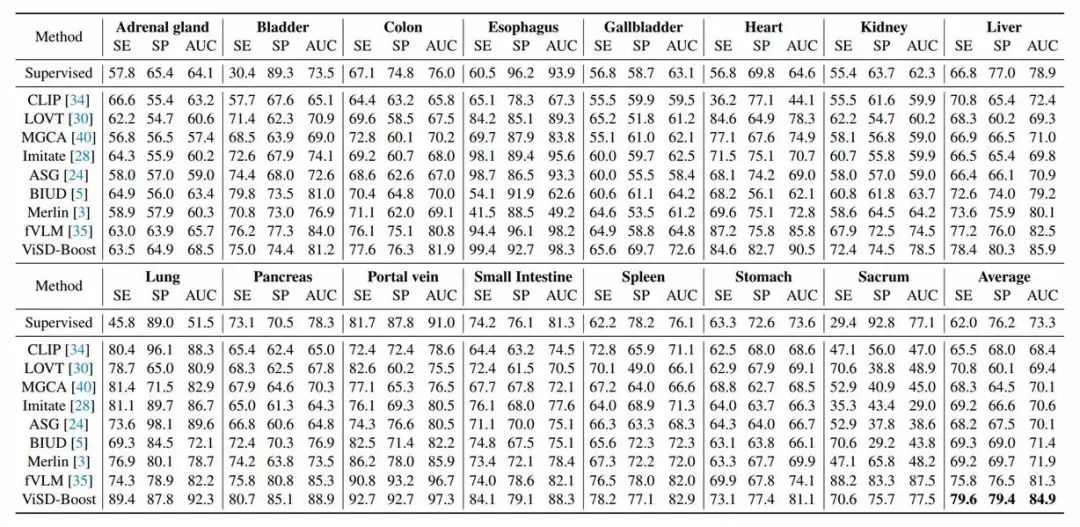
表1. 各方法在MedVL-CT69K测试集上Zero-shot的性能比较。
-
在下游报告生成任务中,ViSD-Boost同样表现出色,报告生成的关键指标(F1, CIDEr等)明显优于其他方法,生成结果兼具医学完整性与自然语言表达能力。
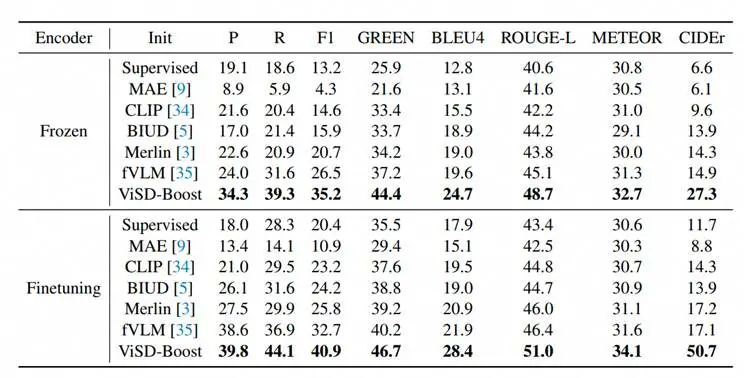
表2. 各方法在下游报告生成任务上的性能比较。
-
更多实验结果可参考论文。
![]()
结论
在这项工作中,我们提出通过提高视觉语义密度来解决医学图像和诊断报告之间语义密度差异造成的视觉对齐偏差。一方面,我们提出了一种疾病级视觉对比学习方法来增强视觉语义。另一方面,我们提出了一种健康解剖分布建模方法来提升视觉语义密度。我们的方法在胸部和腹部CT场景下都实现了良好的Zero-shot诊断性能,并在多个下游任务中展示了迁移学习能力。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 0
0 0
0- 0



 已为社区贡献120条内容
已为社区贡献120条内容

所有评论(0)