深度学习之学习笔记(七)—— 损失函数
损失函数在第五章《神经网络的学习(训练)》中,我们介绍神经网络的训练过程中,需要不断对权重进行调整。调整权重的目的是为了得到一组最终权重,使得输入的特征数据的输出达到我们的期望值,也就是神经网络的实际输出值与期望输出值误差最小。那么问题来了:如何度量两组数据之间的差异?序号实际输出值期望输出值(Label)1数据a数据b2323.1...
损失函数
在第五章《神经网络的学习(训练)》中,我们介绍神经网络的训练过程中,需要不断对权重进行调整。调整权重的目的是为了得到一组最终权重,使得输入的特征数据的输出达到我们的期望值,也就是神经网络的实际输出值与期望输出值误差最小。
那么问题来了:如何度量两组数据之间的差异?
| 序号 | 实际输出值 | 期望输出值(Label) |
| 1 | 数据a | 数据b |
| 2 | 323.1 | 320.7 |
| 3 | 321.1 | 322 |
| 4 | 321.5 | 321.4 |
| 5 | 323 | 324.6 |
| 6 | 324.1 | 323.2 |
| 7 | 319 | 321.2 |
| 8 | 318.2 | 324.2 |
| 9 | 321.3 | 322.9 |
| 10 | 321.8 | 323 |
| 11 | 320.4 | 324 |
| 12 | 322.2 | 323 |
| 13 | 322.8 | 325.2 |
| 14 | 321.5 | 320.5 |
| 15 | 319.5 | 323.5 |
| 16 | 322.9 | 323.5 |
| 17 | 321 | 322 |
| 18 | 323.7 | 324.9 |
损失函数闪亮登场( )
)
我们希望找到一种度量实际输出值与期望输出值之间误差的方式,这种度量方式可以使用函数表示,这个函数称为误差损失函数,神经网络的训练过程就是要找到一组权重,使得误差损失函数最小
度量误差的方式有很多种,我们用一个线性回归的例子来说明。假设要预测一个公司某商品的销售量
X:门店数 Y:销量
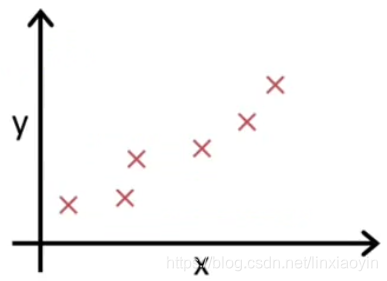
我们发现销量随着门店数上升而上升。我们想要知道门店和销量的大概关系是怎么样的?于是建立一个预测模型 。首先假设该模型的权重参数为
, 那么
,用下图中的蓝色直线表示
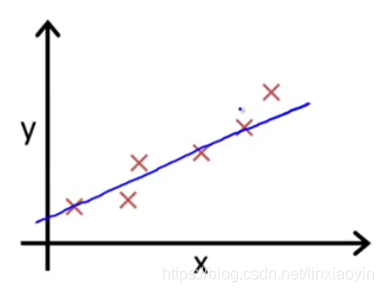
