MySQL索引之王:B+树全方位解析!揭秘数据库的底层选择
最后思考💡 随着SSD的普及,B+树会淘汰吗?🔍 不会!顺序访问仍快于随机访问(5-10倍)页面读取机制依然有效范围查询优势不可替代未来趋势:B+树 + SSD = 如虎添翼!行动指南:使用查看你的B+树状态,探索INDEX TREE部分!欢迎在评论区分享你的发现。🚀。
·
为什么全球最流行的数据库MySQL选择B+树作为核心索引结构? 本文将带你穿越数据结构的世界,揭开MySQL设计决策背后的深层逻辑!
一、索引结构的抉择:MySQL的十字路口
想象MySQL在构建索引系统时面临的抉择:
MySQL的决策矩阵:
| 需求 | 二叉树 | 哈希表 | B树 | B+树 |
|---|---|---|---|---|
| 磁盘I/O优化 | ❌ | ⚠️ | ✅ | ✅✅ |
| 范围查询效率 | ⚠️ | ❌ | ✅ | ✅✅ |
| 高并发稳定 | ❌ | ⚠️ | ✅ | ✅✅ |
| 存储利用率 | ❌ | ✅ | ⚠️ | ✅✅ |
| 插入删除效率 | ❌ | ✅ | ✅ | ✅ |
二、B+树结构全景:三层精妙设计
B+树核心架构
B+树典型结构:
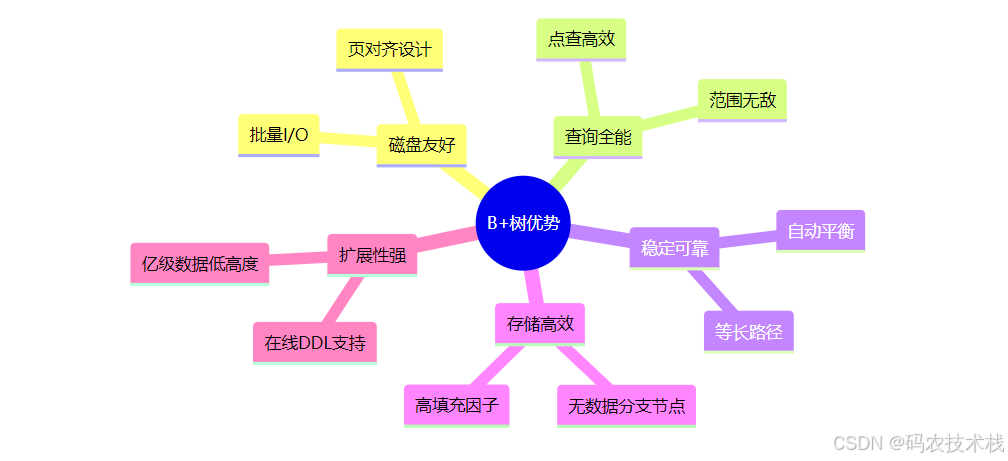
三、B+树的五大核心优势
1. 磁盘I/O优化之王
机械硬盘访问原理:
B+树的优化:
- 节点大小 = 磁盘页大小(默认16KB)
- 单次I/O加载整个节点
- 4层B+树可存储10亿数据(只需3次I/O)
2. 范围查询的终极武器
SELECT * FROM orders
WHERE amount BETWEEN 1000 AND 5000;
B+树执行流程:
3. 超稳定的查询性能
查询路径等长特性:
B树 vs B+树查询对比:
| 查询类型 | B树 | B+树 |
|---|---|---|
| 最小键值 | 2次I/O | 3次I/O |
| 最大键值 | 4次I/O | 3次I/O |
| 中间键值 | 3次I/O | 3次I/O |
4. 超高存储利用率
节点空间分布: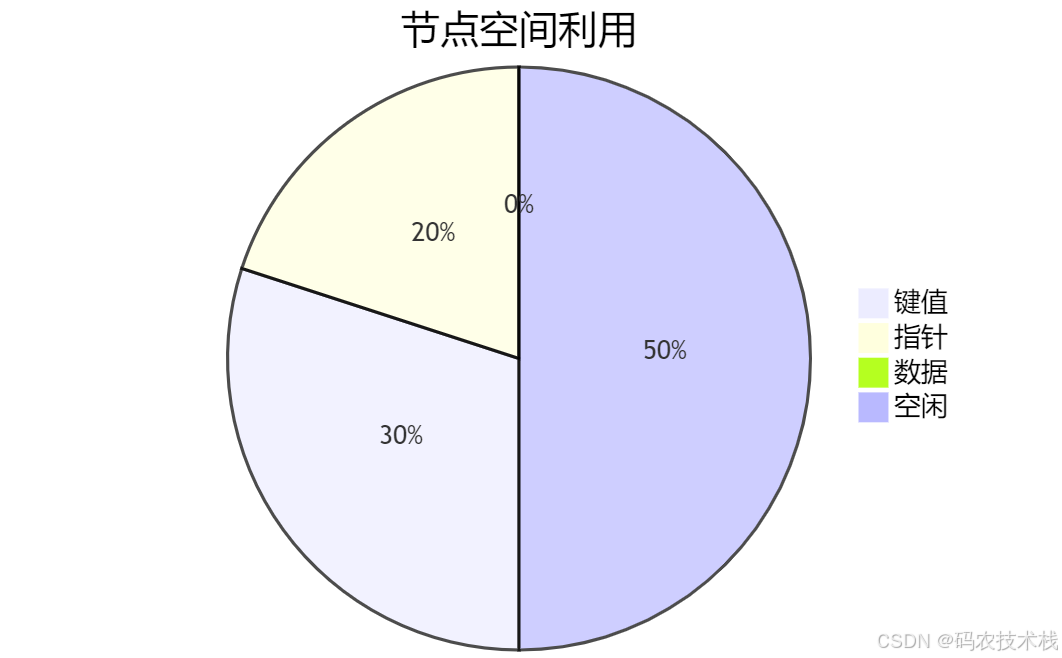
B+树 vs B树存储对比:
| 特性 | B树 | B+树 | 优势 |
|---|---|---|---|
| 数据存储位置 | 所有节点 | 仅叶子节点 | B+树分支节点更小 |
| 相同内存缓存 | 1,000节点 | 5,000节点 | 5倍缓存效率 |
| 10亿数据高度 | 5-6层 | 4层 | 减少I/O次数 |
5. 并发控制的天然盟友
InnoDB锁机制与B+树:
优势体现:
- 行锁直接定位叶子节点数据
- 间隙锁利用叶子节点链表结构
- MVCC多版本存储在叶子节点
四、B+树 vs 其他数据结构:全面对决
1. B+树 vs 二叉树
致命缺陷:
- 二叉树高度:log₂(N) = 30层(10亿数据)
- B+树高度:log₅₀₀(N) ≈ 4层
2. B+树 vs 哈希表
哈希索引缺陷:
-- 无法优化范围查询
SELECT * FROM users WHERE age > 30;
-- 无法优化排序