我们希望预测模型的输出与实际值差值越小越好,所以就定义了一种衡量模型好坏的方式,即损失函数。非常直观地,这个损失函数可以用实际输出值与期望输出值之差的绝对值来表示,称为绝对损失函数:
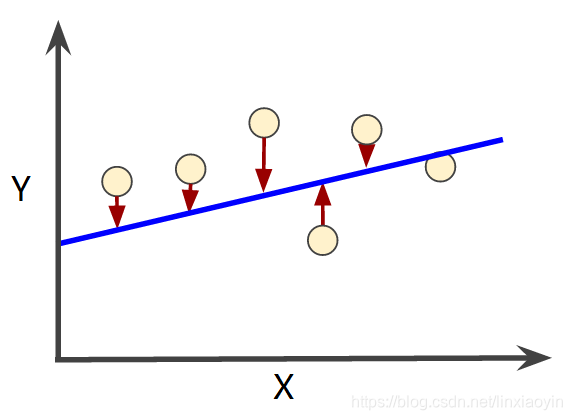
同时,我们选取另一组权重参数为 ,那么
, 计算输出值与期望值的差值:
| X | Y1 | Y2 | 期望输出值 | 差值1 | 差值2 |
|---|---|---|---|---|---|
| 1 | 13 | 12 | 13 | 0 | -1 |
| 2 | 16 | 16 | 14 | 2 | 2 |
| 3 | 19 | 20 | 20 | -1 | 0 |
| 4 | 22 | 24 | 21 | 1 | 3 |
| 5 | 25 | 28 | 25 | 0 | 3 |
| 6 | 28 | 32 | 30 | -2 | 2 |
将差值1取绝对值后求和,得:6
将差值2取绝对值后求和,得:11
由此,我们判断当权重参数为 时,模型的表现更好。
我们在第五章《神经网络的学习(计算)》中,曾提到过
在步骤(3)中,我们计算
的调整值时,用的方法是直接计算预期值与输出值的差:
,这是很朴素的方法。一般在神经网络的训练中,我们会采用更为复杂的损失函数来计算这个调整值。
均方误差损失函数
在实际中,比绝对损失函数更常用的损失函数是均方误差(Mean Squared Error,简称MSE),该损失函数表示如下:
其中,表示所有样本数。
表示样本的实际输出值,
表示样本的期望输出值。
对于前面的门店与销量的例子,
当权重参数为 时,均方误差损失函数的值为:
当权重参数为 时, 均方误差损失函数的值为:
当权重参数为 时,模型的表现更好。
损失函数的分类
在实际应用中,并没有一个通用的,对所有的机器学习算法都表现的很不错的损失函数(或者说没有一个损失函数可以适用于所有类型的数据)。针对特定问题选择某种损失函数需要考虑到到许多因素,包括是否有离群点,机器学习算法的选择,运行梯度下降的时间效率,是否易于找到函数的导数,以及预测结果的置信度等。
从学习任务的类型出发,可以从广义上将损失函数分为两大类——分类损失(Classification Loss)和回归损失(Regression Loss)。在分类任务中,我们要从类别值有限的数据集中预测输出,比如给定一个手写数字图像的大数据集,将其分为 0~9 中的一个。而回归问题处理的则是连续值的预测问题,例如给定房屋面积、房间数量,去预测房屋价格。
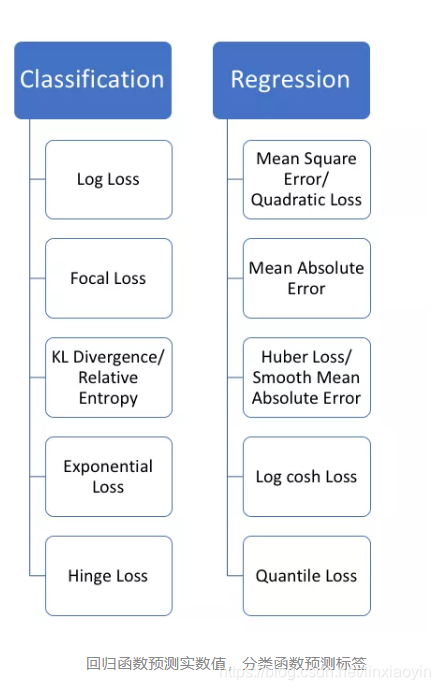
我们上面介绍的均方误差损失函数(上图中右边的Mean Square Error)属于回归损失函数。下面我们要介绍分类损失函数中使用得最广泛的损失函数——交叉熵,它与上图中左边的KL Divergence / Relative Entropy(KL散度 / 相对熵)指的是同一件事。
交叉熵损失函数( )
)
在介绍交叉熵之前,我们先认识一下信息熵(Entropy)。
信息熵(Entropy)
熵 (entropy) 这一词最初来源于热力学。1948年,克劳德·爱尔伍德·香农将热力学中的熵引入信息论,所以也被称为香农熵 (Shannon entropy),信息熵 (information entropy)。
一条信息的信息量大小和它的不确定性(概率)有直接的关系。我们需要搞清楚一件非常非常不确定的事,或者是我们一无所知的事,就需要了解大量的信息。相反,如果我们对某件事已经有了较多的了解,我们就不需要太多的信息就能把它搞清楚。所以,从这个角度,我们可以认为,信息量的度量就等于不确定性的大小(不确定性越大,概率越小)。
例如:
- 事件一:巴西进世界杯
- 事件二:中国进世界杯
由于中国进世界杯的概率很小,所以事件二带来的信息量更大一些,给人留下的印象更深刻(惊讶)。
由上面的例子可知,信息的量度应该依赖于概率分布 ,因此我们想要寻找一个函数
,它是概率
的单调函数,表达了信息的内容:
- 如果我们有两个不相关的事件
和
,那么观察两个事件同时发生时获得的信息量应该等于观察到事件各自发生时获得的信息之和,即
- 因为两个事件是独立不相关的,因此
- 根据这两个关系,很容易看出
一定与
的对数有关 (因为对数的运算法则是
)
因此我们定义 ,其中负号是用来保证信息量是正数或者零(因为
取值在[0,1]之间)
其中 log 函数的底的选择是任意的
- 信息论中基常常选择为2,因此信息的单位为比特(bit)
- 而机器学习中基常常选择为自然常数e,因此单位常常被称为奈特(nat)
也被称为随机变量 x 的自信息 (self-information),描述的是随机变量的某个事件发生所带来的信息量,其图形如下图:
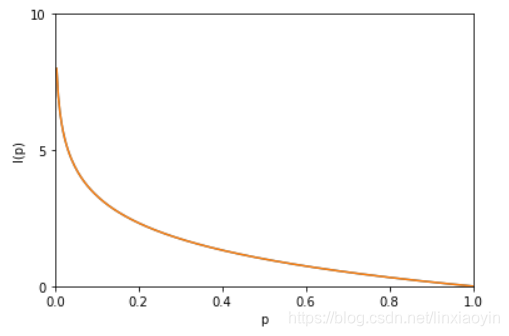
信息熵的定义:
假设一个发送者想传送一个随机变量的值给接收者。那么在这个过程中,他们传输的平均信息量可以通过求