SELECT * FROM products ORDER BY price;
哈希碰撞处理:
3. B+树 vs B树
B树结构缺陷:
核心差异:
| 特性 | B树 | B+树 |
|---|---|---|
| 数据位置 | 所有节点 | 仅叶子 |
| 叶子连接 | 无 | 双向链表 |
| 查询稳定性 | 波动大 | 高度统一 |
| 范围查询 | 需要回溯 | 顺序遍历 |
五、B+树在InnoDB中的实现
InnoDB索引结构
二级索引查询流程:
页面结构(16KB)
struct InnoDBPage {
FIL_HEADER(38字节)
PAGE_HEADER(56字节)
INFIMUM记录(13字节)
SUPREMUM记录(13字节)
用户记录
PAGE_DIRECTORY
FIL_TRAILER(8字节)
}
六、B+树实战:从理论到SQL
创建不同索引对比
-- B+树索引(默认)
CREATE INDEX idx_amount ON orders(amount);
-- 哈希索引(Memory引擎)
CREATE TABLE hash_table (
id INT PRIMARY KEY,
data VARCHAR(100)
) ENGINE=MEMORY;
CREATE INDEX idx_hash USING HASH ON hash_table(data);
-- 全文本索引(特殊结构)
CREATE FULLTEXT INDEX idx_content ON articles(content);
索引选择演示
-- 范围查询(B+树有效)
EXPLAIN SELECT * FROM orders
WHERE amount > 1000 AND amount < 5000;
-- type: range, key: idx_amount
-- 等值查询(哈希更快但有限制)
EXPLAIN SELECT * FROM hash_table
WHERE data = 'test';
-- type: const
七、为什么不是其他结构?MySQL的深层考量
LSM树的诱惑与缺陷
放弃原因:
- 读放大问题(需查多级文件)
- 压缩影响实时性能
- 不适合OLTP高频读场景
跳表的局限
不适用原因:
- 内存结构为主
- 磁盘I/O不友好
- 无批量加载优化
八、总结:B+树的王者之道
MySQL选择B+树的终极原因
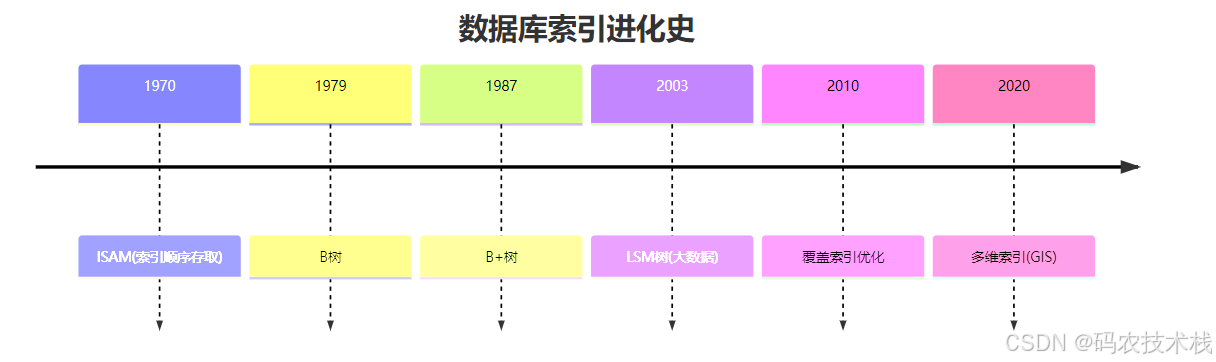
数据库索引结构进化史
最后思考:
💡 随着SSD的普及,B+树会淘汰吗?
🔍 不会!SSD减少了寻道时间,但:
- 顺序访问仍快于随机访问(5-10倍)
- 页面读取机制依然有效
- 范围查询优势不可替代
未来趋势:B+树 + SSD = 如虎添翼!
行动指南:使用SHOW ENGINE INNODB STATUS查看你的B+树状态,探索INDEX TREE部分!欢迎在评论区分享你的发现。🚀

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 20
20 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)