关于概率分布
注:概率分布的期望是指某些事件大量发生以后的平均的结果。比如一个六面的骰子扔了很多很多次以后,得到的骰子的平均值会趋近于3.5。
交叉熵(Cross Entropy)的通俗解释(来自知乎)
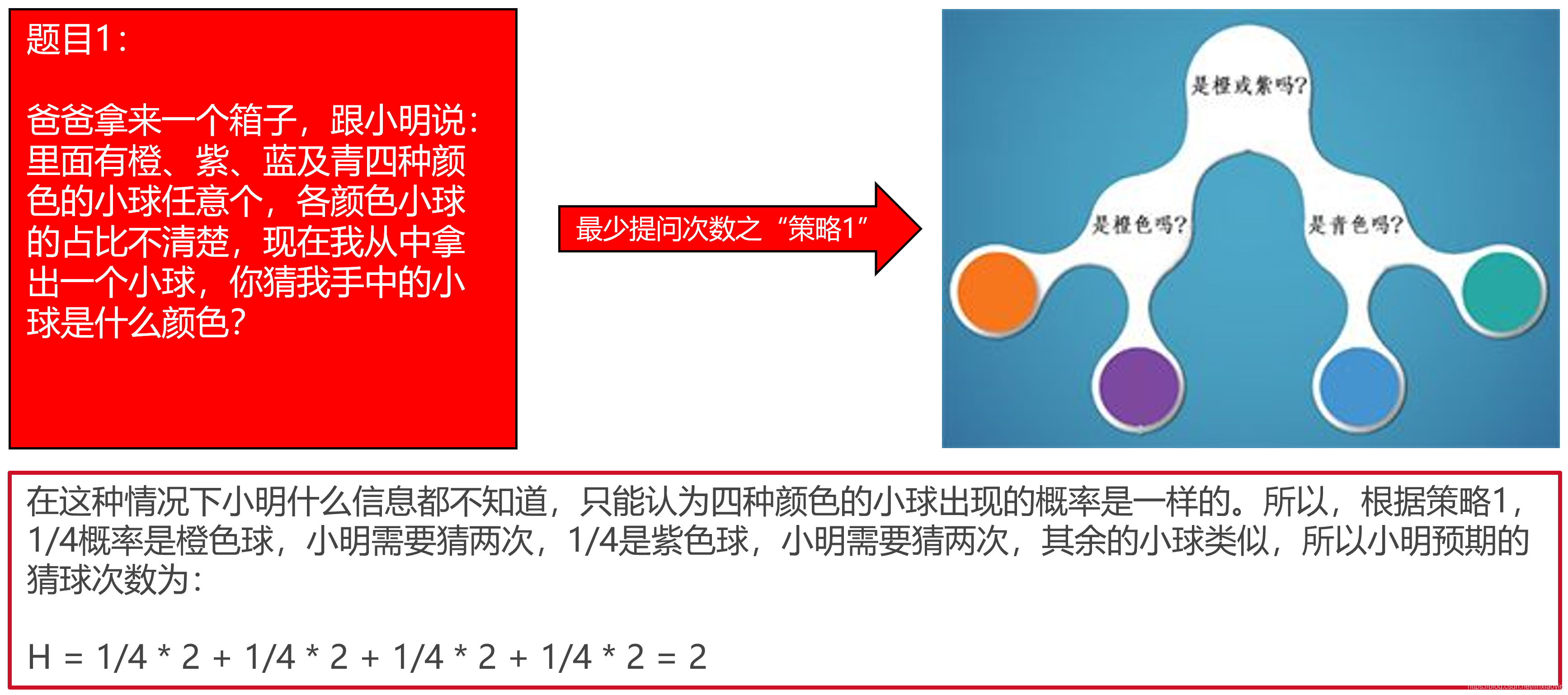
小明在学校玩王者荣耀被发现了,爸爸被叫去开家长会,心里悲屈的很,就想法子惩罚小明。到家后,爸爸跟小明说:既然你犯错了,就要接受惩罚,但惩罚的程度就看你聪不聪明了。这样吧,我们俩玩猜球游戏,我拿一个球,你猜球的颜色,我可以回答你任何问题,你每猜一次,不管对错,你就一个星期不能玩王者荣耀,当然,猜对,游戏停止,否则继续猜。当然,当答案只剩下两种选择时,此次猜测结束后,无论猜对猜错都能100%确定答案,无需再猜一次,此时游戏停止。
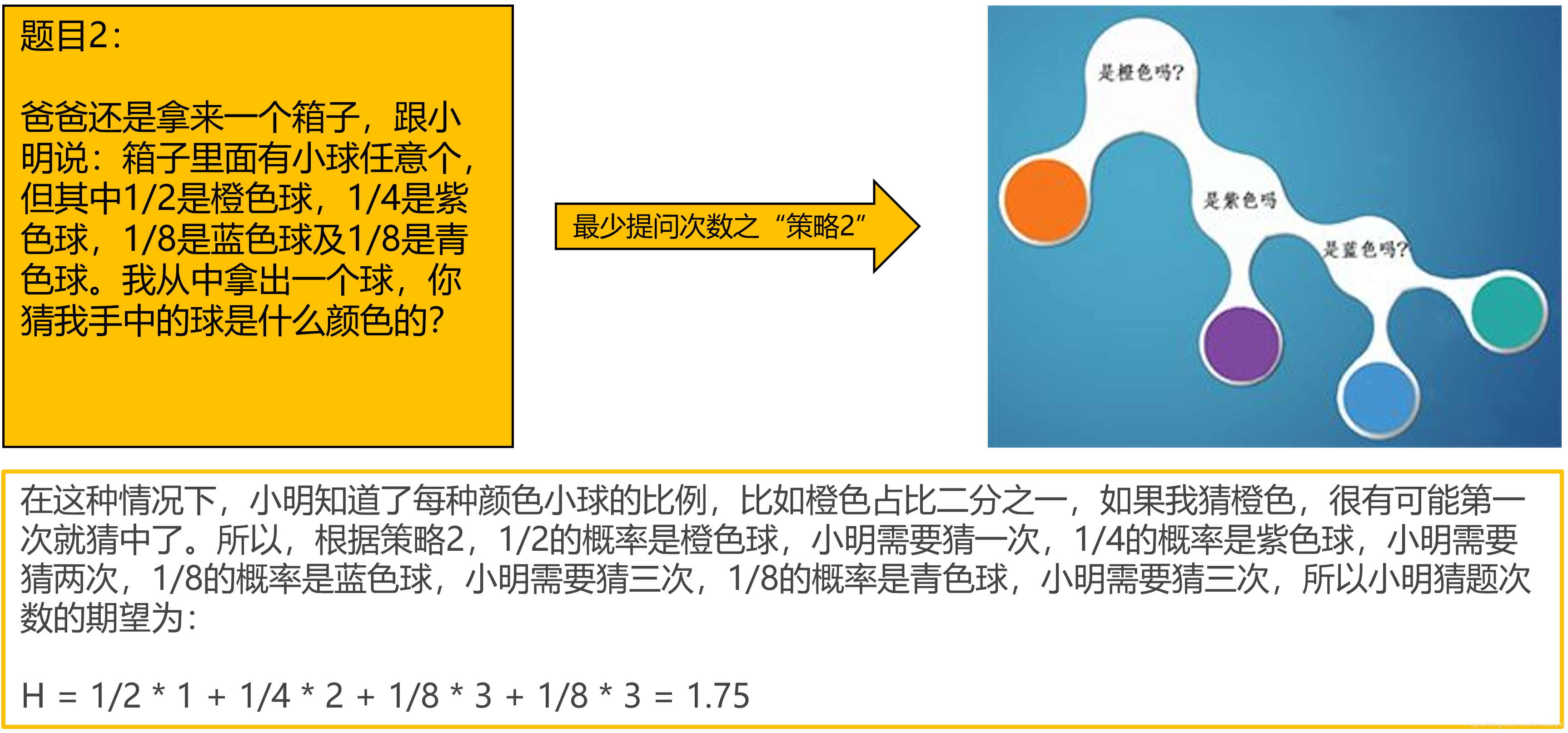

上面三个题目表现出这样一种现象:针对特定概率为 的小球,需要猜球的次数
。
例如题目2中,
- 1/4是紫色球,
次
- 1/8是蓝色球,
次
这就是一个事件的自信息(self-information)。那么,针对整个系统,有多种可能发生的事件,预期的猜题次数为:
这就是信息熵。上面三个题目的预期猜球次数都是由这个公式计算而来,第一题的信息熵为2,第二题的信息熵为1.75,最三题的信息熵为 。
信息熵代表的是随机变量或整个系统的不确定性,熵越大,随机变量或系统的不确定性就越大。上面题目1的熵 > 题目2的熵 > 题目3的熵。在题目1中,小明对整个系统一无所知,只能假设所有的情况出现的概率都是均等的,此时的熵是最大的。题目2中,小明知道了橙色小球出现的概率是1/2及其他小球各自出现的概率,说明小明对这个系统有一定的了解,所以系统的不确定性自然会降低,所以熵小于2。题目3中,小明已经知道箱子中肯定是橙色球,爸爸手中的球肯定是橙色的,因而整个系统的不确定性为0,也就是熵为0。所以,在什么都不知道的情况下,熵会最大,针对上面的题目1~~题目3,这个最大值是2,除此之外,其余的任何一种情况,熵都会比2小。
所以,每一个系统都会有一个真实的概率分布,也叫真实分布,题目1的真实分布为(1/4,1/4,1/4,1/4),题目2的真实分布为(1/2,1/4,1/8,1/8),而根据真实分布,我们能够找到一个最优策略,以最小的代价消除系统的不确定性,而这个代价大小就是信息熵,记住,信息熵衡量了系统的不确定性,而我们要消除这个不确定性,所要付出的【最小努力】(猜题次数、编码长度等)的大小就是信息熵。具体来讲,题目1只需要猜两次就能确定任何一个小球的颜色,题目2只需要猜测1.75次就能确定任何一个小球的颜色。
很明显,针对题目2,使用策略1是一个坏的选择,因为需要猜题的次数增加了,从1.75变成了2。原因在于使用策略1相当于忽略了爸爸告诉小明关于箱子中各小球的真实分布,而仍旧认为所有小球出现的概率是一样的,认为小球的分布为(1/4,1/4,1/4,1/4),这个分布就是非真实分布。因此,当我们知道根据系统的真实分布制定最优策略去消除系统的不确定性时,我们所付出的努力是最小的,但并不是每个人都和最强王者一样聪明,我们也许会使用其他的策略(非真实分布)去消除系统的不确定性,就好比如我将策略1用于题目2。
那么,当我们使用非最优策略消除系统的不确定性,所需要付出的努力的大小我们该如何去衡量呢?这就需要引入交叉熵,其用来衡量在给定的真实分布下,使用非真实分布所指定的策略消除系统的不确定性所需要付出的努力的大小。
交叉熵的定义:
其中,
表示真实分布,
表示非真实分布。
例如上面所讲的将策略1用于题目2,真实分布 , 非真实分布
,交叉熵为:
比最优策略的1.75来得大。
因此,交叉熵越低,这个策略就越好,最低的交叉熵也就是使用了真实分布所计算出来的信息熵,因为此时 ,交叉熵 = 信息熵,可以理解为信息熵是交叉熵的理想情况。这也是为什么在机器学习中的分类算法中,我们总是最小化交叉熵这个损失函数,因为交叉熵越低,就证明由算法所产生的策略最接近最优策略,也间接证明我们算法所算出的非真实分布越接近真实分布。
相对熵(KL散度)
我们如何去衡量不同策略之间的差异呢?这就需要用到相对熵,其用来衡量两个取值为正的函数或概率分布之间的差异。
现在,假设我们想知道某个策略和最优策略之间的差异,我们就可以用相对熵来衡量这两者之间的差异。即,相对熵 = 某个策略的交叉熵 - 信息熵(根据系统真实分布计算而得的信息熵,为最优策略)。
所以将策略1用于题目2,所产生的相对熵为:2 - 1.75 = 0.25
相对熵的公式如下:
损失函数是衡量预测模型预测结果表现的指标。寻找函数最小值最常用的方法是“梯度下降法”。把损失函数想象成起伏的山脉,梯度下降就好比从山顶滑下,寻找山脉的最低点(目的)。下一章,我们将介绍“梯度下降法”。
References:

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)